selenium爬取拉勾网
文章目录
- 1 安装selenium和webdriver
- 1.1 自动控制浏览器
- 2 正式爬取拉勾网
- 2.1控制浏览器,进入拉勾网
- 2.2爬取所需内容
- 2.2.1解析提取信息
- 2.2.2 翻页爬取
- 3 将内容写入csv文件
- 4 selenium爬取拉勾网代码汇总
1 安装selenium和webdriver
在Python路径下安装selenium,安装成功后还需安装相应浏览器的webdriver,不然无法控制浏览器,比如谷歌浏览器要下载chromedriver
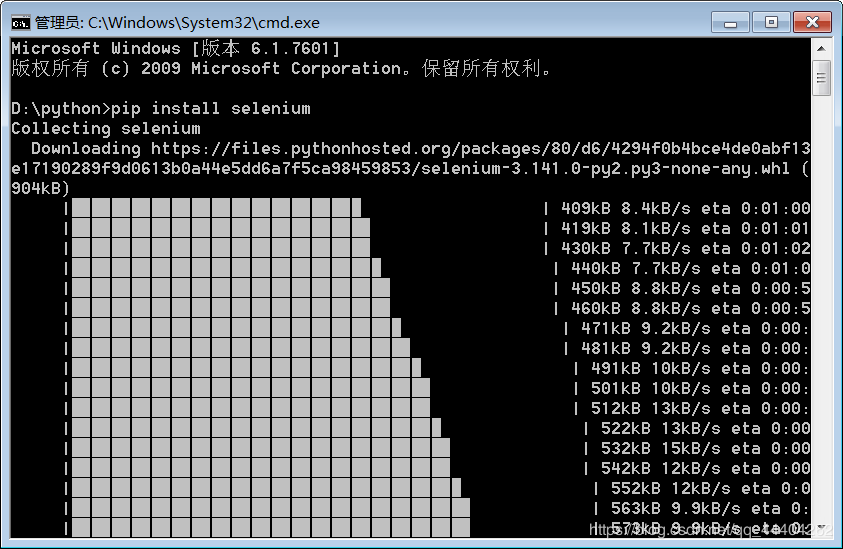
进入官网 http://npm.taobao.org/mirrors/chromedriver/ ,红框中是浏览器版本相应的chromedriver,选择下载后,将压缩包解压
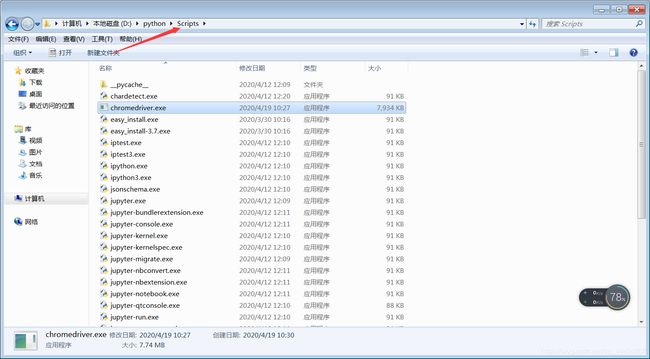
将文件复制到Python路径下的scripts中,不需要配置环境就可以写代码了
1.1 自动控制浏览器
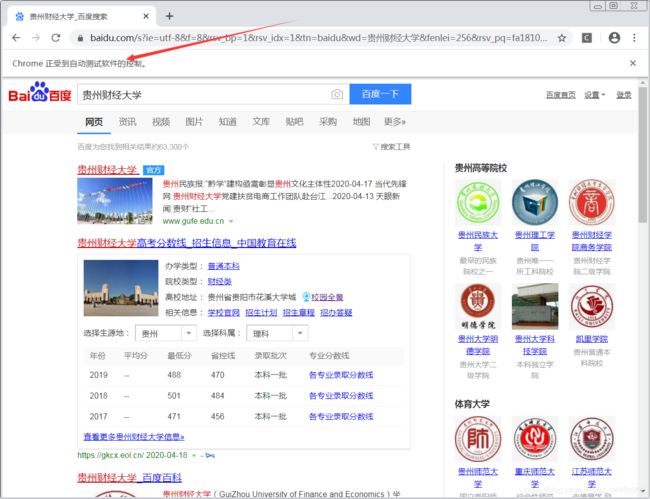
用百度首页作为例子去控制浏览器
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
url = "https://www.baidu.com/"
#创建一个浏览器
driver = webdriver.Chrome()
driver.get(url) #打开网页
search = driver.find_element_by_xpath('//*[@id="kw"]') #输入框节点
search.send_keys('贵州财经大学') #发送内容
search.send_keys(Keys.ENTER) #回车
# time.sleep(3) #等待网页加载
# search.find_element_by_id('su').click() #点击
time.sleep(5) #暂停5秒
driver.close() #关闭浏览器
运行结果:
2 正式爬取拉勾网
2.1控制浏览器,进入拉勾网
用selenium控制浏览器进入拉勾网,查询有关Python 爬虫的职位
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#拉勾网链接
url=" https://www.lagou.com/"
#创建浏览器,打开拉勾网链接
driver = webdriver.Chrome()
driver.get(url)
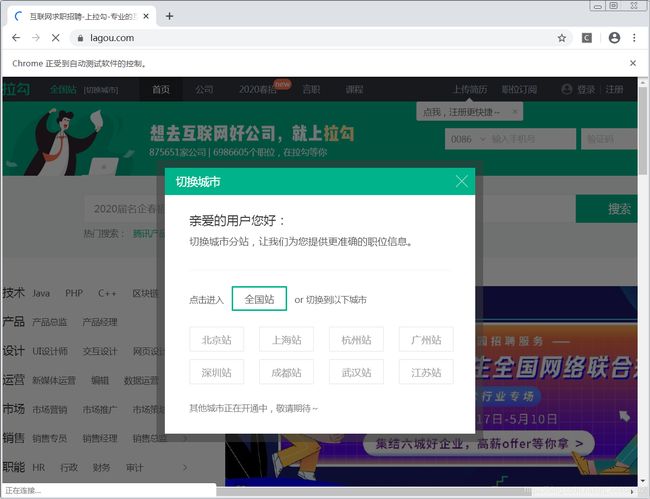
进入首页后,会跳转出一个选择城市分站的小窗口,对网页元素检查,按照图中标的顺序复制“全国站”的xpath路径,让浏览器自动点击
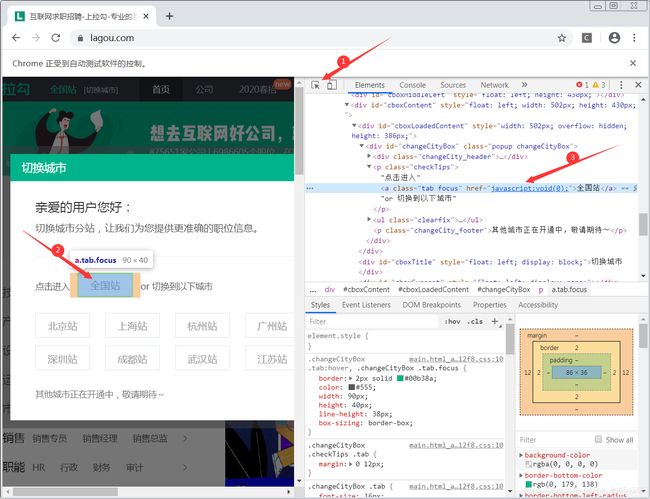
#自动点击全国站
driver.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click()
选择好城市分站后,让浏览器自动在首页搜索框中输入Python 爬虫,对网页元素检查,按照图中箭头所指可找到搜索框 id,然后在搜索框中输入“Python 爬虫”
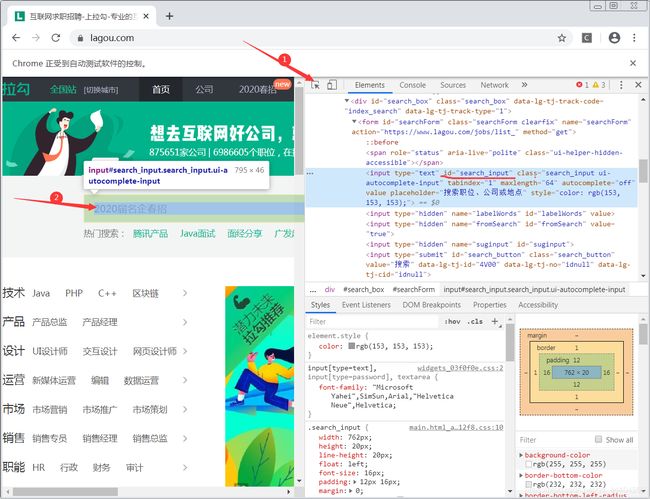
#搜索框
search = driver.find_element_by_id('search_input')
#发送内容
search.send_keys('python 爬虫')
点击“搜索”,查询相关职位,用查找搜索框id的方式zhan查找“搜索”的id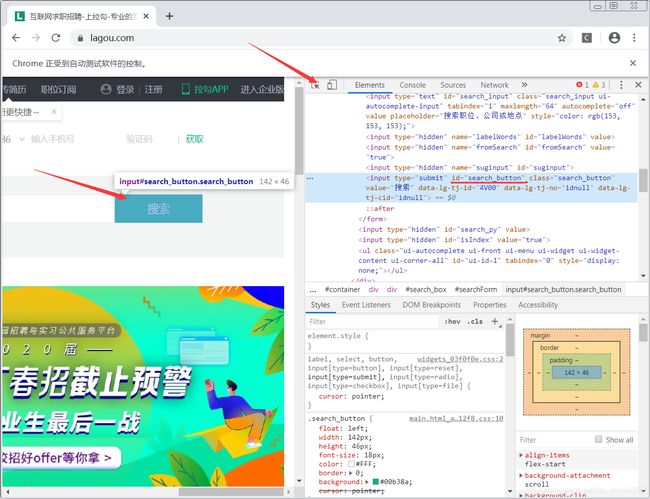
#导入包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#拉勾网链接
url=" https://www.lagou.com/"
#创建浏览器,打开拉勾网链接
driver = webdriver.Chrome()
driver.get(url)
#自动点击全国站
driver.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click()
#搜索框
search = driver.find_element_by_id('search_input')
#发送内容
search.send_keys('python 爬虫')
#停留3秒
time.sleep(3)
#点击搜索框
driver.find_element_by_id('search_button').click()
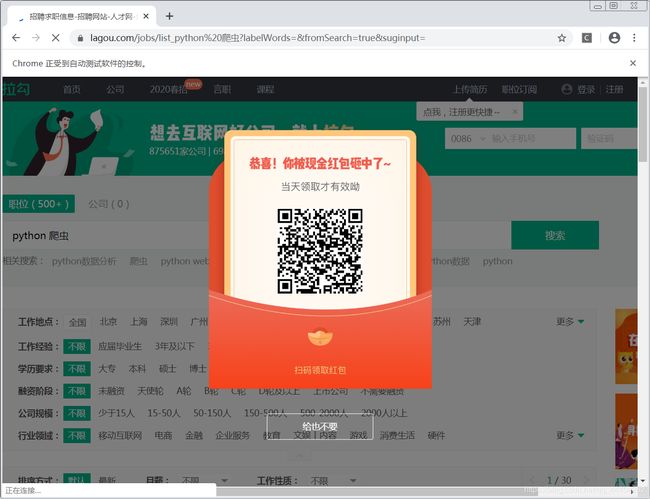
点击搜索之后,会跳出一个扫码领红包的小窗口,对元素检查,用复制“全国站”xpath路径的方式复制“给也不要”的xpath路径
#导入包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#拉勾网链接
url=" https://www.lagou.com/"
#创建浏览器,打开拉勾网链接
driver = webdriver.Chrome()
driver.get(url)
#自动点击全国站
driver.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click()
#搜索框
search = driver.find_element_by_id('search_input')
#发送内容
search.send_keys('python 爬虫')
#停留3秒
time.sleep(3)
#点击搜索框
driver.find_element_by_id('search_button').click()
time.sleep(2)
#点击关闭红包
driver.find_element_by_xpath('/html/body/div[8]/div/div[2]').click()
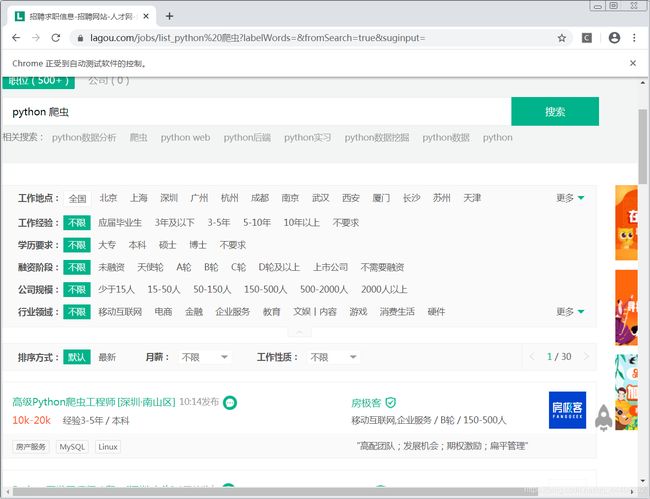
2.2爬取所需内容
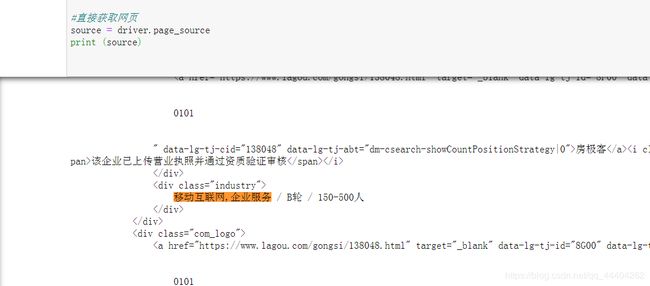
直接获取网页内容
#直接获取网页
source = driver.page_source
print (source)
2.2.1解析提取信息
用复制“全国站”xpath路径的方式去复制“职位”和“薪资”的xpath路径

分析每个职位和薪资的xpath路径,就红框中位置不一样,依序递增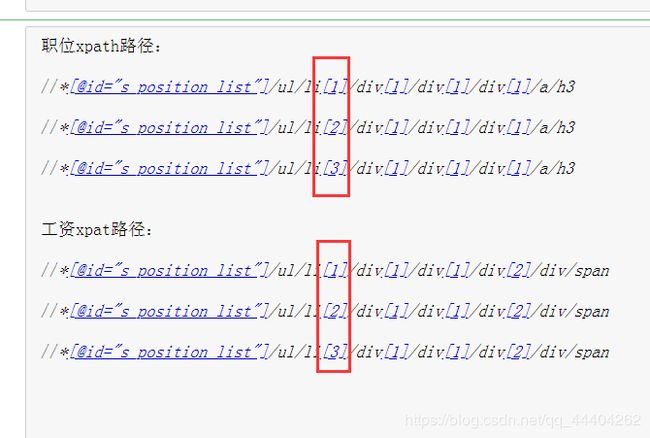
可用代码表示为:
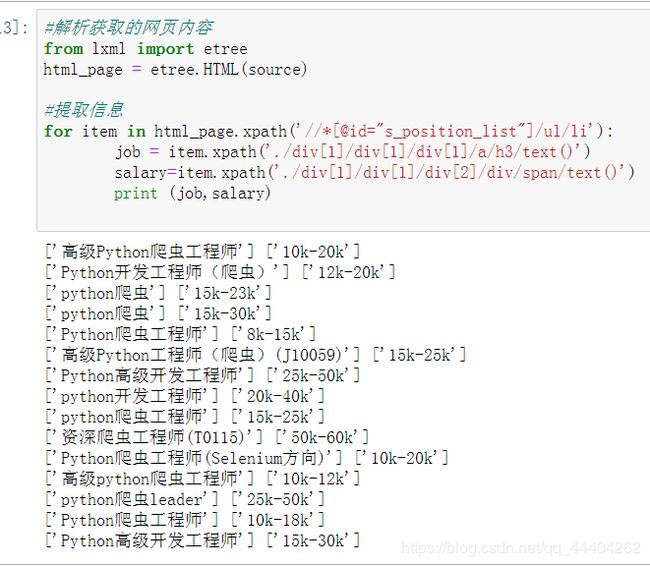
#提取信息
for item in html_page.xpath('//*[@id="s_position_list"]/ul/li'):
job = item.xpath('./div[1]/div[1]/div[1]/a/h3/text()')
salary=item.xpath('./div[1]/div[1]/div[2]/div/span/text()')
print (job,salary)
爬取第一页的内容:
2.2.2 翻页爬取
分析翻页数字的xpath路径,如红框所示,它的xpath路径没有规律,用last()表示翻页数字xpath路径的最后一个标签,表示为 :
//*[@id=“s_position_list”]/div[2]/div/span[last()]

代码汇总:
#导入包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#拉勾网链接
url=" https://www.lagou.com/"
#创建浏览器,打开拉勾网链接
driver = webdriver.Chrome()
driver.get(url)
#自动点击全国站
driver.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click()
#搜索框
search = driver.find_element_by_id('search_input')
#发送内容
search.send_keys('python 爬虫')
#停留3秒
time.sleep(3)
#点击搜索框
driver.find_element_by_id('search_button').click()
time.sleep(2)
#点击关闭红包
driver.find_element_by_xpath('/html/body/div[8]/div/div[2]').click()
#直接获取网页
source = driver.page_source
print (source)
#解析获取的网页内容
from lxml import etree
html_page = etree.HTML(source)
#提取信息
for item in html_page.xpath('//*[@id="s_position_list"]/ul/li'):
job = item.xpath('./div[1]/div[1]/div[1]/a/h3/text()')
salary=item.xpath('./div[1]/div[1]/div[2]/div/span/text()')
print (job,salary)
def main():
# 提取最大页
maxPage = driver.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[5]').text
print ("一共找到%s页"%maxPage)
#翻页爬取
for i in range(1,30):
print ("正在点击",(i+1))
driver.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[last()]').click()
time.sleep(2)
#程序入口
if __name__ =='__main__':
main()
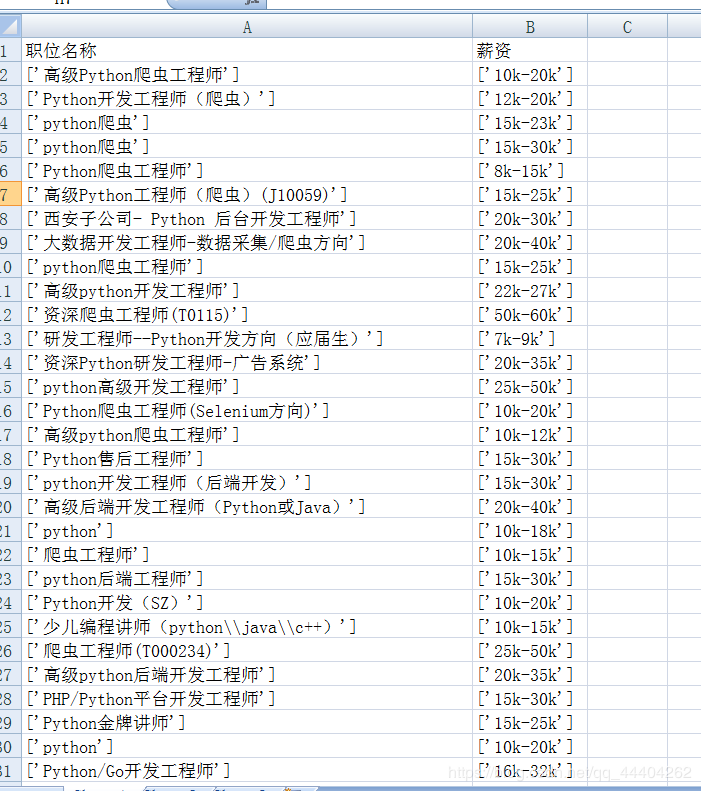
爬取结果:

3 将内容写入csv文件
import csv
#创建文件并打开
fp = open('拉勾网.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('职位名称','薪资'))
#写入数据
writer.writerow((job,salary))
fp.close() #关闭文件
4 selenium爬取拉勾网代码汇总
import time, csv
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#创建文件并打开
fp = open('拉勾网.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('职位名称','薪资'))
lagou_url = "https://www.lagou.com/"
#创建一个浏览器
driver = webdriver.Chrome()
driver.get(lagou_url) #打开网页
driver.find_element_by_xpath('//*[@id="changeCityBox"]/p[1]/a').click() #点击全国站
search = driver.find_element_by_id('search_input') #搜索框
search.send_keys('python 爬虫') #发送内容
time.sleep(2)
driver.find_element_by_id('search_button').click()
time.sleep(1)
driver.find_element_by_xpath('/html/body/div[8]/div/div[2]').click() #点击关闭红包
#提取信息
def spider_text():
source = driver.page_source#获取该网页源码
html_page = etree.HTML(source)
for item in html_page.xpath('//*[@id="s_position_list"]/ul/li'):
job = item.xpath('./div[1]/div[1]/div[1]/a/h3/text()')
salary = item.xpath('./div[1]/div[1]/div[2]/div/span/text()')
print (job, salary)
#写入数据
writer.writerow((job,salary))
# 翻页爬取
def main():
# 提取最大页
maxPage = driver.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[5]').text
print ("一共找到%s页"%maxPage)
for i in range(0, int(maxPage)):
spider_text()
print ("正在点击:", (i+2))
driver.find_element_by_xpath('//*[@id="s_position_list"]/div[2]/div/span[last()]').click()
time.sleep(2)
#程序入口
if __name__ =='__main__':
main()
fp.close() #关闭文件
爬取结果: