迁移学习︱艺术风格转化:Artistic style-transfer+ubuntu14.0+caffe(only CPU)
说起来这门技术大多是秀的成分高于实际,但是呢,其也可以作为图像增强的工具,看到一些比赛拿他作训练集扩充,还是一个比较好的思路。如何在caffe上面实现简单的风格转化呢?
好像网上的博文都没有说清楚,而且笔者也没有GPU机器,于是乎,走上了漫漫的研究逼死自己之路...
作者实践机器配置:
服务器:ubuntu16.04(8 core)+caffe+only CPU
突然觉得楷体是不是好看多了...哈哈,接下来的博客要改字体喽~
——————————————————————————————
一、图像风格迁移:image style transfer
本节内容来源于CDA深度学习课程,由唐宇迪老师所述,主要参考论文:《Image Style Transfer Using Convolutional Neural Networks》(下载链接)
训练模型要准备四样内容:
1、训练好的模型+参数,官方参考的是VGG16 VGG19、caffenet、googlenet四类,官方准备好下载链接;
2、一张style风格图,用来做模仿;
3、一张content内容图,即可。
4、一张底图N,用来准备改写图,一般都是拿content内容图来做,caffe里面默认也是拿内容图来作为底图。
来看到论文里面的内容,以及训练好一些图像模型,保持权重不变。怎么训练?
把style和content图都过卷积层(如上图),然后输出,不计算权重的loss,而是计算图片的loss。
保持权重不变了,那么训练的时候loss是什么?
算法使用随机的一个白噪声图(white noise image)作为输入,定义与内容图的content loss和风格图的`style loss’,之后使用标准的BP算法更新weight,调整输入的图像(白噪声图)
注意这里是调整输入的图,目的就是对于某个特定的输入图像x,其loss(包含content loss和style losss)达到最小
(参考博客:Image Style Transfer Using Convolutional Neural Network(理论篇))
那么现在loss改变为
loss=α(底图-风格图)+(1-α)(底图-内容图)=α(N-style)+(1-α)(N-content)
其中的参数α可以理解为转化比率,就是一张图可以长得多像风格图,默认为1e4。
这样就可以把两张图融合在一起,成为一张带有风格特点的图像。

二、caffe实现(单CPU)
本文不累述caffe+单CPU如何实现安装,都是在caffe可以使用的前提下进行后续。不明白可参考另外caffe+单CPU安装教程:caffe+CPU︱虚拟机+Ubuntu16.04+CPU+caffe安装笔记
1、实现前提
pycaffe是否可以使用?
答:来到caffe文件夹下的Python文件夹(./caffe/python),打开python 然后:import caffe
有报错:
如果是“no module caffe”的报错,修改一下环境变量:
- export PYTHONPATH=/caffe/python:$PYTHONPATH
2、style-transfer实现步骤
(1)github下载,style-transfer相关代码,下载链接;
(2)pycaffe环境布置,因为github上的代码是基于pycaffe的,所以需要配置python progressbar,
- pip install progressbar
(3)下载训练好模型,放在对的地方:
方法一:官方有下载链接,执行在\scripts 下的download_models.sh 就会出现下载
方法二:上面方法下载不了,可以直接用他们的链接下载:
googlenet:http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
caffenet:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
vgg16:http://www.robots.ox.ac.uk/~vgg/software/very_deep/caffe/VGG_ILSVRC_16_layers.caffemodel
vgg19:http://www.robots.ox.ac.uk/~vgg/software/very_deep/caffe/VGG_ILSVRC_19_layers.caffemodel都挺大的,VGG16就有500+MB,下载好了,还不行,还要注意,放在对的文件夹下:./model/vgg16
那么一个可以使用的训练好的模型文件夹有三样东西:ilsvrc_2012_mean.npy、VGG_ILSVRC_16_layers.caffemodel、VGG_ILSVRC_16_layers_deploy.prototxt
(4)运行模型
- python style.py -s <style_image> -c <content_image> -m <model_name> -g 0
要对应在style-transfer文件夹然后才执行上述代码才可以哟,才使用上述内容。
主要必须有的参数解析:
-s,风格图位置;
-c,内容图位置;
-m,模型位置;
-g,什么模式,-1为CPU,0为单个GPU,1为两个GPU。
其他默认或不必须参数:
parser.add_argument("-r", "--ratio", default="1e4", type=str, required=False, help="style-to-content ratio")
非必要,转化比率,有默认值,1e4,10^-4,0.00001
parser.add_argument("-n", "--num-iters", default=512, type=int, required=False, help="L-BFGS iterations")
非必要,有默认值,多少次会输出一次结果
3、风格/内容的比率ratio对结果的影响
比值越小合成的图风格化越明显(参考:Image Style Transfer Using Convolutional Neural Network(理论篇))

4、初始化方法对结果的影响(以风格图作为底图还是随机产生底图)
作者表示,扔入不同的底图方案都不会十分影响最后的结果。但是区别在于,如果你想一次性输出很多张图片的话,那么你就需要设置初始化为白噪声图,如果你一开始选择的就是内容图作为底图,那么这么多张图片都会长得一样,不具有其他分布了。
——————————————————————————————
三、网络上的案例
来自于网上:基于caffe的艺术迁移学习 style-transfer-windows+caffe
下面是运行代码的格式: python style.py -s
在windows下 切换到style.py 所在的目录,输入代码如下
python style.py -s images/style/starry_night.jpg -c images/content/nanjing.jpg -m vgg19 -g 0
可见上面例子中,style-image对应starry_night.jpg 即风格图像, content_image对应自己的照片nanjing.jpg, 模型选择vgg19, g 0对应选择默认的GPU,如果是g -1则为CPU
然后回车就能运行,得到上述结果了。 下面是运行的示意图:

可以看到,选择GPU、然后加载图像和模型成功后就开始跑了,左侧是显示运行进度,已经是6%,还需要54分钟左右,由于图像比较大,时间比较长。
网络上有人在titanX上合成图片,(参考:Image Style Transfer Using Convolutional Neural Network(理论篇))
一张140*480的图,迭代300次,在titan x上用时30s左右
——————————————————————————————
四、优化以及报错问题探究
1、报错一:
- 报错:WARNING: Logging before InitGoogleLogging() is written to STDERR
- F1226 22:43:57.664203 10578 common.cpp:66] Cannot use GPU in CPU-only Caffe: check mode.
2、报错二:显示不了进度条:Optimizing: 0% | | ETA: --:--:--
CPU太慢了,要等他一会,才能有时间估计...
3、优化一:为啥输出的图片都是512的呢?
系统默认的,你风格图+内容图是什么尺寸,输出的图片都是512.当然你可以修改参数来获得更大的尺寸。参考:基于caffe的艺术迁移学习 style-transfer-windows+caffe
更改style.py的一些内容:
parser.add_argument("-l", "--length", default=1024, type=float, required=False, help="maximum image length")
def transfer_style(self, img_style, img_content, length=1024, ratio=1e5,
n_iter=512, init="-1", verbose=False, callback=None)不更改的话,程序中默认输出是512宽度,和输入原始图像一致的宽长比。
——————————————————————————————
五、caffe在CPU环境下如何优化效率?
CPU运行caffe简直就是闹着玩一样...超级慢,自己的游戏笔记本,i7-6700HQ,单核合成一张图要25h... 要人命...
1、优化办法一:多核CPU
执行多CPU核操作,那么如何让caffe可以适应多个CPU一起用呢?笔者在网络上看了很多博文,基本在caffe配置中,就得进行修改。
来到caffe文件夹,make clean之后,可以用多线程加速(需要sudo?):
- make all -j4
- make test -j4
- make runtest -j4
(PS,而且好像-j4,利用4核是最优的方案,核心数用多了反而不好,会出现错误或者速度变慢,why??)
(PS,留言区大神(hr_999)给出解答:make all -j4的命令行参数-j4,真的只是针对make说的,意思是调用gcc的多线程编译而已。你仔细看,使用了-j4以后,编译的文件是不是以4个为一组进行的? 至于程序里面的多线程,涉及到的问题很多,绝不可能仅仅弄个命令行参数就能轻松开启
https://stackoverflow.com/questions/31395729/how-to-enable-multithreading-with-caffe?utm_medium=organic&utm_source=google_rich_qa&utm_campaign=google_rich_qa 要实现caffe的多线程计算,就要把默认的BLAS换成openBLAS)
执行如下命令编译 pycaffe:
- make pycaffe -j4
当然,在make pycaffe之后,还有网友有再执行make distribute的,不知道有没有用(深度学习工具caffe详细安装指南)
1、深度学习框架Caffe的编译安装
2、caffe配置与踩坑小结
3、开源深度学习框架Caffe在Ubuntu14.04下的搭建
2、优化办法二:caffe使用工具开启多线程:openblas-openmp(多线程版本)
Caffe用到的Blas可以选择Altas,OpenBlas,Intel MKL,Blas承担了大量了数学工作,所以在Caffe中Blas对性能的影响很大。 MKL要收费,Altas略显慢(在我的电脑上运行Caffe自带的example/mnist/lenet_solver.prototxt,大概需要45分钟。。。)
根据网上资料的介绍使用OpenBlas要快一些,于是尝试安装使用OpenBlas来加速训练过程。
用OpenBlas时,OPENBLAS_NUM_THREADS设置为最大,让CPU负载跑满,并不能大幅提高速度,这是为什么?一直没搞明白。
3、优化办法三——修改迭代次数
修改迭代次数。作者也说特别是CPU版本的caffe,减少迭代次数,是一个非常好的办法,因为cpu太慢了。。
作者分别尝试了 50, 100, 200, 400, and 800这样5中的迭代次数。
内容图和风格图是:

之后的效果是:
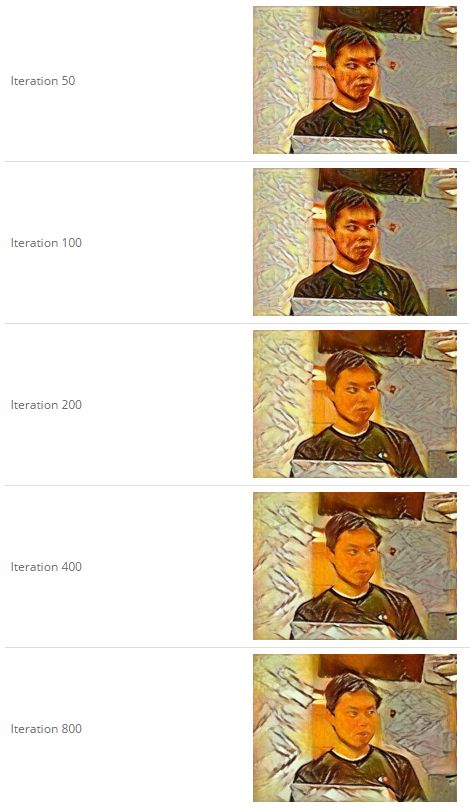
感觉50的已经差不多了,迭代越多,也就是背景纹理在改变。
——————————————————————————————
六、哪种训练模型比较好?
效率优化方面,因为不同的模型参数不一样,所以喽,你可以down一些比较小的模型也可以加速,不过其实不明显,还不如修改迭代次数来着更简单粗暴。
参考博客:Artistic style transfer

从外观来看,VGG模型效果比较好。caffeNet太丑,就没放,但是caffeNet是最快的(作者也是任性...)
googleNet比AlexNet参数少,网络还深,当然效果看起来,学得没VGG好。
——————————————————————————————————————————————
延伸一:Adobe 写实深度摄影风格迁移,局部仿射解决画面扭曲
用深度学习实现摄影风格迁移的方法,能够处理各种类型的图像,同时忠实地迁移参考风格。我们的方法建立在最近的通过考虑神经网络的不同层使画面内容分离,从而实现艺术风格转换的研究之上。但是,这种方法不适用于摄影作品的风格迁移。即使输入的图像和参考的图像都是摄影作品,其输出仍然表现出怪异的绘画特征。我们的贡献是将输入到输出的转换约束在色彩空间的局部仿射,并将这种约束表示为可以反向传播的自定义 CNN 层。
我们的结果表明,这种方法成功地抑制了画面的扭曲,并在各种场景中得到了令人满意的写实的摄影风格迁移,包括时间、天气、季节的改变和艺术性编辑。
为了实现这一结果,我们必须解决两个根本性的挑战。一是结构保存(structure preservation),解决这一难题使我们实现了将摄影照片与绘画区分开来。第二个挑战是语义准确性和迁移忠实度(Semantic accuracy and transfer faithfulness)。现实世界中场景的复杂性提出了这一挑战,即迁移应该忠实于场景语义。例如,在城市风景照片中,建筑物的外观应该是建筑物,天空是天空,假如风格迁移之后天空看起来像建筑物是不可接受的。我们将输入图像和参考风格图像的语义标签纳入迁移过程,以便子区域之间的迁移得到语义上的等效,并且每个语义之间的映射接近均匀。我们的结果显示,该算法保留了所需风格的丰富性,并防止了外溢。如图2所示。
来源文章《Adobe 写实深度摄影风格迁移,局部仿射解决画面扭曲》
——————————————————————————————————————————————
延伸二:图像风格迁移(Neural Style)简史
图像风格迁移带来的商业化启迪主要来源知乎文章
Gatys发现纹理能够描述一个图像的风格。严格来说文理只是图片风格的一部分,但是不仔细研究纹理和风格之间的区别的话,乍一看给人感觉还真差不多。
每个风格的算法都是各管各的,互相之间并没有太多的共同之处。比如油画风格迁移,里面用到了7种不同的步骤来描述和迁移油画的特征。又比如头像风格迁移里用到了三个步骤来把一种头像摄影风格迁移到另一种上。以上十个步骤里没一个重样的,可以看出图像风格处理的研究在2015年之前基本都是各自为战,捣鼓出来的算法也没引起什么注意。相比之下Photoshop虽然要手动修图,但比大部分算法好用多了。
最新的实时任意风格迁移算法之一,生成时间:少于10秒(少于一秒的算法也有,但个人认为看上去没这个好看),训练时间:10小时
