opencv+Recorder︱OpenCV 中的 Canny 边界检测+轮廓、拉普拉斯变换
本文来自于段力辉 译《OpenCV-Python 中文教程》
边缘检测是图像处理和计算机视觉中的基本问题,通过标识数字图像中亮度变化明显的点,来捕捉图像属性中的显著变化,包括深度上的不连续、表面方向的不连续、物质属性变化、和场景照明变化。
.
零、边缘检测年度进展
由南开大学的程明明副教授所述,所做摘录。
.
1、传统的边缘检测的进展
图像边缘检测能够大幅减少数据量,在保留重要的结构属性的同时,剔除弱相关信息。
在深度学习出现之前,传统的Sobel滤波器,Canny检测器具有广泛的应用,但是这些检测器只考虑到局部的急剧变化,特别是颜色、亮度等的急剧变化,通过这些特征来找边缘。
这些特征很难模拟较为复杂的场景,如伯克利的分割数据集(Berkeley segmentation Dataset),仅通过亮度、颜色变化并不足以把边缘检测做好。2013年,开始有人使用数据驱动的方法来学习怎样联合颜色、亮度、梯度这些特征来做边缘检测。
为了更好地评测边缘检测算法,伯克利研究组建立了一个国际公认的评测集,叫做Berkeley Segmentation Benchmark。从图中的结果可以看出,即使可以学习颜色、亮度、梯度等low-level特征,但是在特殊场景下,仅凭这样的特征很难做到鲁棒的检测。比如上图的动物图像,我们需要用一些high-level 比如 object-level的信息才能够把中间的细节纹理去掉,使其更加符合人的认知过程(举个形象的例子,就好像画家在画这个物体的时候,更倾向于只画外面这些轮廓,而把里面的细节给忽略掉)。
.
2、深度学习与边缘检测
传统的基于特征的方法,最好的结果只有0.7,这很大程度上是因为传统的人工设计的特征并没有包含高层的物体级别信息,导致有很多的误检。因而研究者们尝试用卷积神经网络CNN,探索是否可以通过内嵌很多高层的、多尺度的信息来解决这一问题。
有很多基于CNN的方法的工作。这里从2014 ACCV N4_Fields开始说起。
- N4-Fields:
如何从一张图片里面找边缘?我们会想到计算局部梯度的大小、纹理变化等这些直观的方法。其实N4-Fields这个方法也很直观,图像有很多的patch,用卷积神经网络(CNN)算出每个patch的特征,然后在字典里面进行检索,查找与其相似的边缘,把这些相似的边缘信息集成起来,就成了最终的结果,可以看到,由于特征更加强大了,结果有了较好的提升。
- DeepEdge:
发表在CVPR 2015的DeepEdge对上述工作进行了扩展,首先使用Canny edge得到候选轮廓点,然后对这些点建立不同尺度的patch,将这些 patch 输入两路的CNN,一路用作分类,一路用作回归。最后得到每个候选轮廓点的概率。
DeepContour:
这是CVPR2015中的另一个工作,该工作还是基于patch的。首先在图像中寻找patch,然后对patch 做多类形状分类,来判断这个边缘是属于哪一类的边缘,最后把不同类别的边缘融合起来得到最终的结果。
HFL
ICCV 2015的工作High-for-Low (HFL)也用CNN对可能的候选轮廓点进行判断。由于使用了经过高层语义信息训练得到的VGG Net,在一定程度上用到了高层语义信息,因此取得了不错的结果。
由上图结果可以看出,这些工作虽然取得了一些进展,但是离人类的表现还有很大的差距。 这些方法的缺点在于都是基于局部策略所做的结果,每次只看一个区域,即只针对一个patch,并没有很充分的利用高层级的信息。
Holistically-Nested Edge Detection:
Holistically-Nested Edge Detection 是屠卓文教授课题组在ICCV 2015 的工作。该工作最大的亮点在于,一改之前边缘检测方法基于局部策略的方式,而是采用全局的图像到图像的处理方式。即不再针对一个个patch进行操作,而是对整幅图像进行操作,为高层级信息的获取提供了便利。
与此同时,该方法使用了multi-scale 和multi-level, 通过groundtruth的映射在卷积层侧边插入一个side output layer,在side output layer上进行deep supervision,将最终的结果和不同的层连接起来。
RCF:
接下来,介绍的是程明明副教授课题组CVPR2017的工作。其实想法很简单,一句话就能概括,由于不同卷积层之间的信息是可以互补的,传统方法的问题在于信息利用不充分,相当于只使用了Pooling前最后一个卷积层的信息,如果我们使用所有卷积层的信息是不是能够更好的利用卷积特征,进而得到更好的结果?
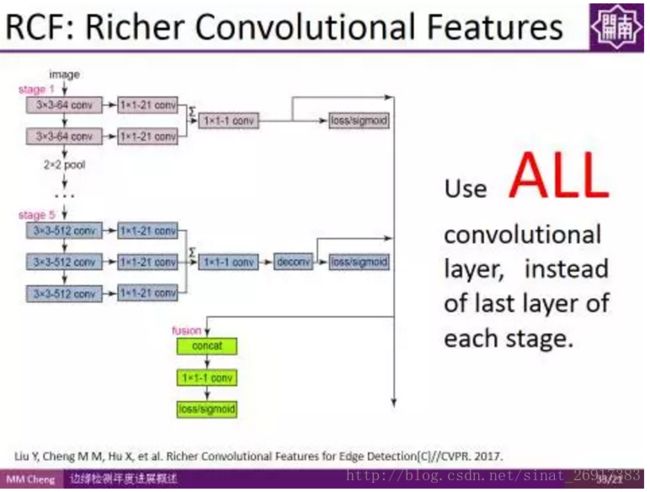
使用所有卷积层的信息,而不是池化之前的最后一层,这样一个非常简单的改变,使得检测结果有了很大的改善。这种方法也有望迁移到其他领域。
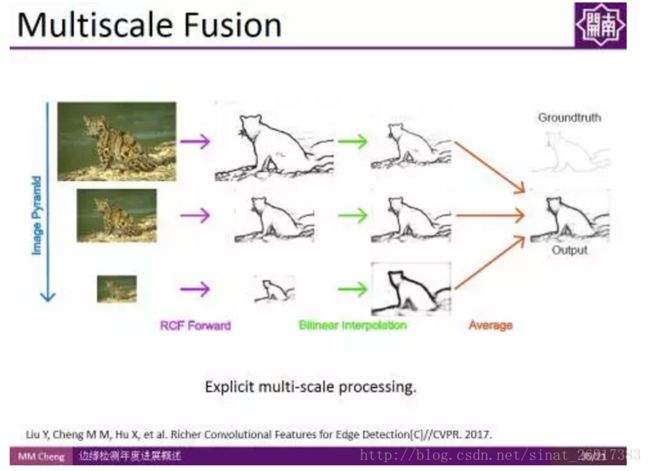
实验结果表明,虽然卷积神经网络自带多尺度特征,但显式地使用多尺度融合对边缘检测结果的提升依然有效。

该方法操作简单,且不明显增加计算时间,虽然代码量少,但在BSDS500数据集上的结果甚至超过人类标注者的平均表现水平,而且在Titan X上能够达到实时检测速度(30fps)。
这部分代码是开源的,可通过访问如下网址获得: https://github.com/yun-liu/rcf。
文中提到所有文章的下载链接为:http://pan.baidu.com/s/1jHLdyIU
.
一、Canny 边缘检测理论
Canny 边缘检测是一种非常流行的边缘检测算法,是 John F.Canny 在1986 年提出的。它是一个有很多步构成的算法,我们接下来会逐步介绍。
1、噪声去除
由于边缘检测很容易受到噪声影响,所以第一步是使用 5x5 的高斯滤波器去除噪声。
.
2、计算图像梯度
对平滑后的图像使用 Sobel 算子计算水平方向和竖直方向的一阶导数(图像梯度)(Gx 和 Gy)。根据得到的这两幅梯度图(Gx 和 Gy)找到边界的梯度和方向,公式如下:
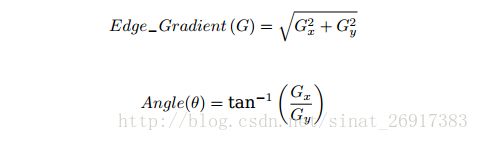
梯度的方向一般总是与边界垂直。梯度方向被归为四类:垂直,水平,和两个对角线。
.
3、非极大值抑制
在获得梯度的方向和大小之后,应该对整幅图像做一个扫描,去除那些非边界上的点。对每一个像素进行检查,看这个点的梯度是不是周围具有相同梯度方向的点中最大的。如下图所示:
现在你得到的是一个包含“窄边界”的二值图像。
.
4、滞后阈值
现在要确定那些边界才是真正的边界。这时我们需要设置两个阈值:minVal 和 maxVal。
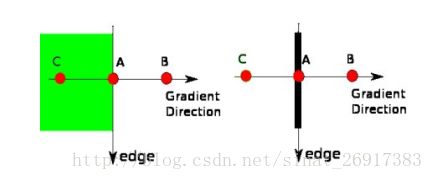
当图像的灰度梯度高于 maxVal 时被认为是真的边界,那些低于 minVal 的边界会被抛弃。如果介于两者之间的话,就要看这个点是否与某个被确定为真正的边界点相连,如果是就认为它也是边界点,如果不是
就抛弃。如下图:
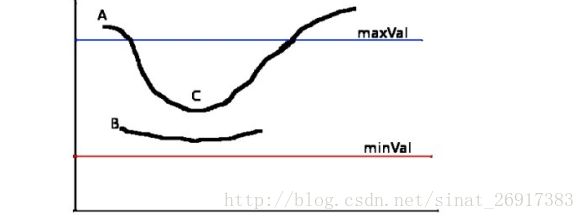
A 高于阈值 maxVal 所以是真正的边界点, C 虽然低于 maxVal 但高于minVal 并且与 A 相连,所以也被认为是真正的边界点。而 B 就会被抛弃,因为他不仅低于 maxVal 而且不与真正的边界点相连。所以选择合适的 maxVal和 minVal 对于能否得到好的结果非常重要。
在这一步一些小的噪声点也会被除去,因为我们假设边界都是一些长的线段。
.
二、OpenCV 中的 Canny 边界检测
在 OpenCV 中只需要一个函数: cv2.Canny(),就可以完成以上几步。让我们看如何使用这个函数。这个函数的第一个参数是输入图像。第二和第三个分别是 minVal 和 maxVal。第三个参数设置用来计算图像梯度的 Sobel卷积核的大小,默认值为 3。最后一个参数是 L2gradient,它可以用来设定求梯度大小的方程。如果设为 True,就会使用我们上面提到过的方程,否则使用方程: Edge−Gradient(G) = jG2 xj + jG2 yj 代替,默认值为 False。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
edges = cv2.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()
.
三、OpenCV 中的轮廓
1、概念
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。
• 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理或者 Canny 边界检测。
• 查找轮廓的函数会修改原始图像。如果你在找到轮廓之后还想使用原始图像的话,你应该将原始图像存储到其他变量中。
• 在 OpenCV 中,查找轮廓就像在黑色背景中超白色物体。你应该记住,要找的物体应该是白色而背景应该是黑色。
让我们看看如何在一个二值图像中查找轮廓:函数 cv2.findContours() 有三个参数,第一个是输入图像,第二个是轮廓检索模式,第三个是轮廓近似方法。
返回值有三个,第一个是图像,第二个是轮廓,第三个是(轮廓的)层析结构。轮廓(第二个返回值)是一个 Python列表,其中存储这图像中的所有轮廓。每一个轮廓都是一个 Numpy 数组,包含对象边界点(x, y)的坐标。
.
2、怎样绘制轮廓
函数 cv2.drawContours() 可以被用来绘制轮廓。它可以根据你提供的边界点绘制任何形状。它的第一个参数是原始图像,第二个参数是轮廓,一个 Python 列表。第三个参数是轮廓的索引(在绘制独立轮廓是很有用,当设置为 -1 时绘制所有轮廓)。接下来的参数是轮廓的颜色和厚度等。
在一幅图像上绘制所有的轮廓:
import numpy as np
import cv2
im = cv2.imread('test.jpg')
imgray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(imgray,127,255,0)
image, contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)绘制独立轮廓,如第四个轮廓:
img = cv2.drawContour(img, contours, -1, (0,255,0), 3)但是大多数时候,下面的方法更有用:
img = cv2.drawContours(img, contours, 3, (0,255,0), 3).
3、轮廓的近似方法
这是函数 cv2.findCountours() 的第三个参数。它到底代表什么意思呢?
上边我们已经提到轮廓是一个形状具有相同灰度值的边界。它会存贮形状边界上所有的 (x, y) 坐标。但是需要将所有的这些边界点都存储吗?这就是这个参数要告诉函数 cv2.findContours 的。
这个参数如果被设置为 cv2.CHAIN_APPROX_NONE,所有的边界点都会被存储。但是我们真的需要这么多点吗?例如,当我们找的边界是一条直线时。你用需要直线上所有的点来表示直线吗?不是的,我们只需要这条直线的两个端点而已。这就是 cv2.CHAIN_APPROX_SIMPLE 要做的。它会将轮廓上的冗余点都去掉,压缩轮廓,从而节省内存开支。
我们用下图中的矩形来演示这个技术。在轮廓列表中的每一个坐标上画一个蓝色圆圈。第一个图显示使用 cv2.CHAIN_APPROX_NONE 的效果,一共 734 个点。第二个图是使用 cv2.CHAIN_APPROX_SIMPLE 的结果,只有 4 个点。看到他的威力了吧!

.
4、轮廓特征
(1)矩
图像的矩可以帮助我们计算图像的质心,面积等。详细信息请查看维基百科Image Moments。
函数 cv2.moments() 会将计算得到的矩以一个字典的形式返回。如下:
import cv2
import numpy as np
img = cv2.imread('star.jpg',0)
ret,thresh = cv2.threshold(img,127,255,0)
contours,hierarchy = cv2.findContours(thresh, 1, 2)
cnt = contours[0]
M = cv2.moments(cnt)
print M(2)对象的重心
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])(3)轮廓面积
轮廓的面积可以使用函数 cv2.contourArea() 计算得到,也可以使用矩
(0 阶矩), M[‘m00’]。
area = cv2.contourArea(cnt)(4)轮廓周长
也被称为弧长。可以使用函数 cv2.arcLength() 计算得到。这个函数的第二参数可以用来指定对象的形状是闭合的(True),还是打开的(一条曲线)。
perimeter = cv2.arcLength(cnt,True).
四、拉普拉斯变换
1、理论以及opencv的函数
拉普拉斯变换也可以用作边缘检测,用二次导数的形式定义。
拉普拉斯变换(Laplace Transform),是工程数学中常用的一种积分变换。
计算图像的 Laplacian 变换
void cvLaplace( const CvArr* src, CvArr* dst, int aperture_size=3 );- src
输入图像.
- dst
输出图像.
- aperture_size
核大小 (与 cvSobel 中定义一样).
函数 cvLaplace 计算输入图像的 Laplacian变换,方法是先用 sobel 算子计算二阶 x- 和 y- 差分,再求和:
对 aperture_size=1 则给出最快计算结果,相当于对图像采用如下内核做卷积:
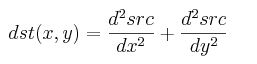
类似于 cvSobel 函数,该函数也不作图像的尺度变换,所支持的输入、输出图像类型的组合和cvSobel一致。
Sobel导数
cvSobel(img,dst,0,1,3);
拉普拉斯变换
cvLaplace(img, dst, 3); 一个通常的应用是检测“团块”。联想到拉普拉斯算子的形式是沿着x轴和y轴的二次导数的和,这就意味着周围是更高值的单点或者小块(比中孔小)会将使这个函数值最大化。反过来说,周围是更低值的点将会使函数的负值最大化。
基于这种思想,拉普拉斯算子也可以用作边缘检测。为达此目的,只需要考虑当函数快速变化时其一阶导数变大即可。同样重要的是,当我们逼近类似边缘的不连续地方时导数会快速增长,而穿过这些不连续地方时导数又会快速减小。所以导数会在此范围内有局部极值。这样我们可以期待局部最大值位于二阶导数为0的地方。
原始图像的边缘位于拉普拉斯的值等于0的地方。不幸的是,在拉普拉斯算子中,所有实质性的和没有意义的边缘的检测都是0.但这并不是什么问题,因为我们可以过滤掉这些点,它们的一阶(sobel)导数值也很大。
(参考:第六章 - 图像变换 -拉普拉斯变换(cvLaplace))
.
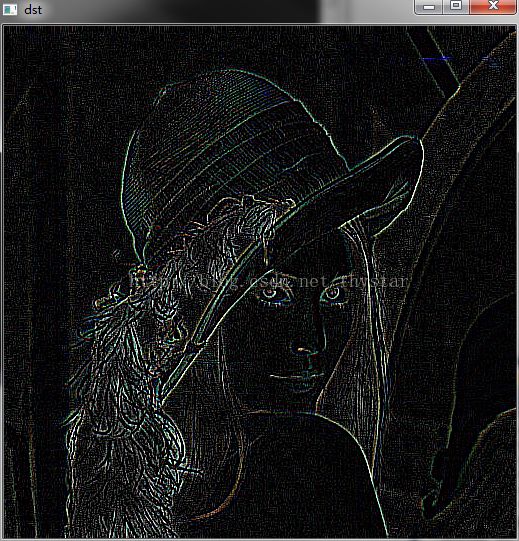
2、Sobel、拉普拉斯变换 、Canny三者的边缘检测效果
分别是:Sobel、拉普拉斯变换 、Canny的效果图。参考来自:OpenCV入门(十四)– Sobel导数,拉普拉斯变换和 Canny算子


.
3、拉普拉斯变换 与其他算法的关系
(1)与Sobel
拉普拉斯算子可以用二次导数的形式定义,可假设其离散实现类似于二阶Sobel导数
(2)与Canny
与拉普拉斯算法不同,Canny算法中,首先在x和y方向求一阶导数, 然后组合为四个方向的导数。这些方向导数达到局部最大值的点就是组成边缘的候选点。
Canny算法最重要的特点是其试图将独立边的候选像素拼装成轮廓。
(3)傅里叶变换、拉普拉斯变换、Z变换
傅里叶分析包含傅里叶级数与傅里叶变换。傅里叶级数用于对周期信号转换,傅里叶变换用于对非周期信号转换。但是对于不收敛信号,傅里叶变换无能为力,只能借助拉普拉斯变换。(主要用于计算微分方程)而z变换则可以算作离散的拉普拉斯变换。(主要用于计算差分方程)从复平面来说,傅里叶分析直注意虚数部分,拉普拉斯变换则关注全部复平面,而z变换则是将拉普拉斯的复平面投影到z平面,将虚轴变为一个圆环。(不恰当的比方就是那种一幅画只能通过在固定位置放一个金属棒,从金属棒反光才能看清这幅画的人物那种感觉。)
作者:Heinrich 来 源:知乎
链接:https://www.zhihu.com/question/22085329/answer/20258145
.
4、拉普拉斯变换做模糊检测
来源于:用 Opencv 和 Python 对汪星人做模糊检测
cv2.Laplacian(image, cv2.CV_64F).var()也就是拉普拉斯变换的方差,计算方差(即标准差的平方)。
这种方法凑效的原因就在于拉普拉斯算子定义本身。它被用来测量图片的二阶导数,突出图片中强度快速变化的区域,和 Sobel 以及 Scharr 算子十分相似。并且,和以上算子一样,拉普拉斯算子也经常用于边缘检测。
此外,此算法基于以下假设:如果图片具有较高方差,那么它就有较广的频响范围,代表着正常,聚焦准确的图片。但是如果图片具有有较小方差,那么它就有较窄的频响范围,意味着图片中的边缘数量很少。正如我们所知道的,图片越模糊,其边缘就越少。
很显然,此算法的技巧在于设置合适的阈值。然而,阈值却十分依赖于所应用的领域。阈值太低会导致正常图片被误断为模糊图片,阈值太高会导致模糊图片被误判为正常图片。这种方法在能计算出可接受清晰度评价值的范围的环境中趋于发挥作用,能检测出异常照片。

案例一则:
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian(image):
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2.Laplacian(image, cv2.CV_64F).var()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
ap.add_argument("-t", "--threshold", type=float, default=100.0,
help="focus measures that fall below this value will be considered 'blurry'")
args = vars(ap.parse_args())