Python一键爬取你所关心的书籍信息
平时看到的豆瓣爬虫基本都是爬豆瓣top100电影、某电影热评、top100图书、热门图书等,最近遇到的一个需求是根据一堆书名的列表(或者书名Excel文件)爬取对应的书目信息,也就是豆瓣图书页面上的出版社、出版时间、ISBN、定价、评分、评分人数等信息,再整合到pandas里进行处理,最后可以进行数据分析。
需求来源
最近整理书目的时候需要根据几百本书的书名整理出对应的出版社、出版时间、ISBN、评分等属性,书单Excel如下图1中的表。批量处理肯定是用爬虫啦,查了一下没有发现相似的文章,并且自己操作时也遇到了比较有趣的问题,于是把自己的操作思路和过程整理成本文。
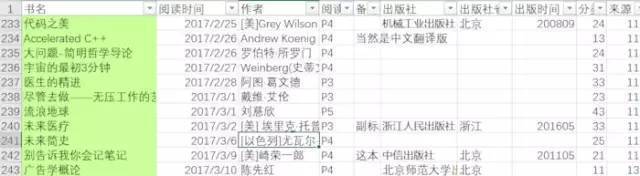
图1,书单数据部分截图
爬取过程
页面分析
首先分析豆瓣图书首页:book.douban.com,直接搜索书名时可以看到搜索参数是写在url上的,于是想着直接用https://book.douban.com/subject_search?search_text={0}&cat=1001'.format('书名'),直接改search_text参数,在这个页面按F12调出控制台,失望的是这个url返回的html是不含数据的,如图2。关键是找了一段时间还是没找到异步返回的数据json(如果有人找到了豆瓣subject_search?search_text={0}&cat=1001这类页面的书籍数据的位置欢迎告诉我呀),这时候考虑用Selenium或者查其他接口。
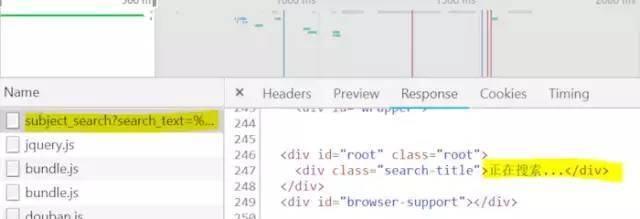
图2,基于搜索url的html截图
json分析
注意到豆瓣图书的搜索页面有一个搜索提示,于是在控制台查Network发现搜索提示返回的直接是一个json,例如查“未来简史”,结果如下:
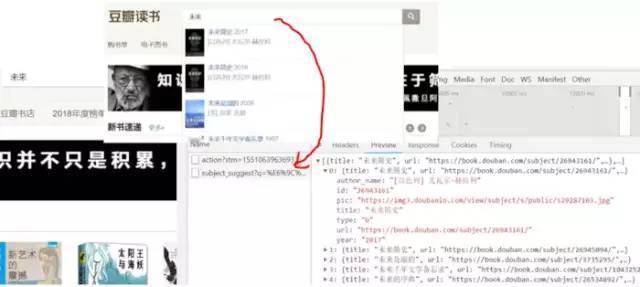
图3,未来简史搜索提示
返回json可以用的属性有:title:书名、url:对应书的豆瓣页面、pic:书封面图资源位置等。如果上面的输入咱们只有书名,就根据书名和返回的json对应,如果有作者、出版年份等属性,就可以更好的核对是否是我们要找的书,为了简化,下面只用了返回json数据的第1条。
基本代码
根据返回的url就可以从这个url去定位我们需要爬的信息。走通了就可以正式写代码了,以下代码采用jupyter notebook的组织方式,也就是切分得比较细。先引入所需库:
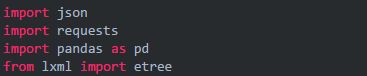
读取书名Excel数据,只用了"书名"列,先不考虑其他列
对书名列表进行循环,得到的属性用字典装着,每本书的属性是一个字典,用列表装各个字典。
通过requests.get('https://book.douban.com/j/subject_suggest?q={0}'.format(bn))获取搜索建议返回的json数据,其中bn是书名字符串。
爬虫的一般解析是用BeautifulSoup或xpath,我更喜欢用xpath,因此下面的代码主要基于xpath解析文本。
以评分为例,鼠标点击评分部分,然后按Ctrl+Shift+I,或者右键点击检查元素,反正就是定位到评分对应的HTML上,定位到评分的代码部分后,右键,选择Copy->Copy XPath,例如对于评分来说有:
//*[@id="interest_sectl"]/div/div[2]/strong。
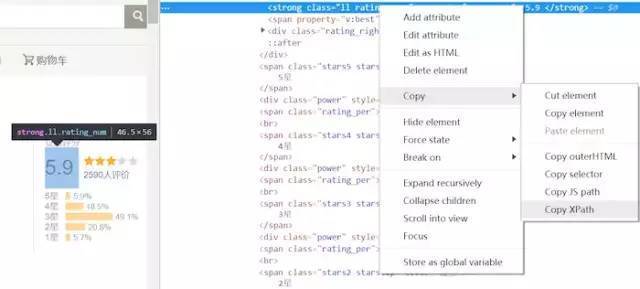
图4,复制评分的xpath
通过con.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')就可以得到评分数据,返回的是列表,一般就是第0个值。同样,其他地方也是这样,而作者、出版社那几个属性是结构比较散的,需要特殊处理。
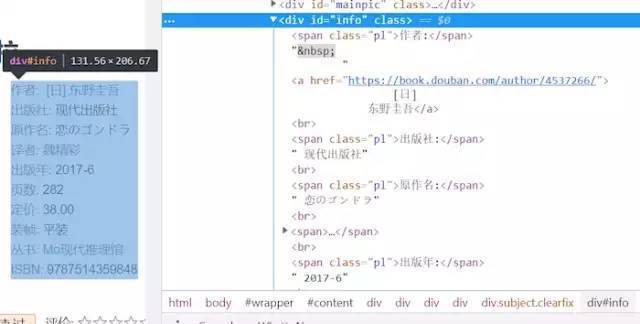
图5,自由度较大的书目信息部分
通过//*[@id="info"]/span[2]可以确定 出版社 这个属性,但是属性的值,具体是哪个出版社不能确定,这些文字是在info这个节点上的。对于这种长度不定的一个html区域,不能写死xpath解析式,需要理清其HTML树结构,建立info的树结构。通过分析几个具体的页面的info部分,建立树结构如下:
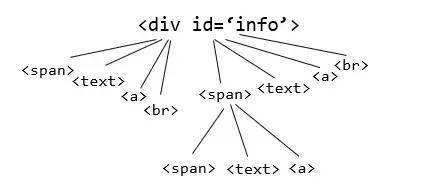
图6,info部分的HTML树
需要得到的是{'出版社’:'中信出版集团'}这样的数据,通过HTML树结构可以看到的特征是键(如出版社)在span里,值可能在text里,也可能封装在span里的子元素里,反正每个键值对之后都有一个br去切分。考虑这些情况写出的代码如下:
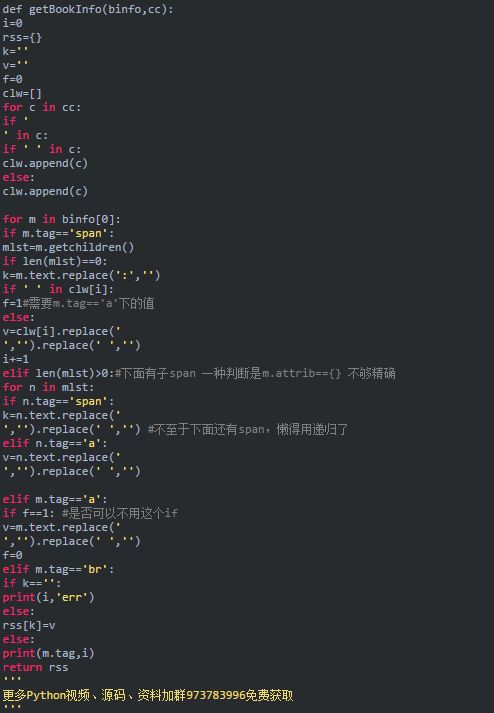
为了在大循环里好调用,上面的部分封装成函数,调用getBookInfo()返回的是一个字典,要整合到已有的字典里。涉及字典的组合,查了一下可以用d=dict(d,**dw),其中d是旧字典,dw是要加到d里的新字典,更简便的方式是用d.update(dw)函数,下面的代码就是用的update的。
主循环代码:
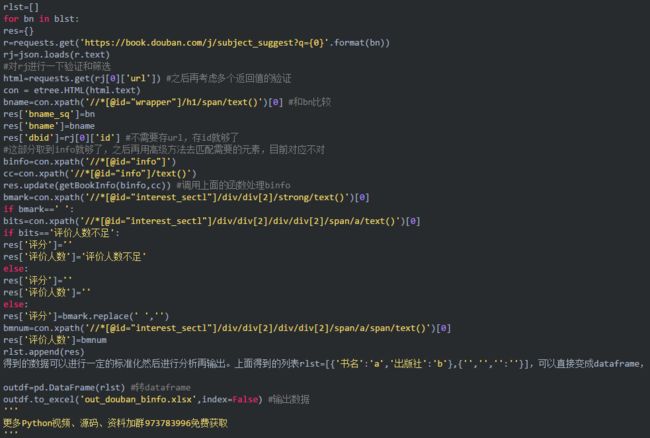
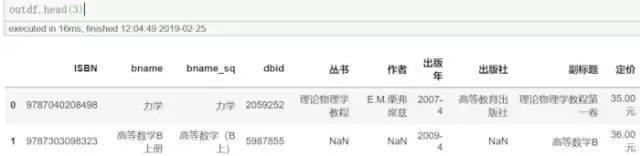
图7,爬到的数据概览
基础数据统计分析
我们开始时读入的bsdf有书名、作者、阅读时间等属性,因为爬下来的数据可能会有缺失值,将两个表合并起来进行分析。分析的维度有书名、作者、阅读时间、出版社、页数等。首先是用merge整合两表然后看一些基本的统计量。

输出是一共有421本书,309个作者,97个出版社;
我们就来看看前几位的作者和出版社,通过
bdf['作者'].value_counts().head(7)可以输出前7位书单里出现最多的作者,出版社同理,结果如下:
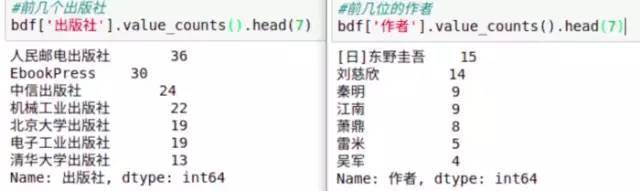
图8,出版社和作者统计
从作者出现次数来看,前6位都是小说类型的书,可以看一下吴军的是哪些书:
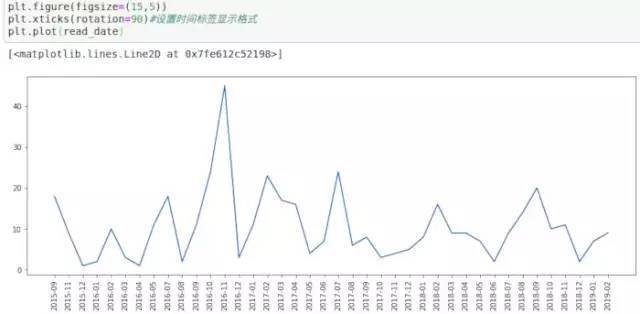
图9,每月阅读数量_时间轴折线图.png
好奇不同年份每个月是否有一定规律呢。要统计这个比较方便的就是用数据透视表了,pandas里的pivot_table出场。
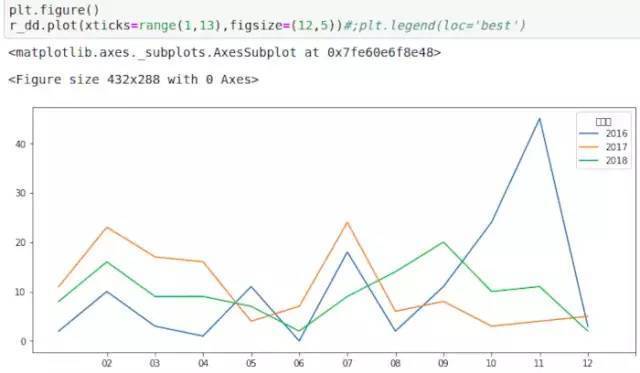
图10,每月阅读数量_按年统计
可以看到这3年在2月和7月阅读普遍数量更多,在7月份之前每月阅读量是逐年上涨的,而从8月到12月则是递减的规律,2016年11月阅读的书籍最多,达到40本以上。
评分是一个数值型变量,用箱线图[图片上传中...(图12_书单内数据相关的书籍.png-5352ab-1551272966564-0)]
展现其特征:
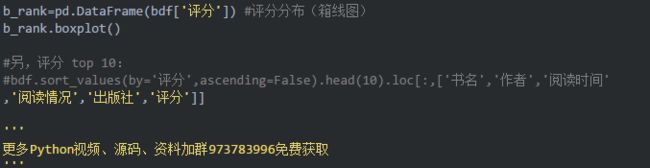
图11,书籍评分箱线图
从箱线图来看,书单有评分的书籍的豆瓣平均分在7.8左右,75%的书评分在7.2以上,也有一些书是在4分一下的。
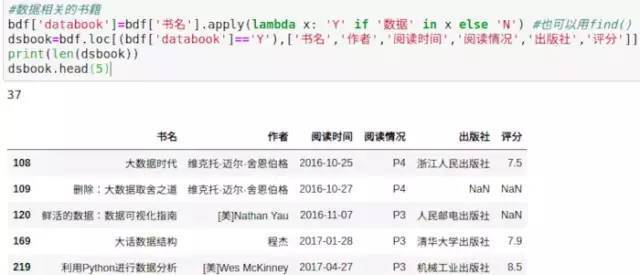
图12,书单内数据相关的书籍
书单里书名直接包含数据的书有37本,数据科学相关的书籍数量应该大于这个值。
可以进一步分析的有:
看的书的书名词云、作者的词云
出版社省份
把字数统计和爬下来的页数进行拟合,把字数和页数一起处理
把含有多国货币的价格属性按汇率换算后看价格的分布
数据输出
上面通过一个具体的需求实践了能解决问题的爬虫,豆瓣还是比较容易爬的,上面解析书目信息的做法还是很有意义的,当然我是用xpath做的,如果用BeautifulSoup又会是另一种实现方式,但分析问题->建立HTML树的过程是通用的。上面的代码还是比较简略的,没有考虑过多的验证和异常处理,有任何意见或建议欢迎交流。