运行第一个MapReduce程序
本文的环境基于CDH5的搭建https://blog.csdn.net/songzehao/article/details/91044032
大数据环境CDH5已搭建成功,自带example也已跑通,总不能老跑人家的mapreduce程序吧,所以是时候跑跑自己写的mr了。
怎么写程序先不管,我们先本着拿来主义,或者好听一点说师夷长技以制夷,第一步只是为了成功走完部署运行jar包的流程,至于怎么实现mr,留到后面的步骤再去研究。所以,先用jdgui反编译hadoop自带的示例jar(/opt/cloudera/parcels/CDH-5.7.2-1.cdh5.7.2.p0.18/jars/hadoop-examples.jar),找到WordCount.class,拷贝出Java源码,放到自己新建的一个普通Java Project中,发现代码很多报错,原因是少jar包,hadoop编程需要哪些jar包,如下:
- hadoop-client-3.2.0.jar
- hadoop-common-3.2.0.jar
- hadoop-hdfs-3.2.0.jar
- hadoop-mapreduce-client-core-3.2.0.jar
- commons-cli-1.2.jar
如下给出各自pom依赖:
org.apache.hadoop
hadoop-common
3.2.0
org.apache.hadoop
hadoop-hdfs
3.2.0
org.apache.hadoop
hadoop-mapreduce-client-core
3.2.0
org.apache.hadoop
hadoop-client
3.2.0
commons-cli
commons-cli
1.2
导入jar包后,代码已不报错,接下来准备生成jar包,方式有很多种,包括在Maven项目中用mvn命令打包等等。
第一种简便的方式,可以直接在Eclipse中Export为JAR FILE;
另一种方式使用javac命令编译,并使用jar命令打包,如下:
E:\J2EE_workspace\Test\src>javac -cp .;D:\maven-repository\commons-cli\commons-cli\1.2\commons-cli-1.2.jar;D:\maven-repository\org\apache\hadoop\hadoop-client\3.2.0\hadoop-client-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-common\3.2.0\hadoop-common-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-hdfs-client\3.2.0\hadoop-hdfs-client-3.2.0.jar;D:\maven-repository\org\apache\hadoop\hadoop-mapreduce-client-core\3.2.0\hadoop-mapreduce-client-core-3.2.0.jar WordCount.java
E:\J2EE_workspace\Test\src>jar -cvf wc3.jar *.class
已添加清单
正在添加: WordCount$IntSumReducer.class(输入 = 1739) (输出 = 739)(压缩了 57%)
正在添加: WordCount$TokenizerMapper.class(输入 = 1736) (输出 = 754)(压缩了 56%)
正在添加: WordCount.class(输入 = 3037) (输出 = 1619)(压缩了 46%)
将生成的wc3.jar从本地上传到任一集群节点,考虑到主节点(10.1.4.18/b3/bi-zhaopeng03)起的服务太多导致OOM,所以这里将其放到一agent从节点(10.1.4.19/b4/bi-zhaopeng04)上的目录/root/songzehao/data下:
[root@bi-zhaopeng04 data]# pwd
/root/songzehao/data
[root@bi-zhaopeng04 data]# ll
总用量 16
-rwxrwxrwx 1 root root 90 6月 11 15:46 test.sh
-rwxrwxrwx 1 hdfs hdfs 4261 6月 11 18:26 wc3.jar
-rw-r--r-- 1 root root 61 6月 11 10:29 words.txt
接下来要为wordcount程序创建一个文本文件words.txt,然后上传至hdfs上的某文件/tmp/songzehao/words_input上。
words.txt内容如下:
[root@bi-zhaopeng04 data]# cat /root/songzehao/data/words.txt
szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn
上传至hdfs指定文件/tmp/songzehao/words_input中:
[root@bi-zhaopeng04 data]# pwd
/root/songzehao/data
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop fs -put words.txt /tmp/songzehao/words_input
put: `words.txt': No such file or directory
结果报错put: `words.txt': No such file or directory,注意这里不可以sudo –u hdfs,不然会报错说没有这个文件。奇怪了,明明有这个文件,路径也没问题,究竟是什么原因呢?这是因为Linux系统的用户权限机制导致,也就是说hdfs用户没有权限去操作/root/songzehao/data/words.txt或没有权限去打开此文件的所有上级目录,所以遇到Linux环境下的文件不存在或找不到的问题,应当重点排查用户是否有足够权限。不妨做个实验,我们切换到hdfs用户下,尝试去访问/root目录,可以发现hdfs并无权限访问/root:
[root@bi-zhaopeng04 data]# su hdfs
上一次登录:三 6月 12 09:55:44 CST 2019pts/1 上
[root@bi-zhaopeng04 data]$ ll /root
ls: 无法打开目录/root: 权限不够
所以,我们以一个能操作此文件的Linux用户去执行hadoop put即可,可以看到内容也与words.txt一致:
[root@bi-zhaopeng04 data]# hadoop fs -put words.txt /tmp/songzehao/words_input
[root@bi-zhaopeng04 data]# hadoop fs -cat /tmp/songzehao/words_input
szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn
至此,我们就具备了执行第一个mr任务的所有理论上的条件,那快来试试吧,跟CDH5搭建https://blog.csdn.net/songzehao/article/details/91044032的测试命令(sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 100)一样,我们尝试执行如下命令:
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop jar wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
或者使用绝对路径
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop jar /root/songzehao/data/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
尝试去执行,结果报错文件找不到File /root/songzehao/data/wc3.jar does not exist:
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop jar wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
19/06/12 14:13:48 INFO client.RMProxy: Connecting to ResourceManager at bi-zhaopeng03/10.1.4.18:8032
19/06/12 14:13:48 INFO mapreduce.JobSubmitter: Cleaning up the staging area /user/hdfs/.staging/job_1559721784881_0043
19/06/12 14:13:48 WARN security.UserGroupInformation: PriviledgedActionException as:hdfs (auth:SIMPLE) cause:java.io.FileNotFoundException: File /root/songzehao/data/wc3.jar does not exist
Exception in thread "main" java.io.FileNotFoundException: File /root/songzehao/data/wc3.jar does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:590)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:803)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:580)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:425)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:340)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1949)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1917)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1882)
at org.apache.hadoop.mapreduce.JobResourceUploader.copyJar(JobResourceUploader.java:210)
at org.apache.hadoop.mapreduce.JobResourceUploader.uploadFiles(JobResourceUploader.java:166)
at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:99)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:194)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1325)
at WordCount.main(WordCount.java:49)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
对呀,跟sudo –u hdfs put一样,先考虑hdfs用户是否有权限访问到任务jar包/root/songzehao/data/wc3.jar,显然也是没有的,但是正确规范的hadoop执行任务jar包又是要在hdfs用户下,解决此矛盾的方法,建议将wc3.jar放至hdfs用户有权限访问的目录下,如/home/hdfs/wc3.jar或/opt/**等公共目录下即可,这也是为什么在搭建完CDH5后,去测试执行sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 100可以成功的原因(因为/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar已经在/opt这个系统自带的公共目录下了,hdfs用户已有权限访问)。Jar包放置得当,比如我放至/opt/szh下:
[root@bi-zhaopeng04 data]# cd /opt/szh/
[root@bi-zhaopeng04 szh]# ll
总用量 8
-rw-r--r-- 1 root root 4910 6月 12 11:42 wc3.jar
之后,可以选择不切换至hdfs用户来直接执行,如下:
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop jar /opt/szh/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output或者切换至hdfs用户来执行,如下:
[root@bi-zhaopeng04 data]# su hdfs
[hdfs@bi-zhaopeng04 data]$ hadoop jar /opt/szh/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
继续尝试去执行,这下总该没问题了吧?好吧,又报错了类找不到Class WordCount$TokenizerMapper not found,来看看具体的异常堆栈吧:
[root@bi-zhaopeng04 data]# sudo -u hdfs hadoop jar /opt/szh/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
19/06/10 19:39:57 INFO client.RMProxy: Connecting to ResourceManager at bi-zhaopeng03/10.1.4.18:8032
19/06/10 19:39:57 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
19/06/10 19:39:57 INFO input.FileInputFormat: Total input paths to process : 1
19/06/10 19:39:58 INFO mapreduce.JobSubmitter: number of splits:1
19/06/10 19:39:58 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1559721784881_0003
19/06/10 19:39:58 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
19/06/10 19:39:58 INFO impl.YarnClientImpl: Submitted application application_1559721784881_0003
19/06/10 19:39:58 INFO mapreduce.Job: The url to track the job: http://bi-zhaopeng03:8088/proxy/application_1559721784881_0003/
19/06/10 19:39:58 INFO mapreduce.Job: Running job: job_1559721784881_0003
19/06/10 19:40:02 INFO mapreduce.Job: Job job_1559721784881_0003 running in uber mode : false
19/06/10 19:40:02 INFO mapreduce.Job: map 0% reduce 0%
19/06/10 19:40:05 INFO mapreduce.Job: Task Id : attempt_1559721784881_0003_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class WordCount$TokenizerMapper not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2199)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:196)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:745)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1693)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.lang.ClassNotFoundException: Class WordCount$TokenizerMapper not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2105)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2197)
... 8 more
该问题也比较明了,没有设置作业jar包,No job jar file set,则需要给conf设置mapred.jar,即,Java代码里加这么一句:
// wc3.jar为最后要执行的作业jar包名称
conf.set("mapred.jar", System.getProperty("user.dir") + File.separator + "wc3.jar");这里顺便给出全部的WordCount源码,包括自己修改添加的一些标准输出语句,如下:
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
System.out.println("Args: " + Arrays.toString(args));
Configuration conf = new Configuration();
conf.set("mapred.jar", System.getProperty("user.dir") + File.separator + "wc3.jar");
// mapred.jar已过期,也可使用新支持的mapreduce.job.jar
// conf.set("mapreduce.job.jar", System.getProperty("user.dir") + File.separator + "wc3.jar");
System.out.println("当前工作目录: " + System.getProperty("user.dir"));
System.out.println("mapred.jar/mapreduce.job.jar: " + conf.get("mapred.jar"));
File jarFile = new File(conf.get("mapred.jar"));
System.out
.println("Jar to run: " + jarFile.getAbsolutePath() + "," + jarFile.isFile() + "," + jarFile.exists());
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
System.out.println("OtherArgs: " + Arrays.toString(otherArgs));
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
Job job = new Job(conf, "szh's word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
System.out.println("Input path: " + otherArgs[i]);
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));
System.out.println("Output path: " + otherArgs[(otherArgs.length - 1)]);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Reducer.Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
折腾了这么久,这下重新导出为jar包,重新执行总该SUCCESS了吧,终于成功了,如下:
[root@bi-zhaopeng04 ~]# sudo -u hdfs hadoop jar /opt/szh/wc3.jar WordCount /tmp/songzehao/words_input /tmp/songzehao/words_output
Args: [/tmp/songzehao/words_input, /tmp/songzehao/words_output]
当前工作目录: /tmp/hsperfdata_hdfs
mapred.jar/mapreduce.job.jar: /tmp/hsperfdata_hdfs/wc3.jar
Jar to run: /tmp/hsperfdata_hdfs/wc3.jar,false,false
OtherArgs: [/tmp/songzehao/words_input, /tmp/songzehao/words_output]
Input path: /tmp/songzehao/words_input
Output path: /tmp/songzehao/words_output
19/06/12 14:57:38 INFO client.RMProxy: Connecting to ResourceManager at bi-zhaopeng03/10.1.4.18:8032
19/06/12 14:57:38 INFO input.FileInputFormat: Total input paths to process : 1
19/06/12 14:57:38 INFO mapreduce.JobSubmitter: number of splits:1
19/06/12 14:57:38 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
19/06/12 14:57:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1559721784881_0045
19/06/12 14:57:38 INFO impl.YarnClientImpl: Submitted application application_1559721784881_0045
19/06/12 14:57:38 INFO mapreduce.Job: The url to track the job: http://bi-zhaopeng03:8088/proxy/application_1559721784881_0045/
19/06/12 14:57:38 INFO mapreduce.Job: Running job: job_1559721784881_0045
19/06/12 14:57:43 INFO mapreduce.Job: Job job_1559721784881_0045 running in uber mode : false
19/06/12 14:57:43 INFO mapreduce.Job: map 0% reduce 0%
19/06/12 14:57:47 INFO mapreduce.Job: map 100% reduce 0%
19/06/12 14:57:51 INFO mapreduce.Job: map 100% reduce 13%
19/06/12 14:57:55 INFO mapreduce.Job: map 100% reduce 25%
19/06/12 14:57:59 INFO mapreduce.Job: map 100% reduce 38%
19/06/12 14:58:03 INFO mapreduce.Job: map 100% reduce 50%
19/06/12 14:58:07 INFO mapreduce.Job: map 100% reduce 63%
19/06/12 14:58:11 INFO mapreduce.Job: map 100% reduce 75%
19/06/12 14:58:15 INFO mapreduce.Job: map 100% reduce 88%
19/06/12 14:58:19 INFO mapreduce.Job: map 100% reduce 100%
19/06/12 14:58:19 INFO mapreduce.Job: Job job_1559721784881_0045 completed successfully
19/06/12 14:58:19 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=367
FILE: Number of bytes written=2018974
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=163
HDFS: Number of bytes written=27
HDFS: Number of read operations=51
HDFS: Number of large read operations=0
HDFS: Number of write operations=32
Job Counters
Launched map tasks=1
Launched reduce tasks=16
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1703
Total time spent by all reduces in occupied slots (ms)=28315
Total time spent by all map tasks (ms)=1703
Total time spent by all reduce tasks (ms)=28315
Total vcore-seconds taken by all map tasks=1703
Total vcore-seconds taken by all reduce tasks=28315
Total megabyte-seconds taken by all map tasks=1743872
Total megabyte-seconds taken by all reduce tasks=28994560
Map-Reduce Framework
Map input records=1
Map output records=14
Map output bytes=103
Map output materialized bytes=303
Input split bytes=116
Combine input records=14
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=303
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =16
Failed Shuffles=0
Merged Map outputs=16
GC time elapsed (ms)=895
CPU time spent (ms)=12940
Physical memory (bytes) snapshot=3937447936
Virtual memory (bytes) snapshot=48442486784
Total committed heap usage (bytes)=3520069632
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=47
File Output Format Counters
Bytes Written=27
趁热赶快去看hdfs中有没有在指定输出目录/tmp/songzehao/words_output下生成文件,可通过web界面浏览hdfs目录,地址:masterIp:50070 /explorer.html#/,如下:
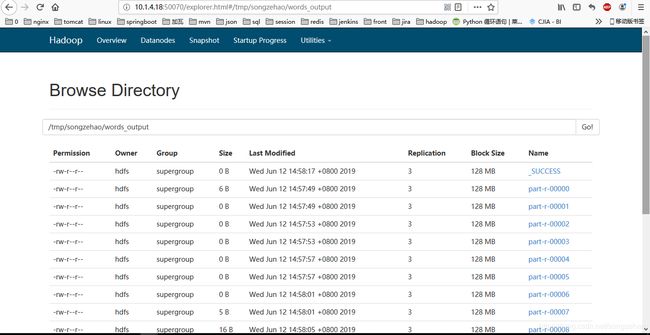
查看一下输出的文件内容吧,是否正确统计出来单词个数,一种方法是直接可以点击文件大小非零的reduce任务输出文件part-r-xxxxx,然后Download查看;另一种可通过hadoop命令行对应查看,如:
[root@bi-zhaopeng04 ~]# hadoop fs -cat /tmp/songzehao/words_output/part-r-00000 /tmp/songzehao/words_output/part-r-00007 /tmp/songzehao/words_output/part-r-00008
szh 3
zp 2
cj 2
dk 5
tyn 2
至此,就算我们成功运行了第一个mr任务了。可是每次执行hadoop jar都要指定主类名吗?这样也有些小麻烦,jar包里面的META-INF/MANIFEST.MF不就可以保存主类信息吗?Hadoop这么优秀的分布式系统架构,应该也已经实现这么一个小小的需求了吧,如果可以的话,那每次执行hadoop jar就不用手动指定主类了。其实Hadoop确实早已想到并实现了这一点,如果我们故意不指定主类名,会发生什么呢?如下:
[root@bi-zhaopeng04 ~]# sudo -u hdfs hadoop jar /opt/szh/wc3.jar /tmp/songzehao/words_input /tmp/songzehao/words_output
Exception in thread "main" java.lang.ClassNotFoundException: /tmp/songzehao/words_input
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:214)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
理所当然地报错说类找不到,至少从异常堆栈信息中,我们已找到翻看源码的突破口RunJar.java,可见Hadoop运行作业jar包,都会进入此入口类。接下来看看它的main方法和run方法:
/** Run a Hadoop job jar. If the main class is not in the jar's manifest,
* then it must be provided on the command line. */
public static void main(String[] args) throws Throwable {
new RunJar().run(args);
}
public void run(String[] args) throws Throwable {
String usage = "RunJar jarFile [mainClass] args...";
if (args.length < 1) {
System.err.println(usage);
System.exit(-1);
}
int firstArg = 0;
String fileName = args[firstArg++];
File file = new File(fileName);
if (!file.exists() || !file.isFile()) {
System.err.println("JAR does not exist or is not a normal file: " +
file.getCanonicalPath());
System.exit(-1);
}
String mainClassName = null;
JarFile jarFile;
try {
jarFile = new JarFile(fileName);
} catch (IOException io) {
throw new IOException("Error opening job jar: " + fileName)
.initCause(io);
}
Manifest manifest = jarFile.getManifest();
if (manifest != null) {
mainClassName = manifest.getMainAttributes().getValue("Main-Class");
}
jarFile.close();
if (mainClassName == null) {
if (args.length < 2) {
System.err.println(usage);
System.exit(-1);
}
mainClassName = args[firstArg++];
}
mainClassName = mainClassName.replaceAll("/", ".");
File tmpDir = new File(System.getProperty("java.io.tmpdir"));
ensureDirectory(tmpDir);
final File workDir;
try {
workDir = File.createTempFile("hadoop-unjar", "", tmpDir);
} catch (IOException ioe) {
// If user has insufficient perms to write to tmpDir, default
// "Permission denied" message doesn't specify a filename.
System.err.println("Error creating temp dir in java.io.tmpdir "
+ tmpDir + " due to " + ioe.getMessage());
System.exit(-1);
return;
}
if (!workDir.delete()) {
System.err.println("Delete failed for " + workDir);
System.exit(-1);
}
ensureDirectory(workDir);
ShutdownHookManager.get().addShutdownHook(
new Runnable() {
@Override
public void run() {
FileUtil.fullyDelete(workDir);
}
}, SHUTDOWN_HOOK_PRIORITY);
if (!skipUnjar()) {
unJar(file, workDir);
}
ClassLoader loader = createClassLoader(file, workDir);
Thread.currentThread().setContextClassLoader(loader);
Class mainClass = Class.forName(mainClassName, true, loader);
Method main = mainClass.getMethod("main", String[].class);
List newArgsSubList = Arrays.asList(args)
.subList(firstArg, args.length);
String[] newArgs = newArgsSubList
.toArray(new String[newArgsSubList.size()]);
try {
main.invoke(null, new Object[] {newArgs});
} catch (InvocationTargetException e) {
throw e.getTargetException();
}
}
从main方法的方法注释或run方法的实现可以了解到,“运行Hadoop作业jar。 如果主类不在jar的清单Manifest中,那么它必须在命令行中提供。”,所以,我们需要在导出jar的时候,指定其主类Main-Class即可,在Eclipse中注意这一步:
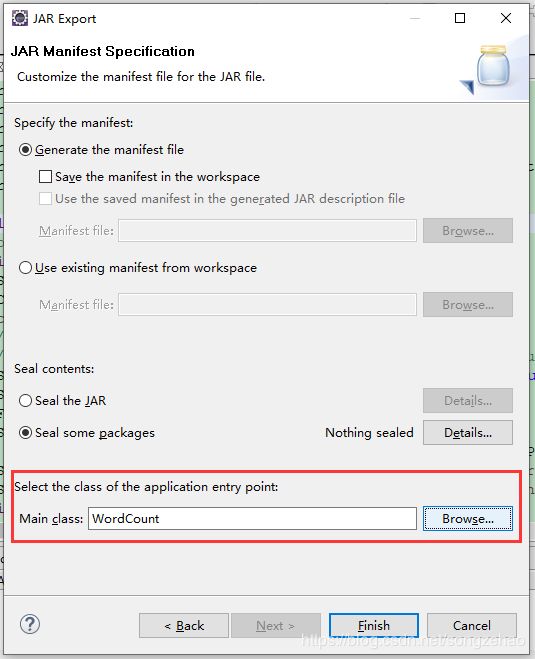
导出后的新jar,查看META-INF/MANIFEST.MF如下:
Manifest-Version: 1.0
Main-Class: WordCount
From now on,我们执行hadoop jar便不用在命令行手动指定主类名了。
❀完结撒花❀