MySQL 实战(一)
MySQL实战(一)
- 1.数据导入导出
- 1.1 Navicat导入,导出向导
- 1.2 MySQL导入导出语句
- 1.3 mysqlimport
- 2.实战
- 2.1 Excel数据导入导出
- 2.2 各部门工资最高的员工
- 2.3 换座位
- 2.4 分数排名
1.数据导入导出
1.1 Navicat导入,导出向导
利用Navicat的导入向导和导出向导,可以方便地执行数据的导入导出:
导入向导
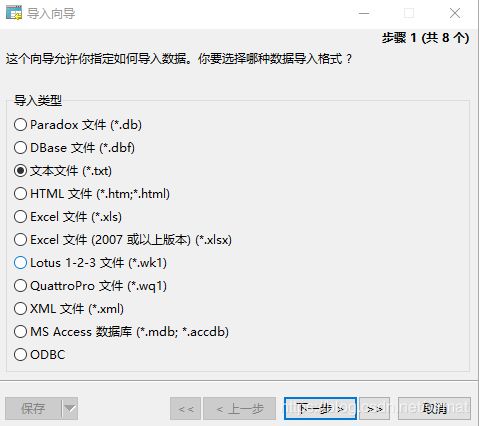
导入向导分为八个步骤:
- 选择数据导入格式,如上图所示;
- 选择文件作为数据源,并指定文件编码;
- 指定分隔符,常见的如分号,逗号,固定宽度和空格;
- 附加选项,设置栏位名行和起止数据行,日期,时间和数字的符号;
- 选择目标表,包括现有表和新建表;
- 设定栏位对应,可以对应源数据表修改导入后的栏位名和设置主键;
- 设置导入模式,如添加,复制,删除,更新,添加或更新;
- 点击开始导入,并输出导入过程中的日志信息,方便查询进度和错误。
导出向导
 导出向导分为5个步骤:
导出向导分为5个步骤:
- 选择导出格式;
- 选择要导出的表,导出到的文件名和路径,文件编码和添加时间戳;
- 选择要导出哪些表中的哪些列;
- 附加选项,如是否包含列的标题,分隔符,时期,时间和数字格式,导出遇到错误是否继续;
- 点击开始导出,并输出导入过程中的日志信息,方便查询进度和错误。
注意
导入Excel文件时,需要打开微软OFFICE软件,且和Navicat选择同样的64位或32位版本,或转为CSV文件导入。
1.2 MySQL导入导出语句
导入语句
1.mysql -u用户名 -p密码 < 要导入的数据库数据(dump.sql);
2.mysql> create database abc; # 创建数据库
mysql> use abc; # 使用已创建的数据库
mysql> set names utf8; # 设置编码
mysql> source /home/abc/abc.sql #导入abc.sql
3.mysql> LOAD DATA LOCAL INFILE 'dump.txt' INTO TABLE mytbl (c1,c3,c2) --修改插入表中列的顺序
-> FIELDS TERMINATED BY ':' --指定定位符
-> LINES TERMINATED BY '\r\n'; --指定换行符
导出语句
SELECT a,b,a+b INTO OUTFILE '/tmp/result.text' --指定导出列和导出文件
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' --指定分隔符,字段左右符号
LINES TERMINATED BY '\n' --指定换行符
FROM test_table;--导出表名
#需要拥有文件权限,导出文件不能是已有的文件,需要登录MySQL服务器使用
mysqldump -u root -p db tbl > dump.txt
password ****** -- 导出db数据库的tb1表到dump.txt
mysqldump -u root -p db> dump.txt
password ****** -- 导出db数据库到dump.txt
mysqldump -u root -p --no-create-info \
--tab=/tmp db tbl
password ****** --导出到可写目录/tmp
#导入时>换成<即可
1.3 mysqlimport
基本语句
mysqlimport -u root -p --local database_name dump.txt
password *****
#指定用户,数据库,导出文件,输入密码,执行导入
可选指令
| 指令 | 用途 |
|---|---|
| -v or -version | 显示版本信息 |
| -p or -password | 提示输入密码 |
| -d or --delete | 新数据导入数据表中之前删除数据数据表中的所有信息 |
| -f or --force | 不管是否遇到错误,mysqlimport将强制继续插入数据 |
| -i or --ignore | mysqlimport跳过或者忽略那些有相同唯一 关键字的行, 导入文件中的数据将被忽略。 |
| -l or -lock-tables | 数据被插入之前锁住表,这样就防止了, 你在更新数据库时,用户的查询和更新受到影响。 |
| -r or -replace | 这个选项与-i选项的作用相反;此选项将替代 表中有相同唯一关键字的记录。 |
| –fields-enclosed- by= char | 指定文本文件中数据的记录时以什么括起的, 很多情况下 数据以双引号括起。 默认的情况下数据是没有被字符括起的。 |
| –fields-terminated- by=char | 指定各个数据的值之间的分隔符,在句号分隔的文件中, 分隔符是句号。您可以用此选项指定数据之间的分隔符。 默认的分隔符是跳格符(Tab) |
| –lines-terminated- by=str | 此选项指定文本文件中行与行之间数据的分隔字符串 或者字符。 默认的情况下mysqlimport以newline为行分隔符。 您可以选择用一个字符串来替代一个单个的字符: 一个新行或者一个回车。 |
2.实战
2.1 Excel数据导入导出
Excel数据
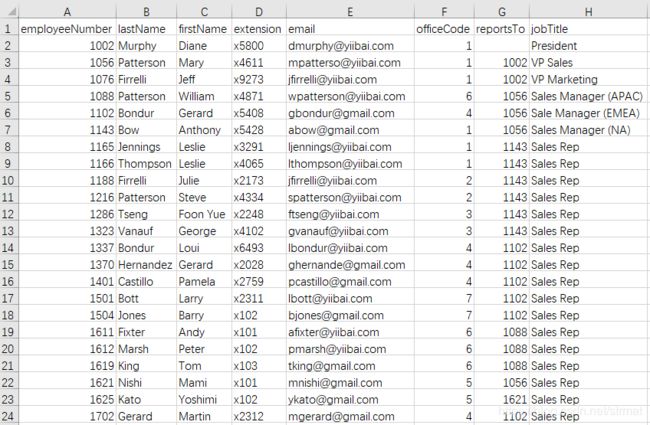 操作:
操作:
Navicat导入导出向导。
导入MySQL数据
2.2 各部门工资最高的员工
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
创建Department 表,包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| Sales | Henry | 80000 |
代码:
#建立数据表
CREATE TABLE IF NOT EXISTS Employee(
Id INT NOT NULL PRIMARY KEY,
Name VARCHAR(20) NOT NULL,
Salary INT NOT NULL,
DepartmentId INT NOT NULL
);
INSERT INTO Employee
VALUES
(1,"Joe",70000,1),
(2,"Henry",80000,2),
(3,"Sam",60000,2),
(4,"Max",90000,1);
CREATE TABLE Department(
Id INT NOT NULL PRIMARY KEY,
Name VARCHAR(20) NOT NULL
);
INSERT Into Department
VALUES
(1,"IT"),(2,"Sales");
#查询语句
SELECT
a.Name AS department,b.NAME AS Employee,b.Salary AS Salary
FROM Employee b
INNER JOIN department a
WHERE b.departmentId = a.Id
AND b.Salary >= (
SELECT MAX(Salary) FROM Employee c
WHERE b.departmentId= c.departmentId);
注意:MySQL5.7.5之后的版本实现了对功能依赖的检测,默认开启only_full_group_by选项,SELECT中出现的列必须是group by后的列或聚合函数,上述代码需关闭only_full_group_by选项运行。
SET SESSION sql_mode="STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION"
SET GLOBAL sql_mode="STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION"
2.3 换座位
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。 其中纵列的 id 是连续递增的 小美想改变相邻俩学生的座位。 你能不能帮她写一个 SQL query 来输出小美想要的结果呢? 请创建如下所示seat表:
示例:
| id | student |
|---|---|
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
假如数据输入的是上表,则输出结果如下:
| id | student |
|---|---|
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
注意: 如果学生人数是奇数,则不需要改变最后一个同学的座位。
代码:
SELECT (CASE
WHEN id=counts THEN id
WHEN MOD(id,2)=0 THEN id-1
ELSE id+1 END) AS id,student
FROM seat,(SELECT COUNT(id) AS counts FROM seat) t1
ORDER BY id;
2.4 分数排名
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
| Id | Score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
代码:
#建立数据表
CREATE TABLE IF NOT EXISTS score(
Id INT NOT NULL PRIMARY KEY,
Score FLOAT NOT NULL
);
INSERT INTO score
VALUES
(1,3.50),
(2,3.65),
(3,4.00),
(4,3.85),
(5,4.00),
(6,3.65);
#查询语句
SELECT score, (
SELECT COUNT(DISTINCT score)
FROM score
WHERE score >= t1.score )
AS 'rank'
FROM score t1
ORDER BY score DESC;