FastAI 2019课程学习笔记 lesson 2:自行获取数据并创建分类器
文章目录
- 数据获取
- google_images_download 的安装和使用
- 挂载google 个人硬盘到Google colab中
- 删除不能打开文件
- 创建ImageDataBunch
- 训练模型
- 解释模型
- 将模型投入生产
- 可能出故障的情况
- 学习率太高(Learning rate too high)
- 学习率太低(Learning rate too low)
- Too few epochs
- Too many epochs
数据获取
数据集在深度学习模型的训练过程中有着重要的影响,本次课程教大家如何利用google的图片搜索功能来创建简单的图片数据集。
本人使用了Google colab作为学习fastai的平台,所以你需要科学上网。本人在实验的过程中发现fastai官方教程提供的获取google image的json文件不好用,所以找了一个开源的google image开源库来代替官方的图片获取方案。
google_images_download 的安装和使用
通过下面代码在Google colab中安装google_images_download:
!pip install google_images_download
我们现在需要制作黑熊,棕熊,泰迪熊的数据集,希望最终的模型可以区分这三种熊,所以我们通过如下的代码来从Google image上获取这三种熊的图片。
from google_images_download import google_images_download #importing the library
response = google_images_download.googleimagesdownload() #class instantiation
arguments = {"keywords":"black bear,grizzly bear,teddy bear","limit":100,"print_urls":True} #creating list of arguments
paths = response.download(arguments) #passing the arguments to the function
print(paths
在这段代码中我们需要注意的是"limit":100,由于这个库的问题,在下载100张以内图片时候是不需要安装selenium 库和 chromedriver 扩展的,但是差不多100张的图片也足够我们需要了。
下载的文件在google colab中一般放在/content/downloads/目录下,为了方便下次我们对数据的使用,我们可以将这些数据永久保存在我们自己Google 硬盘之中
挂载google 个人硬盘到Google colab中
from google.colab import drive
drive.mount('/content/gdrive', force_remount=True)
root_dir = "/content/gdrive/My\ Drive/"
可以通过如下代码实现挂载google硬盘到google colab中
然后我们可以通过如下代码将下载的图片文件拷贝到个人的文件夹中,后面的目标文件夹大家可以自行更改:
!cp -r /content/downloads/* /content/gdrive/My\ Drive/pytorch/Fast_AI_learning/data/bears/
删除不能打开文件
通过以下的程序实现删除不能打开的文件,当然我们也可以自己去https://drive.google.com下去找到对应的文件夹,看看是否存在图片不能打开的情况,如果存在则删除这些图片
path = Path("/content/gdrive/My Drive/pytorch/Fast_AI_learning/data/bears")
classes = ['black bear','grizzly bear','teddy bear']
for c in classes:
print(c)
verify_images(path/c, delete=True, max_size=500)
创建ImageDataBunch
与lesson 1类似,我们创建ImageDataBunch:
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
在我们在创建data bunch时候,如果不知道分离的验证集和训练集,就默认当前文件夹是训练集,但是我们应该留出20%的数据作为验证集,所以我们自动的、随机的创建一个验证集。在我们随机创建一个验证集时候,我们总是提前设置一个固定的随机种子,这意味着每次我执行这段代码的时候都会得到同样的验证集结果。
随机性是一个非常重要的部分来找出稳定的解,每次你运行它的时候它都会起作用。但重要的是,你总是有相同的验证集,否则当你正试图决定这个超参数改变改善我的模型,但你有一组不同的数据测试,那么你不知道也许这组数据恰好是有点简单。
这就是为什么总是把随机的种子放在这里。
通过下面代码显示出一部分图像结果:
data.show_batch(rows=3, figsize=(7,8))
 通过下面代码显示数据种类结果以及训练集和验证集的数量:
通过下面代码显示数据种类结果以及训练集和验证集的数量:
data.classes, data.c, len(data.train_ds), len(data.valid_ds)
得到:
(['black bear', 'grizzly bear', 'teddy bear'], 3, 204, 51)
训练模型
根据lesson 1的训练模型方式,我们通过resnet34模型来进行训练:
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)
得到如下的结果:
 然后我们先保存当前状态,然后通过运行学习率寻找工具并绘制出学习率:
然后我们先保存当前状态,然后通过运行学习率寻找工具并绘制出学习率:
learn.save('stage-1')
learn.unfreeze()
learn.lr_find()
learn.recorder.plot()
最后得到这样的图像:
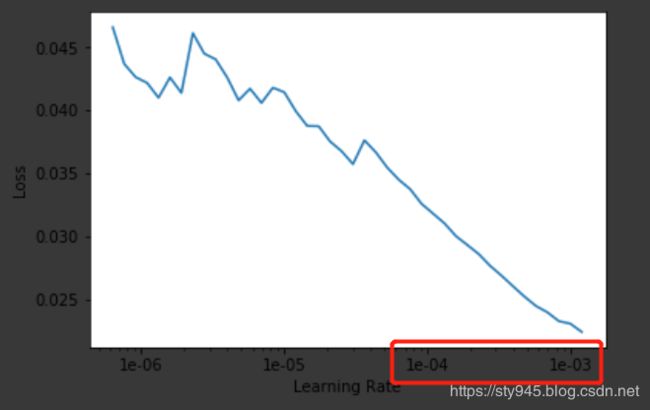
通过图像我们发现在区间[1e-4, 1e-3]中间loss是下降最快的,所以我们通过下面的代码进一步的优化模型:
learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4))

经过我们到现在的努力,我们的错误率维持在了1.9%,这已经是一个相对来说比较好的结果的了。我们通过google image创建了一个数据集,然后创建了一个分类器,最后我们得到了1.9%的错误率,现在我们保存下这个状态。
learn.save('stage-2')
解释模型
learn.load('stage-2')
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
绘制得到混淆矩阵如下:
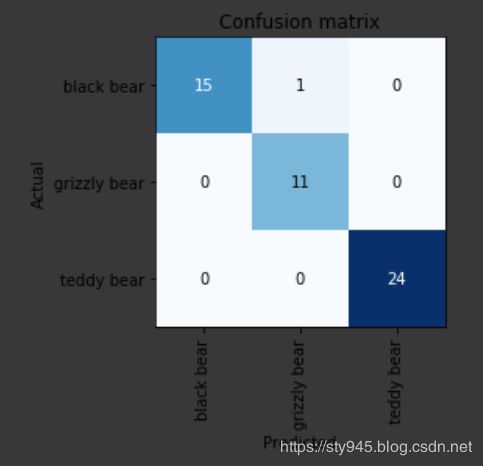 我们发现其中有个黑熊被我们预测成了棕熊
我们发现其中有个黑熊被我们预测成了棕熊
将模型投入生产
首先将模型导出:
learn.export()
这会在目录中创建一个名为export.pkl的文件,它包含了部署模型所需要的所有内容(模型,权重以及一些元数据)
我们可以选择再cpu上执行这个预测程序,当我们的机器没有gpu时候,这是自行发生的
defaults.device = torch.device('cpu')
我们可以选择一张图片:
img = open_image(path/'grizzly bear/2.grizzly_pam-hartman_0_epv0457.jpg')
img
 我们在保证路径下包含的
我们在保证路径下包含的export.pkl,然后我们在生产环境中创建学习器:
learn = load_learner(path)
然后我们就可以进行我们的预测工作了
pred_class, pred_idx, outputs = learn.predict(img)
pred_class
我们得到如下结果,预测表明这张图片表示的是棕熊。
Category grizzly bear
可能出故障的情况
在大多数情况之下,我们按照官方指定的教程去运行程序是没有产生正确的结果的,所以我们来谈谈当我们遇到问题时候会发生什么?这就是我们为什么开始学习一些理论的原因,因为为了方便我们理解为什么会有这些问题以及我们如何解决这些问题。
首先我们先看下一些典型的问题案例,如下:
- 你的学习率太高或者太低
- 你的epoch的数量太多或者太少
所以我们来学习下这意味着什么以及为什么他们发挥重要的作用。
学习率太高(Learning rate too high)
所以让我们用我们的泰迪熊探测器来提高我们的学习速度。默认的学习率是0.003,这在大多数情况下是可行的。如果我们试着把学习率设为0.5,这是非常大的,会发生什么呢?我们的验证损失相当大,它通常是1以下的数。如果你看到你的验证损失,在我们知道验证损失是什么之前,只要出现这样的情况,证明你的learning rate就太高了,你只需要知道这些让它更低就可以了。不管你经历了多少个epoch,如果发生这种情况,就没有办法挽回了,你必须回去重新建立你的神经网络,从零开始适应一个较低的学习率(learning rate)。
learn = create_cnn(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(1, max_lr=0.5)

学习率太低(Learning rate too low)
如果我们传入的最大的学习率不是 0.003而是0.00001呢?
learn = create_cnn(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(5, max_lr=1e-5)
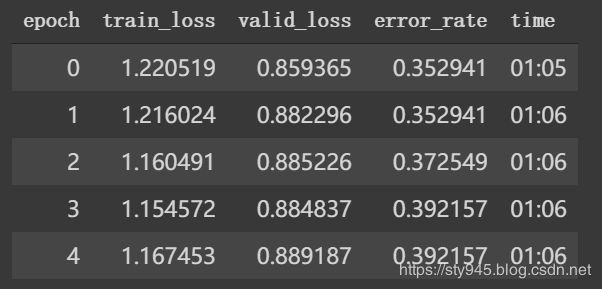
虽然使用很低的学习率,我们的错误率有所下降但是下降的速度非常的缓慢。
可以通过使用learn.recorder.plot_losses来绘制出验证和训练损失,可以看见他们在慢慢的下降。

如果你看见这种情况,就证明你的学习速率太小了,所以你可以尝试10倍,100倍的放大学习率然后再次进行训练。**还有一个需要注意的是如果你的学习率太小了,那么你的训练损失会高于你的验证损失,你永远不会希望这样的情况发生在你的训练模型中的。**这就意味着你没训练够,意味着你的学习率太低了或者你的epoch的数量太小了。所以如果你的训练模型发生这样的情况,使用更高的学习率再多训练几次。
Too few epochs
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(1)

如果使用一个epoch,并且错误率在7%,这是低于随机预测的,但是看看训练损失和验证损失之间的差别,我们发现训练损失是远远高于验证损失的,所以太少的epoch和太小的learning rate的结果是相似的。所以你可以尝试更多的epoch,如果结果还是一样,那么你可以尝试更高的学习率。如果尝试一个更高的学习率,损失会达到10亿,然后你再把学习率设为原来的值,再增加一个epoch,这就是平衡,也就是调参,99%的时候你只关心这些,只有1/20的情况下,默认值是无效的。
Too many epochs
太多的epoch会造成过拟合。当你训练你的模型时间太长,模型可能就会只识别特定的泰迪熊而不是一般的泰迪熊了。尽管你可能听过在深度学习中很难产生过拟合,所以现在为大家展示一个过拟合的案例,并且关闭一些其他选项,我关闭了数据增强,dropout,以及weight decay(权值衰减),我尽可能的让模型过拟合。我以一个很小的学习率训练模型,并且训练模型很长时间,我可能会得到一个过拟合的模型。
唯一能告诉你过拟合的是错误率短暂的提升,然后开始变得更差。你可能会听见很多人,甚至那些声称了解机器学习的人告诉你说如果你的training loss 比validation loss低,那么就是过拟合,但是这其实并不是完全正确。
任何一个正确的训练模型的training loss都比validation loss低
这并不是过拟合的迹象,这并不意味着你做错了什么,这恰恰证明你做的是对的。你过拟合的标志是错误率开始变得更糟,这才是你应该关心的。你希望你的模型拥有更低的错误率,所以只要你在训练的时候,你的模型的错误在改善,那么你就没有过拟合。
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.9, bs=26,
ds_tfms=get_transforms(do_flip=False, max_rotate=0, max_zoom=1, max_lighting=0, max_warp=0
),size=224, num_workers=4).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet50, metrics=error_rate, ps=0, wd=0)
learn.unfreeze()
learn.fit_one_cycle(40, slice(1e-6,1e-4))
结果如下:
epoch train_loss valid_loss error_rate time
0 1.281925 1.141897 0.694323 00:07
1 1.346654 1.129421 0.694323 00:03
2 1.340803 1.107458 0.681223 00:03
3 1.355779 1.085071 0.646288 00:03
4 1.295381 1.050753 0.589520 00:03
5 1.224308 1.000656 0.497817 00:03
6 1.159185 0.938931 0.397380 00:03
7 1.088768 0.867412 0.310044 00:03
8 1.008123 0.788017 0.231441 00:03
9 0.938289 0.708754 0.157205 00:03
10 0.864608 0.634222 0.122271 00:03
11 0.793969 0.566193 0.096070 00:03
12 0.733825 0.508754 0.082969 00:03
13 0.680985 0.458568 0.069869 00:03
14 0.632074 0.418085 0.061135 00:03
15 0.589376 0.385271 0.056769 00:03
16 0.551403 0.356482 0.056769 00:03
17 0.516843 0.330840 0.052402 00:03
18 0.485706 0.311566 0.052402 00:03
19 0.457809 0.295450 0.052402 00:03
20 0.432226 0.281761 0.052402 00:03
21 0.408979 0.269984 0.052402 00:03
22 0.387673 0.259906 0.048035 00:03
23 0.368162 0.251425 0.039301 00:03
24 0.350114 0.245693 0.034934 00:03
25 0.333477 0.238942 0.034934 00:03
26 0.318159 0.232099 0.030568 00:03
27 0.303887 0.226424 0.030568 00:03
28 0.290654 0.222446 0.030568 00:03
29 0.278258 0.218786 0.034934 00:03
30 0.266660 0.215658 0.030568 00:03
31 0.255738 0.214105 0.030568 00:03
32 0.245596 0.209824 0.030568 00:03
33 0.236173 0.205443 0.034934 00:03
34 0.227359 0.204399 0.030568 00:03
35 0.218893 0.202812 0.030568 00:03
36 0.210922 0.202212 0.039301 00:03
37 0.203402 0.201633 0.039301 00:03
38 0.196221 0.201402 0.039301 00:03
39 0.189409 0.201313 0.039301 00:03
综上是在训练深度模型时候容易出错的四点