Scheduler学习之四:dl_sched_class(上)
- 关于deadline的原理概述
参考:deadline调度器之(一):原理 http://www.wowotech.net/process_management/deadline-scheduler-1.html
这篇文章介绍的很好。摘抄其中关键的内容:对于DL调度器,用户需要设定三个参数:周期(period)、运行时间(runtime)和最后期限(deadline)。周期和该实时任务的工作模式相关。例如:对于一个视频处理任务,它的主要的工作是每秒钟处理60帧的视频数据,即每16毫秒需要处理每一帧视频,因此,该任务的周期就是16ms。
对于实时任务,一个周期内总是有固定的“工作”要做,例如在视频任务中,所谓的工作就是对一帧视频数据进行处理,Runtime是完成这些“工作”需要的CPU执行时间,即在一个周期中,需要CPU参与运算的时间值。在设定运行时间参数的时候我们不能太乐观,runtime在设定的时候必须考虑最坏情况下的执行时间(worst-case execution time ,WCET)。例如,在视频处理中,各个帧的情况可能不太一样(一方面帧间的相关性不同,另外,即便是针对一帧数据,其图像像素之间的相关性也不同),有些会耗时长一些,有些会短一些。如果处理时间最长的那帧视频需要5毫秒来处理,那么它的runtime设定就是五毫秒。最后我们来说说Deadline参数。在一个实时任务的工作周期内,deadline定义了处理完成的结果必须被交付的最后期限。我们还是以上面的视频处理任务为例,在一个视频帧的处理周期中(16ms),如果该任务需要在该周期的前10毫秒内把处理过的视频帧传送给下一个模块,那么deadline参数就是10毫秒。为了达到这个要求,显然在该周期的前10ms就必须完成一帧数据的处理,即5ms的runtime必须位于该周期的前10ms时间范围内。
-
个人理解
deadline调度器关键依赖如下的结构体实现task的管理与调度。
dl_period规定了本task执行的周期。形如android中的每隔16.67ms要更新一帧一样。
dl_deadline规定了本task在一个周期内最迟交付成果的时间。
dl_runtime规定了task在一个周期内最worse情况执行的时间。
为了保证上面目标的实现,需要有一个timer来在下个周期的时候将task enqueue进 dl_rq->root的树当中。
为了能够实现上面的目标,在dl_rq的红黑树中,按照最近deadline进行排序,每次Pick next task的时候,直接选择最左边的即可。
为了做到Loading均衡,使用dl_rq->pushable_dl_tasks_root将允许放到多个cpu上排队的task串成红黑树
一个周期的runtime执行完,如果需要boost就进行重新填充时间,否则就进行throttle并待到下一个周期的时候再进行enqueue.struct sched_dl_entity { struct rb_node rb_node; /* * Original scheduling parameters. Copied here from sched_attr * during sched_setattr(), they will remain the same until * the next sched_setattr(). */ u64 dl_runtime; /* Maximum runtime for each instance */ u64 dl_deadline; /* Relative deadline of each instance */ u64 dl_period; /* Separation of two instances (period) */ u64 dl_bw; /* dl_runtime / dl_period */ u64 dl_density; /* dl_runtime / dl_deadline */ /* * Actual scheduling parameters. Initialized with the values above, * they are continuously updated during task execution. Note that * the remaining runtime could be < 0 in case we are in overrun. */ s64 runtime; /* Remaining runtime for this instance */ u64 deadline; /* Absolute deadline for this instance */ unsigned int flags; /* Specifying the scheduler behaviour */ /* * Some bool flags: * * @dl_throttled tells if we exhausted the runtime. If so, the * task has to wait for a replenishment to be performed at the * next firing of dl_timer. * * @dl_boosted tells if we are boosted due to DI. If so we are * outside bandwidth enforcement mechanism (but only until we * exit the critical section); * * @dl_yielded tells if task gave up the CPU before consuming * all its available runtime during the last job. * * @dl_non_contending tells if the task is inactive while still * contributing to the active utilization. In other words, it * indicates if the inactive timer has been armed and its handler * has not been executed yet. This flag is useful to avoid race * conditions between the inactive timer handler and the wakeup * code. * * @dl_overrun tells if the task asked to be informed about runtime * overruns. */ unsigned int dl_throttled : 1; unsigned int dl_boosted : 1; unsigned int dl_yielded : 1; unsigned int dl_non_contending : 1; unsigned int dl_overrun : 1; /* * Bandwidth enforcement timer. Each -deadline task has its * own bandwidth to be enforced, thus we need one timer per task. */ struct hrtimer dl_timer; /* * Inactive timer, responsible for decreasing the active utilization * at the "0-lag time". When a -deadline task blocks, it contributes * to GRUB's active utilization until the "0-lag time", hence a * timer is needed to decrease the active utilization at the correct * time. */ struct hrtimer inactive_timer; }; - code 跟踪
const struct sched_class dl_sched_class = { .next = &rt_sched_class, .enqueue_task = enqueue_task_dl, .dequeue_task = dequeue_task_dl, .yield_task = yield_task_dl, .check_preempt_curr = check_preempt_curr_dl, .pick_next_task = pick_next_task_dl, .put_prev_task = put_prev_task_dl, .set_next_task = set_next_task_dl, #ifdef CONFIG_SMP .balance = balance_dl, .select_task_rq = select_task_rq_dl, .migrate_task_rq = migrate_task_rq_dl, .set_cpus_allowed = set_cpus_allowed_dl, .rq_online = rq_online_dl, .rq_offline = rq_offline_dl, .task_woken = task_woken_dl, #endif .task_tick = task_tick_dl, .task_fork = task_fork_dl, .prio_changed = prio_changed_dl, .switched_from = switched_from_dl, .switched_to = switched_to_dl, .update_curr = update_curr_dl, };1.1 .enqueue_task = enqueue_task_dl
static void enqueue_task_dl(struct rq *rq, struct task_struct *p, int flags) { struct task_struct *pi_task = rt_mutex_get_top_task(p);//此处涉及到rt mutex,后续研究,此处应该是获取等待当前task所拿锁的最top的那个task struct sched_dl_entity *pi_se = &p->dl; /* * Use the scheduling parameters of the top pi-waiter task if: * - we have a top pi-waiter which is a SCHED_DEADLINE task AND * - our dl_boosted is set (i.e. the pi-waiter's (absolute) deadline is * smaller than our deadline OR we are a !SCHED_DEADLINE task getting * boosted due to a SCHED_DEADLINE pi-waiter). * Otherwise we keep our runtime and deadline. */ if (pi_task && dl_prio(pi_task->normal_prio) && p->dl.dl_boosted) { pi_se = &pi_task->dl;//如果当前task有一个top pi-waiter task,并且这个task也是dl并且有被boost,那么enqueue top pi waiter } else if (!dl_prio(p->normal_prio)) { //如果当前task不是dl优先级的则不enqueue /* * Special case in which we have a !SCHED_DEADLINE task * that is going to be deboosted, but exceeds its * runtime while doing so. No point in replenishing * it, as it's going to return back to its original * scheduling class after this. */ BUG_ON(!p->dl.dl_boosted || flags != ENQUEUE_REPLENISH); return; } /* * Check if a constrained deadline task was activated * after the deadline but before the next period. * If that is the case, the task will be throttled and * the replenishment timer will be set to the next period. */ if (!p->dl.dl_throttled && !dl_is_implicit(&p->dl)) dl_check_constrained_dl(&p->dl); if (p->on_rq == TASK_ON_RQ_MIGRATING || flags & ENQUEUE_RESTORE) { add_rq_bw(&p->dl, &rq->dl); add_running_bw(&p->dl, &rq->dl); } /* * If p is throttled, we do not enqueue it. In fact, if it exhausted * its budget it needs a replenishment and, since it now is on * its rq, the bandwidth timer callback (which clearly has not * run yet) will take care of this. * However, the active utilization does not depend on the fact * that the task is on the runqueue or not (but depends on the * task's state - in GRUB parlance, "inactive" vs "active contending"). * In other words, even if a task is throttled its utilization must * be counted in the active utilization; hence, we need to call * add_running_bw(). */ if (p->dl.dl_throttled && !(flags & ENQUEUE_REPLENISH)) { if (flags & ENQUEUE_WAKEUP) task_contending(&p->dl, flags); return; } enqueue_dl_entity(&p->dl, pi_se, flags); if (!task_current(rq, p) && p->nr_cpus_allowed > 1) enqueue_pushable_dl_task(rq, p); }经过前面的一些判断,走到了enqueue_dl_entity function,关于前面的判断情况,待后续再做研究,今天主要研究如何enqueue。Deadline的task如何管理。
static void enqueue_dl_entity(struct sched_dl_entity *dl_se, struct sched_dl_entity *pi_se, int flags) { BUG_ON(on_dl_rq(dl_se)); /* * If this is a wakeup or a new instance, the scheduling * parameters of the task might need updating. Otherwise, * we want a replenishment of its runtime. */ if (flags & ENQUEUE_WAKEUP) { task_contending(dl_se, flags); update_dl_entity(dl_se, pi_se); } else if (flags & ENQUEUE_REPLENISH) { replenish_dl_entity(dl_se, pi_se); } else if ((flags & ENQUEUE_RESTORE) && dl_time_before(dl_se->deadline, rq_clock(rq_of_dl_rq(dl_rq_of_se(dl_se))))) { setup_new_dl_entity(dl_se); } __enqueue_dl_entity(dl_se);//enqeueue entity } static void __enqueue_dl_entity(struct sched_dl_entity *dl_se) { struct dl_rq *dl_rq = dl_rq_of_se(dl_se);//根据dl_se取得dl rq,那么是如何取得的呢? struct rb_node **link = &dl_rq->root.rb_root.rb_node; struct rb_node *parent = NULL; struct sched_dl_entity *entry; int leftmost = 1; BUG_ON(!RB_EMPTY_NODE(&dl_se->rb_node)); while (*link) {//遍历红黑树,找到应该挂载的parent parent = *link; entry = rb_entry(parent, struct sched_dl_entity, rb_node); if (dl_time_before(dl_se->deadline, entry->deadline))//根据这个条件判断,说明红黑树是按照deadline情况进行排序的。那么deadline如何设定的呢?值的范围是多少呢? link = &parent->rb_left; else { link = &parent->rb_right; leftmost = 0; } } rb_link_node(&dl_se->rb_node, parent, link);//挂载到parent rb_insert_color_cached(&dl_se->rb_node, &dl_rq->root, leftmost);//如后面所示,这个地方会去更新root中的leftmost,从而方便后面Pick next task inc_dl_tasks(dl_se, dl_rq); }如何根据dl_se取得dl_rq呢?
static inline struct dl_rq *dl_rq_of_se(struct sched_dl_entity *dl_se) { struct task_struct *p = dl_task_of(dl_se); struct rq *rq = task_rq(p); return &rq->dl; } static inline struct task_struct *dl_task_of(struct sched_dl_entity *dl_se) { return container_of(dl_se, struct task_struct, dl); } #define container_of(ptr, type, member) ({ \ void *__mptr = (void *)(ptr); \ BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \ !__same_type(*(ptr), void), \ "pointer type mismatch in container_of()"); \ ((type *)(__mptr - offsetof(type, member))); })//此处是关键。将当前指针向前移动member相对于type的offset就得到type对象的地址。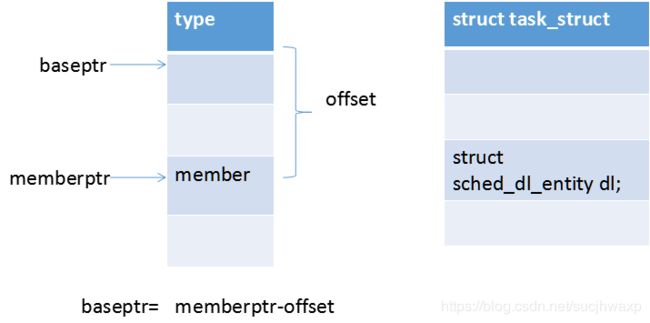
所以根据se找到rq的路径如下:
se->task->cpu->rq->dl
其中根据task得到rq的方法如下:#define task_rq(p) cpu_rq(task_cpu(p))而rq中包含dl的成员:
struct rq { ………… struct cfs_rq cfs; struct rt_rq rt; struct dl_rq dl; ……………… }所以,task在dl_sched_class是采用如下的方式进行管理的:
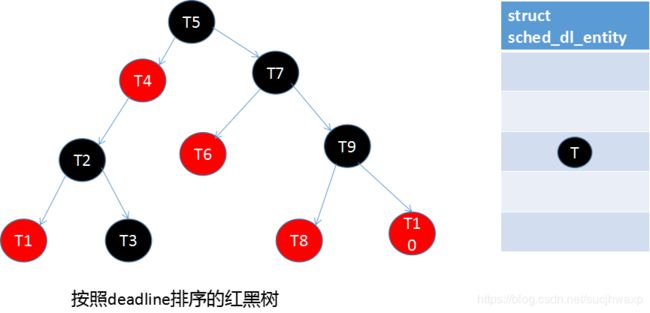
deadline的值如何设定?
/* * When a deadline entity is placed in the runqueue, its runtime and deadline * might need to be updated. This is done by a CBS wake up rule. There are two * different rules: 1) the original CBS; and 2) the Revisited CBS. * * When the task is starting a new period, the Original CBS is used. In this * case, the runtime is replenished and a new absolute deadline is set. * * When a task is queued before the begin of the next period, using the * remaining runtime and deadline could make the entity to overflow, see * dl_entity_overflow() to find more about runtime overflow. When such case * is detected, the runtime and deadline need to be updated. * * If the task has an implicit deadline, i.e., deadline == period, the Original * CBS is applied. the runtime is replenished and a new absolute deadline is * set, as in the previous cases. * * However, the Original CBS does not work properly for tasks with * deadline < period, which are said to have a constrained deadline. By * applying the Original CBS, a constrained deadline task would be able to run * runtime/deadline in a period. With deadline < period, the task would * overrun the runtime/period allowed bandwidth, breaking the admission test. * * In order to prevent this misbehave, the Revisited CBS is used for * constrained deadline tasks when a runtime overflow is detected. In the * Revisited CBS, rather than replenishing & setting a new absolute deadline, * the remaining runtime of the task is reduced to avoid runtime overflow. * Please refer to the comments update_dl_revised_wakeup() function to find * more about the Revised CBS rule. */ static void update_dl_entity(struct sched_dl_entity *dl_se, struct sched_dl_entity *pi_se) { struct dl_rq *dl_rq = dl_rq_of_se(dl_se); struct rq *rq = rq_of_dl_rq(dl_rq); if (dl_time_before(dl_se->deadline, rq_clock(rq)) || dl_entity_overflow(dl_se, pi_se, rq_clock(rq))) { if (unlikely(!dl_is_implicit(dl_se) && !dl_time_before(dl_se->deadline, rq_clock(rq)) && !dl_se->dl_boosted)){ update_dl_revised_wakeup(dl_se, rq); return; } dl_se->deadline = rq_clock(rq) + pi_se->dl_deadline;//设置deadline为当前时刻加上相对的deadline 时间。 dl_se->runtime = pi_se->dl_runtime; } }而上面的函数的调用关系如下所示:
每次task enqueue的时候都会更新其deadline,然后在queue当中按照deadline进行排序。所以,deadline反映的是这个task最晚被执行的时间。
-
task的调度
static struct task_struct * pick_next_task_dl(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { struct sched_dl_entity *dl_se; struct dl_rq *dl_rq = &rq->dl; struct task_struct *p; WARN_ON_ONCE(prev || rf); if (!sched_dl_runnable(rq)) //rq->dl.dl_nr_running > 0 表明dl中没有task可以调度 return NULL; dl_se = pick_next_dl_entity(rq, dl_rq);//主要function BUG_ON(!dl_se); p = dl_task_of(dl_se); set_next_task_dl(rq, p, true); return p; } static struct sched_dl_entity *pick_next_dl_entity(struct rq *rq, struct dl_rq *dl_rq) { struct rb_node *left = rb_first_cached(&dl_rq->root);//#define rb_first_cached(root) (root)->rb_leftmost, 选取最左边的task if (!left) return NULL; return rb_entry(left, struct sched_dl_entity, rb_node); }如上面的code所示,每一次pick位于红黑树最左边的task.最左边的task意味着deadline最先到达的task.所以,理论上讲rb_leftmost代表最左边,应该会随着task的进入或者离开进行更新.如下的code所示:
* Leftmost-cached rbtrees. * * We do not cache the rightmost node based on footprint * size vs number of potential users that could benefit * from O(1) rb_last(). Just not worth it, users that want * this feature can always implement the logic explicitly. * Furthermore, users that want to cache both pointers may * find it a bit asymmetric, but that's ok. */ struct rb_root_cached { struct rb_root rb_root; struct rb_node *rb_leftmost; }; #define RB_ROOT_CACHED (struct rb_root_cached) { {NULL, }, NULL } /* Same as rb_first(), but O(1) */ #define rb_first_cached(root) (root)->rb_leftmost static inline void rb_insert_color_cached(struct rb_node *node, struct rb_root_cached *root, bool leftmost) { if (leftmost) root->rb_leftmost = node;//如前面的code所示,被__enqueue_dl_entity调用 rb_insert_color(node, &root->rb_root); } static inline void rb_erase_cached(struct rb_node *node, struct rb_root_cached *root) { if (root->rb_leftmost == node) root->rb_leftmost = rb_next(node); rb_erase(node, &root->rb_root); } static inline void rb_replace_node_cached(struct rb_node *victim, struct rb_node *new, struct rb_root_cached *root) { if (root->rb_leftmost == victim) root->rb_leftmost = new; rb_replace_node(victim, new, &root->rb_root); }另一个重要函数为set_next_task_dl:
static void set_next_task_dl(struct rq *rq, struct task_struct *p, bool first) { p->se.exec_start = rq_clock_task(rq); /* You can't push away the running task */ dequeue_pushable_dl_task(rq, p);//如注释讲那样,如果P要去running,这时候就不能被push,所以,要将其从pushable_dl_tasks_root中拿掉. if (!first) return; if (hrtick_enabled(rq)) start_hrtick_dl(rq, p);//启动一个硬件定时中断,稍候详细讨论 if (rq->curr->sched_class != &dl_sched_class) update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 0);//更新rq 的load deadline_queue_push_tasks(rq); }static void dequeue_pushable_dl_task(struct rq *rq, struct task_struct *p) { struct dl_rq *dl_rq = &rq->dl; if (RB_EMPTY_NODE(&p->pushable_dl_tasks))//pushable_dl_tasks为空,则返回. return; if (dl_rq->pushable_dl_tasks_root.rb_leftmost == &p->pushable_dl_tasks) {//因为p要被deqeueu出去,所以要更新最高deadline的task struct rb_node *next_node; next_node = rb_next(&p->pushable_dl_tasks); if (next_node) { dl_rq->earliest_dl.next = rb_entry(next_node, struct task_struct, pushable_dl_tasks)->dl.deadline; } } rb_erase_cached(&p->pushable_dl_tasks, &dl_rq->pushable_dl_tasks_root); RB_CLEAR_NODE(&p->pushable_dl_tasks); }pushable_dl_tasks中的task是什么时候被链入task的呢?
dl_rq->pushable_dl_tasks_root.rb_leftmost == &p->pushable_dl_tasks中的p的pushable_dl_tasks又是如何赋值的呢?/* * The list of pushable -deadline task is not a plist, like in * sched_rt.c, it is an rb-tree with tasks ordered by deadline. */ static void enqueue_pushable_dl_task(struct rq *rq, struct task_struct *p) { struct dl_rq *dl_rq = &rq->dl; struct rb_node **link = &dl_rq->pushable_dl_tasks_root.rb_root.rb_node; struct rb_node *parent = NULL; struct task_struct *entry; bool leftmost = true; BUG_ON(!RB_EMPTY_NODE(&p->pushable_dl_tasks)); while (*link) { parent = *link; /*#ifdef CONFIG_SMP struct plist_node pushable_tasks; struct rb_node pushable_dl_tasks; #endif */如上面所示,pushable_dl_tasks在task_struct当中其实也是一个rb_node,通过rb_node就可以获得其所在的task entry = rb_entry(parent, struct task_struct, pushable_dl_tasks); if (dl_entity_preempt(&p->dl, &entry->dl))//查找可以被抢占的sched_dl_entity.可以被抢占的条件为如后面所述,其主要是deadline比p的要大 link = &parent->rb_left; else { link = &parent->rb_right; leftmost = false; } } if (leftmost) dl_rq->earliest_dl.next = p->dl.deadline; rb_link_node(&p->pushable_dl_tasks, parent, link); rb_insert_color_cached(&p->pushable_dl_tasks, &dl_rq->pushable_dl_tasks_root, leftmost);//更新leftmost,方便后面获取最先到达的deadline } static inline bool dl_entity_preempt(struct sched_dl_entity *a, struct sched_dl_entity *b) { return dl_entity_is_special(a) || dl_time_before(a->deadline, b->deadline); } static inline bool dl_entity_is_special(struct sched_dl_entity *dl_se) { #ifdef CONFIG_CPU_FREQ_GOV_SCHEDUTIL return unlikely(dl_se->flags & SCHED_FLAG_SUGOV); #else return false; #endif }
在enqueue_task_dl函数的结尾有如下的调用:if (!task_current(rq, p) && p->nr_cpus_allowed > 1) enqueue_pushable_dl_task(rq, p);所以进入dl_rq->pushable_dl_tasks_root的条件为,当前task还不能被立即执行即要排队,同时,其允许run在多个cpu当中.
所以,这里有两颗红黑树了:
dl_rq->root保存所有enqueue进来的task,无论其是否Pushable
dl_rq->pushable_dl_tasks_root保存可以被push的task,主要是方便后面做负载均衡是用的.
start_hrtick_dl
如下的函数所示,这时候,启动了一个runtime之后的定时.#ifdef CONFIG_SCHED_HRTICK static void start_hrtick_dl(struct rq *rq, struct task_struct *p) { hrtick_start(rq, p->dl.runtime); }那么这个定时到了之后做什么呢?
/* * Called to set the hrtick timer state. * * called with rq->lock held and irqs disabled */ void hrtick_start(struct rq *rq, u64 delay) { struct hrtimer *timer = &rq->hrtick_timer; ktime_t time; s64 delta; /* * Don't schedule slices shorter than 10000ns, that just * doesn't make sense and can cause timer DoS. */ delta = max_t(s64, delay, 10000LL); time = ktime_add_ns(timer->base->get_time(), delta); hrtimer_set_expires(timer, time);//定时到了之后,执行hrtick_timer中的function,所以要查检这个function是什么 if (rq == this_rq()) { __hrtick_restart(rq); } else if (!rq->hrtick_csd_pending) { smp_call_function_single_async(cpu_of(rq), &rq->hrtick_csd); rq->hrtick_csd_pending = 1; } }而hrtick_timer在如下的函数中初始化:
static void hrtick_rq_init(struct rq *rq) { #ifdef CONFIG_SMP rq->hrtick_csd_pending = 0; rq->hrtick_csd.flags = 0; rq->hrtick_csd.func = __hrtick_start; rq->hrtick_csd.info = rq; #endif hrtimer_init(&rq->hrtick_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_HARD); rq->hrtick_timer.function = hrtick;//定时到了之后,会执行这个函数. } /* * High-resolution timer tick. * Runs from hardirq context with interrupts disabled. */ static enum hrtimer_restart hrtick(struct hrtimer *timer) { struct rq *rq = container_of(timer, struct rq, hrtick_timer); struct rq_flags rf; WARN_ON_ONCE(cpu_of(rq) != smp_processor_id()); rq_lock(rq, &rf); update_rq_clock(rq); rq->curr->sched_class->task_tick(rq, rq->curr, 1);//所以,关键是这个函数. rq_unlock(rq, &rf); return HRTIMER_NORESTART; } 在dl_sched_class当中: /* * scheduler tick hitting a task of our scheduling class. * * NOTE: This function can be called remotely by the tick offload that * goes along full dynticks. Therefore no local assumption can be made * and everything must be accessed through the @rq and @curr passed in * parameters. */ static void task_tick_dl(struct rq *rq, struct task_struct *p, int queued) { update_curr_dl(rq); update_dl_rq_load_avg(rq_clock_pelt(rq), rq, 1); /* * Even when we have runtime, update_curr_dl() might have resulted in us * not being the leftmost task anymore. In that case NEED_RESCHED will * be set and schedule() will start a new hrtick for the next task. */ if (hrtick_enabled(rq) && queued && p->dl.runtime > 0 && is_leftmost(p, &rq->dl)) start_hrtick_dl(rq, p); }而update_curr_dl函数如下所示:
/* * Update the current task's runtime statistics (provided it is still * a -deadline task and has not been removed from the dl_rq). */ static void update_curr_dl(struct rq *rq) { struct task_struct *curr = rq->curr; struct sched_dl_entity *dl_se = &curr->dl; u64 delta_exec, scaled_delta_exec; int cpu = cpu_of(rq); u64 now; if (!dl_task(curr) || !on_dl_rq(dl_se)) return; /* * Consumed budget is computed considering the time as * observed by schedulable tasks (excluding time spent * in hardirq context, etc.). Deadlines are instead * computed using hard walltime. This seems to be the more * natural solution, but the full ramifications of this * approach need further study. */ now = rq_clock_task(rq); delta_exec = now - curr->se.exec_start;//计算从上次统计之后,到现在running的时间 if (unlikely((s64)delta_exec <= 0)) { if (unlikely(dl_se->dl_yielded)) goto throttle; return; } schedstat_set(curr->se.statistics.exec_max, max(curr->se.statistics.exec_max, delta_exec));//统计执行的最长时间 curr->se.sum_exec_runtime += delta_exec; //计算总执行时间 account_group_exec_runtime(curr, delta_exec); curr->se.exec_start = now;//重新开始计时 cgroup_account_cputime(curr, delta_exec);//看上去和cgroup相关,后面再研究 if (dl_entity_is_special(dl_se))//特殊的task return; /* * For tasks that participate in GRUB, we implement GRUB-PA: the * spare reclaimed bandwidth is used to clock down frequency. * * For the others, we still need to scale reservation parameters * according to current frequency and CPU maximum capacity. */ if (unlikely(dl_se->flags & SCHED_FLAG_RECLAIM)) { scaled_delta_exec = grub_reclaim(delta_exec, rq, &curr->dl);//采用grub的方式统计delta } else { unsigned long scale_freq = arch_scale_freq_capacity(cpu); unsigned long scale_cpu = arch_scale_cpu_capacity(cpu); scaled_delta_exec = cap_scale(delta_exec, scale_freq); scaled_delta_exec = cap_scale(scaled_delta_exec, scale_cpu);//按cpu频率及能力进行归一化。这种归一化,可以屏蔽掉大核或者小核的差异。 } dl_se->runtime -= scaled_delta_exec;//所以,runtime指的是按cpu能力归一化的时间。 throttle: if (dl_runtime_exceeded(dl_se) || dl_se->dl_yielded) {//判断throttle的条件 (dl_se->runtime <= 0) dl_se->dl_throttled = 1; /* If requested, inform the user about runtime overruns. */ if (dl_runtime_exceeded(dl_se) && (dl_se->flags & SCHED_FLAG_DL_OVERRUN)) dl_se->dl_overrun = 1; __dequeue_task_dl(rq, curr, 0);//将当前task从dl_rq->root及dl_rq->pushable_dl_tasks_root中拿掉 if (unlikely(dl_se->dl_boosted || !start_dl_timer(curr)))//如果有被boost,直接重新enqueue,如果没有被boost就启动timer,timer到达的时间为下一个周期。下一个周期到来的时候,会取消throttle,然后重新enqueue. enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH); if (!is_leftmost(curr, &rq->dl))//如果有新的deadline最早的就调度新的最早deadline的task. resched_curr(rq); } /* * Because -- for now -- we share the rt bandwidth, we need to * account our runtime there too, otherwise actual rt tasks * would be able to exceed the shared quota. * * Account to the root rt group for now. * * The solution we're working towards is having the RT groups scheduled * using deadline servers -- however there's a few nasties to figure * out before that can happen. */ if (rt_bandwidth_enabled()) { struct rt_rq *rt_rq = &rq->rt; raw_spin_lock(&rt_rq->rt_runtime_lock); /* * We'll let actual RT tasks worry about the overflow here, we * have our own CBS to keep us inline; only account when RT * bandwidth is relevant. */ if (sched_rt_bandwidth_account(rt_rq)) rt_rq->rt_time += delta_exec; raw_spin_unlock(&rt_rq->rt_runtime_lock); } }所以update_cur_dl做了如下的事情:
1. 更新当前task的sum_exec_runtime
2.对runtime做扣除
3.触发throttle机制
throttle之后,将当前task dequeueu。
对于throttle的task, 还没有消除throttle不会重新enqueue如下的code所示:/* * If p is throttled, we do not enqueue it. In fact, if it exhausted * its budget it needs a replenishment and, since it now is on * its rq, the bandwidth timer callback (which clearly has not * run yet) will take care of this. * However, the active utilization does not depend on the fact * that the task is on the runqueue or not (but depends on the * task's state - in GRUB parlance, "inactive" vs "active contending"). * In other words, even if a task is throttled its utilization must * be counted in the active utilization; hence, we need to call * add_running_bw(). */ if (p->dl.dl_throttled && !(flags & ENQUEUE_REPLENISH)) { if (flags & ENQUEUE_WAKEUP) task_contending(&p->dl, flags); return; }取消throttle的时间为下一个时间周期:
如在上面的update_cur_dl中:
if (unlikely(dl_se->dl_boosted || !start_dl_timer(curr))) enqueue_task_dl(rq, curr, ENQUEUE_REPLENISH);如果task有被boost,直接以replenish(重新填充)的方式重新enqueue task.如果没有被boost,则启动timer:
/* * If the entity depleted all its runtime, and if we want it to sleep * while waiting for some new execution time to become available, we * set the bandwidth replenishment timer to the replenishment instant * and try to activate it. * * Notice that it is important for the caller to know if the timer * actually started or not (i.e., the replenishment instant is in * the future or in the past). */ static int start_dl_timer(struct task_struct *p) { struct sched_dl_entity *dl_se = &p->dl; struct hrtimer *timer = &dl_se->dl_timer; struct rq *rq = task_rq(p); ktime_t now, act; s64 delta; lockdep_assert_held(&rq->lock); /* * We want the timer to fire at the deadline, but considering * that it is actually coming from rq->clock and not from * hrtimer's time base reading. */ act = ns_to_ktime(dl_next_period(dl_se));//时间为下一个周期。dl_se->deadline - dl_se->dl_deadline + dl_se->dl_period; now = hrtimer_cb_get_time(timer); delta = ktime_to_ns(now) - rq_clock(rq); act = ktime_add_ns(act, delta); /* * If the expiry time already passed, e.g., because the value * chosen as the deadline is too small, don't even try to * start the timer in the past! */ if (ktime_us_delta(act, now) < 0) return 0; /* * !enqueued will guarantee another callback; even if one is already in * progress. This ensures a balanced {get,put}_task_struct(). * * The race against __run_timer() clearing the enqueued state is * harmless because we're holding task_rq()->lock, therefore the timer * expiring after we've done the check will wait on its task_rq_lock() * and observe our state. */ if (!hrtimer_is_queued(timer)) { get_task_struct(p); hrtimer_start(timer, act, HRTIMER_MODE_ABS_HARD); } return 1; }根据如下的函数dl_next_period对下一个周期的计算方法:
static inline u64 dl_next_period(struct sched_dl_entity *dl_se) { return dl_se->deadline - dl_se->dl_deadline + dl_se->dl_period; } 因为dl_se->deadline的计算方式为:
dl_se->deadline = rq_clock(rq) + pi_se->dl_deadline;所以正常情况,下一个周期实际上是距离当前task enqueue的时间点加上period。因此,period反映两次task enqueue的时间间隔。
当下一个周期到来时:/* * This is the bandwidth enforcement timer callback. If here, we know * a task is not on its dl_rq, since the fact that the timer was running * means the task is throttled and needs a runtime replenishment. * * However, what we actually do depends on the fact the task is active, * (it is on its rq) or has been removed from there by a call to * dequeue_task_dl(). In the former case we must issue the runtime * replenishment and add the task back to the dl_rq; in the latter, we just * do nothing but clearing dl_throttled, so that runtime and deadline * updating (and the queueing back to dl_rq) will be done by the * next call to enqueue_task_dl(). */ static enum hrtimer_restart dl_task_timer(struct hrtimer *timer) { struct sched_dl_entity *dl_se = container_of(timer, struct sched_dl_entity, dl_timer); struct task_struct *p = dl_task_of(dl_se); struct rq_flags rf; struct rq *rq; rq = task_rq_lock(p, &rf); /* * The task might have changed its scheduling policy to something * different than SCHED_DEADLINE (through switched_from_dl()). */ if (!dl_task(p)) goto unlock; /* * The task might have been boosted by someone else and might be in the * boosting/deboosting path, its not throttled. */ if (dl_se->dl_boosted) goto unlock; /* * Spurious timer due to start_dl_timer() race; or we already received * a replenishment from rt_mutex_setprio(). */ if (!dl_se->dl_throttled) goto unlock; sched_clock_tick(); update_rq_clock(rq); /* * If the throttle happened during sched-out; like: * * schedule() * deactivate_task() * dequeue_task_dl() * update_curr_dl() * start_dl_timer() * __dequeue_task_dl() * prev->on_rq = 0; * * We can be both throttled and !queued. Replenish the counter * but do not enqueue -- wait for our wakeup to do that. */ if (!task_on_rq_queued(p)) {//针对非on_rq状态,重新填充待新的wakeup并重新enqueue replenish_dl_entity(dl_se, dl_se); goto unlock; } #ifdef CONFIG_SMP if (unlikely(!rq->online)) { /* * If the runqueue is no longer available, migrate the * task elsewhere. This necessarily changes rq. */ lockdep_unpin_lock(&rq->lock, rf.cookie); rq = dl_task_offline_migration(rq, p); rf.cookie = lockdep_pin_lock(&rq->lock); update_rq_clock(rq); /* * Now that the task has been migrated to the new RQ and we * have that locked, proceed as normal and enqueue the task * there. */ } #endif //如果已经是on rq状态,则启动重新填充的enqueue.在update_curr_dl中,如果runtime消耗完之后,会将task dequeue出队列。 enqueue_task_dl(rq, p, ENQUEUE_REPLENISH); if (dl_task(rq->curr)) check_preempt_curr_dl(rq, p, 0); else resched_curr(rq); #ifdef CONFIG_SMP /* * Queueing this task back might have overloaded rq, check if we need * to kick someone away. */ if (has_pushable_dl_tasks(rq)) { /* * Nothing relies on rq->lock after this, so its safe to drop * rq->lock. */ rq_unpin_lock(rq, &rf); push_dl_task(rq); rq_repin_lock(rq, &rf); } #endif unlock: task_rq_unlock(rq, p, &rf); /* * This can free the task_struct, including this hrtimer, do not touch * anything related to that after this. */ put_task_struct(p); return HRTIMER_NORESTART; }根据上述信息,可以猜测runtime小于period,runtime表示一个period周期内,需要run的时间。而deadline表示:
如在__checkparam_dl函数中:/* runtime <= deadline <= period (if period != 0) */ if ((attr->sched_period != 0 && attr->sched_period < attr->sched_deadline) || attr->sched_deadline < attr->sched_runtime) return false;这是符合前面讲的deadline与period、runtime表示的含义。
-
Summary
本文主要追踪了deadline关于task的管理与task的调度。大概理解了task的原理。后面有时间再跟踪一下deadline的boost机制与bw管理机制。