mysql常见问题集锦
mysql常见问题集锦
一、数据类型相关问题
1、varchar(N)占用多少空间
(1)varchar(N)里的N是字符数,而不是字节数;
(2)字符类型(varchar text blob等)空间=字符实际长度+字段长度;
(3)varchar(N)占用的空间:
如果是lantin1字符集时,最大空间=1N+(1 or 2)bytes,因为lantin1的1个字符占用1个字节,后面加的1或2bytes是用来表示字段长度的,当可能超过255个字节时,要2个bytes来表示字段长度;
如果是utf8字符集时,最大空间=3N+(1 or 3)bytes,因为utf8的1个字符占用3个字节,后面加的1或2bytes是用来表示字段长度的,当可能超过255字节时,要2个bytes来表示字段长度;
(4)当varchar(N)可能超过255字节时,字段长度=2;
例子:varchar(100)字符集为utf8时,’aaaa‘分别占用几个字节?
因为:varchar(100)如果存储中文的话,将占用3100 >225个字节,因此,需要2个字节来表示字段长度
’aaaa‘占用的空间=3100+2=302bytes
(5)补充: 

2、char和varchar(N)类型的区别:
(1)char最大可表示255个字符,而varchar的总长度不能超过65535个字节(bytes),最大支持字符数根据字符集不同而不同;
(2)char会截掉尾部空字符串,而varchar不会截掉尾部空字符串;
(3)”char固定长度,varchar变长“这种说法对于innodb存储引擎是错误的。
innodb中是根据row_format来决定的: 
除了redundant外,在处理多字节字符集(gbk utf8等)char字段时,innodb都会当成变长字符来处理,单字节的则仍然分配固定长度空间;也就是说,utf8 gbk字符集的char和varchar一致,都是变长的,而lantin1字符集的char类型是固定长度的。
【总结】
使用innodb存储引擎,对于常用的字符集gbk或utf8,char和varchar没区别,建议用varhcar类型。
3、varchar和text都可以表示长字符,且都是实际多少字符就占用多少空间,那需要存储多长字符串时,是选择varchar还是text呢?
(1)功能方面:
varchar长度有限制,所有char和varchar字段总和不能超过65535字节;且varchar可以有默认值。
而text类型最长可以存储4G,且text不能设置默认值;
【如何选择】
a、如果表中有太多长字段,可能无法将所有字段都建为varchar(例如,所有字段建立为varhcar大于65535字节的时候),可以结合varchar和text使用。
b、如果字段需要有默认值,那么使用varchar。
(2)性能方面:
有一种常见说法是“text字段是溢出字段,而varchar不会溢出,所以varchar更高效”======这种说法不完全对,因为text字段不一定溢出,只有当一整个行长度无法存入页中,可能会将最长的字段将余下行链接到其他页,这一点上text和varchar都是一样的 ;
text字段无法利用tmp_table_size内存排序,直接磁盘排序(using filesort);
3、存储字符串推荐选择使用varchar(N),N尽量小,为什么?
varchar(10)和varchar(100)为例子:
引擎层(磁盘存储与buffer pool)空间使用上两种是相同的;
server层处理数据时并非按照实际大小分配内存。
一些操作:排序、表DDL,varchar(100)会使用更多的磁盘和内存空间,效率会更低;
因为:server层并不知道引擎层数据是怎么组织的,各引擎组织方式肯定不一样,server层在分配内存时使用的是表定义时的长度,一些需要在server处理数据的操作都可能会受到影响!比如排序、加索引时会使用更多内存(tmp_table_size)或磁盘空间,性能受到影响。
4、int(11),给int指定长度有什么意义?
int(11)和int(4)为例子:
(1)int(11)和int(4)没有区别,只有在字段定义时加了zerofill属性,显示字段值时不足指定宽度会补0,但是zerofill几乎不用;
【补充】
默认int就是int(11),这是有符号的整型,如果是无符号整型则是int(10)
===========================================
二、锁相关问题
innodb存储引擎的锁按照锁粒度分:行级锁、表级锁两种;按照锁模式分:共享锁、独占锁;
行级锁分为:记录锁、间隙锁(gap key)、next-key锁(记录锁+间隙锁);
1、行级锁
(1)概念:
行级锁是MySQL中粒度最小的一种锁,他能大大减少数据库操作的冲突。但是粒度越小,实现的成本也越高。MYISAM引擎只支持表级锁,而INNODB引擎能够支持行级锁。
(2)innodb的行级锁的三种类型:
(2.1)记录锁:是加在索引记录上的;
(2.2)间隙锁:gap lock,对索引记录间的范围加锁,或者加在最后一个索引记录的前面或后面;间隙锁主要是防止幻读,用在Repeated-read(简称RR)隔离级别下,在Read-commited(简称RC)下,一般没有间隙锁(外键情况下例外)。且间隙锁只会出现在辅助索引上,唯一索引和主键索引没有间隙锁。间隙锁(无论是S还是X)都只会阻塞insert操作。
(2.3)Next-key锁:记录锁和间隙锁的组合,间隙锁锁定记录锁之前的范围;
(3)行级锁又分为共享锁和排他锁
INNODB的行级锁有共享锁(S LOCK)和排他锁(X LOCK)两种。共享锁允许多个线程读同一行记录,不允许任何线程对该行记录进行修改。排他锁允许当前线程删除或更新一行记录,其他线程不能操作该记录。
(4)共享锁
【用法】: SELECT … LOCK IN SHARE MODE; MySQL会对查询结果集中每行都添加共享锁。
【 锁申请前提】:当前没有线程对该结果集中的任何行使用排他锁,否则申请会阻塞。
【操作限制】:如下是,使用共享锁和不使用共享锁的线程,对锁定记录操作的限制 
(4.1) 使用共享锁线程可对其锁定记录进行读取,其他线程同样也可对锁定记录进行读取操作,并且这两个线程读取的数据都属于同一个版本。
(4.2) 对于写入操作,使用共享锁的线程需要分情况讨论,当只有当前线程对指定记录使用共享锁时,线程是可对该记录进行写入操作(包括更新与删除),这是由于在写入操作前,线程向该记录申请了排他锁,然后才进行写入操作;当其他线程也对该记录使用共享锁时,则不可进行写入操作,系统会有报错提示。不对锁定记录使用共享锁的线程,当然是不可进行写入操作了,写入操作会阻塞。
(4.3)使用共享锁进程可再次对锁定记录申请共享锁,系统并不报错,但是操作本身并没有太大意义。其他线程同样也可以对锁定记录申请共享锁。
(4.4)使用共享锁进程可对其锁定记录申请排他锁;而其他进程是不可以对锁定记录申请排他锁,申请会阻塞。
(5)排他锁:
【用法】: SELECT … FOR UPDATE; MySQL会对查询结果集中每行都添加排他锁,在事物操作中,任何对记录的更新与删除操作会自动加上排他锁。
【锁申请前提】:当前没有线程对该结果集中的任何行使用排他锁或共享锁,否则申请会阻塞。
【操作限制】:如下是,使用排他锁和不使用排他锁的线程,对锁定记录操作限制 
(5.1)使用排他锁线程可以对其锁定记录进行读取,读取的内容为当前事物的最新版本;而对于不使用排他锁的线程,同样是可以进行读取操作,这种特性是一致性非锁定读。即对于同一条记录,数据库记录多个版本,在事物内的更新操作会反映到新版本中,而旧版本会提供给其他线程进行读取操作。
(5.2)使用排他锁线程可对其锁定记录进行写入操作;对于不使用排他锁的线程,对锁定记录的写操作是不允许的,请求会阻塞。
(5.3)使用排他锁进程可对其锁定记录申请共享锁,但是申请共享锁之后,线程并不会释放原先的排他锁,因此该记录对外表现出排他锁的性质;其他线程是不可对已锁定记录申请共享锁,请求会阻塞。
(5.4)使用排他锁进程可对其锁定记录申请排他锁(实际上并没有任何意义);而其他进程是不可对锁定记录申请排他锁,申请会阻塞。
(6)SQL里的锁使用情况举例
(6.1)delete from t where id=10;该SQL会在主键索引(id=10)上加记录锁,锁住记录行,且是独占锁(意向独占锁,ix);
(6.2)select * from t where id=10 lock in shared mode;该SQL会在主键索引(id=10)上加j记录锁,锁住记录,且是共享锁(意向共享锁,is);
(6.3)insert into t values(12,1);该SQL会在insert前会加一个insert intention gap lock,这个锁是允许并发但是不允许id同值的并发。理解上就是:允许其他insert语句,但是不允再对id=12做并发插入;insert后在(12,1)上加记录锁。
(6.4)RR模式下create table P as select * from T;这个SQL里会对表T加锁,加共享的Next-key lock,锁住T表所有记录以及间隙锁;
(6.5)RC模式下create table P as select * from T;这个SQL不会对T表加锁,对T表做一致性读(快照读);
2、表级锁
(1)概念
表级锁是MySQL中粒度最大的一种锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。
(2)表级锁的类型
表级锁定分为两类:读锁与写锁。读锁是预期将对数据表进行读取操作,锁定期间保证表不能被修改。写锁是预期会对数据表更新操作,锁定期间保证表不能被其他线程更新或读取。
(3)读锁
【用法】:LOCK TABLE table_name [ AS alias_name ] READ; 指定数据表,LOCK类型为READ即可,AS别名是可选参数,如果指定别名,使用时也要指定别名才行。
【申请读锁前提】:当前没有线程对该数据表使用写锁,否则申请会阻塞。
【操作限制】:其他线程可以对锁定表使用读锁;其他线程不可以对锁定表使用写锁 
对于使用读锁的MySQL线程,由于读锁不允许任何线程对锁定表进行修改,在释放锁资源前,该线程对表操作只能进行读操作,写操作时会提示非法操作。而 对于其他没使用锁的MySQL线程,对锁定表进行读操作可以正常进行,但是进行写操作时,线程会等待读锁的释放,当锁定表的所有读锁都释放时,线程才会响 应写操作。
(4)写锁
【用法】:LOCK TABLE table_name [AS alias_name] [ LOW_PRIORITY ] WRITE;别名用法与读锁一样,写锁增加了指定优先级的功能,加入LOW_PRIORITY可以指定写锁为低优先级。
【申请写锁前提】:当没有线程对该数据表使用写锁与读锁,否则申请回阻塞。
【操作限制】:其他MySQL线程不可以对锁表使用写锁、读锁 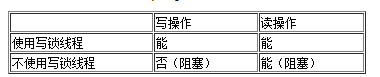
对于使用写锁的MySQL线程,当前线程可以对锁定表进行读写操作。但是对于其他线程,对指定表读写操作都是非法的,需要等待直到写锁释放。
(5)读锁和写锁的优先级关系
对于锁分配的优先级是: LOW_PRIORITY WRITE < READ < WRITE
(5.1)当多个线程申请锁,会优先分配给WRITE锁,不存在WRITE锁时,才分配READ锁,LOW_PRIORITY WRITE需要等到WRITE锁与READ都释放后,才有机会分配到资源。
(5.2)对于相同优先级的锁申请,分配原则为谁先申请,谁先分配。
(6)其他注意事项
(6.1)不能操作(查询或更新)没有被锁定的表。
例如:当只申请table1的读锁,SQL语句中包含对table2的操作是非法的:
mysql> LOCK TABLE test READ;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM test_myisam;
ERROR 1100 (HY000): Table 'test_myisam' was not locked with LOCK TABLES
(6.2)不能在一个SQL中使用两次表(除非使用别名)
当SQL语句中多次使用一张表时,系统会报错。例如:
mysql> LOCK TABLE test READ;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM test WHERE id IN (SELECT id FROM test );
ERROR 1100 (HY000): Table 'test' was not locked with LOCK TABLES
解决这个问题的方法是使用别名,如果多次使用到一个表,需要声明多个别名。
mysql> LOCK TABLE test AS t1 READ, test AS t2 READ;
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM test AS t1 WHERE id IN (SELECT id FROM test AS t2);
(6.3)申请锁时使用别名,使用锁定表时必须加上别名。
三、性能相关问题
1、null在B+tree里是如何存储的?为什么推荐为每个字段设置默认值而不使用null??
1)、不同数据处理null方式不同,但查询时任何数据库对于允许null值的字段处理比较复杂。
2)、对于innodb类型的表来说,innodb记录(索引)头包含一个null位图,标志哪些字段是null,innodb中字段为null值可以存在索引中,索引中null值被当成一个值处理;oracle里则不会,oracle里索引中不会收录为null的值;
3)、null无法做比较(< > !=等)可能出现“数据丢失”,只能is null来判断!
例子:select …from …where a is null;这个sql在mysql里可以利用索引,oracle则不行;
综合以上,推荐字段里设置默认值,而不使用null;
2、外键约束,在相比与程序做的判断约束下,二者哪种性能更高?实际生产环境是否建议使用外键约束??
现在的应用都讲究快速迭代,表结构变化很频繁,如果用了主外键会非常困难和麻烦。
在进行线上加载或清理工作,如果用了主外键,数据维护会很麻烦;主外键有时候也并不能覆盖业务逻辑约束。
综合考虑是:性能要求高,并发大,数据多的场景下,尽可能不要使用外键约束。类似的:主外键、触发器、函数、存储过程等都不推荐使用,尽量保持数据库“简单”。
3、子查询 VS join
1)子查询分为:非关联字查询(子查询里没有外表依赖)、关联子查询(子查询里有外表依赖) 
2)子查询写起来简单,可读性较好(子查询较少时),join要实现子查询功能比较难写
例子:子查询改写成join
(非关联子查询)select * from t1 where t1.a in (select t2.a from t2 where t2.b=1);
等价于
select t1.* from t1,(select distinct a from t2 where b=1) t3
where t3.a=t1.a;
(关联子查询)select * from t1 where t1.a in (select t2.a from t2 where t2.b=t1.b);
等价于
select t1.* from t1.(select distinct a from t2 where t2) t3 where t3.a=t1.a and t3.b=t1.b;
子查询改写成join,其实join里还是有一个子查询的(作为临时表),而且改成join后SQL复杂很多。 
【总结】
mysql使用next loop方式进行join;
子查询中t1,t2无法正确使用索引;
外表驱动子(查询)表,这里t1驱动t2表;要尽量使外表数据小,如果外表是大表则效率会非常差;
对于不带子查询的join,mysql可以使用合理的索引和驱动表;
mysql5.6之后,对子查询做了优化:子表只查一次,并将结果集存储在临时hash表,需要设置优化器参数optimizer_switch来优化;
【建议】
mysql的子查询效率通常比较低,能用(不带字查询的)join尽量使用join;否则建议将查询频率非常高的复杂查询拆分成多条简单查询,通过提升系统并发来达到优化目的。
也说明:不带子查询的join性能才比子查询好,带了子查询的join效率依旧差。
4、视图的性能
视图仅推荐在做权限控制,非线上业务查询的时候使用。
5、mysql极限
1)mysql单表字段一般多少比较合适?超过多少会出现严重性能问题?
innodb最大支持1000个字段,出现性能问题通常不是简单因为字段过多导致,与之相对通常是字段组合不合理导致。
建议根据业务查询习惯指定最合理简练的表结构。
2)mysql一个数据库多少张表比较合适?
mysql会为每张表分配数据文件(独立表空间)与表定义文件;
表过多时需要更多资源,需要调节部分参数(innodb_open_file open_file_limit table_open_cache等参数)
mysql查询时都会开表以及关表。太多表可能导致操作变慢;
建议按照业务模块拆分到不同实例;
转载:http://www.cnblogs.com/zhoubaojian/articles/7866227.html