zookeeper轻松入门
zookeeper的必要性
开源的大数据系统,如Hadoop、HIVE等等,类似于动物园,难以管理。

zookeeper扮演动物管理员的角色出现,对分布式系统进行协调。

典型应用场景
◎分布式通知/协调
用于分布式系统的任务分发与任务执行结果反馈
◎集群管理
zookeeper可以监控节点的存活状态
◎master选举
maser/slave结构系统中,避免单点故障,需要多个master,其中只有一个active master,zookeeper帮助选择active master
◎分布式锁
—独占:某一时刻只有一个client能够获得
—控制时序:多个客户端的某些过程按照顺序执行
分布式队列
… …
架构
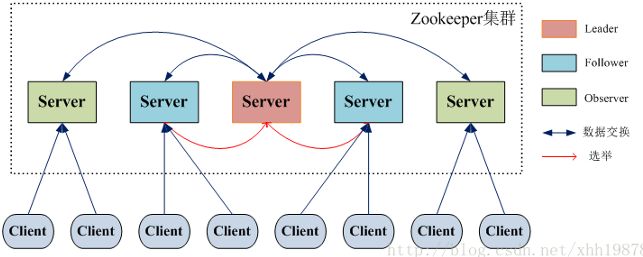
zookeeper由2N+1个server组成,只要保证至少N+1个节点可用时,整个系统就可正常运行。
Server角色类型
Leader:不接受client的请求,负责进行投票的发起和决议,最终更新状态
Follwer:接收客户端请求并返回客户结果,参与Leader发起的投票
Observer:和Follwer类似,同client进行交互,存有数据副本,但不参与投票
leader和各个follower是互相通信的,对于zk系统的数据都是保存在内存里面的,同样也会备份一份在磁盘上。对于每个节点而言,命名空间是一样的,即他们有同样的数据。其中leader是唯一的,其他都是learner(follower+observer),如果leader挂了,zk集群会重新选举。超过一半以上的zk节点挂了,则zk service不可用。
数据结构
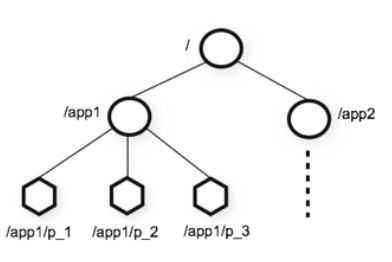
类似于文件系统结构,呈树状,保证每个节点的唯一性。不同的是所有节点都称为ZNode,既可以包含子节点,也可以包含数据。图中为6个ZNode。
ZNode类型
在创建znode节点的时候,可以根据需求制定其类型。主要有以下几种:
◎PERSISTENT:持久化znode节点,一旦创建不会主动消失,除非客户端主动删除。
◎SEQUENCE:顺序增加编号节点。类似于id自增,假如已经有节点/servers/server0000000000,再新建一个节点则为/servers/server0000000001,依次类推,以后任意client创建znode都会得到一个比当前路径下最大znode编号+1的节点。
◎PERSISTENT|SEQUENCE:正如定义一样,此类型是前两种的结合。即顺序自增的持久化znode节点。这种节点会根据当前已存在的最大znode节点自动+1编号,且不会随着session的断开而消失。
◎EPHEMERAL:临时znode节点,依附于client建立的连接存在。client连接到zk service会建立一个session并建立临时节点。一旦client关闭zk的连接,session被服务器清除,同时该临时节点也被删除。
◎EPHEMERAL|SEQUENCE:临时自增编号节点,znode节点会自动增加,同时也会随session的消失而消失。
数据交互
读
集群中所有zk节点的本地副本数据都是一致的,因此读取数据时可直接读取client连接的server内存中数据即可
更新
相对读操作,更新过程较复杂,如图所示
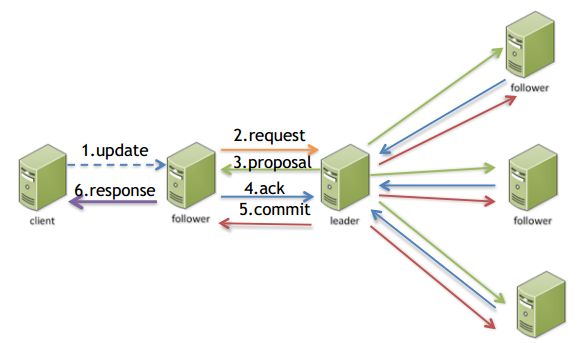
1)client向server发送更新请求
2)server向leader转发更新请求
3)leader向follower发起proposol过程
4)follower执行并反馈结果
5)leader接收响应,超过一半返回成功,则认为成功,否则认为失败。并将结果反馈给client连接到的server
6)server将结果反馈给client
正如上述过程,随着client请求变多,zk集群变大时,follower的压力变大,同时更新的成本变大,因为在投票的过程中,所有的follower都要在本地执行伪更新操作并将结果反馈给leader,超过一半返回成功leader才认为更新成功了,等待时间长。
解决方案:增加observer节点。observer节点只是为了扩展系统,提高读取速度。同follower类似,可以接收客户端连接请求,将写请求转发给leader。但是observer不参加投票,只同步leader的状态。意思也就是说在客户端发送一个更新请求时,observer对于leader发起的protosol是屏蔽的,它不会做任何操作。只静静的等着最后分享投票结果就OK了。
zookeeper特性
◎顺序性
client的update请求都会根据它发出的顺序被顺序性的处理
◎原子性
一个update操作要么成功要么失败,没有其他
◎强一致性
client无论连接到哪个server,展示给它的都是同一个视图,即所有server包括observer在内的数据都是一致的
◎可靠性
update一旦成功,就被持久化了。除非另一个update请求更新当前值
◎实时性
对于每一个client,它的系统视图都是最新的