第二章 端对端的机器学习项目 Part II
这篇文章是本人学习 《Hands-On-Machine-Learning-with-Scikit-Learn-and-TensorFlow》的读书笔记第二篇。整理出来是希望在巩固自己的学习效果的同时,希望能够帮助到同样想学习的人。本人也是小白,可能很多地方理解和翻译不是很到位,希望大家多多谅解和提意见。
4. 为机器学习算法准备数据
把特征和目标值分开,方便后续做特征转换。
housing = strat_train_set.drop('median_house_value',axis=1) #删除目标值
housing_labels = strat_train_set['median_house_value'].copy()
数据清洗
total_bedrooms 属性中存在缺失值,缺失值的处理:
- 删除有缺失值的数据点
- 删除整个 total_bedrooms 属性
- 用值来填充缺失值(0,平均数,中位数等)
housing.dropna(subset['total_bedrooms']) #option1
housing.drop('total_bedrooms',axis=1) #option2
median = housing['total_bedrooms'].median()
housing['total_bedrooms'].fillna(median) #option3
使用第三种方法来填充缺失值时,在测试集上也应该使用同样的中位数值填充缺失值。使用 Scikit-Learn 的 Imputer来实现缺失值的填充。
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
#create an imputer instances
imputer = SimpleImputer(strategy='median') #specify median method
housing_num = housing.drop("ocean_proximity", axis=1) #drop non-numerical attribute
imputer.fit(housing_num) #fit the imputer instance to the training data
X = imputer.transform(housing_num) #replacing missing values with learned medians
housing_tr = pd.DataFrame(X, columns=housing_num.columns,index=housing.index) #convert Numpy arrays into pandas dataframe
文本和类别数据的处理
使用 Scikit-Learn 的 LabelEncoder 将文本数据转变为数值型数据。
try:
from sklearn.preprocessing import OrdinalEncoder
except ImportError:
from future_encoders import OrdinalEncoder # Scikit-Learn < 0.20
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
ordinal_encoder.categories_
[array(['<1H OCEAN', 'INLAND', 'ISLAND', 'NEAR BAY', 'NEAR OCEAN'],
dtype=object)]
Scikit-Learn 中提供 OneHotEncoder 编码可以将字符型的类别变量转换成独热编码的向量。
try:
from sklearn.preprocessing import OrdinalEncoder # just to raise an ImportError if Scikit-Learn < 0.20
from sklearn.preprocessing import OneHotEncoder
except ImportError:
from future_encoders import OneHotEncoder # Scikit-Learn < 0.20
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
housing_cat_1hot
<16512x5 sparse matrix of type ''
with 16512 stored elements in Compressed Sparse Row format>
得到的 housing_cat_1hot 是一个SciPy格式的稀疏矩阵而不是一个 NumPy的数组,可以使用 toarray()的方法将它转换为稠密的 Numpy 数组。
housing_cat_1hot.toarray()
自定义转换器
使用 Scikit-Learn的 FunctionTransformer类可以基于转换函数构建转换器。
from sklearn.preprocessing import FunctionTransformer
def add_extra_features(X, add_bedrooms_per_room=True):
rooms_per_household = X[:, rooms_ix] / X[:, household_ix]
population_per_household = X[:, population_ix] / X[:, household_ix]
if add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = FunctionTransformer(add_extra_features, validate=False,
kw_args={'add_bedrooms_per_room':False})
housing_extra_attribs = attr_adder.fit_transform(housing.values)

特征缩放
机器学习算法的效果不会太好,当各特征的取值在不同范围时,我们的数据集中total_rooms 的特征取值为[6,39320],median_income的取值为[0,15]。注意,一般目标值是不需要做特征缩放的。常见的特征缩放的方法有最小-最大值缩放,标准化。
- Min-max Scaling:(num - min)/ (max - min),使数据缩放到(0,1)。Scikit-Learn 中提供了 MinMaxScaler可实现该功能。
- Standardization:(num - mean)/ variance。不像 Min-max Scaling把数据缩放到0-1的范围,标准化将数据缩放到0均值,单位方差。这对于像神经网络这种希望收入范围在0-1之间的模型来说,标准化可能不是最佳。但是标准化对异常值不敏感,假如median_income中有个错误值为100,则 min-max scaling会将数据缩放到(0,0.15)的范围,而影响数据整体的分布。Scikit-Learn 中提供了StandardScaler实现标准化缩放。
Transformation Pipelines
Scikit-Learn 中提供了 Pipeline类来完成转换序列,使得程序能够按顺序执行每个转换。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer',Imputer(strategy='median')),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
同样,我们也可以为类别型的变量设置 transformer pipeline。Scikit-Learn 中提供了ColumnTransformer 类整合数值型和类别型的转换器。传入一个转换器的列表,当需要用到 fit()或者transform()的方法时,它并行地运行各个转换器的 fit()或者transform()方法,然后等待他们的结果并最终把他们合并到一起输出。
try:
from sklearn.compose import ColumnTransformer
except ImportError:
from future_encoders import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ['ocean_proximity']
full_pipeline = ColumnTransformer([
('num', num_pipeline, num_attribs),
('cat', OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
5 在训练集上进行训练和验证
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
在部分数据上查看预测效果
# try it out on some training instances
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data) #data transformation
print('Predictions:\t\t', lin_reg.predict(some_data_prepared))
使用 Scikit-Learn 中的 mean_squared_error函数,计算 RMSE。
# calculate the mean_squared_error
from sklearn.metrics import mean_squared_error
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels,housing_predictions)
lin_rmse = np.sqrt(lin_mse)
使用 Scikit-Learn 中的 mean_absolute_error函数,计算 MAE。
# calculate the mean_absolute_error
from sklearn.metrics import mean_absolute_error
lin_mae = mean_absolute_error(housing_labels, housing_predictions)
计算后发现 RMSE和 MAE都很多,考虑可能是模型欠拟合,使用决策树算法对数据进行拟合。
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_mse = np.sqrt(tree_mse)
此时计算出来的 tree_mse 为 0。很明显,决策树算法过拟合了。
6 微调模型
计算交叉验证的得分
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring='neg_mean_squared_error', cv=10)
tree_rmse_scores = np.sqrt(-scores)
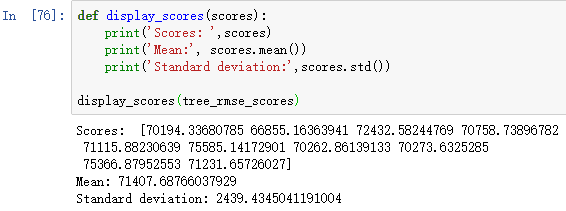
计算线性回归的交叉验证得分。
# cross validation scores for linear regression
lin_scores = cross_val_score(lin_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
使用随机森林来作预测,同时计算其交叉验证得分。
# choose Random Forest as a regressor
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor(n_estimators=10, random_state=42)
forest_reg.fit(housing_prepared, housing_labels)
# calculate the mean_squared_error for Random Forest Regressor
housing_predictions = forest_reg.predict(housing_prepared)
forest_mse = mean_squared_error(housing_labels, housing_predictions)
forest_rmse = np.sqrt(forest_mse)
forest_scores = cross_val_score(forest_reg, housing_prepared,housing_labels,
scoring='neg_mean_squared_error',cv=10)
forest_rmse_scores = np.sqrt(-forest_scores)
display_scores(forest_rmse_scores)
使用线性核的SVM作为分类器,并计算其 RMSE。
from sklearn.svm import SVR
svm_reg = SVR(kernel='linear')
svm_reg.fit(housing_prepared, housing_labels)
housing_predictions = svm_reg.predict(housing_prepared)
svm_mse = mean_squared_error(housing_labels, housing_predictions)
svm_rmse = np.sqrt(svm_mse)
使用 Scikit-Learn 的 GridSearchCV来帮助选择参数
from sklearn.model_selection import GridSearchCV
param_grid = [
# try 12 (3×4) combinations of hyperparameters
{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},
# then try 6 (2×3) combinations with bootstrap set as False
{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},
]
forest_reg = RandomForestRegressor(random_state=42)
# train across 5 folds, that's a total of (12+6)*5=90 rounds of training
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error', return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
输出最佳的参数组合和最优的估计参数。

# look at the score of each hyperparameter combination tested during the grid search
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'],cvres['params']):
print(np.sqrt(-mean_score),params)
# 以 dataframe 的方式显示结果
pd.DataFrame(grid_search.cv_results_)
使用随机搜索来进行参数选择。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {
'n_estimators': randint(low=1, high=200),
'max_features': randint(low=1, high=8),
}
forest_reg = RandomForestRegressor(random_state=42)
rnd_search = RandomizedSearchCV(forest_reg, param_distributions=param_distribs,
n_iter=10, cv=5, scoring='neg_mean_squared_error',
random_state=42)
rnd_search.fit(housing_prepared, housing_labels)

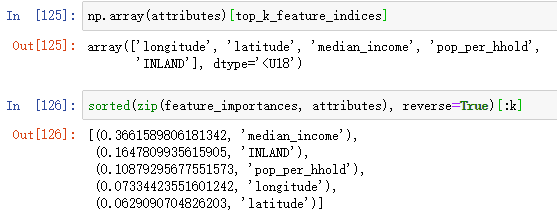
输出每个属性值对于正确预测的相对重要程度。
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ['rooms_per_hhold','pop_per_hhold', 'bedrooms_per_room']
cat_encoder = full_pipeline.named_transformers_['cat']
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs + extra_attribs + cat_one_hot_attribs
sorted(zip(feature_importances, attributes), reverse=True)

有了这个信息,可以考虑删除点一些不是很重要的变量。
在测试集上评估系统性能
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop('median_house_value', axis=1)
y_test = strat_test_set['median_house_value'].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
计算测试集的 RMSE 95%的置信区间。
# we can compute a 95% confidence interval for the test RMSE
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
mean = squared_errors.mean()
m = len(squared_errors)
np.sqrt(stats.t.interval(confidence, m-1,loc=np.mean(squared_errors),
scale=stats.sem(squared_errors)))
# we could also compute the interval manually like this
tscore = stats.t.ppf((1 + confidence)/2, df=m-1)
tmargin = tscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - tmargin), np.sqrt(mean + tmargin)
# Alternatively, we could use a z-scores rather than t-scores
zscore = stats.norm.ppf((1 + confidence) / 2)
zmargin = zscore * squared_errors.std(ddof=1) / np.sqrt(m)
np.sqrt(mean - zmargin), np.sqrt(mean + zmargin)
整合数据准备和预测的Pipeline
full_pipeline_with_predictor = Pipeline([
('preparation', full_pipeline),
('linear', LinearRegression())
])
full_pipeline_with_predictor.fit(housing, housing_labels)
full_pipeline_with_predictor.predict(some_data)
使用 joblib保存模型
my_model = full_pipeline_with_predictor
from sklearn.externals import joblib
joblib.dump(my_model, 'my_model.pkl') #save model
my_model_loaded = joblib.load('my_model.pkl') #load model
7 上线、监督、维护你的系统
- 需要编写程序监督你的系统运行,当性能出问题时应及时预警。
- 评估系统性能时需要对系统的预测进行抽样,评估是否准确,可能需要人为的分析。
- 时常评估系统输入的数据质量。
- 定期使用新数据重新训练模型。
8 练习题的解答
- Question: 构建一个SVM回归算法,尝试使用多种参数,比如 kernel=‘linear’(C有多种值)或者 kernel=‘rbf’(C和gamma有多种值)。
from sklearn.model_selection import GridSearchCV
param_grid = [
{'kernel': ['linear'], 'C': [10., 30., 100., 300., 1000., 3000., 10000., 30000.0]},
{'kernel': ['rbf'], 'C': [1.0, 3.0, 10., 30., 100., 300., 1000.0],
'gamma': [0.01, 0.03, 0.1, 0.3, 1.0, 3.0]},
]
svm_reg = SVR()
grid_search = GridSearchCV(svm_reg, param_grid, cv=5, scoring='neg_mean_squared_error', verbose=2, n_jobs=4)
grid_search.fit(housing_prepared, housing_labels)
negative_mse = grid_search.best_score_
rmse = np.sqrt(-negative_mse)
- Question: 使用RandomizedSearchCV代替GridSearchCV 。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import expon, reciprocal
param_distribs = {
'kernel': ['linear', 'rbf'],
'C': reciprocal(20, 200000),
'gamma': expon(scale=1.0),
}
svm_reg = SVR()
rnd_search = RandomizedSearchCV(svm_reg, param_distributions=param_distribs,
n_iter=50, cv=5, scoring='neg_mean_squared_error',
verbose=2, n_jobs=4, random_state=42)
rnd_search.fit(housing_prepared, housing_labels)
negative_mse = rnd_search.best_score_
rmse = np.sqrt(-negative_mse)
- Question:在数据处理的Pipeline中加入转换器用来选择最重要的特征
from sklearn.base import BaseEstimator, TransformerMixin
# np.argpartition(arr,k) 将数组arr中所有元素(包括重复元素)从小到大排列,比第k大的元素
# 小的放在前面,大的放在后面,输出新数组索引
def indices_of_top_k(arr, k):
return np.sort(np.argpartition(np.array(arr),-k)[-k:])
class TopFeatureSelector(BaseEstimator, TransformerMixin):
def __init__(self, feature_importances, k):
self.feature_importances = feature_importances
self.k = k
def fit(self, X, y=None):
self.feature_indices = indices_of_top_k(self.feature_importances, self.k)
return self
def transform(self,X):
return X[:, self.feature_indices]
找到最大的 k 个特征对应的序号
k = 5
top_k_feature_indices = indices_of_top_k(feature_importances, k)
top_k_feature_indices
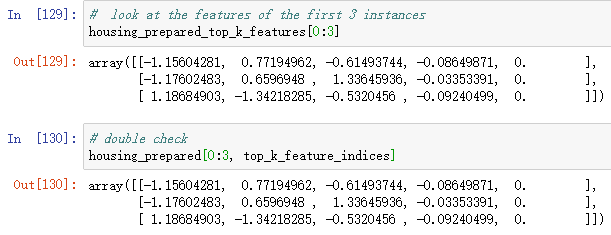
preparation_and_feature_selection_pipeline = Pipeline([
('preparation', full_pipeline),
('feature_selection', TopFeatureSelector(feature_importances, k))
])
housing_prepared_top_k_features = preparation_and_feature_selection_pipeline.fit_transform(housing)
4. Question:创建一个Pipeline完成所有的数据处理过程和最后的预测。
prepare_select_and_predict_pipeline = Pipeline([
('preparation', full_pipeline),
('feature_selection', TopFeatureSelector(feature_importances, k)),
('svm_reg', SVR(**rnd_search.best_params_))
])
prepare_select_and_predict_pipeline.fit(housing, housing_labels)

5. Question:使用GridSearchCV自动发现一些数据处理的方法。
param_grid = [{
'preparation__num__imputer__strategy': ['mean', 'median', 'most_frequent'],
'feature_selection__k': list(range(1, len(feature_importances) + 1))
}]
grid_search_prep = GridSearchCV(prepare_select_and_predict_pipeline, param_grid, cv=5,
scoring='neg_mean_squared_error', verbose=2, n_jobs=4)
grid_search_prep.fit(housing, housing_labels)
程序
我把书中的程序都用 Python 3运行了一遍,确保没有Bug并且都加了注释,方便大家理解。原书的数据集和代码在这个网站上,我自己运行的程序在我的GitHub上。