并发编程2:认识并发编程的利与弊
读完本文你将了解:
-
- 多线程的优点
- 1提高资源利用率
- 2响应更快
- 多线程的缺点
- 1增加资源消耗
- 2上下文切换的开销
- 3设计编码测试的复杂度增加
- Java 内存模型与 CPU 内存简介
- Java 中的堆
- Java 中的栈
- 计算机中的内存寄存器缓存
- 多线程可能出现的问题
- 竞态条件与临界区
- 内存可见性
- 总结
- 35 追加
- Thanks
- 多线程的优点
从上篇文章 并发编程1:全面认识 Thread 我们了解了 Java 中线程的基本概念和关键方法。
在开始使用线程之前,我觉得我们有必要先了解下多线程给我们带来的好处与可能造成的损失,这样才能在合适的地方选用合适的并发策略。
多线程的优点

1:提高资源利用率
“一口多用”其实就是一种多线程。
想象一下,我们左手拿着海鲜大狂欢披萨,右手拿着意式面包佐芦笋腊肉肠,桌子上还放着青柠香茅饮,左边吃一口,右边咬一块,再使劲地喝一口,啊!此生无憾!
看到了吧,多线程最大的优点就是:提高资源利用率。
在 PC 或者手机中,我们的资源主要说的就是 CPU。
我们知道,通常情况下,网络和磁盘的 I/O 比 CPU 和内存的 IO 慢的多。
在执行频繁 I/O 的任务时,CPU 很多时候都处于闲置状态。这时如果我们开启多个线程,在 A 线程 I/O 的同时让 CPU 执行 B,在 B 线程 I/O 的同时再执行 A。这样就比 A B 串行执行时 CPU 的利用率更高。
2:响应更快
这一点想必小肉深有感悟:
- 家里快递来了,小肉会说:shixin,去取一下。我下去愚公移山的时候,她可以继续 shopping;
- 窗外有人吼卖樱桃喽,小肉会说:shixin,去买一点。我去夸父逐日的时候,她可以继续吃吃吃。
我们在主线程接受用户请求后,将耗时操作交给子线程,然后告诉用户在等待的同时还可以干点别的。
此外将一些可以拆分的任务分给多个线程执行,执行完毕后再合并结果,也会让任务处理更高效。
多线程的缺点
俗话说:有阳光的地方就有黑暗;
俗话说:世界上没有免费的午餐。
线程能够给我们带来以上好处,是需要一定代价的。
1:增加资源消耗
每个线程都拥有各自的计数器、堆栈(stack)、局部变量等资源,同时管理这些线程也需要额外的资源。
2:上下文切换的开销
当 CPU 调度不同线程时,它需要更新当前执行线程的数据,程序指针,以及下一个线程的相关信息。
这种切换会有额外的时间、空间消耗,我们在开发中应该避免频繁的线程切换。
3:设计、编码、测试的复杂度增加
其实第三点才是关键,我们知道公司人数越多问题越多,线程也一样,线程之间的交互非常复杂。
不正确的线程同步只有运行时才能发现问题,而且非常难以重现,发现并修复复杂度大大增加。
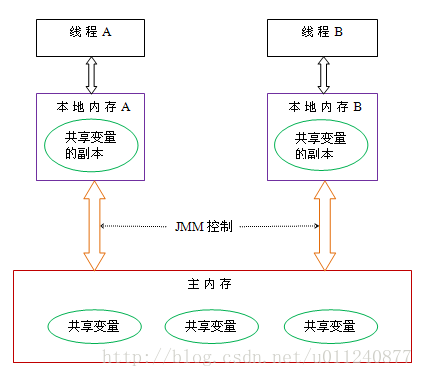
Java 内存模型与 CPU 内存简介
在了解多个线程同时访问数据可能出现的问题之前,我们需要先了解 Java 内存模型。
Java 内存模型规范了 Java 虚拟机与计算机内存是如何协同工作的。

Java 内存模型中将 JVM 分为堆和栈:
- 堆为同一个 JVM 中所有线程共享,存放运行时创建的对象和数组数据;
- 栈为每个线程独有,栈中存放了当前方法的调用信息以及基本数据类型和引用类型的数据。
Java 中的堆
堆在虚拟机启动时创建,堆占用的内存由垃圾回收器管理,不需要我们手动回收。
JVM 没有规定死必须使用哪一种内存回收机制,不同的虚拟机实现可以使用不同的回收算法。
堆中包含在 Java 程序中创建的所有对象,无论是哪一个线程创建的。
一个对象的成员变量随着这个对象自身存放在堆上。不管这个成员变量是基本类型还是引用类型。
Java 中的栈
栈在线程创建时创建,它和 C 语言中的栈相似,在一个方法中,你创建的局部变量和部分结果都会保存在栈中,并在方法调用和返回中起作用。
当前栈只对当前线程可见。即使两个线程执行同样的代码,这两个线程仍然会在自己的线程栈中创建一份本地副本。
因此,每个线程拥有每个本地变量的独有版本。
栈中保存方法调用栈、基本类型的数据、以及对象的引用。
计算机中的内存、寄存器、缓存
这部分摘自:http://ifeve.com/java-memory-model-6/
一个现代计算机通常由两个或者多个 CPU,每个 CPU 都包含一系列的寄存器,CPU 在寄存器上执行操作的速度远大于在主存上执行的速度。
每个 CPU 可能还有一个 CPU 缓存层。CPU 访问缓存层的速度快于访问主存的速度,但通常比访问内部寄存器的速度还要慢一点。
通常情况下,当一个 CPU 需要读取主存时,它会将主存的部分读到 CPU 缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。
当 CPU 需要将结果写回到主存中去时,它会将内部寄存器的值刷新到缓存中,然后在某个时间点将值刷新回主存。
这里先简单地对“Java 内存模型”进行介绍,后序介绍完常见并发类后再详细总结。
多线程可能出现的问题
通过上述介绍,我们可以知道,如果多个线程共享一个对象,每个线程在自己的栈中会有对象的副本。
如果线程 A 对对象中的某个变量进行修改后还没来得及写回主存,线程 B 也对该变量进行了修改,那最后刷新回主内存后的值一定和期望的值不一致。
就好比拭心和小翔同时开发同一模块代码,拭心下笔如有神不一会儿搞定了注册登录并且提交,小翔没有从服务器拉代码就蒙头狂写,最后一 pull 代码,就会发现自己写的好多都跟服务器上的冲突了!
竞态条件与临界区
当多个线程操作同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。导致竞态条件发生的代码区称作临界区。
在临界区中使用适当的同步就可以避免竞态条件,比如 synchronized, 显式锁和原子操作类等。
内存可见性
拭心写的代码小翔无法立即看到,这就是所谓的“内存可见性”问题。
为了让线程 A 对变量做的修改线程 B 立即可以看到,我们可以使用 volatile 修饰变量或者对修改操作使用同步。
总结
本篇文章结合 Java 内存模型简单介绍了多线程开发的优点与可能导致的问题,犹豫了一下我还是觉得有必要在开始学习 Java 各种并发 API 之前了解它们出现的背景,这样更容易明白它们解决了什么问题。
知道了多线程的开销与可能带来的问题后,我们在开发中不要为了使用多线程而使用多线程。应该在确认多线程给项目带来的好处比隐含的开销更多时,再使用多线程。
2017.3.5 追加
感谢遥望江南2009的提问,他的认真促使我仔细查阅了一些资料,在这里记录下关于线程里容易混淆的一些概念:
1.JVM 中每个线程操作操作对象的话会拷贝主线程的对象到自己线程的哪里?
当线程访问某一个对象时候值的时候:
首先通过对象的引用找到对应在堆内存的变量的值;
然后把堆内存变量的具体值 load 到线程工作内存中,建立一个变量副本;
之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后也不会立即同步修改共享堆内存中该变量的值;
直到某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。
上面说的线程工作内存是 JVM 的一个抽象概念,具体是哪里,JLS 也没有说明,但可以肯定的是,这里关于线程的“working memory”对许多平台来说都是对高速缓存的抽象。规范不能把implementation-specific 的东西写进去,不然会影响实现难度。
2.在JAVA中,有六个不同的地方可以存储数据:
- 寄存器(register)
- 这是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部。但是寄存器的数量极其有限,所以寄存器由编译器根据需求进行分配。你不能直接控制,也不能在程序中感觉到寄存器存在的任何迹象。
- 堆栈(stack)
- 位于通用RAM中,但通过它的“堆栈指针”可以从处理器哪里获得支持。堆栈指针若向下移动,则分配新的内存;若向上移动,则释放那些 内存。这是一种快速有效的分配存储方法,仅次于寄存器。创建程序时候,JAVA编译器必须知道存储在堆栈内所有数据的确切大小和生命周期,因为它必须生成 相应的代码,以便上下移动堆栈指针。这一约束限制了程序的灵活性,所以虽然某些JAVA数据存储在堆栈中——特别是对象引用,但是JAVA对象不存储其 中。
- 堆(heap)
- 一种通用性的内存池(也存在于RAM中),用于存放所以的JAVA对象。堆不同于堆栈的好处是:编译器不需要知道要从堆里分配多少存储区 域,也不必知道存储的数据在堆里存活多长时间。因此,在堆里分配存储有很大的灵活性。当你需要创建一个对象的时候,只需要new写一行简单的代码,当执行 这行代码时,会自动在堆里进行存储分配。当然,为这种灵活性必须要付出相应的代码。用堆进行存储分配比用堆栈进行存储存储需要更多的时间。
- 静态存储(static storage)
- 这里的“静态”是指“在固定的位置”。静态存储里存放程序运行时一直存在的数据。你可用关键字static来标识一个对象的特定元素是静态的,但JAVA对象本身从来不会存放在静态存储空间里。
- 常量存储(constant storage
- 常量值通常直接存放在程序代码内部,这样做是安全的,因为它们永远不会被改变。有时,在嵌入式系统中,常量本身会和其他部分分割离开,所以在这种情况下,可以选择将其放在ROM中
- 非RAM存储
- 如果数据完全存活于程序之外,那么它可以不受程序的任何控制,在程序没有运行时也可以存在。
就速度来说,有如下关系: 寄存器 > 堆栈 > 堆 > 其他
(摘自《Thinking in Java》)
欢迎扫描关注微信公众号“安卓进化论”,向高手进击!

Thanks
https://en.wikipedia.org/wiki/Java_memory_model
https://en.wikipedia.org/wiki/Java_concurrency#Memory_model
http://tutorials.jenkov.com/java-concurrency/costs.html
http://ifeve.com/java-concurrency-thread-directory/
https://www.zhihu.com/question/29833675
http://www.iteye.com/problems/24814