Kaggle Titanic 机器学习实践笔记
参考网站:
https://www.cnblogs.com/darkknightzh/p/6117528.html
http://blog.csdn.net/han_xiaoyang/article/details/49797143
目录结构是这个样子的:
Titanic
--data (放官网的数据)
-train.csv
-test.csv
-gender_submission.csv
--program
-data_exploration.py
做题先审题,在官网的data页里能看到对于各字段的说明:
Data Dictionary
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | (兄妹/堂兄妹/配偶个数) |
| parch | # of parents / children aboard the Titanic | (父母/子女/继子继女个数) |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation(登船港口) | C = Cherbourg, Q = Queenstown, S = Southampton |
train_data.info()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
info()函数查看缺失值情况,可以看出
Age有缺失值,只有714条数据
Cabin有缺失值,只有204条数据
Embarked有2条缺失值,有889条数据
查看数值型数据分布:
train_data.describe()
Out[2]:
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
从mean这一行得出:
--有0.383838的人得救了
--大部分人属于2/3等舱
--平均年龄29岁
--平均票价32元
结合25%,30%两行可以得出:
--从Pclass列可知,超过50%的人是三等舱
--对于年龄和票价两列, 75%和max的差距很大
先对单变量看一下分布:
train_data.Survived.value_counts()
Out[8]:
0 549
1 342
Name: Survived, dtype: int64
type(train_data.Survived.value_counts())
Out[9]: pandas.core.series.Series
train_data['Pclass'].value_counts()
Out[11]:
3 491
1 216
2 184
Name: Pclass, dtype: int64
三等舱有491人,二等舱184人,一等舱216人train_data['Embarked'].value_counts()
Out[12]:
S 644
C 168
Q 77
Name: Embarked, dtype: int64
登船港口分布
S港口登船的人最多,Q港口登船的人最少
train_data['Sex'].value_counts()
Out[13]:
male 577
female 314
Name: Sex, dtype: int64
train_data['SibSp'].value_counts()
Out[14]:
0 608
1 209
2 28
4 18
3 16
8 7
5 5
Name: SibSp, dtype: int64
train_data['Parch'].value_counts()
Out[15]:
0 678
1 118
2 80
5 5
3 5
4 4
6 1
Name: Parch, dtype: int64
各属性与是否获救联立分析
看看获救情况与Pclass客舱等级的关系,以下是两种等价的写法
train_data.Pclass[train_data.Survived == 0].value_counts()
Out[19]:
3 372
2 97
1 80
Name: Pclass, dtype: int64
train_data['Pclass'][train_data['Survived']==0].value_counts()
Out[20]:
3 372
2 97
1 80
Name: Pclass, dtype: int64
完整的查看获救情况与客舱等级关系代码及结果图:
import pandas as pd
import matplotlib.pyplot as plt
from pylab import * #识别中文字体用
mpl.rcParams['font.sans-serif'] = ['SimHei'] #画图识别中文
train_data=pd.read_csv('../data/train.csv')
#train_data.info()
#看看各乘客等级的获救情况
Survived_0 = train_data.Pclass[train_data.Survived == 0].value_counts()
Survived_1 = train_data.Pclass[train_data.Survived == 1].value_counts()
df=pd.DataFrame({u'获救':Survived_1, u'未获救':Survived_0})
df.plot(kind='bar', stacked=True,color=['lightcoral','lightgreen']) #为获救赋予绿色,未获救赋予红色
plt.title(u"各乘客等级的获救情况")
plt.xlabel(u"乘客等级")
plt.ylabel(u"人数")
plt.show()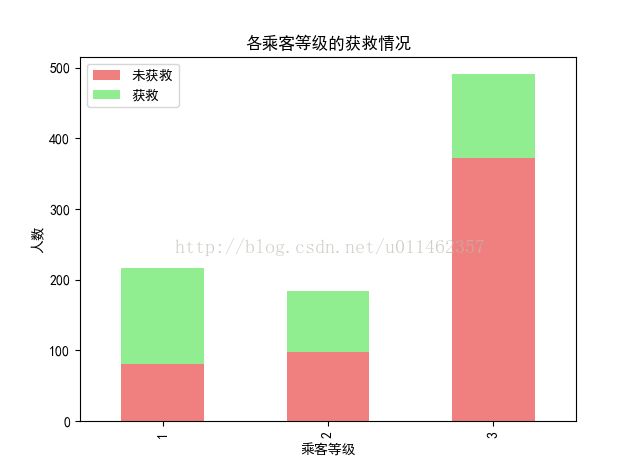
可见一等舱获救比例最高,所以Pclass这个特征有用
#看看各性别的获救情况
Survived_m = train_data['Survived'][train_data['Sex'] == 'male'].value_counts()
Survived_f = train_data['Survived'][train_data['Sex'] == 'female'].value_counts()
df=pd.DataFrame({u'男性':Survived_m, u'女性':Survived_f})
df.plot(kind='bar', stacked=True,color=['pink','royalblue'])
plt.title(u"按性别看获救情况")
plt.xlabel(u"性别")
plt.ylabel(u"人数")
plt.show()
粉色是女性,蓝色是男性(符合平常认知哈)
横坐标的0是未获救,1是获救
可以看出获救的人里女性占大多数,女生优先。 所以性别这个特征有用

可以看出,从S港口上船的人获救占比大
怀疑S港口是个富人聚集的港口,Q港口是个穷人聚集的港口
所以登录港口是个有用的特征
#看看登船口岸,舱级与是否活着的关系
y1 = train_data[train_data.Survived==0].groupby(['Embarked','Pclass'])['Survived'].count().reset_index()['Survived'].values
y2 = train_data[train_data.Survived==1].groupby(['Embarked','Pclass'])['Survived'].count().reset_index()['Survived'].values
ax = plt.figure(figsize=(8,3)).add_subplot(111)
pos = range(9)
ax.bar(pos, y1, align='center', alpha=0.5, color='r', label='dead')
ax.bar(pos, y2, align='center', bottom=y1, alpha=0.5, color='g', label='alive')
ax.set_xticks(pos)
xticklabels = []
for embarked_val in ['C','Q','S']:
for pclass_val in range(1,4):
xticklabels.append('%s/%d'%(embarked_val,pclass_val))
ax.set_xticklabels(xticklabels,size=15)
ax.legend(fontsize=15, loc='best')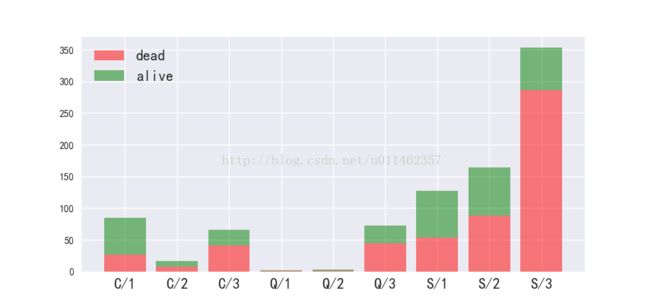
从不同舱级的比例来看,似乎C上岸更容易获救是因为头等舱的人较多?
但进一步对比C/S 发现,同样的舱级,C获救概率依然更高
脑洞下:
- C地的人更加抱团,互帮互助- -
- 人数上来看S地的人更多,不同等级分布也更合常理,而C地的人头等舱很多,商务舱几乎没有,屌丝仓的也不少;
猜想:C地的人更多是权贵,S地的人来自商贸发达的商人?,所有C地的人地位更高- -
#看看配偶/兄妹/堂兄妹 个数的获救情况
Sibsp_Survived_0 = train_data['SibSp'][train_data['Survived'] == 0].value_counts()
Sibsp_Survived_1 = train_data['SibSp'][train_data['Survived'] == 1].value_counts()
df=pd.DataFrame({u'获救':Sibsp_Survived_1, u'未获救':Sibsp_Survived_0})
df.plot(kind='bar', stacked=True,color=['lightcoral','lightgreen'])
plt.title(u"SibSp个数的获救情况")
plt.xlabel(u"SibSp个数")
plt.ylabel(u"人数")
plt.show()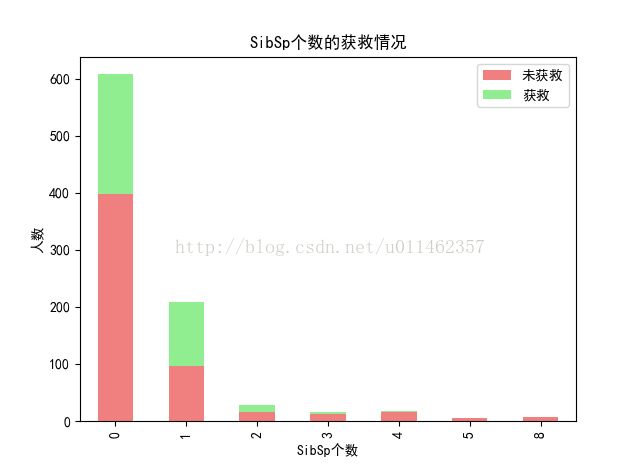
这个图很明显可以看出,Sibsp越少获救概率越大
我理解为单身狗 容易获救; 拖家带口的 不容易获救
#看看父母/孩子个数 的获救情况
Parch_Survived_0 = train_data['Parch'][train_data['Survived'] == 0].value_counts()
Parch_Survived_1 = train_data['Parch'][train_data['Survived'] == 1].value_counts()
df=pd.DataFrame({u'获救':Parch_Survived_1, u'未获救':Parch_Survived_0})
df.plot(kind='bar', stacked=True,color=['lightcoral','lightgreen'])
plt.title(u"Parch个数的获救情况")
plt.xlabel(u"Parch个数")
plt.ylabel(u"人数")
plt.show()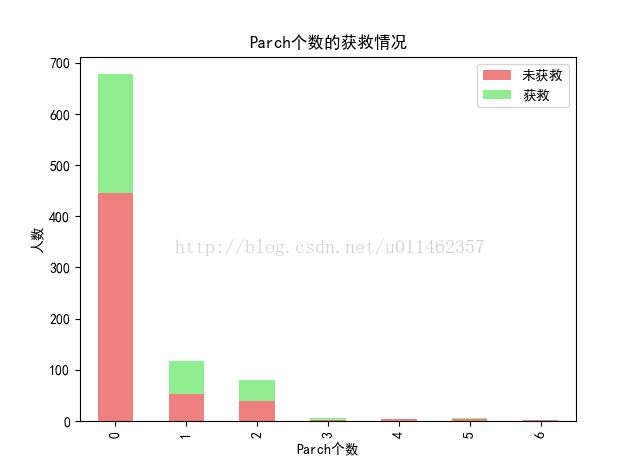
还是单身狗获救占比大,拖家带口不容易获救
plt.close('all') #不把前面画的图都关掉的话会发生重叠
#按年龄看获救分布
plt.scatter(train_data['Age'], train_data['Survived'])
plt.show()
没有什么明显的分布,获救情况似乎与年龄没什么关系
plt.close('all')#我现在只想看这一个图,把前面画的图都关闭掉,否则会发生重叠
#看看年龄与舱级的关系
train_data['Age'][train_data['Pclass'] == 1].plot(kind='kde')
train_data['Age'][train_data['Pclass'] == 2].plot(kind='kde')
train_data['Age'][train_data['Pclass'] == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.show()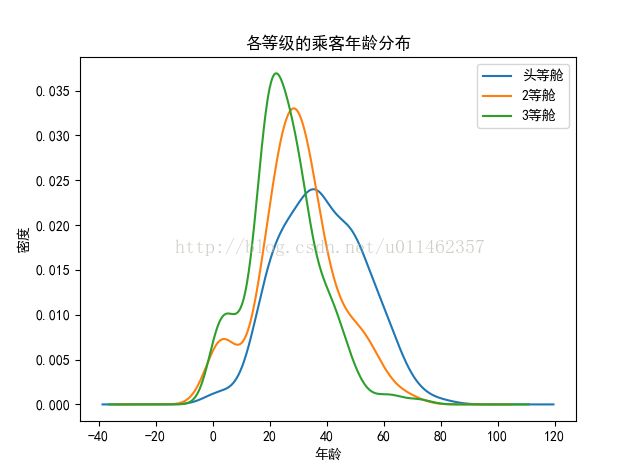
头等舱主要是40岁左右的人,三等舱主要是20岁左右的年轻人 ,与常识认知相符。
看看Cabin:
train_data['Cabin'].value_counts()
Out[1]:
B96 B98 4
G6 4
C23 C25 C27 4
C22 C26 3
D 3
E101 3
F2 3
F33 3
B58 B60 2
C123 2
E44 2
C68 2
E33 2
D36 2
B77 2
C93 2
C92 2
C52 2
C2 2
C65 2
E24 2
D26 2
F G73 2
D17 2
B57 B59 B63 B66 2
B49 2
B28 2
C125 2
B22 2
D35 2
..
E63 1
C46 1
C118 1
D11 1
A6 1
A24 1
A23 1
C90 1
C82 1
D15 1
C70 1
A26 1
B102 1
C49 1
E17 1
A5 1
C45 1
B3 1
B4 1
C128 1
F38 1
A10 1
C30 1
D28 1
A16 1
D50 1
E46 1
B86 1
C87 1
B82 B84 1
Name: Cabin, Length: 147, dtype: int64
票价:
plt.close('all')#看当前图可以把前面的图都关闭掉,否则会发生重叠
#看看年龄与舱级的关系
train_data['Fare'][train_data['Survived'] == 0].plot(kind='kde')
train_data['Fare'][train_data['Survived'] == 1].plot(kind='kde')
plt.xlabel(u"票价")# plots an axis lable
plt.xlim([0,550])#设定x轴刻度起于0, 止于550
plt.ylabel(u"密度")
plt.title(u"获救情况与票价联系分布图")
plt.legend((u'获救', u'未获救'),loc='best') # sets our legend for our graph.
plt.show()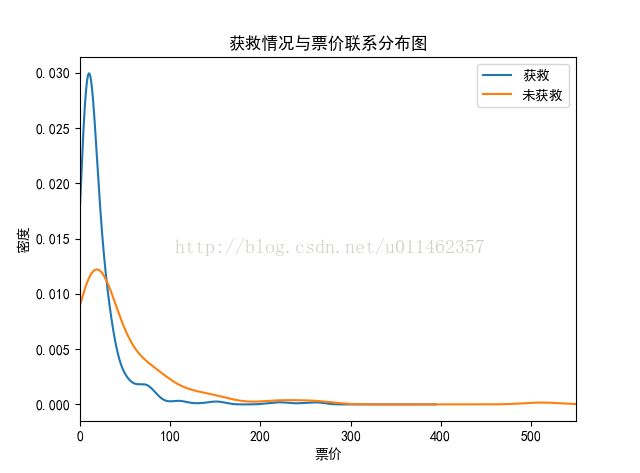
船舱:
train_data['Survived'].groupby(by=train_data['Cabin'].isnull()).agg('mean')
Out[6]:
Cabin
False 0.666667
True 0.299854
Name: Survived, dtype: float64可以看出,Cabin有指的人更容易获救,为空的人更不容易获救
看看登船口岸是空的这两条记录,这两个人都获救了,而且都是头等舱
train_data[train_data['Embarked'].isnull()==True]
Out[2]:
PassengerId Survived Pclass Name \
61 62 1 1 Icard, Miss. Amelie
829 830 1 1 Stone, Mrs. George Nelson (Martha Evelyn)
Sex Age SibSp Parch Ticket Fare Cabin Embarked
61 female 38.0 0 0 113572 80.0 B28 NaN
829 female 62.0 0 0 113572 80.0 B28 NaN
因为S地登船的人最多,所以可以简单粗暴地把它填充为S