哈希(散列)函数的一些应用
目录
1. hash表的原理与实现
2. Java中的hashcode()方法
3. Collection中HashMap的应用
4. Bloom Filter在海量数据中的应用
1.hash表原理与实现
根据key-value而直接进行访问的数据结构。把关键字key通过某种映射函数映射到表中的某个位置来访问,来提高查找的速度。映射函数就称之为hash函数。存放映射的数组称之为hash表,散列表是根据关键字直接求出地址的查找方法,其查找的期望时间是O(1)。
冲突(碰撞collision):对不同的关键字key ,得到相同的表的位置。这种情况称之为碰撞(collision)。几种解决冲突的方法:
开放定址法:hash表由m个元素组成,其地址是0到m-1,在向表中插入新纪录的时候,如果通过hash函数映射得到的地址已经被占用。那么通过探查下个空位置来存放这个新纪录。采用的方式就是可以通过这个公式
hi=(h(key)+di)%m 1≤i≤m-1
① 、 h(key)为散列函数,di为增量序列,m为表长。
② 、 h(key)是初始的探查位置,后续的探查位置依次是hl,h2,…,hm-1,即h(key),hl,h2,…,hm-1形成了一个探查序列。
③ 、 散列表的装填因子α= 填入表中的元素个数 / 散列表的长度。开放定址发要求hash表的装填因子α<=1
拉链法:将所有产生冲突的放在同一个单链表中,也就是说对每个hash地址都建立一个单链表。这样一个hash地址就可以被多个关键字key共享。是不是觉得很熟悉,没错HashMap的底层实现与之很类似。一个Entry数组,每个数组元素相当于一个链表的头元素。
2.Java中的hashcode方法
首先API中的解释说明Returns a hash code value for the object. This method is supported for the benefit of hashtables such as those provided by java.util.Hashtable .意思就是说,hashcode方法返回这个对象的hash(散列)值,这个方法为hash表提供一些便利(优点),例如,java.util.Hashtable提供的hash表。
关于hashcode的一些协定:
1、在同一次 应用执行期间,多次调用一个对象的hashcode方法,其返回的integer值必须保持一致。在某个应用程序的一次执行到另一次执行,调用一个对象的hashcode值在两次执行过程中,不必保持一致。
2、根据equals(Object )方法,如果两个对象相等,那么分别调用两个对象的hashcode方法返回的integer值必须一致。
3、以下情况不是必需的:如果根据equals(Object)方法,如果两个对象不相等,那么这两个对象调用hashcode方法必定返回不一致的值。但是,程序员应该晓得,为不相等的对象生成不同的整数结果可以提高hash表的性能。(换句话说就是如果两个对象不相等,那么hashcode的返回值可能相等也可能不相等,但最后不相等)。
举个例子
package com.cn.hn.test;
import java.util.Date;
public class HashcodeSimple {
public static void main(String[] args){
String test1 = "123";
String test2 = test1;
System.out.println("test1==test2?"+test1.equals(test2));
System.out.println("String:"+test1.hashCode());
Date d1 =new Date();
System.out.println("java.util.Date:"+d1.hashCode());
}
}
第一次执行结果
test1==test2?true
String:48690
java.util.Date:1732896453
第二次执行结果
test1==test2?true
String:48690
java.util.Date:1732948949
这里呢:String类型的hashcode两次返回的值都保持了一致。原因是因为字符串常量“123”,如果字符串常量池中没有,则会把“123”字符串插入到常量池中,如果有的话直接返回引用。因为String的hashcode方法跟String对象底层的数组有关,字符串常量不变,底层的数组也没有变,自然得到的hash值也没有改变
public int hashCode() {
int h = hash;
int len = count;
if (h == 0 && len > 0) {
int off = offset;
char val[] = value;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}
再看java.util.Date其实现的hashcode方法如下面所示。可以看到Date类型的的hash值跟时间有关,两次生成的时间不同,产生的hash值自然也不相同。
public int hashCode() {
long ht = this.getTime();
return (int) ht ^ (int) (ht >> 32);
}
3、Collection中HashMap的应用
平常做开发的时候List和Map作为两种最常见的集合,HashMap作为Map的实现之一,底层的实现采用就是数据+链表的数据结构,即hash得到的值相同的话,采用上述的拉链法来解决冲突。下面就仔细看下HashMap的底层实现:
1、作为一个数组,其默认长度为static final int DEFAULT_INITIAL_CAPACITY = 1 << 4(即16);
2、作为一个hash表,为了避免太多的hash碰撞,于是有了加载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;
3、作为一个数组,在扩容的时候size变为原来的2倍,都是将旧的数据复制到新的数组;
就拿map.put()这个方法作为入口详细扯下(由于HashMap在jdk8引入了红黑树,导致该方法与jdk7实现差异比较大,本文jdk的版本即jdk8):
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
///如果map为空就创建map并返回null
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/// 如果当前hash得到的数组位置没有存放Node的时候,则就放在这个位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/// 这里就是处理hash碰撞的地方
///1、如果当前key与要插入的key相同,则直接覆盖否则2
///2、判断p节点是否是TreeNode,也就是判断当前节点链表是否是红黑树,如果是直接在红黑树上插入key-value
///3.1、在p节点的链表上遍历到最后一个准备插入,如果找到与要插入的key相同的节点,直接覆盖
///3.2、如果当前链表的长度大于7(8-1),将当前链表转换成红黑树并插入节点
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
////判断是否需要扩容:当前的容量大于capacity*factor(3/4),直接capacity*2
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
4、Bloom Filter在海量数据中的应用
Bloom filter即布隆过滤器是一种多hash函数映射的快速查找算法,用于检索一个元素是否在一个集合中。
原理:
利用一个有m位的二进制数组M,这个位数组每一位都初始设为0。假设原始集合S{x1,x2,……xn},Bloom filter使用k个相互独立的hash函数。通过这k个hash函数将原始集合S中的元素都映射到位数组M中,例如将集合S中的x1通过h1,……hk得到x1在位数组M中的k个位置h1(x1)……hk(x1)。
然后将位数组M中的h1(x1)……hk(x1)位置的值设为1,如果之前其它元素已经将该位置设为1了,那么这个位置的值将不做更改还是为1。通过这种方式,将原始集合S中的所有元素都映射到位数组M中。
在查找某个元素x是否属于该集合的时候,通过k个hash函数得到k个位数组M中位置的值。如果这k个位置的值有一个为0,则代表这个元素x不是这个集合中的元素。
换种图像的方式表达上述的意思就是

查找的时候
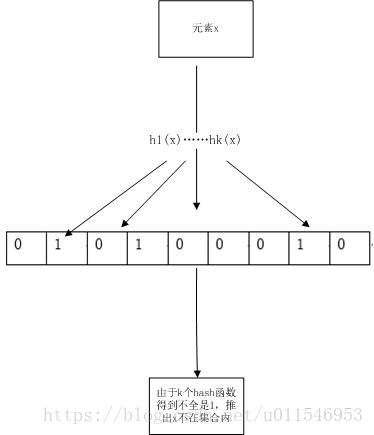
小结:由查找的过程的可以看出:一种极端情况下:位数组中的所有位都是1的情况下,无论一个元素是否属于这个集合,因为h1(x)……hk(x)得到的都是1,所以x的查找结果就是存在于这个集合中。当然,这个结果是错误。所以推断出bloom filter 的查找结果不是100%准确的。(准备的来说就是:如果一个元素被bloomFilter 判断为不在该集合中,那么这个元素在这个集合中一定不存在。)
一般我们使用bloom filter不用自己来实现了其中的算法,而强大的google为我们使用提供了一个非常便利的包com.google.guava。在这个包里还有其它很强大的例如collect,cache。下面就是采用guava的BloomFilter创建的一个测试demo
public class BloomFilterTest {
public static int size = 10000000;
public static double fpp = 0.003;
public static void main(String[] args) {
BloomFilter bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size,fpp);
for (int i =0;i < size ;++i){
bloomFilter.put(i+1);
}
for (int j =1;j<=size;++j){
if (!bloomFilter.mightContain(j)){
System.out.println(j+"数据本身在,误判为不在");
}
}
List nums = new ArrayList<>();
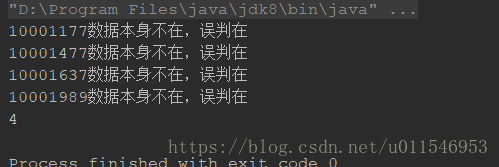
for (int i=1000;size+i 执行结果
总结:关于hash函数就写到这里,本文只是从一些定义原理,到工作中一些简单的应用和个人的理解做了个小小的总结。如有不对的地方,欢迎指出。
ps:写这个篇博文,停停写写,中间还换了工作,终于下定决心把这个写完,纪念下2018-10-18。