facenet 人脸识别原理理解(三)
在前两篇文章已经介绍了facenet人脸识别代码的使用和具体操作,但相关的原理还是没有说,这篇文章进行简单的讲解一下。
1. 原理
在人脸识别中,当我们需要加在图片数据库入新的一张人脸图片时,是怎么做到识别的呢,难道要我们重新修改网络最后的输出函数softmax,添加一个输出,然后再重新训练整个网络?这是不现实的吧!
那我们要怎么做呢?更多的做法是采用欧氏距离D来衡量这两张图片的差距,进行判别是否属于同一个人。如果两张人脸图片越相似,空间距离D越小;差别越大,则空间距离D越大。
我们要设置一个阈值τ,距离小于τ时属于同一个人脸,距离大于τ时就判断为不同的人脸。
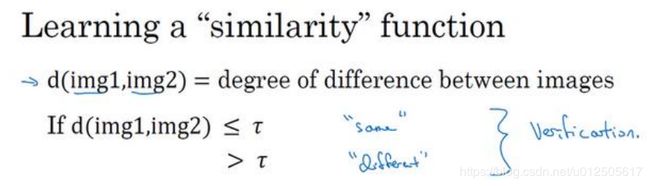
2. 网络结构
下面我从facenet的网络结构说起。

从网络中可以看到Batch之后是Deep architeture(Inception ResNet v1),再到L2范数,然后就是嵌入层(embedding),最后就是三元组损失了。
L2:在L2范数前要进行归一化,要不然数值太大了!
EMBEDDING: 嵌入层,是一种映射关系,从一种特征空间映射到另外一种特征空间。
Triplet Loss:三元组损失。三元组由Anchor(A), Negative(N), Positive(P)这三个组成,从字面意思我们就可以猜想,我们想让Anchor和Positive尽量的靠近(Positive意味这同一个人),Anchor和Negative尽量的远离(Negative表示不同的人)。
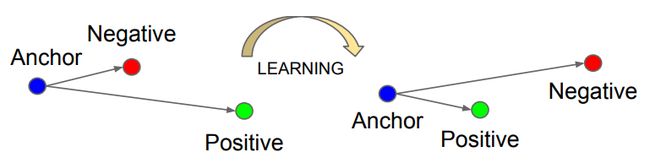
但我们在训练之前,会有 Anchor和Negative离得近,Anchor和Positive离得远的情况,如左边的图片一样。经过学习之后转变为右边我们想要的效果:Anchor与Negative离得远,与Positive离得近。
3. Triplet Loss损失函数
我们想让它小于等f(A)到f(P)之间的距离小于f(A)到f(P)的距离,或者说是比较它们的范数的平方,得到下式子。

其中a是一个常数,防止把所有的东西都学成 0,如果f总是输出 0,即 0-0 < 0,这种情况。同时a代表着间隔距离,它拉大了 Anchor 和 Positive 图片对和 Anchor 与 Negative 图片对之间的差距。看代码中常默认为0.2。
总的损失函数:

左边为同类距离 ,右边为不同的类之间的距离。使用梯度下降法优化的过程就是让类内距离不断下降,类间距离不断提升,这样损失函数才能不断地缩小。但为了防止loss小于0,通过代码里面我们可以看到会和0比较一下。
def triplet_loss(anchor, positive, negative, alpha):
"""Calculate the triplet loss according to the FaceNet paper
Args:
anchor: the embeddings for the anchor images.
positive: the embeddings for the positive images.
negative: the embeddings for the negative images.
Returns:
the triplet loss according to the FaceNet paper as a float tensor.
"""
with tf.variable_scope('triplet_loss'):
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, positive)), 1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor, negative)), 1)
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist), alpha)
loss = tf.reduce_mean(tf.maximum(basic_loss, 0.0), 0)
return loss- center_loss损失函数
关于损失函数,除了上面的triplet_loss函数外,其实facenet.py文件里面代码还有一个center_loss损失函数,这是Deep Face 使用的方法。它会在某一个类中找到一个center,让这类所有样本的特征到中心的距离最短,让同一类别更加紧凑一些。
def center_loss(features, label, alfa, nrof_classes):
"""Center loss based on the paper "A Discriminative Feature Learning Approach for Deep Face Recognition"
(http://ydwen.github.io/papers/WenECCV16.pdf)
"""
nrof_features = features.get_shape()[1]
centers = tf.get_variable('centers', [nrof_classes, nrof_features], dtype=tf.float32,
initializer=tf.constant_initializer(0), trainable=False)
label = tf.reshape(label, [-1])
centers_batch = tf.gather(centers, label)
diff = (1 - alfa) * (centers_batch - features)
centers = tf.scatter_sub(centers, label, diff)
with tf.control_dependencies([centers]):
loss = tf.reduce_mean(tf.square(features - centers_batch))
return loss, centers
4. Training 训练
4.1 Triplet Selection
关于如何选择这些三元组来形成训练集,随机地选择A、 P和N,遵守A和P是同一个人,而A和N是不同的人这一原则。有个问题就是:如果随机的选择它们,那么这个约束条件(d(A, P) + a ≤ d(A, N))很容易达到,因为随机选择的图片,A和N比A和P差别很大的概率很大。这样网络就很难学到东西,稳健性就很差了。引用吴恩达老师Deep learning 课程中的一段话:
那我们要做的就是尽可能选择难训练的三元组A、P和N。难训练的三元组就是,你的A、P和N的选择使得d(A, P)很接近d(A, N),即d(A, P) ≈ d(A, N),这样你的学习算法会竭尽全力使右边这个式子变大(d(A, N)),或者使左边这个式子(d(A, P))变小,这样左右两边至少有一个a的间隔。

同样在facenet论文中我们也可以看到,我们要选择最远的相同人脸![]() (hard positive),和最近的不同人脸
(hard positive),和最近的不同人脸![]() (hard negative)来训练,如上图所示。
(hard negative)来训练,如上图所示。
4.2 Classifier
我们在生成 .pkl 文件的时候用到calssifier.py 文件,里面用SVM来训练一个分类器。整体流程大致是:CNN forward 输出后经L2传入Embedding层,得到embedding ouput的特征进行传给SVM classifier来训练一个分类器。然后把训练好的分类器保存为pickle文件。在执行指令读取分类器的时候加载SVM分类器模型,自己所用的测试图片数据就会SVM分类器模型中的类别做对比判断。.pkl文件保存的参数包括模型(model)和类别(class_names),我们是可以直接读出来的。
代码里面SVM有两种模式:TRAIN (用来训练SVM模型);CLASSIFY (用来加载SVM模型)。看代码会有更好的理解:
# Run forward pass to calculate embeddings
print('Calculating features for images')
nrof_images = len(paths)
nrof_batches_per_epoch = int(math.ceil(1.0*nrof_images / args.batch_size))
emb_array = np.zeros((nrof_images, embedding_size))
for i in range(nrof_batches_per_epoch):
start_index = i*args.batch_size
end_index = min((i+1)*args.batch_size, nrof_images)
paths_batch = paths[start_index:end_index]
images = facenet.load_data(paths_batch, False, False, args.image_size)
feed_dict = { images_placeholder:images, phase_train_placeholder:False }
emb_array[start_index:end_index,:] = sess.run(embeddings, feed_dict=feed_dict)
classifier_filename_exp = os.path.expanduser(args.classifier_filename)
if (args.mode=='TRAIN'):
# Train classifier
print('Training classifier')
model = SVC(kernel='linear', probability=True) # use SVM classifier
model.fit(emb_array, labels)
# Create a list of class names
class_names = [ cls.name.replace('_', ' ') for cls in dataset]
# Saving classifier model
with open(classifier_filename_exp, 'wb') as outfile:
pickle.dump((model, class_names), outfile)
print('Saved classifier model to file "%s"' % classifier_filename_exp)
elif (args.mode=='CLASSIFY'):
# Classify images
print('Testing classifier')
with open(classifier_filename_exp, 'rb') as infile:
(model, class_names) = pickle.load(infile)
print('Loaded classifier model from file "%s"' % classifier_filename_exp)
predictions = model.predict_proba(emb_array)
best_class_indices = np.argmax(predictions, axis=1)
best_class_probabilities = predictions[np.arange(len(best_class_indices)), best_class_indices]
for i in range(len(best_class_indices)):
print('%4d %s: %.3f' % (i, class_names[best_class_indices[i]], best_class_probabilities[i]))
accuracy = np.mean(np.equal(best_class_indices, labels))
print('Accuracy: %.3f' % accuracy)
关于对facenet代码的理解,网上已经有一些比较详细的讲解了,可以读这篇博客:FaceNet源码解读2:史上最全的FaceNet源码使用方法和讲解(二)。
而人脸识别的各种在应用方面还存在各种问题,随之而来的是新算法的出现,了解更改前沿技术可以看这篇文章,个人觉得还是不错的:格灵深瞳:人脸识别最新进展以及工业级大规模人脸识别实践探讨
上篇文章:facenet 人脸识别库的搭建和使用方法(二)
参考资料:
https://blog.csdn.net/fire_light_/article/details/79592804