keras入门(四) ResNet网络 实现猫狗大战
先来一张resnet网络结构图,本文采用的是resnet50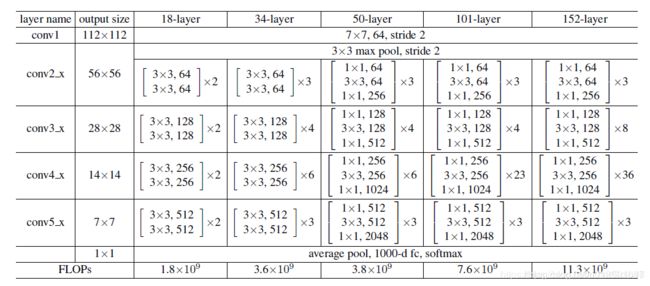
核心思想就是引入skip connect,阻止深层网络的退化。

import keras
from keras import Model, layers
from keras.layers import Conv2D, BatchNormalization, Add, MaxPooling2D, AveragePooling2D, Input, Activation, Flatten, \
Dense, GlobalAveragePooling2D, Dropout
from keras.callbacks import EarlyStopping
from keras.optimizers import SGD
import os
import argparse
import random
import numpy as np
from scipy.misc import imread, imresize, imsave
parser = argparse.ArgumentParser()
parser.add_argument('--train_dir', default='F:/kaggle/train/')
parser.add_argument('--test_dir', default='F:/kaggle/test/')
parser.add_argument('--log_dir', default='./')
parser.add_argument('--batch_size', default=32)
parser.add_argument('--gpu', type=int, default=0)
args = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
type_list = ['cat', 'dog']
def identity_block(input, stage, filters):
conv_name = 'cn' + str(stage) + '_branch'
bais_name = 'bn' + str(stage) + '_branch'
input_short_cut = input
filter1, filter2, filter3 = filters
input = Conv2D(filter1, (1, 1), strides=(1, 1), padding='same', name=conv_name + '_one')(input)
input = BatchNormalization(name=bais_name + "_one_BN")(input)
input = Activation("relu")(input)
input = Conv2D(filter2, (3, 3), strides=(1, 1), padding='same', name=conv_name + '_two')(input)
input = BatchNormalization(name=bais_name + "_two_BN")(input)
input = Activation("relu")(input)
input = Conv2D(filter3, (1, 1), strides=(1, 1), padding='same', name=conv_name + '_three')(input)
input = BatchNormalization(name=bais_name + "_three_BN")(input)
input = Add()([input, input_short_cut])
input = Activation("relu")(input)
return input
def convolutional_block(input, stage, strides, filters):
conv_name = 'cn' + str(stage) + '_branch'
bais_name = 'bn' + str(stage) + '_branch'
input_short_cut = input
filter1, filter2, filter3 = filters
input = Conv2D(filter1, (1, 1), strides=strides, padding='same', name=conv_name + '_one')(input)
input = BatchNormalization(name=bais_name + "_one_BN")(input)
input = Activation('relu')(input)
input = Conv2D(filter2, (3, 3), strides=(1, 1), padding='same', name=conv_name + '_two')(input)
input = BatchNormalization(name=bais_name + "_two_BN")(input)
input = Activation('relu')(input)
input = Conv2D(filter3, (1, 1), strides=(1, 1), padding='same', name=conv_name + '_three')(input)
input = BatchNormalization(name=bais_name + "_three_BN")(input)
input_short_cut = Conv2D(filter3, (1, 1), strides=strides, padding='same', name=conv_name + '_four')(input_short_cut)
input_short_cut = BatchNormalization(name=bais_name + "_four_BN")(input_short_cut)
input = Add()([input, input_short_cut])
input = Activation('relu')(input)
return input
def ResNet50(input_shape=(224, 224, 3)):
input = Input(shape=input_shape)
outinput = Conv2D(64, (7, 7), strides=(2, 2), padding='same', name='conv1')(input)
outinput = BatchNormalization(name="conv1_BN")(outinput)
outinput = Activation("relu")(outinput)
outinput = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool1_1')(outinput)
outinput = convolutional_block(outinput, 1, 1, [64, 64, 256])
outinput = identity_block(outinput, 2, [64, 64, 256])
outinput = identity_block(outinput, 3, [64, 64, 256])
outinput = convolutional_block(outinput, 4, 2, [128, 128, 512])
outinput = identity_block(outinput, 5, [128, 128, 512])
outinput = identity_block(outinput, 6, [128, 128, 512])
outinput = identity_block(outinput, 7, [128, 128, 512])
outinput = convolutional_block(outinput, 8, 2, [256, 256, 1024])
outinput = identity_block(outinput, 9, [256, 256, 1024])
outinput = identity_block(outinput, 10, [256, 256, 1024])
outinput = identity_block(outinput, 11, [256, 256, 1024])
outinput = identity_block(outinput, 12, [256, 256, 1024])
outinput = identity_block(outinput, 13, [256, 256, 1024])
outinput = convolutional_block(outinput, 14, 2, [512, 512, 2048])
outinput = identity_block(outinput, 15, [512, 512, 2048])
outinput = identity_block(outinput, 16, [512, 512, 2048])
outinput = GlobalAveragePooling2D(name='avg_pool')(outinput)
outinput = (Dropout(0.5))(outinput)
#outinput = AveragePooling2D(pool_size=(2, 2), padding="same")(outinput)
#outinput = Flatten()(outinput)
outinput = Dense(2, activation='softmax')(outinput)
model = Model(inputs=input, outputs=outinput, name="ResNet50")
return model
def create_generate(train_file_list, batch_size, input_size):
while (True):
random.shuffle(train_file_list)
image_data = np.zeros((batch_size, input_size[0], input_size[1], 3), dtype='float32')
label_data = np.zeros((batch_size, 1), dtype='int32')
for index, file_name in enumerate(train_file_list):
image = imresize(imread(args.train_dir + file_name), input_size)
label = file_name.split('.')[0]
image_data[index % batch_size] = np.reshape(image / 255, (input_size[0], input_size[1], 3))
label_data[index % batch_size] = type_list.index(label)
if (0 == (index + 1) % batch_size):
# label_data = to_categorical(labei_data, 2)
label_data = keras.utils.to_categorical(label_data, 2)
yield image_data, label_data
image_data = np.zeros((batch_size, input_size[0], input_size[1], 3), dtype='float32')
label_data = np.zeros((batch_size, 1), dtype='int32')
def train(model):
early_stop = EarlyStopping(monitor='val_loss', patience=5, mode='min')
tensor_board = keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq=0, batch_size=16, write_graph=True, write_grads=False, write_images=False, embeddings_freq=0, embeddings_layer_names=None, embeddings_metadata=None, embeddings_data=None, update_freq='epoch')
sgd = SGD(lr=0.001, decay=1e-8, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy'])
#model.compile(optimizer=sgd, loss='binary_crossentropy', metrics=['accuracy'])
train_generate, validation_genarate = prepare_data()
model.fit_generator(generator=train_generate, steps_per_epoch=1250
, epochs=30, verbose=1,
validation_data=validation_genarate, validation_steps=30, max_queue_size=1,
shuffle=True,
callbacks=[early_stop, tensor_board])
model.save_weights(args.log_dir + 'model.h5')
def predict(model):
file_list = os.listdir(args.test_dir)
cat_real_count = 0
dog_real_count = 0
cat_predict_count = 0
dog_predict_count = 0
for index, file_name in enumerate(file_list):
print(index)
label = file_name.split('.')[0]
if 'cat' == label:
cat_real_count = cat_real_count + 1
else:
dog_real_count = dog_real_count + 1
image = imresize(imread(args.test_dir + file_name), (224, 224, 3))
label = model.predict(np.reshape(image / 255, (1, 224, 224, 3)))
label = np.argmax(label, 1)
if 0 == label:
imsave('./result/cat/' + file_name, imread(args.test_dir + file_name))
cat_predict_count = cat_predict_count + 1
else:
imsave('./result/dog/' + file_name, imread(args.test_dir + file_name))
dog_predict_count = dog_predict_count + 1
# print(cat_predict_count / cat_real_count)
if __name__ == '__main__':
try:
model = ResNet50()
train(model)
except Exception as err:
print(err)与VGG相比,在训练过程中能够快速收敛,而且准确率更高,能够达到97%,但是训练过程中遇到了过拟合的问题,验证集上的准确率在70%~80%,怎么调参都无法解决,训练了好几天,没有太多的头绪,等以后有想法了再解决一下