Python进阶篇:4 pandas基础篇
Pandas是一个强大的分析结构化数据的工具集。
1、Pandas中的数据结构
1.1、数据结构Series
Pandas中的Series对象类似一维数组的对象。Series对象是由数据和索引组成。构建Series对象常见方式:
(1)通过数组或列表的方式;
(2)通过dict字典的方式;

【Series对象常见参数】

- data:类似数组array,可迭代的、字典或标量值包含存储在序列中的数据。
- index:类似数组或索引,默认为RangeIndex(0,1,2,.,.,n)
- dtype:数据类型
- name:名称
- copy:复制,默认为False
【Series对象中属性和方法】
(1)ser_obj.values:数据
(2)ser_obj.index:索引
(3)ser_obj.name:series的名称
(4)ser_obj.index.name:索引
(5)通过in判断数据是否存在,Series对象也可看作定长、有序的字典:
(6)通过索引位置必须是整型,获取数据,ser_obj.iloc[index]。
(7)ser_obj.str使用:
- ser_obj.str.split('_')方法:对元素进行分割;
- ser_obj.str.replace('_', '')方法:对元素进行替换;
- ser_obj.str.lower()方法:对元素大写转小写;
- ser_obj.str.contains(',')方法,包含。
【例子】
import numpy as np
import pandas as pd
# 构建Series对象,是一维数组
# 通过list创建Series对象
s1 = pd.Series(range(10,20))
# 通过ndarray创建Series对象
s2 = pd.Series(np.random.rand(5)) # 随机产生5个小于1的小数
# 通过字典dict创建Series对象,字典的key就是索引号,字典的value就是Series对象的值
s3 = pd.Series({'x':0,'y':1,'z':2})
# 构建Series对象并通过index参数指定索引,索引可以是任意类型数据,name参数就是数据定义一名称
s4 =pd.Series(np.random.rand(5),index=['a','b','c','d','e'],name='rand_num')
s4.index.name = "s4_index" # 给索引指定一个名称
print('属性索引index:',s4.index) # 索引对象RangeIndex(start=0,stop=100,step=1)开始是0,stop末尾索引数,步长是1
print('索引index的name:',s4.index.name)
print('name属性:',s4.name) # 数据名称
print('values属性:',s4.values) # 是个array类型的数组
print('预览头部前两条数据:',s4.head(2))
print('预览尾部后3条数据:',s4.tail(3))
print("通过索引名称获取数据:",s4['c'])
print("通过in判断数据是否在Series对象中(返回布尔类型):",0.1 in s4)
print('通过索引位置(整数)获取数据:',s4[1])
print('通过索引位置(整数)获取数据:',s4.iloc[1]) # iloc表示整型位置
###################################处理缺失数据###############################
city = ['北京','重庆','郑州','武汉',None]
s5 = pd.Series(city)
my_nums = [1,3,5,7,None]
s6 = pd.Series(my_nums)
# pandas在处理缺失数据时,如果是object类型自动None,如果是int或float类型则变成NaN1.2、数据结构DataFrame
DataFrame直翻就是数据帧,DataFrame的数据类似多维数组或表格数据。DataFrame中的每一列数据可以是不同的数据类型;DataFrame的索引包括行索引index和列索引column/label。
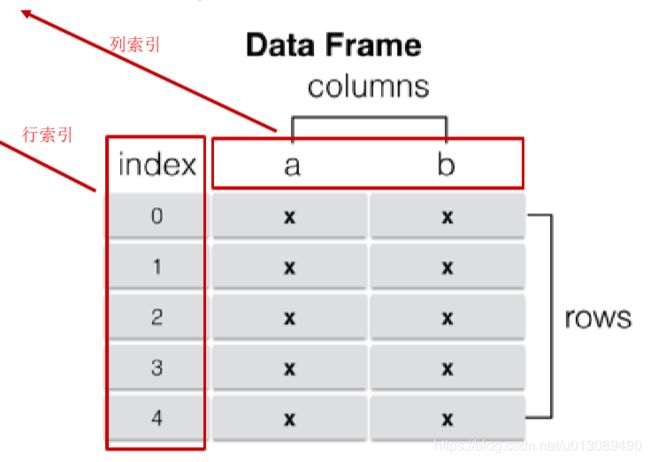
【DataFrame对象常见属性 】
(1)columns列信息
(2)可以使用df_obj.iterrows()产生一个迭代器;可以先用for循环。
DataFrame(data=None, index=None, columns=None, dtype=None,copy=False)【DataFrame对象参数说明】
(1)data参数,默认值为None,可以Series序列、arrays数组、constant常量或者类似列表的对象;如果是dict则必须是python3.6版本或更高版本。
(2)index参数:行索引或类似数组,用于生产索引。如果数据中没有索引或者指定索引,默认RangeIndex就是0,1,2...n。
(3)columns参数:列索引,用于生成列标签。如果没有列标签默认RangeIndex就是0,1,2...n。
(4)dtype参数:默认值为None,常用类型有str,list,dict等。
(5)copy参数:布尔类型默认值为False。从输入中复制数据。仅影响数据帧DataFrame或者二维数组ndarray输入。
【创建DataFrame对象方式】
(1)通过ndarray;
(2)通过dict;
【通过列索引获取列数据(Series类型)】
使用df_obj[label]或df_obj.label
【增加列数据,类似dict添加key-value】df_obj.[new_label] = data
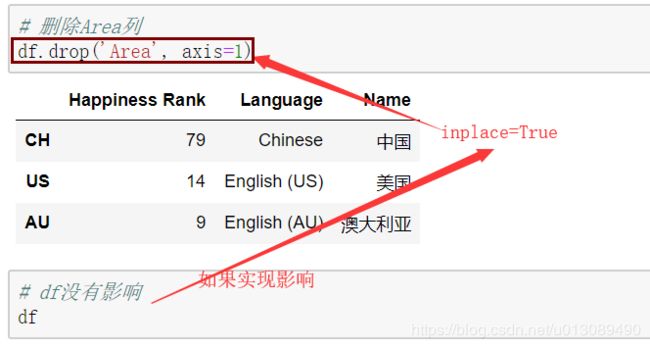
【删除列】
(1)df_obj.drop(columns=[]),注意返回值是操作后的数据,原数据不会改变;
(2)def df_obj[列索引],原数据会发生改变。
import numpy as np
import pandas as pd
#通过ndarray方式构建DataFrame
array = np.random.randn(5,4) # 构建5行4列的二维数组
df_obj = pd.DataFrame(array)
# 通过字典dict构建DataFrame
dict_data = {'a':1.,
'b': pd.Timestamp('20190203'),
'c': pd.Series(1,index=list(range(4)),dtype='float32'),
'd':np.array([3]*4,dtype='int32'),
'e':['java','c','c++','python'],
'f':'shanghai'
}
print(dict_data)
df_obj2 = pd.DataFrame(dict_data)
print(df_obj2)
print('列信息',df_obj2.columns)
print('索引信息',df_obj2.index)
print('行信息',df_obj2.values) # df_obj2.values是array数组
print('数据索引写法一:',df_obj2['e'])
print('数据索引写法二:',df_obj2.e)
# 增加列
df_obj2['g'] = range(4)
# 删除列方式一
df_obj3 = df_obj2.drop(columns=['b','g']) # 删除索引为b和g的两列数据
# 通过上面的删除我们发现,df_obj2数据没有变化,只是执行drop()方法时新产生一个DataFrame对象是删除后的数据
# 删除列方式二
del df_obj2['a'] # 使用del关键字删除指定列,df_obj2对象发生改变1.3、数据结构Index
在Series和DataFrame中索引都是Index对象,不可变immutaable,保证了数据的安全。常见的Index种类:
(1)Index
(2)Int64Index
(3)MultiIndex,“层级”索引;
(4)DatetimeIndex,时间戳类型;
重置索引使用reset_index(drop=True|False),将索引重新赋值为0-1;其中参数drop为True时表示丢掉原来的索引序列,默认为False。
2、Series和DataFrame的索引操作
2.1、Series索引操作
【行索引】
ser_obj['label'] 或 ser_obj[pos]
【切片索引】
ser_obj[2:4] 或ser_obj['label1','label3']
【不连续索引】
ser_obj[['label1','label1','label1']] 或 ser_obj[[pos1,pos2,pos3]]
import numpy as np
import pandas as pd
ser_obj = pd.Series(range(10,20,2),index=['a','b','c','d','e'])
# 行索引
print(ser_obj['b']) # 等同于ser_obj.loc['b']
print(ser_obj[1]) # 等同于ser_obj.iloc[1]
# 切片索引
print(ser_obj[1:3]) # 不包含索引下标为3的数据
print("="*90)
print(ser_obj['b':'d']) # 包含d列数据
# 不连续索引
print("="*90)
print(ser_obj[[0,2,4]])
print(ser_obj[['b','d']])2.2、DataFrame索引操作
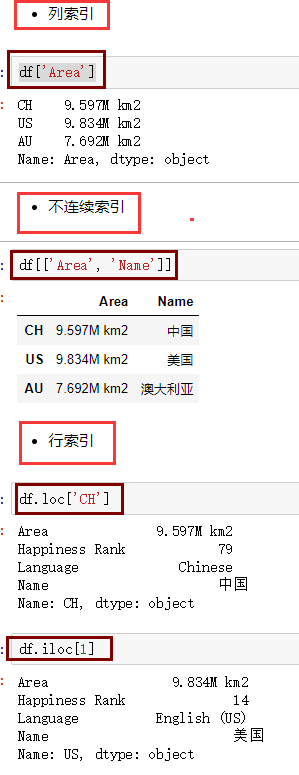
【列索引】
df_obj['label']
【不连续索引】
df_obj['label1','label5']
【行索引】
行索引和Series的索引类似,有.loc[],iloc[]。
【混合索引】
混合索引一般采用先行后列,或者是先列后行的方式。
在DataFrame中默认inplace=False,表示将操作后的结果进行返回,对原始数据不产生任何影响;当inplace=True没有返回值,在原始数据上进行操作,对原始数据会产生影响。
Pandas的索引可以总结为一下几点:
(1).loc[],标签索引;
(2).iloc[]:位置索引;
(3).loc[]和.iloc[]主要用于行索引;
(4)DataFrame索引时可以将其看做ndarray操作;标签的切片索引时包含末尾位置的。
# 构建DataFrame
country1 = pd.Series({'Name': '中国',
'Language': 'Chinese',
'Area': '9.597M km2',
'Happiness Rank': 79})
country2 = pd.Series({'Name': '美国',
'Language': 'English (US)',
'Area': '9.834M km2',
'Happiness Rank': 14})
country3 = pd.Series({'Name': '澳大利亚',
'Language': 'English (AU)',
'Area': '7.692M km2',
'Happiness Rank': 9})
df = pd.DataFrame([country1, country2, country3], index=['CH', 'US', 'AU'])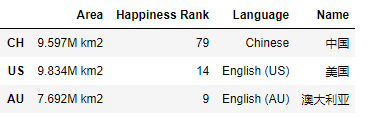

3、函数
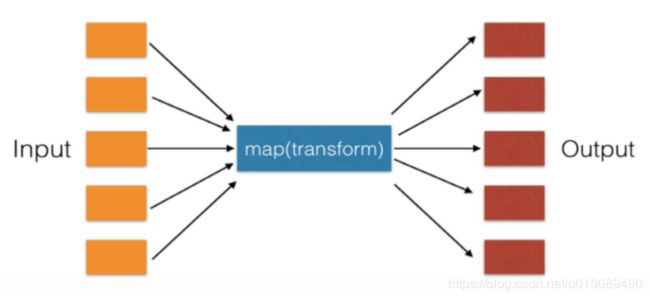
3.1、map()函数
map()函数只能应用于Series对象,将函数用于一个Series的每一个元素。用法类似于python的高阶函数map()操作。这种用法的好处是不使用循环,代码简洁,效率高。
import pandas as pd
import math
import numpy as np
#####################pandas中map()函数使用########################
l = list(range(10))
ser_obj = pd.Series(l)
#开根号
ser_obj1 =ser_obj.map(np.sqrt) # ser_obj没有发生改变,返回结果是一个新的对象
# 自定义lambda函数
ser_obj2 = ser_obj.map(lambda x: x**2+3)
print(ser_obj2)
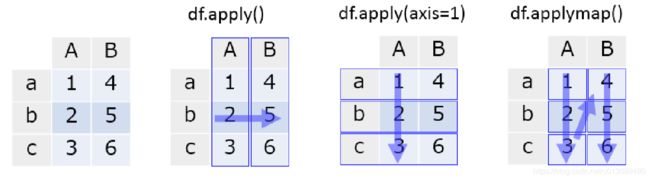
print(ser_obj)3.2、apply()/applymap()函数
【apply()函数】
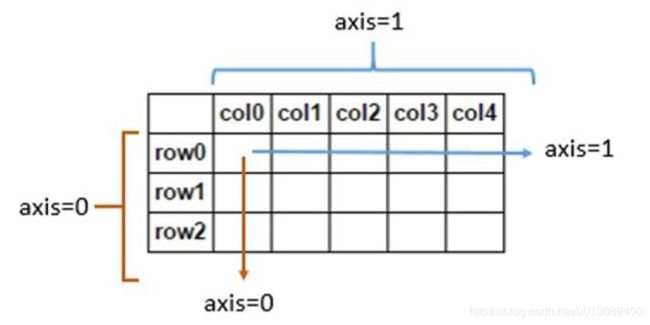
apply()函数即可应用于Series对象也可以应用于DataFrame对象上。通过apply()函数应用到行或者列上,在DataFrame中操作 是需要注意指定轴的方向,默认axis=0。
【applymap()函数】
applymap()函数是应用到DataFrame上的每一个元素上。注意和apply()方法的区别。
import pandas as pd
import math
import numpy as np
#####################pandas中apply()函数########################
# 生成一个5行2列的DataFrame二维数据,columns指定列名
df = pd.DataFrame(np.arange(10).reshape(5, 2), columns=['col_1', 'col_2'])
print(df.apply(np.sum)) # 由于apply()函数默认作用在axis=0轴方向上表示同一行数据累加,所以结果是Series对象
print(df.apply(np.sum,axis=1)) # 作用在axis=1轴上也就是列方向上表示同一列的数据累加,结果还是Series对象
#####################pandas中applymap()函数########################
print(df.applymap(np.sqrt)) # DataFrame上每一个数据进行开方根
staff_df = pd.DataFrame([{'姓名': '张三', '部门': '研发部'},
{'姓名': '李四', '部门': '财务部'},
{'姓名': '赵六', '部门': '市场部'}])
# 根据姓名列获取姓氏,并添加列姓氏
staff_df['姓'] = staff_df['姓名'].map(lambda x:x[0])
print(staff_df)3.3、排序函数sort_index()/sort_values()
sort_index()是按照索引排序;二sort_values是按照值排序,可以是多只值排序。
import pandas as pd
filepath = './test.csv'
# 读取文件
# read_excel()方法中的usecols表示读取那些列,index_col指定那一列为索引;都是列表类型
data = pd.read_csv(filepath, usecols=['Country', 'Region', 'Happiness Rank', 'Happiness Score'],
index_col='Happiness Rank')
###################1.索引排序 sort_index(ascending=False|True,axis=0|1)################
# (1)按照索引排序使用sort_index()方法,参数ascending是排序方式,ascending单词含义是上升,默认值为True表示升序且默认作用在0轴上也就是行上
print(data.sort_index(ascending=False).head(20))
# (2)按照列名排序
print(data.sort_index(ascending=True,axis=1).head(50))
###################2.按值排序 sort_values(by='只一个列名'|['列名1','列名2'])################
# 单列排序
print(data.sort_values(by='Country').head(30))
# 多列排序,其中by参数和ascending参数都是列表形式
print(data.sort_values(by=['Region','Country'],ascending=[True,False]).head(5))注意:在对多值排序也就是多列排序时,sort_values()函数中的by参数和ascending都是list类型,且顺序也是对应的。
【应用例子】
把日期字段列进行处理,处理 前如下:

import pandas as pd
import re
def process_date(row_data):
if '月' in row_data['date_time']:
row_data['date_time'] = re.sub("月","-",row_data['date_time'])
row_data['date_time'] = re.sub("日", "", row_data['date_time'])
row_data['date_time'] = "2019-" + row_data['date_time']
return row_data['date_time']
else: #此处一定要处理,否认在不处理值就为None
return row_data['date_time']
df = pd.read_excel("./weibo_final.xls",usecols=['type','url','date_time','content'])
ser_date = df.apply(lambda x:process_date(x),axis=1) # 注意处理某一行数据,需要指定坐标轴为1
df['date_time'] = ser_date
df.to_excel("澎湃新闻&人民日报.xlsx",index=False)
4、pandas对csv/excel文件操作
4.1、对csv文件基本操作
一般我们使用numpy的np.loadtxt()方法操作csv文件比较复杂,而使用pandas操作文件比较简单些。
【读csv文件】
df_obj = pd.read_csv(),返回DataFrame类型的数据 ; 索引在左,数值在右,索引是pandas自动创建的。
import pandas as pd
filename = "./test.csv"
df_obj = pd.read_csv(filename)
print('获取单列',df_obj['name'])
print('获取多列',df_obj['name','age'])【写csv文件】
df_obj.to_csv(), 参数index=False不写入索引列。
4.2、对excel文件基本操作
【读Excel文件】
读取excel文件使用read_excel(sheet_name='一个工作簿名称' | ['工作簿2','工作簿2'])方法。参数sheet_name就是工作簿的索引号,可以是单个工作簿也可以是多个工作簿。
read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None,names=None, parse_cols=None, parse_dates=False,date_parser=None,na_values=None,thousands=None, convert_float=True, has_index_names=None, converters=None,dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
参数解析:
(1)io : string, path object ; excel 路径。
(2)sheetname : 返回多表使用sheetname=[0,1],若sheetname=None是返回全表 注意:int/string 返回的是dataframe,而none和list返回的是dict of dataframe
(3)header : header参数:指定列名行,默认0,即取第一行,数据为列名行以下的数据 若数据不含列名,则设定 header = None ,注意这里还有列名的一行。
(4)skiprows : 省略指定行数的数据;
(5)skip_footer : int,default 0, 省略从尾部数的int行数据;
(6)index_col : int, list of ints, default None指定列为索引列,也可以使用u”strings”;
(7)names : array-like, default None, 指定列的名字。
import pandas as pd
filename = "./test.xlsx"
# 读取单个工作簿
df_obj_one = pd.read_excel(filename,sheet_name='Sheet1')
#读取多个工作簿
df_obj_more = pd.read_excel(filename,sheet_name=['Sheet1','Sheet2'])
print(df_obj_more['Sheet1'].head(2))
print(df_obj_more['Sheet1'].tail(4))
【写Excel文件】
存储函数为pd.DataFrame.to_excel(),注意,必须是DataFrame写入excel, 即Write DataFrame to an excel sheet。其具体参数如下:
to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None,columns=None, header=True, index=True, index_label=None,startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,
inf_rep='inf', verbose=True, freeze_panes=None)
【DataFrame对象的to_excel()常用参数】
(1)excel_writer参数,输出路径。
(2)sheet_name参数,将数据存储在excel的那个sheet页面,如果是一个工作簿就是字符串类型,如果多个工作簿则是列表类型。
(3)na_rep,缺失值填充;类型是str,默认是''空字符串。
(4) colums参数: sequence, optional,Columns to write 选择输出的的列。
(5)header参数: 布尔或列表或字符串类型,默认值为True写入到excel表格中,可以用list命名列的名字。header = False 则不输出题头也就列名不写入到excel表格中。
(6)index参数: boolean类型默认True且默认是把行索引写入到excel表格中;当index=False 则不显示行索引(名字)也就是行索引不写入到excel表格中。
(7)index_label参: 类型是字符串或序列, 默认为 None值;设置索引列的列名。
使用pd.to_excel()方法写入多个工作簿如下:
(1)第一步:writer = pd.ExcelWriter('output.xlsx’)
(2)第二步:写入工作簿Sheet1,df1.to_excel(writer,'Sheet1’) ;然后写入工作簿Sheet2,df2.to_excel(writer,'Sheet2’) 。
(3)第三步:保存工作簿writer.save()
import numpy as np
import pandas as pd
# 写入单个工作簿
ser_name =pd.Series(['a','b','c'])
ser_value = pd.Series([1,2,3])
data = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),
columns=['a', 'b', 'c'])
data.to_excel('只有一个工作簿.xlsx',index=False) # to_excel(index=False|True)参数index为False表示索引不写入excel表格
#读取多个工作簿
wf = pd.ExcelWriter('output.xlsx')
ser_country_1 = pd.Series(['美国','日本','德国','中国'])
ser_city_1 = pd.Series(['纽约','加州','北京','武汉'])
# index表示行索引是列表类型
df1 = pd.DataFrame([ser_city_1,ser_country_1],index=['x','y'])
# to_excel()函数的header参数表示写入excel后的列名
df1.to_excel(wf,sheet_name='Sheet_1',index=False,header=['a','b','c','d']) # index为False表示不写入
df2 = pd.DataFrame([[1,3],[2,4],[5,7],[6,8]])
# header参数默认值为True,表示列名默认为0,1..n的方式,如果为False表示列名不被写入到excel中。
df2.to_excel(wf,sheet_name='Sheet_2',index=False,header=False)
df3 = pd.DataFrame(np.arange(10).reshape(5,2))
df3.to_excel(wf,sheet_name='Sheet_3',index=False)
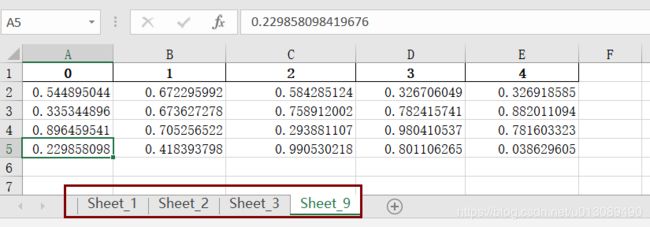
df4 = pd.DataFrame(np.random.rand(4,5)) # 生产四行五列
df4.to_excel(wf,sheet_name='Sheet_9',index=False)
wf.save()
# DataFrame对象to_excel()方法的freeze_panes参数指定要冻结最下面一行和最右边一列
# DataFrame对象to_excel()方法的na_rep 表示缺少数据表示,类型是str,默认是''空字符串
# DataFrame对象to_excel()方法的float_format参数表示浮点数的格式化字符串,例如float_format=“%.2f”
#DataFrame对象to_excel()方法的columns参数索引列的列标签(如果需要)。如果未指定,并且header和index为true,则使用索引名称。如果数据帧使用多索引,则应给出序列。
5、pandas数据清洗(缺失/重复/替换)
5.1、pandas处理数据缺失
在pandas中判断数据是否存在缺失值,Series对象的isnull()方法,或者是DataFrame的对象的isnull()方法。在结合any()方法判断行或者列中是否有缺失值存在。
【pandas处理缺失常用方法】
(1)dropna()方法:丢弃缺失数据,默认作用在0轴上,注意inplace参数表示直接修改原始数据;
def dropna(self, axis=0, how='any', thresh=None, subset=None,inplace=False)注意dropna()方法的参数inplace。默认值为Flase;
- inplace=False 没有对原始对象进行修改,有返回值,返回值结果就是创建一个新的对象;
- inplace=True对原始对象进行修改,无返回值;
dropna()方法的参数axis;默认axis为0表示按照行删除,当axis=1表示按照列删除
df.dropna(how='all')表示只会删除全部为空的行或者列,how的默认值any。
“删除某一列中有空值的行”
wb_data = pd.read_csv("微博_all.csv",usecols=use_columns)
print(wb_data.shape)
# 删除content_wb列中有空值的行
wb_data.dropna(subset=['content_wb'], axis=0,inplace=True)“统计某一列中有空值的行”
wb_data = pd.read_csv("微博_all.csv",usecols=use_columns)
# 统计content_wb列空值的行
info_null =wb_data['content_wb'].isnull().value_counts() 
(2)fillna()方法:填充缺失数据;
def fillna(self, value=None, method=None, axis=None, inplace=False,
limit=None, downcast=None, **kwargs)(3)df.ffill()方法:按之前的数据填充;
(4)df.bfill()方法:按之后的数据填充。
一般在项目中使用ffill()或者bfill()方法时,注意数据排序
import pandas as pd
filename = "./log.csv"
log_data = pd.read_csv(filename)
# 判断是否存在缺失值
print(log_data.isnull()) # isnull()方法是作用每一个元素上
# any()函数默认在行上也就是0轴上,any函数的作用是只有一个为True就为True
print(log_data.isnull().any()) # axis=0
print(log_data.isnull().any(axis=1)) # any()方法作用在1轴上,也就是列的上
# 丢弃缺失值
# dropna()函数默认作用在0轴上
print(log_data.dropna())
# 填充缺失值
print(log_data.fillna(-1)) # 将缺失值填为-1
sorted_log_data = log_data.sort_values(by=['time', 'user']) # 对数据进行排序
print(sorted_log_data.ffill()) # 按之前的填写
print(sorted_log_data.bfill()) # 按之后的填写对某一列添加缺失值
#给所在机构的缺失值添加为“--”
df['所在机构'].fillna("--")(4)缺失值得发现
缺失值的发现一般使用df.isnull()或者df.notnull()
5.2、pandas处理数据重复
1、duplicated()函数
duplicated()方法:返回表示重复行的布尔Series序列,可以选择某些列;
def duplicated(self, subset=None, keep='first')【duplicated()方法参数说明】
(1)subset参数:列标签或标签序列Series,默认是全部列;
(2)keep参数:默认值为first,该选项有 三个值first,last,False。first表示第一次出现,last表示最后一次出现,False表示将所有重复项标记为真。
2、drop_duplicates()方法
drop_duplicates()方法过滤重复行,默认判断全部列且第一次出现重复。
def drop_duplicates(self, subset=None, keep='first', inplace=False) 
drop_duplicates()函数参数说明,subset和keep参数和上面的duplicates()方法参数一样,而inplace为True参数表示直接修改原始数据无返回值;而inplace为False时表示不修改原始数据且有返回值,返回值是被处理后的数据。
import pandas as pd
data = pd.DataFrame(
{'age': [28, 31, 27, 28],
'gender': ['M', 'M', 'M', 'F'],
'surname': ['Liu', 'Li', 'Chen', 'Liu']}
)
# 判断是否存在重复数据
print(data.duplicated()) # 全部列上判断是否存在重复数据
print(data.duplicated(subset=['age','surname'])) # subset参数指定某些列
# 去掉重复数据
print(data.drop_duplicates(subset=['age','surname'])) # 去掉第一次出现重复的,在age和surname列上
print(data.drop_duplicates(subset=['age','surname'],keep='last')) # 去掉最后一次出现重复的在age和surname列上
5.3、pandas处理数据替换
pandas中替换数据使用replace()方法。
def replace(self, to_replace=None, value=None, inplace=False, limit=None,
regex=False, method='pad')而replace()方法常用参数是to_replace,参数to_replace为需要被替换的值,可以是数值、字符串,列表,字段。

import pandas as pd
data = pd.DataFrame(
{'A': [0, 1, 2, 3, 4],
'B': [5, 6, 7, 8, 9],
'C': ['a', 'b', 'c', 'd', 'e']}
)
# 数值替换,replace()方法作用在每一个元素上
print(data.replace(0, 100)) # 将0替换为100
# 列表替换为值
print(data.replace([0, 1, 2, 3], 4)) # 把列表中出现的全部替换为后面一个参数
# 列表替换为对应列表中的值
print(data.replace([0, 1, 2, 3], [4, 3, 2, 1]))
# 按字典替换
print(data.replace({0: 10, 1: 100})) # 把0替换为10,把1替换为1006、遍历Series对象和DataFrame对象
【遍历】
import pandas as pd
read_data = pd.read_excel("./city.xlsx", index_col="id")
#iterrows()方法遍历DataFrame对象
for index,rows in read_data.iterrows():#index表示行的索引,rows表示一行的数据,每个rows是一个字典类型
print(index,rows['name'],rows['type'])
#Series对象,就是一维数组
ser_data = read_data[read_data['type']=='A']['name']
for index,data in ser_data.iteritems(): #index表示行索引,data表示这个行的数据
print(data)7、pandas中取出重复的数据
# 第一步 将重复数据全部去除
data1 = df.drop_duplicates(subset="City",keep=False) # 当keep=False时,就是去掉所有的重复行
# 第二步骤:出现重复的数据只保留一个
data2= df.drop_duplicates(subset="City",keep='first') #当keep=‘first’时,就是保留第一次出现的重复行
# 第三步:将出现重复的数据只保留一个data2最佳到删除所有重复数据的data1中,最后删除所有重复数据;也就是求差集
data3 = data2.append(data1).drop_duplicates(keep=False)
data3.to_excel("招聘信息中重复数据.xlsx",index=False)
8、将excel中不同工作簿相同列名合并
import pandas as pd
f = pd.ExcelFile('河南省科学技术进步奖名单.xls')
print(f.sheet_names)# 获取工作表名称
data = pd.DataFrame()
for i in f.sheet_names:
d = pd.read_excel("河南省科学技术进步奖名单.xls",sheetname=i)
if not "年" in i:
i= i+"年"
print(d.columns.values.tolist(),i)
d["年份"] = i
data = pd.concat([data,d])
data.to_csv("河南省科学技术进步奖名单.csv",index=False,header=True)9、pandas读取网页中的table表格数据
#表格
ry_table = html.xpath("//div[@id='"+aria_id+"']//table[@class='el-table__body']").get()
table_data = pd.read_html(ry_table)[0]
for index, data in table_data.iterrows():
self.save_ry(key, active_name,data[0], data[1], data[2], data[3], data[4], data[5])