转自:
GATK4.0和全基因组数据分析实践(下)
QualByDepth(QD)
QD是变异质量值(Quality)除以覆盖深度(Depth)得到的比值。这里的变异质量值就是VCF中QUAL的值——用来衡量变异的可靠程度,这里的覆盖深度是这个位点上所有 含有变异碱基的样本的覆盖深度之和,通俗一点说,就是这个值可以通过累加每个含变异的样本(GT为非0/0的样本)的覆盖深度(VCF中每个样本里面的DP)而得到。举个例子:
1 1429249 . C T 1044.77 . . GT:AD:DP:GQ:PL 0/1:48,15:63:99:311,0,1644 0/0:47,0:47:99:392,0,0 1/1:0,76:76:99:3010,228,0
这个位点是1:1429249,VCF格式,但我把FILTER和INFO的信息省略了,它的变异质量值QUAL=1044.77。我们可以从中看到一共有三个样本,其中一个是杂合变异(GT=0/1),一个纯合的非变异(GT=0/0),最后一个是纯合的变异(GT=1/1)。每个样本的覆盖深度都在其各自的DP域上,分别是:63,47和76。按照定义,这个位点的QD值就应该等于质量值除以另外两个含有变异的样本的深度之和(排除中间GT=0/0这个不含变异的样本),也就是:
QD = 1044.77 / (63+76) = 7.516
QD这个值描述的实际上就是单位深度的变异质量值,也可以理解为是对变异质量值的一个归一化,QD越高一般来说变异的可信度也越高。在质控的时候,相比于QUAL或者DP(深度)来说,QD是一个更加合理的值。因为我们知道,原始的变异质量值实际上与覆盖的read数目是密切相关的,深度越高的位点QUAL一般都是越高的,而任何一个测序数据,都不可避免地会存在局部深度不均的情况,如果直接使用QUAL或者DP都会很容易因为覆盖深度的差异而带来有偏的质控结果。
在上面『执行硬过滤』的例子里面,我们看到认为好的SNP变异,QD的值不能低于2,但 问题是为什么是2,而不是3或者其它数值呢?
要回答这个问题,我们可以通过利用NA12878 VQSR质控之后的变异数据和原始的变异数据来进行比较,并把它说明白。
首先,我们可以先把所有变异位点的QD值都提取出来,然后画一个密度分布图(Y轴代表的是对应QD值所占总数的比例,而不是个数),看看QD值的总体分布情况(如下图,来自NA12878的数据)。
从这个图里,我们可以看到QD的范围主要集中在0~40之间。同时,我们可以明显地看到有两个峰值(QD=12和QD=32)。这两个峰所反映的恰恰是杂合变异和纯合变异的QD值所集中的地方。这里大家可以思考一下,哪一个是代表杂合变异的峰,哪一个是代表纯合变异的峰呢?
回答是,第一个峰(QD=12)代表杂合,而第二峰(QD=32)代表纯合,为什么呢?因为对于纯合变异来说,贡献于质量值的read是杂合变异的两倍,同样深度的情况下,QD会更大。对于大多数的高深度测序数据来说,QD的分布和上面的情况差不多,因此这个分布具有一定的代表性。
接着,我们同时画出VQSR之后所有 可信变异(FILTER=Pass)和 不可信变异的QD分布图,如下,浅绿色代表可信变异的QD分布图,浅红色代表不可信变异的QD分布图。
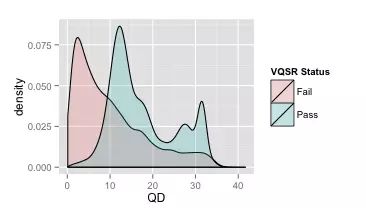
你可以看到,大多数Fail的变异,都集中在左边的低QD区域,而且红波峰恰好是QD=2的地方,这就是为什么硬过滤时设置QD>2的原因了。
可是在上面的图里,我想你也看到了,有很多Fail的变异它的QD还是很高的,有些甚至高于30,通过这样的硬过滤参数所得到的结果中就会包含这部分本该要过滤掉的坏变异;而同样的,在低QD(<2)区域其实也有一些是好的变异,但是却被过滤掉了。这其实也是硬过滤的一大弊端,它不会像VQSR那样,通过多个不同维度的数据构造合适的高维分类模型,从而能够更准确地区分好和坏的变异,而仅仅是一刀切。
当你理解了上面有关QD的计算和阈值选择的过程之后,要弄懂后面的指标和阈值也就容易了,因为用的也都是同样的思路。
FisherStrand(FS)
FS是一个通过Fisher检验的p-value转换而来的值,它要描述的是测序或者比对时对于只含有变异的read以及只含有参考序列碱基的read是否存在着明显的正负链特异性(Strand bias,或者说是差异性)。这个差异反应了测序过程不够随机,或者是比对算法在基因组的某些区域存在一定的选择偏向。如果测序过程是随机的,比对是没问题的,那么不管read是否含有变异,以及是否来自基因组的正链或者负链,只要是真实的它们就都应该是比较均匀的,也就是说,不会出现链特异的比对结果,FS应该接近于零。
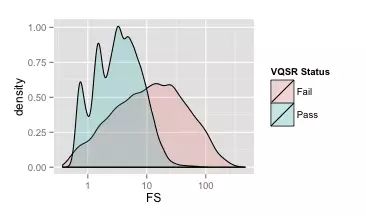
与QD一样,我们先来看一下质控前所有变异的FS总体密度分布图(如下)。很明显与QD相比,FS的范围更加的大,从0到好几百的都有。不过从图中也可以看出,绝大部分的变异还是在100以下的。这里多说一句,在VCF的INFO中有时除了FS之外,有时你还会看到SB或者SOR。它们实际上是从不同的层面对链特异的现象进行描述。只不过SB给出的是原始各链比对数目,而FS则是对这些数据做了精确Fisher检验;SOR原理和FS类似,但是用了不同的统计检验方法计算差异程度,它更适合于高覆盖度的数据。

下面这一个图则是经过VQSR之后,画出来的FS分布图。跟上面的QD一样,浅绿色代表好变异,浅红色代表坏变异。我们可以看到,大部分好变异的FS都集中在0~10之间,而且坏变异的峰值在60左右的位置上,因此过滤的时候,我们把FS设置为大于60。其实设置这么高的一个阈值是比较激进的(留下很多假变异),但是从图中你也可以看到,不过设置得多低,我们总会保留下很多假的变异,既然如此我们就干脆选择尽可能保留更多好的变异,然后祈祷可以通过『执行硬过滤』里其他的阈值来过滤掉那些无法通过FS过滤的假变异。
StrandOddsRatio(SOR)
关于SOR在上面讲到FS的时候,我就在注释里提及过了。它同样是对链特异(Strand bias)的一种描述,但是从上面我们也可以看到FS在硬过滤的时候并不是非常给力,而且由于很多时候read在外显子区域末端的覆盖存在着一定的链特异(这个区域的现象其实是正常的),往往只有一个方向的read,这个时候该区域中如果有变异位点的话,那么FS通常会给出很差的分值,这时SOR就能够起到比较好的校正作用了。计算SOR所用的统计检验方法也与FS不同,它用的是symmetric odds ratio test,数据是一个2×2的列联表(如下),公式也十分简单,我把公式进行了简单的展开,从中可以清楚地看出,它考虑的其实就是ALT和REF这两个碱基的read覆盖方向的比例是否有偏,如果完全无偏,那么应该等于1。

sor = (ref_fwd/ref_rev) / (alt_fwd/alt_rev) = (ref_fwd * alt_rev) / (ref_rev * alt_fwd)
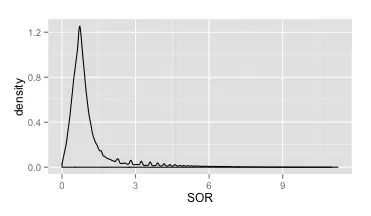
OK,那么同样的,我们先看一下这个值总体的密度分布情况(如下)。总的来说,这个分布明显集中在0~3之间,这也和我们的预期比较一致。不过也有比较明显的长尾现象,这个时候我们也没必要定下太过明确的阈值预期,先看VQSR的分布结果。
下面这个图就是在VQSR之后,区分了好和坏变异之后,SOR的密度分布。很明显,好的变异基本就在1附近。结合这个分布图,我们在上面的例子里把它的阈值定为3基本上也不会过损失好的变异了,虽然单靠这个阈值还是会保留下不少假的变异,但是至少不合理的长尾部分可以被砍掉。

RMSMappingQuality(MQ)
MQ这个值是所有比对至该位点上的read的比对质量值的均方根(先平方、再平均、然后开方,如下公式)。
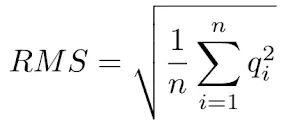
它和平均值相比更能够准确地描述比对质量值的离散程度。而且有意思的是,如果我们的比对工具用的是bwa mem,那么按照它的算法,对于一个好的变异位点,我们可以预期,它的MQ值将等于60。
下面是所有未过滤的变异位点上MQ的密度分布图。基本上就只在60的地方存在一个很瘦很高的峰。可以说这是目前为止这几个指标中图形最为规则的了,在这个图上,我们甚至就可以直接定出MQ的阈值了,比如所有小于50的就可以过滤掉了。
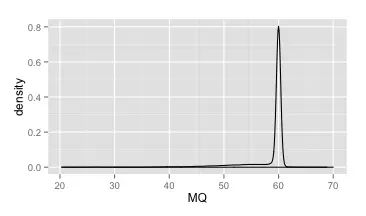
但是,理性告诉我们还是要看一下VQSR的对比结果(下图)。
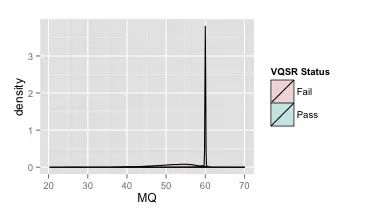
你会发现似乎所有好的变异都紧紧集中在60旁边了,其它地方就都是假的变异了,所以MQ的阈值设置为50也是合理的。但是同样要注意到的地方是,60这个范围实际上依然有假的变异位点在那里,我们把这个区域放大来看,如下图,这里你就会发现其实假变异的密度分布图也覆盖到60这个范围了。

考虑到篇幅的问题,接下来MappingQualityRankSumTest(MQRankSum)和ReadPOSRankSumTest(ReadPOSRankSum)的阈值设定原理,我不打算再细说下去了 ,思路和上面的4个是完全一样的。都是通过比较VQSR之后的密度分布图,最后确定了硬过滤的阈值。
但请不要以为这只是适用于GATK得到的变异,实际上,只要我们弄懂了这些指标选择的原因和过滤的思路,那么通过任何其他的变异检测工具也是依旧可以适用的,区别就在于GATK帮我们把这些要用的指标算好了。
同样地,这些指标也不是一成不变的,可以根据实际的情况换成其他,或者我们自己重新计算。
Ti/Tv处于合理的范围
Ti/Tv的值是物种在与自然相互作用和演化过程中在基因组上留下来的一个统计标记,在物种中这个值具有一定的稳定性。因此,一般来说,在完成了以上的质控之后,还会看一下这些变异位点Ti/Tv的值是多少,以此来进一步确定结果的可靠程度。
Ti(Transition)指的是嘌呤转嘌呤,或者嘧啶转嘧啶的变异位点数目,即A<->G或C<->T;
Tv(Transversion)指的则是嘌呤和嘧啶互转的变异位点数目,即A<->C,A<->T,G<->C和G<->T。(如下图)

另外,在哺乳动物基因组上C->T的转换比较多,这是因为基因组上的胞嘧啶C在甲基化的修饰下容易发生C->T的转变。
说了这么多,Ti/Tv的比值应该是多少才是正常的呢?如果没有 选择压力的存在,Ti/Tv将等于0.5,因为从概率上讲Tv将是Ti的两倍。但现实当然不是这样的,比如对于人来说,全基因组正常的Ti/Tv在2.1左右,而外显子区域是3.0左右,新发的变异(Novel variants)则在1.5左右。
最后多说一句,Ti/Tv是一个被动指标,它是对最后质控结果的一个反应,我们是不能够在一开始的时候使用这个值来进行变异过滤的。
作者:黄树嘉
鏈接:https://www.jianshu.com/p/ff8204ae7ebf
來源:簡書
簡書著作權歸作者所有,任何形式的轉載都請聯繫作者獲得授權並註明出處。