Python爬虫-爬取豆瓣读书
爬点什么好呢?最近老是浏览豆瓣上的帖子,那就爬取下豆瓣读书吧!
网络请求,返回值是html页面。
需要对返回回来的结果进行解析。使用Beautiful Soup来解析
参见(http://beautifulsoup.readthedocs.io/zh_CN/latest/)
说几个再爬虫中使用到的:
(1)find_all(tag,attributes,recursive,text,limit,keywords)
这个方法一般会大量使用,查找文档中含有该tag标签的所有信息
bsObj.find_all("li",{"class":""})就是查找文档中所有的li标签,并且该标签的class属性为“”
(2)获取某个标签属性的值,可以使用tag.get(“属性名称”)
a.get("href")(3)获取标签中的文本,可以使用get_text() 方法
如以下这种:
<span class="publisher">
理想国 | 广西师范大学出版社
span>可以使用
span.get_text()还有其他的父节点获取,子节点获取等等很多,参见文档获取详细用法。
上图:

我先拿到li标签下的信息,因为我只获取自己感兴趣的信息,所以创建列表,再分别获取div,h4,span标签下的信息,赋值。最后将其插入mongodb。
from urllib.request import urlopen,HTTPError
from bs4 import BeautifulSoup
import pymongo
import time
client = pymongo.MongoClient('localhost', 27017) # 连接mongodb,端口27017
#db=client.myinfo
test = client['test'] # 创建数据库文件test
reptiledouban = test['reptiledouban'] # 创建表forecast
html=urlopen("https://book.douban.com/")
bsObj=BeautifulSoup(html,"html.parser")
dict={}
keys = ["_id","封面链接", "购买链接", "主题", "作者", "出版日期", "出版社"]
count=1
for link in bsObj.find_all("li",{"class":""}):
for linkFirst in link.find_all("div",{"class":"cover"}):
dict["封面链接"]=(linkFirst.a.get("href"))
for linksecond in link.find_all("div", {"class": "intervenor-info"}):
dict["购买链接"] = (linksecond.img.get("src"))
for linkThird in link.find_all("div", {"class": "more-meta"}):
dict["主题"] = (linkThird.h4.get_text())
for linkFourth in link.find_all("div", {"class": "author"}):
dict["作者"] = (linkFourth.get_text())
for linkFive in link.find_all("span", {"class": "year"}):
dict["出版日期"] = (linkFive.get_text())
for linkSix in link.find_all("span", {"class": "publisher"}):
dict["出版社"] = (linkSix.get_text())
if dict:
dict["_id"] = count
reptiledouban.insert_one(dict) #插入mongodb数据库
time.sleep(1) # 线程推迟1s执行
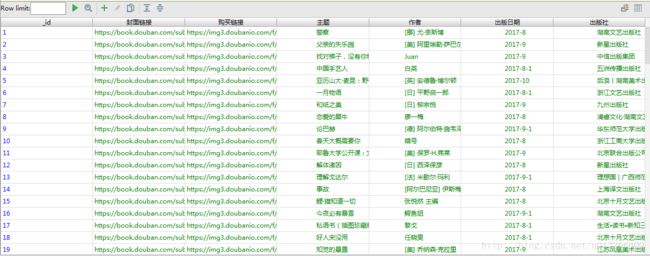
count = count + 1最后mongdb 中的结果如下:
问题总结:
(1)mongdb中插入数据库,按照默认的“_id”字段,主键插入重复,所以我重新自定义了主键,每次自增一,解决重复问题。
(2)我现在爬取出来的数据其中有重复数据,还不知道这是怎么回事?待解