论文笔记:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(第一版)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(第二版)
前言
本文基于是Google在2019年5月发表的版本,与2018年11月发表的第一版略有不同,第二版将第一版中的3、4章中的一些细节,如预训练和微调过程、数据集描述、部分消融实验等放到了附录里。网上的翻译大多基于第一版,本文基于第二版,对论文大部分内容进行了翻译,也稍有一些删减或补充。
Abstract
BERT 表示来自 Transformer 的双向编码器表示(Bidirectional Encoder Representations from Transformers)。
BERT 旨在通过联合调节所有层中的左右上下文来预训练来自未标记文本的深度双向表示。 因此,只需要一个额外的输出层,就可以对预训练的 BERT 表示进行微调,从而为广泛的任务(比如回答问题和语言推断任务)创建最先进的模型,而无需对特定于任务进行大量模型结构的修改。
BERT 的概念很简单,但实验效果很强大。它刷新了 11 个 NLP 任务的当前最优结果,包括将 GLUE
基准提升至 80.4%(7.6% 的绝对改进)、将 MultiNLI 的准确率提高到 86.7%(5.6% 的绝对改进),以及将 SQuAD v1.1 的问答测试 F1 得分提高至 93.2 分(提高 1.5 分)——比人类表现还高出 2 分。
1 Introduction
语言模型预训练可以显著提高许多自然语言处理任务的效果。这些任务包括句子级任务,如自然语言推理和释义,目的是通过句子的整体分析来预测句子之间的关系,以及标记级任务,如命名实体识别和 SQuAD 问答,模型需要在标记级(token-level)生成细粒度的输出。
现有的两种方法可以将预训练好的语言模型表示应用到下游任务中:基于特征(feature-based)和基于微调(fine-tuning)。基于特征的策略(如 ELMo)使用特定于任务的模型结构,其中包含预训练的表示作为附加特征。微调策略(如生成预训练 Transformer (the Generative Pre-trained Transformer,OpenAI GPT))引入了最小的特定于任务的参数,通过简单地微调预训练参数在下游任务中进行训练。 在之前的研究中,两种策略在预训练期间使用相同的目标函数,利用单向语言模型来学习通用语言表达。
因为标准语言模型是单向的,这就限制了可以在预训练期间可以使用的模型结构的选择。例如,在 OpenAI GPT 中,作者使用了从左到右的模型结构,其中每个token只能关注 Transformer 的self-attention层中该token前面的token。这些限制对于句子级别的任务来说是次优的(还可以接受),但当把基于微调的方法用来处理token级别的任务(如 SQuAD 问答)时可能会造成不良的影响,因为在token级别的任务下,从两个方向分析上下文是至关重要的。
受完形填空任务的启发,BERT 通过提出一个新的预训练任务来解决前面提到的单向约束:“遮蔽语言模型”(MLM,masked language model)。遮蔽语言模型从输入中随机遮蔽一些token标记,目的是仅根据被遮蔽标记的上下文来预测它对应的原始词汇的 id。与从左到右的语言模型预训练不同,MLM 目标允许表示融合左右上下文,这允许我们预训练一个深层双向 Transformer。除了遮蔽语言模型之外,我们还提出了一个联合预训练文本对来进行“下一个句子预测”的任务。
本文的贡献:
- 论证了双向预训练对语言表征的重要性。
- 预训练的表示消除了许多特定于任务的高度工程化的模型结构的需求。BERT 是第一
个基于微调的表示模型,它在大量的句子级和标记级任务上实现了最先进的性能,优于许多特定
于任务的结构的模型。 - BERT 在 11 个 NLP 任务上有提升。
2 Related Work
预训练通用语言表示有很长的历史,本节仅简要回顾最流行的方法。
2.1 Unsupervised Feature-based Approaches
经过预训练的词嵌入被认为是现代 NLP 系统的一个不可分割的部分,词嵌入(word embedding)提供了比从头开始学习的显著改进。
这些方法已被推广到更粗的粒度,如句子嵌入(sentence embedding)或段落嵌入(paragraph embedding)。与传统的单词嵌入一样,这些学习到的表示通常也用作下游模型的输入特征。
ELMo从不同的维度对传统的词嵌入研究进行了概括。他们建议从语言模型中提取上下文敏感的特征。在将上下文嵌入与特定于任务的架构集成时,ELMo 为几个主要的 NLP 标准提供了最先进的技术,包括在 SQuAD 上的问答,情感分析,和命名实体识别。
2.2 Unsupervised Fine-tuning Approaches
语言模型迁移学习(LMs)的一个最新趋势是,在对受监督的下游任务的模型进行微调之前,先对 LM目标上的一些模型构造进行预训练。这些方法的优点是只有很少的参数需要从头开始学习。至少部分得益于这一优势,OpenAI GPT 在 GLUE 基准测试的许多句子级任务上取得了此前最先进的结果。
2.3 Transfer Learning from Supervised Data
虽然无监督预训练的优点是可用的数据量几乎是无限的,但也有研究表明,从具有大数据集的监督任
务中可以进行有效的迁移,如自然语言推理和机器翻译。在NLP之外,计算机视觉研究也证明了从大型预训练模型中进行迁移学习的重要性,有一个有效的方法可以微调在 ImageNet 上预训练的模型。
3 BERT
Model Architecture
BERT 的模型结构是一个多层双向Transformer 编码器。
在本文中,我们将层数(即 Transformer 块)表示为 L,将隐藏尺寸表示为 H、自注意力头数表示为 A。在所有实验中,我们将前馈/滤波器尺寸设置为 4H,即 H=768 时为 3072,H=1024 时为 4096。我们主要报告在两种模型尺寸上的结果:
- B E R T B A S E BERT_{BASE} BERTBASE: L=12, H=768, A=12, 总参数=110M
- B E R T L A R G E BERT_{LARGE} BERTLARGE: L=24, H=1024, A=16, 总参数=340M
为了比较, B E R T B A S E BERT_{BASE} BERTBASE 的模型尺寸与 OpenAI GPT 相当。然而,BERT Transformer 使用双向自注意力机制,而 GPT Transformer 使用受限的自注意力机制,导致每个 token 只能关注其左侧的语境。
我们注意到,双向 Transformer 在文献中通常称为「Transformer 编码器」,而只关注左侧语境的版本则因能用于文本生成而被称为「Transformer 解码器」。
Input/Output Representations
我们的输入表示能够在一个标记序列中清楚地表示单个文本句子或一对文本句子(例如,[Question,
Answer])。(注释:在整个工作中,“句子”可以是连续的任意跨度的文本,而不是实际语言意义上的句子。“序列”是指输入到 BERT 的标记序列,它可以是单个句子,也可以是两个句子组合在一起。)通过把给定标记对应的标记嵌入、句子嵌入和位置嵌入求和来构造其输入表示。

- 我们使用含 3 万个标记词语的 WordPiece 嵌入(Wu et al., 2016)。我们用 ## 表示拆分的单词
片段。 - 我们使用学习到的位置嵌入,支持的序列长度最长可达 512 个标记。
- 每个序列的第一个标记始终是特殊分类嵌入([CLS])。该特殊标记对应的最终隐藏状态(即,
Transformer 的输出)被用作分类任务中该序列的总表示。对于非分类任务,这个最终隐藏状态将
被忽略。
句子对被打包在一起形成一个单独的序列。我们用两种方法区分这些句子。方法一,我们用一个
特殊标记([SEP])将它们分开。方法二,我们给第一个句子的每个标记添加一个可训练的句子 A
嵌入,给第二个句子的每个标记添加一个可训练的句子 B 嵌入。 - 对于单句输入,我们只使用句子 A 嵌入。
3.1 Pre-traing BERT
Task #1: Masked LM
直觉上,我们有理由相信,深度双向模型严格来说比从左到右模型或从左到右模型结合从右到左模型
的浅层连接更强大。不幸的是,标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件
作用将允许每个单词在多层上下文中间接地“看到自己”。
为了训练深度双向表示,我们采用了一种简单的方法,即随机遮蔽一定比例的输入标记,然后仅预测
那些被遮蔽的标记。我们将这个过程称为“遮蔽语言模型”(masked LM, MLM),尽管在文献中它通常被称为完形填词(Cloze)任务(Taylor, 1953)。在这种情况下,就像在标准语言模型中一样,与遮蔽标记相对应的最终隐藏向量被输入到与词汇表对应的输出 softmax 中(也就是要把被遮蔽的标记对应为词汇表中的一个词语)。在我们所有的实验中,我们在每个序列中随机遮蔽 15% 的标记。与去噪的自动编码器(Vincent et al., 2008)不同的是,我们只是让模型预测被遮蔽的标记,而不是要求模型重建整个输入。
虽然这允许我们获得双向的预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为在微调期间不会出现[MASK]令牌。为了缓解这种情况,我们并不总是使用实际的[MASK]令牌来替换“被遮蔽的”单词。**训练数据生成器随机选择15%的令牌位置进行预测。如果选择了第i个令牌,我们将第i个令牌替换为(1)80%的时间:[MASK]令牌;(2)10%的时间:一个随机令牌;(3)10%的时间:不变的第i个令牌。**然后,Ti将用于预测具有交叉熵损失的原始令牌。我们在附录C.2中比较这个过程的变化。
Task #2: Next Sentence Prediction (NSP)
许多重要的下游任务,例如问答(QA)和自然语言推论(NLI),都是基于对两个句子之间关系的理解,而这并不是语言建模直接捕获的。 为了训练能够理解句子关系的模型,我们预训练了可以从任何单语语料库琐碎生成的二值化的下一个句子预测任务。 特别,在为每个预训练示例选择句子A和B时,有50%的时间B是A后面的下一个句子(标记为IsNext),有50%的时间A后面的下一个句子是来自语料库(标记为NotNext)。 正如我们所示在图1中,C用于下一句预测(NSP)。尽管它很简单,但我们在5.1节中证明了对此的预训练这项任务对QA和NLI都是非常有益的。
NSP任务与Jernite等(2017)和洛格斯瓦兰和李(2018)使用的表征学习目标密切相关。然而,在以前的工作中,只有语句嵌入被传输到下游任务,然而BERT传输所有的参数来初始化最终任务模型参数。
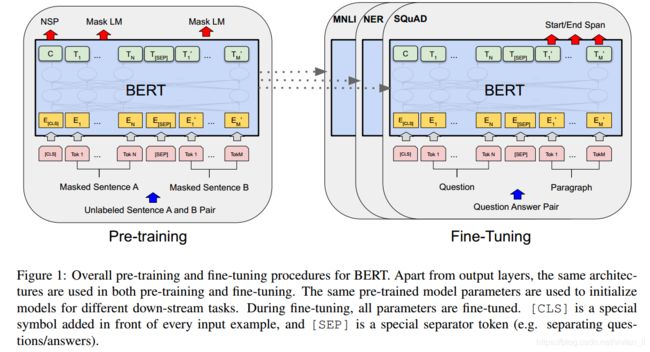
Pre-training data
预训练程序很大程度上遵循了现有的语言模型预训练的文献。对于预训练的语料库,我们使用BooksCorpus(8亿单词)和英文维基百科(2500万字)。对于Wikipedia,我们只提取文本段落,而忽略列表、表格和标题。为了提取长的连续序列,使用文档级别的语料库,而不是使用像 Billion Word Benchmark (Chelba et al., 2013)那样使用打乱顺序的句子级别语料库是至关重要的。
3.2 Fine-tuning BERT
微调非常简单,因为Transformer中的自我关注机制使BERT可以通过交换适当的输入和输出来对许多下游任务进行建模,无论是涉及单个文本还是文本对。对于涉及文本对的应用程序,常见模式是在应用双向交叉注意力之前对文本对进行独立编码,例如Parikh等(2016);Seo等(2017)。 而BERT是使用自我注意机制来统一这两个阶段,由于用自注意力编码连接的文本对有效地包含了两个句子之间的双向交叉注意。
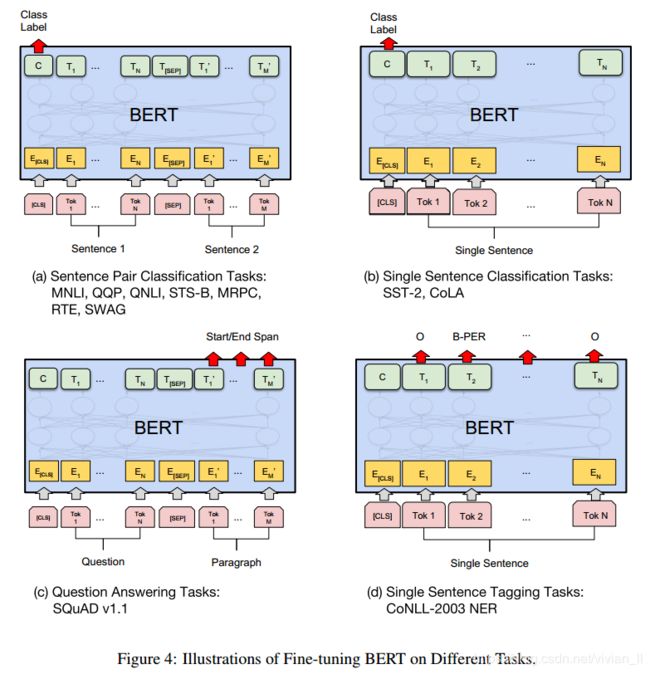
对于每个任务,我们只需将特定于任务的输入和输出插入BERT并对所有参数进行端到端的微调。在输入处,训练前的句子A和句子B类似于(1)释义(paraphrasing)中的句子对,(2)隐含的假设-前提对,(3)问题答案中的问题-段落对,以及(4)文本分类或序列标记中的退化的text- ∅ \varnothing ∅ 对。 在输出中,令牌表示形式被输入到一个输出层,用于标记级任务,如序列标记或问题回答,而[CLS]表示形式被输入到一个输出层,用于分类,如entailment或情感分析。
与预训练相比,微调相对便宜(inexpensive)。论文中的所有结果都可以从完全相同的预先训练的模型开始,在单个Cloud TPU上复现最多1个小时,或者在GPU上复现几个小时。我们将在第4节的相应小节中描述特定于任务的细节。更多详细信息,请参见附录A.5。
4 Experiments
在本节中,我们将展示11个NLP任务的BERT微调结果。
4.1 GLUE
通用语言理解评价 (GLUE,General Language Understanding Evaluation) 基准(Wang et al.(2018))是对多种自然语言理解任务的集合。GLUE数据集的详细描述包含在附录B.1中。
为了在 GLUE 上微调模型,我们按照本文第 3 节中描述的那样表示输入的句子或者句子对,并且使用
最后一层的隐藏向量 C ∈ R H C \in \mathbb{R}^{H} C∈RH中的第一个输入标记([CLS])作为句子总的表示。在微调期间唯一引入的新的参数是一个分类层参数矩阵 W ∈ R K × H W \in \mathbb{R}^{K \times H} W∈RK×H,其中K是要分类的数量。我们用C和W计算一个标准的分类损失,换句话说是 log ( softmax ( C W T ) ) \log\left(\operatorname{softmax}\left(C W^{T}\right)\right) log(softmax(CWT)) 。
我们对所有的GLUE任务中的数据使用32的batch size和微调在3个epoch中。对于每个任务,我们在验证集上选择最佳的微调学习率(在5e-5、4e-5、3e-5和2e-5之间)。此外,对于 B E R T L A R G E BERT_{LARGE} BERTLARGE,我们发现finetuning有时在小数据集上是不稳定的,所以我们运行了几个随机重启,并在验证集中选择了最好的模型。对于随机重启,我们使用相同的预训练检查点,但执行不同的数据打乱和分类器层初始化来微调模型。
结果如表 1 所示。在所有的任务上, B E R T B A S E BERT_{BASE} BERTBASE 和 B E R T L A R G E BERT_{LARGE} BERTLARGE 都比现有的系统更加出色 ,与先进水平相比,分别取得 4.4% 及 6.7% 的平均改善。请注意,除了 B E R T B A S E BERT_{BASE} BERTBASE含有注意力屏蔽(attention masking), B E R T B A S E BERT_{BASE} BERTBASE和 OpenAI GPT 的模型结构方面几乎是相同的。对于最大和最广泛使用的 GLUE 任务 MNLI,BERT 比当前最优模型获得了 4.7% 的绝对提升。在 GLUE 官方的排行榜上, B E R T L A R G E BERT_{LARGE} BERTLARGE获得了 80.4 的分数,与原榜首的 OpenAI GPT 相比截止本文写作时只获得了 72.8 分。
我们发现, B E R T L A R G E BERT_{LARGE} BERTLARGE在所有任务中都显著优于 B E R T B A S E BERT_{BASE} BERTBASE,尤其是那些训练数据很少的任务。模型大小的影响在5.2节中进行了更深入的探讨。
4.2 SQuAD v1.1
斯坦福问答数据集(SQuAD Standford Question Answering Dataset)是一个由 100k 个众包的问题/
答案对组成的集合(Rajpurkar et al., 2016)。给出一个问题和一段来自维基百科包含这个问题答案的
段落,我们的任务是预测这段答案文字的区间。
我们将输入问题和段落表示为一个单一打包序列(packed sequence),其中问题使用 A 嵌入,段落使用 B 嵌入。在微调模型期间唯一需要学习的新参数是区间开始向量 S ∈ R H S \in \mathbb{R}^{H} S∈RH和区间结束向量 E ∈ R H E \in \mathbb{R}^{H} E∈RH 。让 BERT 模型最后一层的隐藏向量的第 i t h i^{t h} ith输入标记被表示为 T i ∈ R H T_{i} \in \mathbb{R}^{H} Ti∈RH。然后,计算单词 i 作为答案区间开始的概率,它是 T i T_i Ti和 S S S 之间的点积并除以该段落所有单词的结果之后再 softmax: P i = e S ⋅ T i ∑ j e S ⋅ T j P_{i}=\frac{e^{S \cdot T_{i}}}{\sum_{j} e^{S \cdot T_{j}}} Pi=∑jeS⋅TjeS⋅Ti。
同样的式子用来计算单词作为答案区间的结束的概率,并采用得分最高的区间作为预测结果。训练目
标是正确的开始和结束位置的对数可能性。
我们表现最好的模型在集成模型排名中上比排名第一模型高出 1.5 个 F1 值,在一个单模型排行榜中比
排名第一的模型高出 1.3个 F1 值。实际上,我们的单模型 BERT 就比最优的集成模型表现更优。即使只在 SQuAD 数据集上(不用 TriviaQA 数据集)我们只损失 0.1-0.4 个 F1值,而且我们的模型输出结果仍然比现有模型的表现好很多。
4.3 SQuAD v2.0
SQuAD2.0任务扩展了SQuAD1.1问题的定义,允许在提供的段落中不存在简短的答案,从而使问题更加实际。
我们观察到比以前最好的系统提升了5.1 F1。
4.4 SWAG
Adversarial Generations(SWAG)数据集由 113k 个句子对组合而成,用于评估基于常识的推理
(Zellers et al., 2018)。给出一个来自视频字幕数据集的句子,任务是在四个选项中选择最合理的延续。
为 SWAG 数据集调整 BERT 模型的方式与为 GLUE 数据集调整的方式相似。
B E R T L A R G E BERT_{LARGE} BERTLARGE优于作者的 ESIM+ELMo 的基线标准模型的 27.1%和OpenAI GPT的8.3% 。
5 Ablation Studies(消融研究)
在本节中,我们对 BERT 的许多方面进行了消融实验,以便更好地理解每个部分的相对重要性。
5.1 Effect of Pre-training Tasks
(我们的核心观点之一是,与之前的工作相比,BERT 的深层双向性(通过遮蔽语言模型预训练)是最重要的改进。)
我们通过使用与 B E R T B A S E BERT_{BASE} BERTBASE完全相同的预训练数据、微调方案和超参数来评估两个训练前目标,从而证明BERT的深度双向性的重要性:
- No NSP:一个双向的模型,使用“遮蔽语言模型”(MLM)但是没有“预测下一句任务”(next sentence prediction,NSP)。
- LTR & No NSP:一个只考虑左上下文(left-context-only)的模型,使用一个标准的从左到右(Left-to-Right,LTR)的语言模型,而不是遮蔽语言模型。在这种情况下,我们预测每个输入词,不应用任何遮蔽。在微调中也应用了仅限左的约束,因为我们发现使用仅限左的上下文进行预训练和使用双向上下文进行微调总是比较糟糕。此外,该模型未经预测下一句任务的预训练。这与OpenAI GPT有直接的可比性,但是使用更大的训练数据集、输入表示和微调方案。

我们可以看到去除 NSP 对 QNLI、MNLI和 SQuAD 的表现造成了显著的伤害。这些结果表明,我们的预训练方法对于获得先前提出的强有力的实证结果是至关重要的。
LTR 模型在所有任务上的表现都比 MLM 模型差,在 MRPC 和 SQuAD 上的下降特别大。对于SQuAD来说,很明显 LTR 模型在区间和标记预测方面表现很差,因为标记级别的隐藏状态没有右侧上下文。
为了增强 LTR 系统,我们尝试在其上添加一个随机初始化的 BiLSTM 来进行微调。这确实大大提高了SQuAD 的成绩,但是结果仍然比预训练的双向模型表现差得多。它还会损害所有四个 GLUE 任务的性能。
也可以培训单独的 LTR 和 RTL 模型,并将每个标记表示为两个模型表示的连接,就像ELMo 所做的那样。但是:(a)这是单个双向模型参数的两倍大小;(b)这对于像 QA 这样的任务来说是不直观的,因为 RTL 模型无法以问题为条件确定答案;(c)这比深层双向模型的功能要弱得多,因为深层双向模型可以选择使用左上下文或右上下文。
5.2 Effect of Model Size
多年来人们都知道,增加模型的大小将持续提升在大型任务(如机器转换和语言建模)上的的表现,表 6
所示的由留存训练数据(held-out traing data)计算的语言模型的困惑度(perplexity)。然而,我们
相信,这是第一次证明,如果模型得到了足够的预训练,那么将模型扩展到极端的规模也可以在非常小的任务中带来巨大的改进。

5.3 Feature-based Approach with BERT

结果如表 7 所示。最佳的执行方法是从预训练的转换器的前 4 个隐藏层串联符号表示,这只比整个模
型的微调落后 0.3 F1 值。这说明 BERT 对于微调和基于特征的方法都是有效的。
6 Conclusion
最近,由于使用语言模型进行迁移学习而取得的实验提升表明,丰富的、无监督的预训练是许多语言
理解系统不可或缺的组成部分。特别是,这些结果使得即使是低资源(少量标签的数据集)的任务也
能从非常深的单向结构模型中受益。我们的主要贡献是将这些发现进一步推广到深层的双向结构,使
同样的预训练模型能够成功地广泛地处理 NLP 任务。
Appendix
附录包括BERT的更多细节、实验的更多细节和进一步的消融研究,包括训练步数的影响和不同masking程序的消融。
A \quad Additional Details for BERT
A.1 Illustration of the Pre-training Tasks
Masked LM and the Masking Procedure
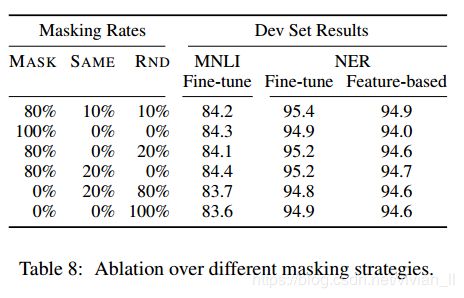
BERT为了训练拥有双向句子信息的模型采用了一种随机遮蔽一定比例的输入标记,然后预测那些被遮蔽的标记的预训练任务。BERT在每个序列中随机遮蔽 15% 的标记,然后通过最后使用softmax去预测被遮蔽的字,但直接使用这样的预训练任务会有两个问题:
- 预训练和微调之间造成了不匹配,因为 [MASK] 标记在微调期间从未出现过。
- 使用 Transformer 的每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛
为了解决问题一(问题二还有待优化),BERT采用了以下的操作:
80% 的情况下:用 [MASK] 替换被选择的单词,例如,my dog is hairy → my dog is [MASK]
10% 的情况下:用一个随机单词替换被选择的单词,例如,my dog is hairy → my dog is apple
10% 的情况下:保持被选择的单词不变,例如,my dog is hairy → my dog is hairy
这种方法的优点是Transformer 编码器不知道它将被要求预测哪些单词,或者哪些单词已经被随机单词替换,因此它被迫保持每个输入标记的分布的上下文表示。另外,因为随机替换只发生在 1.5% 的标记(即,15% 的10%)这似乎不会损害模型的语言理解能力。
Next Sentence Prediction

A.2 Pre-training Procedure
为了生成每个训练输入序列,我们从语料库中采样两段文本,我们将其称为“句子”,尽管它们通常比单个句子长得多(但也可以短一些)。第一个句子添加 A 嵌入,第二个句子添加 B 嵌入。50% 的情况下B 确实是 A 后面的实际下一句,50% 的情况下它是随机选取的一个的句子,这是为“下一句预测”任务所做的。两句话合起来的长度要小于等于 512 个标记。语言模型遮蔽过程是在使用 WordPiece 序列化句子后,以均匀的 15% 的概率遮蔽标记,不考虑部分词片的影响(那些含有被 WordPiece 拆分,以##为前缀的标记)。
我们使用 256 个序列(256 个序列 * 512 个标记= 128,000 个标记/批次)的批大小进行 1,000,000 步
的训练,这大约是在 33 亿词的语料库中训练 40 个周期。我们用Adam 优化算法并设置其学习率为
1 e − 4 , β 1 = 0.9 , β 2 = 0.999 1 e-4, \beta 1=0.9, \beta 2=0.999 1e−4,β1=0.9,β2=0.999,L2的权重衰减是 0.01,并且在前 10000 步学习率热身(learning rate warmup),然后学习率开始线性衰减。我们在所有层上使用 0.1 概率的 dropout。像
OpenAI GPT 一样,我们使用 gelu 激活(Hendrycks and Gimpel, 2016)而不是标准 relu。训练损失是遮蔽语言模型似然值与下一句预测似然值的平均值。
更长的序列代价过高(disproportionately expensive ),因为注意力是序列长度的平方。为了加快预处理速度,我们0%的步骤用128的序列长度来预训练模型。然后,我们用长为512的序列来训练其余的步骤的10%,来学习位置嵌入。
A.3 Fine-tuning Procedure
对于微调,除了批量大小、学习率和训练次数外,大多数模型超参数与预训练期间相同。Dropout 概
率总是使用 0.1。最优超参数值是特定于任务的,但我们发现以下可能值的范围可以很好地在所有任务
中工作:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
我们还观察到大数据集(例如 100k+ 标记的训练集)对超参数选择的敏感性远远低于小数据集。微调
通常非常快,因此只需对上述参数进行完全搜索,并选择在验证集上性能最好的模型即可。
A.4 Comparison of BERT, ELMo ,and OpenAI GPT

请注意,除了架构上的差异外,BERT和OpenAI GPT是基于fine-tuning的方法,而ELMo是feature-based的方法。
在现有预训练方法中,与 BERT 最相似的是 OpenAI GPT,它在一个大的文本语料库中训练从左到右
的 Transformer 语言模型。事实上,BERT 中的许多设计决策都是有意选择尽可能接近 GPT 的,这样
两种方法就可以更加直接地进行比较。我们工作的核心论点是,在 3.1 节中提出的两项新的预训练语
言模型任务占了实验效果改进的大部分,但是我们注意到 BERT 和 GPT 在如何训练方面还有其他几
个不同之处:
- GPT 是在 BooksCorpus(800M 词)上训练出来的;BERT 是在 BooksCor-pus(800M 词)和
Wikipedia(2,500M 词)上训练出来的。 - GPT 仅在微调时使用句子分隔符([SEP])和分类标记([CLS]);BERT 在预训练时使用
[SEP], [CLS] 和 A/B 句嵌入。 - GPT 在每批次含 32,000 词上训练了 1M 步;BERT 在每批次含 128,000 词上训练了 1M 步。
- GPT 在所有微调实验中学习速率均为 5e-5;BERT 选择特定于任务的在验证集中表现最好的微调
学习率。
为了分清楚这些差异的影响,我们在5.1节中进行了消融实验,实验表明大部分的改善实际上来自于两个预训练任务(遮蔽语言模型和下一句预测任务)和它们所带来的双向性。
A.5 Illustrations of Fine-tuning on Different Tasks
B Detailed Experimental Setup
B.1 Detailed Descriptions for the GLUE Benchmark Experiments.
MNLI: 多类型的自然语言推理(Multi-Genre Natural Language Inference)
QQP: Quora问题对(Quora Question Pairs)是一个二元分类任务,目的是确定两个问题在Quora上问的语义是否相等 (Chen et al., 2018)。
QNLI: 问题自然语言推理(Question Natural Language Inference)。
SST-2: 斯坦福情感语义树(Stanford Sentiment Treebank)数据集是一个二元单句分类任务。
CoLA: 语言可接受性单句二元分类任务语料库(Corpus of Linguistic Acceptability)。
STS-B: 文本语义相似度基准(Semantic Textual Similarity Bench-mark )是从新闻标题中和其它来源里提取的句子对的集合(Cer et al., 2017)。
MRPC: 微软研究释义语料库(Microsoft Research Paraphrase Corpus)从在线新闻中自动提取的句子对组成,并用人工注解来说明这两个句子在语义上是否相等(Dolan and Brockett, 2005.)。
RTE: 识别文本蕴含(Recognizing Textual Entailment)是一个与 MNLI 相似的二元蕴含任务。
WNLI: 威诺格拉德自然语言推理(Winograd NLI)是一个来自(Levesque et al., 2011) )的小型自然语言推理数据集。
C Additional Ablation Studies
C.1 Effect of Number of Training Steps
- BERT真的需要这么多的预训练 (128,000 words/batch * 1,000,000 steps) 来实现高的微调精度。 B E R T B A S E BERT_{BASE} BERTBASE在 MNLI 上进行 1M 步预训练时的准确率比 500k 步提高了近 1.0%。
- 遮蔽语言模型的收敛速度确实比 LTR(left to right) 模型稍慢。然而,在绝对准确性方面,遮蔽语言模型几乎在训练一开始就超越 LTR 模型。
C.2 Ablation for Different Masking Procedures
参考网址:
https://github.com/yuanxiaosc/BERT_Paper_Chinese_Translation(bert2018.11第一版的翻译,非常好)