Apache Ranger对HDFS、HBase、Hive、Yarn授权
概述与安装
1. 简介
Apache Ranger是集中式的权限管理框架,可以对HDFS、HBase、Hive、Yarn等组件提供细粒度的权限访问控制,并且提供WebUI和RestAPI方便进行操作。
2. 功能
A、集中认证(Authentication)、授权(Authorization)、审计(Audit)、加密(Encryption)、安全(Security)于一体,标准化各种Hadoop组件授权方法。
B、细粒度权限访问控制,如对HBase、Hive访问控制可具体到列。
C、支持众多组件:HDFS、Hive、HBase、Yarn、Sqoop、Storm、Solr、Knox、Kafka、Solr、Nifi、Elasticsearch、Kylin等。
D、支持基于浏览器WebUI和RestAPI管理/创建策略、管理权限。
E、集中审计日志。
F、支持基于资源(Resource Based Policies)和标签(Tag Based Policies)的权限控制。
3. 主要组件
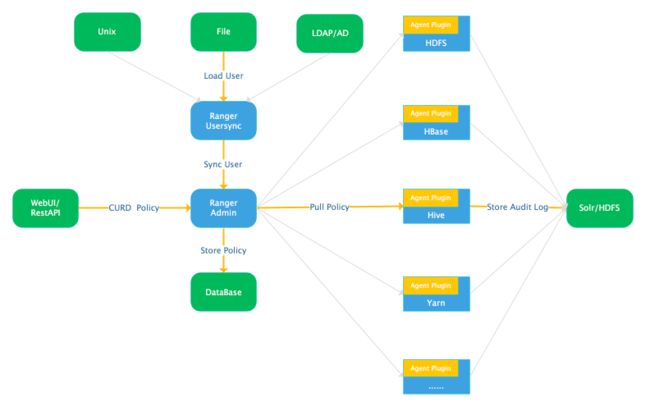
Ranger Admin: 增删改查策略,并提供WebUI和RestAPI接口。
Ranger Usersync: 定期从LDAP/Unix/File中加载用户,并同步给Ranger Admin。
Agent Plugin: 以插件的形式集成到各系统中,定期从Ranger Admin拉取策略,并根据访问执行策略,且定期将审计日志记录到Solr和HDFS。
除以上主要组件,还包括以下组件:
Ranger Tagsyncs: 定期从标签源(通常是Atlas),同步标签信息。
Ranger KMS: 即Ranger Key Management Service,是基于Hadoop KMS 封装的秘钥管理服务,支持HDFS静态数据加密。
4、通过Ambari安装Ranger
Ambari WebUI=>Add Service=>Ranger
注意:
-
必须有MySQL/Oracle/Postgres/MSSQL/SQL Anywhere Server数据库实例。
-
Ranger Admin服务器上,必须安装DB Client以供Ranger访问数据库。
-
数据库实例赋予了Ranger DB Admin用户对Ranger DB的访问权限。
-
Ambari Server服务器上执行以下命令加载jdbc驱动:
ambari-server setup --jdbc-db={database-type} --jdbc-driver={/jdbc/driver/path},如:
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
5、基本WebUI

Access Manager
-
Resource Based Policies:基于资源的策略。
-
Tag Based Policies:基于标签的策略,一般和Atlas连用,用基于标记的策略可以控制跨多个Hadoop组件的资源访问,而无需在每个组件中创建单独的服务和策略。
-
Reports:查看策略并导出报告。
Audit
检索审计日志。
Settings
-
Users/Groups:增删改查用户/用户组。
-
Permissions:根据用户/用户组查询权限。
HDFS授权
Enable HDFS Plugin
Ambari WebUI=>Ranger=>Ranger Plugin=>HDFS Ranger Plugin=>ON=>重启HDFS
配置策略
如下图所示,点击默认创建的 HDFS service,进入 policy 配置管理页,即可配置相关权限。

举例,如给ranger_acl_test用户授予hdfs目录/data/data_warehouse/test写权限。

注意:可通过Ranger WebUI=> Settings=>Users/Groups 添加新用户。
当用户ranger_acl_test对改目录没有写权限时,则报以下异常:
![]()
HBase授权
Enable HBase Plugin
Ambari WebUI=>Ranger=>Ranger Plugin=>Hbase Ranger Plugin=>ON=>重启HBase集群
注意:Ranger授权HBase是通过HBase协处理器实现,具体实现类:RangerAuthorizationCoprocessor。
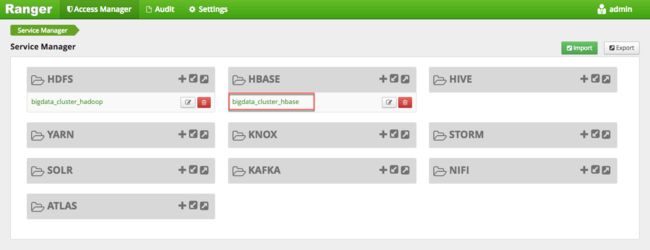
配置策略
如下图所示,点击默认创建的 HBase service,进入 policy 配置管理页,即可配置相关权限。
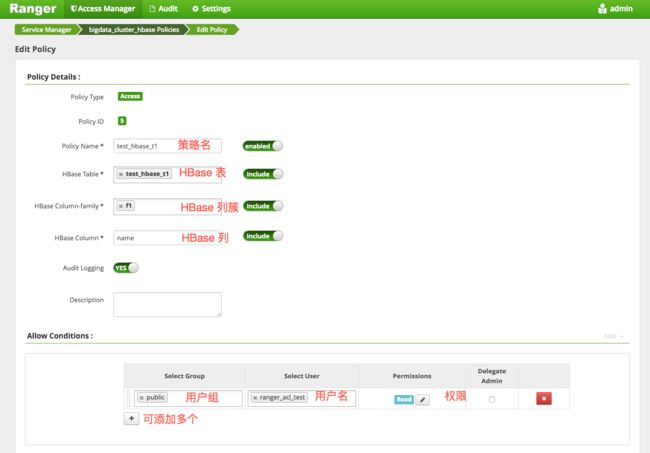
举例,如给ranger_acl_test用户授予HBase表test_hbase_t1的f1:name列读权限。
可看到,HBase 表test_hbase_t1虽然有两列f1:age,f1:name,但给ranger_acl_test用户授权后,只Scan出了f1:name列。

Hive授权
访问Hive的三种方式
Hive内置两种授权方式:基于存储的授权(Storage Based Authorization)、基于SQL标准的授权(SQL Standards Based Authorization)。
HiveServer2方式
-
场景:用户使用beeline客户端或JDBC代码通过HiveServer2访问Hive。
-
权限控制:Hive内置基于SQL标准的授权就是针对HiveServer2使用场景进行权限控制的。Ranger中对Hive的表/列级别的权限控制也是针对HiveServer2的使用场景,如果用户还需要通过Hive Cli或HDFS访问Hive数据,则还需要以下进一步控制权限。
Hive Cli方式
-
场景:用户通过Hive Cli访问Hive数据。
-
权限控制:Hive内置基于存储的授权就是针对Hive Cli使用场景进行权限控制的,底层实际上还是基于HDFS路径进行控制。该场景,在Ranger中对Hive表的HDFS路径进行权限控制即可。
HDFS方式
-
场景:用户直接通过HDFS访问Hive数据
-
权限控制:该场景,在Ranger中对Hive表的HDFS路径进行权限控制即可。
总之,在实际中根据场景,用相应的方式控制权限。
Enable Hive Plugin
Ambari WebUI=>Ranger=>Ranger Plugin=>Hive Ranger Plugin=>ON=>重启Hive
为HiveServer2场景配置策略
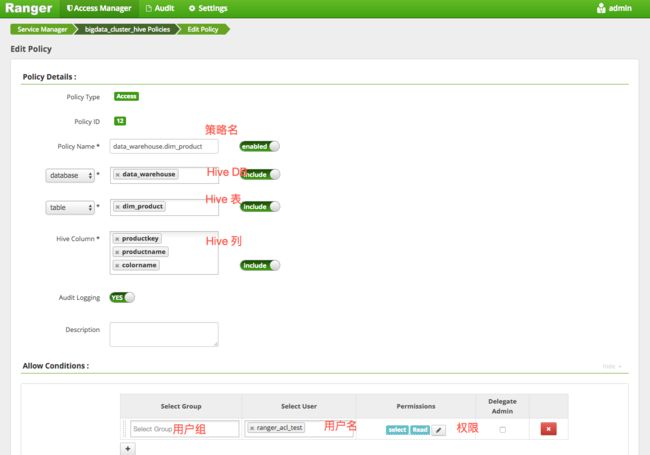
如下图所示,点击默认创建的 Hive service,进入 policy 配置管理页,即可配置相关权限。

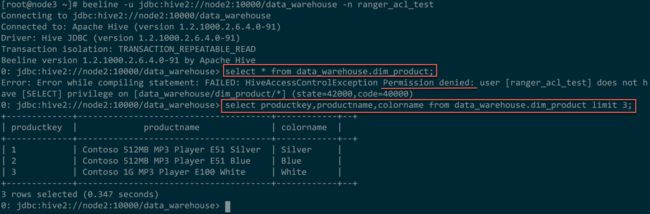
举例,如给ranger_acl_test用户授予Hive表data_warehouse.dim_product的productkey,productname,colorname列读权限。
如下,可看到,ranger_acl_test用户只能查询有权限的列。
Yarn授权
Enable Yarn Plugin
Ambari WebUI=>Ranger=>Ranger Plugin=>YARN Ranger Plugin=>ON=>重启Yarn
配置策略
如下图所示,点击默认创建的 Yarn service,进入 policy 配置管理页,即可配置相关权限。
举例,如给ranger_acl_test用户授予Yarn队列root.offline提交任务的权限。
首先,默认情况下,用户ranger_acl_test没有向offline队列提交任务的权限。如下:
[ranger_acl_test@node1 ~]$ hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar pi -Dmapred.job.queue.name=offline 10 100

配置策略如下:

这样,就可以向该队列提交任务了。