day02学习大纲
一. 格式化输出:
%s 占位字符串
%d 占位数字
"xxx%sx %sxx" % (变量, 变量)
二. 运算符:
a+=b a = a + b
and 并且. 左右两端同时为真. 结果才能是真
or 或者. 左右两端有一个是真. 结果就是真
not 非真既假, 非假既真
顺序: () => not => and => or
a or b:
如果a是0, 结果是b, 否则结果是a
a and b : 和or相反
三. 编码
ascii : 8bit 1byte, 英文字母+ 数字 + 特殊符号
gbk: 16bit 2byte, 主要是中文
unicode: 32bit 4byte
utf-8:
英文:8bit 1byte
欧洲:16bit 2byte
中文:24bit 3byte
encode() 编码成bytes字节
decode() 解码
四. 基本数据类型int和bool
int bit_length()
bool:
数据类型的转换
True: 1
False: 0
0: False
非0: True
结论: 如果想把x转化成y. y(x)
结论: 所有的空都认为是False
五. 基本数据类型str
索引和切片: 索引的下标从0开始
切片: [p:q:r] 从p到q每隔r出来1个
r如果是负数, 从右往左
常用的操作:
1. upper() 转化成大写.
2. split() 字符串切割. 切割的结果是列表
3. replace() 字符串替换
4. stript() 去掉左右两端的空白(空格, \t, \n)
5. isdigit() 判断是否是数字组成
6. startswith() 是否以xxx开头
7. find() 查找. 如果找不到返回-1
内置函数:
len()求字符串长度.
for循环
for 变量 in 可迭代对象:
循环体
in 和 not in
六 列表和元组
[元素, 元素]
列表有索引和切片
增删改查:
增加: append() insert()
删除: remove(元素) pop(索引)
修改: lst[index] = 新元素
查询: lst[index]
for item in lst:
循环体
深浅拷贝:
1. 赋值. 没有创建新列表
2. 浅拷贝. 只拷贝表面(第一层)
3. 深拷贝. 全部都拷贝一份
元组: 不可变, 主要用来存储数据
range(),可以让for循环数数(重点中的重点)
七. 字典
由{}表示. 以k:v形式保存数据
k必须可哈希. 不可变
增删改查:
1. 新增: dic['新key'] = 新value, setdefault(key, value)
2. 删除: pop(), del, cleart()
3. 修改: dic[key] = value
4. 查询: get(), dic[key], keys(), values(), items()
循环(必须要掌握):
1. for k in dic:
k
dic[k]
2. for k, v in dic.items():
k
v
八: set集合
特点: 无序, 不重复, 元素必须可哈希
add() 添加
九: is和==
is判断内存地址
==判断数据
十: 列表和字典的循环
在循环列表和字典的时候. 不能删除原来列表和字典中的内容
把要删除的内容记录在新列表中. 循环这个新列表. 删除老列表
下周要预习:
1. 文件操作
2. 函数
一、格式化输出
%s是占位字符数,实际可以占位任何东西,%s用的比较多.
%d要占位整数,只能占位数字,这时对应的数据必须是int类型. 否则程序会报错.一般用的不多.
例:现在有以下需求,让⽤用户输入name, age, job,hobby 然后输出如下所⽰示:
例2:制作标准化的名片,分别输入name,job,address,phone.自动生成名片.

代码如下:
name = input("请输入你的名字:")
job = input("请输入你的工作:")
address = input("请输入你的地址:")
phone = input("请输入你的电话:")
print('''
===============%s==================
==Name: %s=========================
==Job: %s==========================
==Address: %s====
==Phone: %s==========================
========================================
''' % (name, name, job, address, phone))
如果Python3.6以上,可以使用模板字符串模板字符串f”{}”,例如:
name = "wusir"
hobby = "playing basketball"
print("%s love %s." %(name,hobby))
print(f"{name} love {hobby}")
当出现2%或3%等%号时,使用2%%表示:例如:
hobby = "playing basketball"
print("80%% of children love %s" %hobby)
二、基本运算符
计算机可以进⾏行行的运算有很多种,可不不只加减乘除这么简单,运算按种类可分为:算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算.
1、算数运算(a=10,b=20)
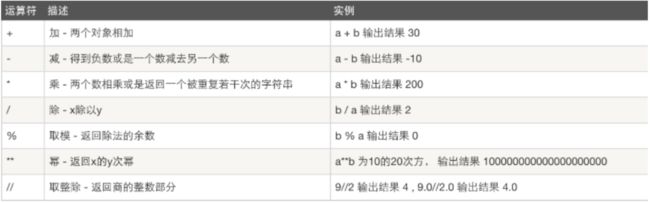
2、比较运算
==和is的区别
== 比较的是数据,这两个人长得是不是一样的
Is 比较的是内存地址,这两个人是不是同一个人
例如:下列程序,第一个是True,第二个是False。
lst=[1,2,3]
lst2=[1,2,3]
print(lst==lst2)
print(lst is lst2)
3.赋值运算
[右边是变量] = 把右边的值赋值给左边的变量,其优先级是最低的.右边的东西必须向执行.
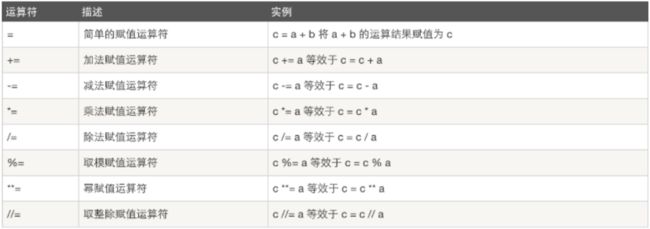
4.算逻辑运
(1)and 并且,只要有一个不成立,就是False,左右两端同时为真,然后最终是真.比如:print(1>5 and 6>4)返回时false.
(2)or 或者,左右两端有一个是真就是真.全部是假,结果才是假.
(3)not 不,非真既假,非假既真.
(4)如果出现混合逻辑运算,先算括号(),再算not,然后是and,最后是or.
例如:
![]() 返回:False
返回:False
![]() 返回True
返回True

(5)在计算机中:非1就是True,0就是False.如果a or b,if a==False 则结果是b,否则是a.
a or b:
如果a=0 结果是b
如果a=非0,结果是a
a and b:
与a or b 相反.
例题:
print(3>4 or 4<3 and 1==1)#False
print(1 < 2 and 3 < 4 or 1>2)#True
print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1)#True
print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)#False
print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)#False
print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)#False
print(8 or 4)#8
print(0 and 3)#0
print(0 or 4 and 3 or 7 or 9 and 6)#3
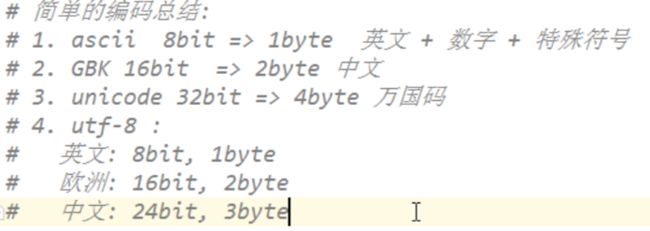
三、编码的问题
ascii : 8bit 1byte, 英文字母+ 数字 + 特殊符号
gbk: 16bit 2byte, 主要是中文
unicode: 32bit 4byte
utf-8:
英文:8bit 1byte
欧洲:16bit 2byte
中文:24bit 3byte
encode() 编码成bytes字节
decode() 解码
(1)美国人发行的计算机使用的编码是ASCII.里面编码的内容都是美国人编码的方式,所以ASCII码中就是英文字母+数字+键盘上的特殊符号+操作符的编码.
(2)编码就是用特定的排列组合来表示我们的文字信息.计算机底层只认识0和1.
(3)在A由于SCII码中使用8位01组合来表示的一个ASCII码的字符.最开始只有7位,但是计算机对7不敏感,整整128个,所以为了拓展,增加了一位,变成了8byte=8bit.ASCII是只有7位是有效的,最前面的那位是空着的,0111 1111
(4)ASCII码没有中文标准,提出一个标准ANSI,在ASCII中扩展1倍.可以兼容ASCII码.即0000 0000 0111 1111
(5)给各个国家进行编码.就产生了,中国GB2312.由于GB2312逐渐扩展,产生了国标扩展码:GBK.中国的计算机上就是GBK.台湾用的大五码big5
(6)GBK共65000多个,包含了中文\中国邻国的文字\韩文\日文\繁体字.如果不能显示,就会显示????
(7)如果中国人使用德国的文字,中国的文字看不到欧洲的文字.就产生了国与国的交流码.产生了Unicode(万国码),需要扩容到了32bit.us2和us4(32bit)即:print(2**32)共42亿文字.
(8)早起的Unicode无法使用,因为(1)太大了.比ASCII码增加了8倍,即1M的英文就产生了4M的空间.(2)网络传输:传输慢,费用高.
(9)随着机能的提高和utf-8的产生,Unicode可以使用了.把Unicode重新定.义,可变长度的Unicode=>tuf-8和utf-16.
Utf-8:最小字节单位是8bit
Utf-16:最小字节单位是16bit
(9)我们用的最多的是utf-8,是从Unicode来的.
1)英文:8位,ASCII码的东西还是ASCII码.
2)欧洲的文字占16位;
3)中文占24位,因为中文有9万多个,如果出现乱码用utf-8后GBK处理.
(10)Python2默认是ASCII,Python3内存使用的Unicode,文件存储使用的utf-8. 内存使用Unicode是可以的,因为内存是实时回收的.内存是可以浪费的.而硬盘是不能超标的.
(11)想要存储,必须进行转换成utf-8或GBK

一个字是3个字节,古力娜扎四个中文就是12个字节.
12.字节的作用就是存储和传输.
13.GBK的编码 一个中文2个字节,古力娜扎一共8个字节.
14.编码encode(得到的是byte类型)\解码 decode(得到的是字符串)
用什么编码,用什么解码.
即:bs.encode(“utf-8”) 解码也必须用utf-8 即 bs.decode(“utf-8”).同理GBK.
15.字符串
0,1=>1bit
8bit =>1byte
1024byte=>1kb
1024kb=>1mb
1024mb=>1gb
四、 基本数据类型int和bool
int bit_length()
bool:
数据类型的转换
True: 1
False: 0
0: False
非0: True
结论: 如果想把x转化成y. y(x)
结论: 所有的空都认为是False
1.基本数据类型:int类型的数据,基本运算.只有一个应用,bit_length()二进制长度.

0=>False
非0=> True 与正负号无关
2.While 1 和while True的区别,while 1会效率高一点.
3.你想把x转换成y,需要y(x)
例如:print(bool(“”))#能够表示False的字符串是假.
4.所有表示空的东西都是假.
比如:print(bool([0]))#列表有东西就是真. print(bool([]))#列表没有东西,就是假. print(bool(none))#none:空,真空,是假.其作用最主要的就是占位.
五、 基本数据类型str
索引和切片: 索引的下标从0开始
切片: [p:q:r] 从p到q每隔r出来1个
r如果是负数, 从右往左
常用的操作:
1. upper() 转化成大写.
2. split() 字符串切割. 切割的结果是列表
3. replace() 字符串替换
4. stript() 去掉左右两端的空白(空格, \t, \n)
5. isdigit() 判断是否是数字组成
6. startswith() 是否以xxx开头
7. find() 查找. 如果找不到返回-1
内置函数:
len()求字符串长度.
for循环
for 变量 in 可迭代对象:
循环体
in 和 not in
一、字符串str:由单引号\双引号\三引号\三双引号括号引起来的内容.即:引号引起来的都是字符串.
单引号中不能有单引号
双引号中可以有单引号.
单引号和双引号都是单行的.如果回车就会出现\ 表示下面内容和本行是同一行代码
三引号表示的是一段字符串,可以多行.
二、字符串的索引和切片
1、索引就是第几个字符,索引从0开始.
正序:012
倒叙:-3,-2.-1
[]表示索引.
-1表示倒数第一个
s = "jay"
print(s[1])#a
print(s[2])#y
print(s[-1])#y
print(s[-3])#j
2、切片:拿到字符串的一部分
1)顾头不顾尾,比如[4:8]取的是4,5,6,7不能取8.
2)默认顺序:从左到右.比如[8:4],不能切出来.从8往后找不到4.
3)还可以负数切,比如[-6:-2],
4)[6:]#表示,从-6开始切到最后.
5)[:6]#表示从头开始切,切到6位
6)[:]#从头切到尾.
s = "jay is a asshole!!!!"
print(s[4:8])#is a
print(s[8:4])#none
print(s[-6:-2])#le!!
print(s[6:])# a asshole!!!!
print(s[:6])#jay is
print(s[:])#jay is a asshole!!!!
print(s[2:8:3])#ys
3、带有步长的切片
#每2个出来一个
#步长可以为负数,表示从右到左.
#[::-1]#相当于从右到左一个一个数,整个句子放过来.
s = "jay is a asshole!!!!"
print(s[3:8:2])#从3到8,每2个出来1个
print(s[::2])
print(s[-1:-6:-2])
三、字符串大小转换
1.首字母大写capitallize:字符串是不可变的数据类型.比如下面这个程序不能首字母大写.每次操作都会返回新字符串.
S还是原来的字符串alex
只能把改变的s赋值给S1,才能显示Alex.
s = "jay is a asshole!!!!"
s1=s.capitalize()
print(s)#jay is a asshole!!!!
print(s1)#Jay is a asshole!!!!
2.所有字母大写:upper;全部转成成小写:lower,对一些欧洲文字不敏感.
s = "Jay Is a Asshole!!!!"
s1=s.upper()
s2=s.lower()
print(s)#Jay Is a Asshole!!!!
print(s1)#JAY IS A ASSHOLE!!!!
print(s2)#jay is a asshole!!!!
例如:让用户输入的字母,需要忽略大小写.
s="Q"
while True:
game = input("Please input your favorite games:"
"Or input Q to exit")
if game.upper()==s:
break
print("Your favorite game:%s" %game)
3.title()标题:每个单词的首字母大写.
s = "Jay Is a Asshole!!!!"
s1=s.title()
print(s1)#Jay Is A Asshole!!!!
4.字符串切割:split()#把字符串切成很多段,默认用空白切割.比如以a为切口,那么打印出来列表,没有a了.
如果没有切的刀,所以原有的字符串还是原有的字符串.
如果刀卡到了边缘.只要下刀了,至少会有两段,用’’空字符串表示.如果下刀的地方是边缘,一定能获得空字符串.
s = "alex_wusir_taibai"
ret = s.split("_")
print(ret)#['alex', 'wusir', 'taibai']
print(type(ret))#
5.字符串的替换:replace
s = "alex_wusir_taibai"
ret=s.replace("sir","先生")
print(ret)
6.strip() 去左右两端的空白,=>脱掉空白
\t #tab,就空格,即制表符,首行缩进2个字符.
\n #newlines 换行
s = "\talex_wusir\t_taibai\t"
ret=s.strip()
print(s)# alex_wusir _taibai 前后有空格
print(ret)#alex_wusir _taibai
应用:防止客户输入的alex+空格,无法检查出来
Strip(“a”)去掉字符串两端的a.
username = input("用户名:").strip()
password = input("输密码:").strip()
if username == "ken" and password =="123":
print("登录成功!")
else:
print("用户名或密码错误")
7.判断这句话是否是***开头,start.with() 判断是以***结尾endwith()
例如:一般应用于判断姓氏。判断开头或结尾是不是“alex”
s = "alex_wusir_taibai"
print(s.startswith("alex"))#True
print(s.endswith("alex"))#False
8.count(“a”)#计算某XX出现的次数.
9.s.find()#找到是索引
如果不存在,返回-1
如果存在,从左到右,第一个位置.
s = "alex_wusir_taibai"
print(s.count("a"))#3
print(s.find("a"))#0
print(s.find("i"))#8
10.isdigit()#判断是否为数字构成.
11.isalpha()只能判断非数字,判断是否由文字的基础组成.所以加上华辣汤后也是True.
12.isalnum判断是否由数字和字母构成,能屏蔽特殊字符.
13.isnumeric():能判断中文的数字,但不认识”两”和”俩”.
s = "asd123"
a = "壹贰三四"
print(s.isdigit())#False
print(s.isalpha())#False
print(a.isnumeric())#True
print(s.isalnum())#True
14.len()#求字符串的长度,内置函数
例如:比如打印“kenments”每个字母
s = "kenments"
i=0
while i<len(s):
print(s[i])
i+=1
15.for循环,比上面案例更简单
for 变量 in 可迭代(iterable)对象:
循环体
#可迭代:能够一个一个的拿出来,拍出来.字符串就是可迭代对象.
#把字符串的中每个一个字符赋值给变量c
s = "kenments"
for c in s:
print(c)
C就是字符变量a,l,e,x.
#但是数字不能放,比如 for i in 10:
16. in/not in #成员运算,
比如判断某某是我们班的成员.应用最多的方面就是评论区/禁言等敏感字词.
比如:s=”alex特别喜欢麻花藤”#麻花藤是敏感词.
s ="ken is a good man!"
if "ken" in s:
print("sorry,you can't write")
else:
print("OK,No problem!")
8.while…else…
For…else…
和if…else…一样的
Break不会执行else,他直接打断这个循环,不执行else,这是一个大坑.
For循环和while循环一样,也可以使用break\continue和else.
For只有迭代完成后,才执行else.
i=0
while i<100:
print(i)
if i == 66:
break
i+=1
else:
print("It's Done")
六、列表和元组
(一)列表:能装对象的对象:一个能装东西的对象,比如把东西装包里.
列表是一个可迭代对象,可循环
存在的意义:存储大量的数据.
(1)如果字符串的话,需要切片,比较麻烦.
(2)列表使用[]括起来,内部元素用,逗号隔开.
List=[“张三丰”,”张无忌”,”张无忌”]
(3)列表和字符串也有索引和切片
Print(list[1])#索引张无忌
Print(list[1::2])#切片
list = ["Ken","Lucy","Tom","John"]
print(list[1])#索引 Lucy
print(list[::2])#切片#['Ken', 'Tom']
print(list[-1::-2])#从右每2个切#['John', 'Lucy']
(4)列表的增删改查
#增加
1)append:追加,向列表的最后放数据.
空列表的创建:list[]或list()
append只能参加一个
list = []
list.append("lucy")
list.append("ken")
print(list)#['lucy', 'ken']
2)insert()#插入\加塞
下面存在问题,后排的位置都后移,效率较低.
list = ["Ken","Lucy","Tom","John"]
list.insert(2,"Lily")
print(list)
3)迭代添加:extend()
一个一个的叠加.
主要应用在两个列表中,进行融合.
list = ["Ken","Lucy","Tom","John"]
list.extend("兽兽")
list.extend("Lily")
print(list)#['Ken', 'Lucy', 'Tom', 'John', '兽', '兽', 'L', 'i', 'l', 'y']
两个列表融合
list = ["Ken","Lucy","Tom","John"]
list1 = ["大米","玉米","石头"]
list.extend(list1)
print(list)#['Ken', 'Lucy', 'Tom', 'John', '大米', '玉米', '石头']
#删除
1) pop(1)#制定位置删除
2) remove(“麻花藤”)#删除,制定某个元素删除.
3) Del list(3)#删除第三个
4) List.clear#清空.
list = ["Ken","Lucy","Tom","John"]
list.pop(2)
print(list)#['Ken', 'Lucy', 'John']
list.remove("John")
print(list)#['Ken', 'Lucy']
del list[1]
print(list)#['Ken', 'Tom', 'John']
list.clear()
print(list)#[]
#修改
list[1]=”东北一家人”#制定某位置的元素,修改成XXX
最常用的索引修改.
list = ["Ken","Lucy","Tom","John"]
list[1]="大米"
print(list)#['Ken', '大米', 'Tom', 'John']
#查询+成员判断
list = ["Ken","Lucy","Tom","John"]
list[1]="大米"
print(list)#['Ken', '大米', 'Tom', 'John']
print(list[2])#Tom
for item in list:
print(item)#打印每个元素
print("大米" in list)#True#成员判断
#list.sort() 排序,升序
#list.reverse() 降序
list = ["Ken","Lucy","Tom","John"]
list1 = [1,6,5,4,36]
list.sort#['John', 'Ken', 'Lucy', 'Tom']
list.reverse()
print(list)#['Tom', 'Lucy', 'Ken', 'John']
list1.sort()
print(list1)#[1, 4, 5, ()
print(list)6, 36]
list1.reverse()
print(list1)#[36, 6, 5, 4, 1]
#深浅拷贝
1)Python中的赋值
Python内部的运行过程,比如a=10,在内存先给10,然后想办法给a,a通过内存地址1A2B,找到10.

如果变量a赋值20,那么20的内存地址eee,则a通过内存eee,找到20.
如果b=a,彼此a放的是eee,所以变量赋值b为内存地址eee.所以a和b是同一个数据.
赋值操作没有拷贝,是同一个地址.
a = [1,6,5,4] b =a b.append(888) print(a)#[1, 6, 5, 4, 888] print(b)#[1, 6, 5, 4, 888]
赋值操作没有创建新列表.
如果b=a[:]#此时对a进行了复制.此时创建了新的列表.
a = [1,6,5,4] b =a[:] b.append(888) print(a)#[1, 6, 5, 4] print(b)#[1, 6, 5, 4, 888]
2)浅拷贝:先按照样子复制一个新内存地址.内存地址不一样.给a添加444,b不变.
浅拷贝的问题就是只抄个地址.其有附件就有问题.
3)这就是深拷贝,其问题的情况需要复制一份自地址.
一般情况使用浅拷贝,省内存.如果涉及到两个操作,都有可能操作你的列表,那此时需要深拷贝.
a = [1,2,3,4,[5,6,7],[7,9,8],"附件1"]
b = a.copy()
c = a.deepcopy()
b.append("444")
print(a)#[1, 2, 3, 4, [5, 6, 7], [7, 9, 8], '附件1']
print(b)#[1, 2, 3, 4, [5, 6, 7], [7, 9, 8], '附件1', '444']#b不能copy附件1
print(c)#[1, 2, 3, 4, [5, 6, 7], [7, 9, 8], '附件1', '444']#c不能copy附件1
(二)元组
元组是不可变的列表:只能看,不能干
元组用小括号()表示,并且空元祖用tuple(),如果元组中只有一个元素,必须在后面加逗号.
但如果只有一个元素,比如tu=(1)或tu=(“sjdkf”),那么统type的格式int和str.因此元组后面必须加逗号,如:tu=(“sd”,)
元组是可迭代的
ken=("金庸","古龙","黄奕","孙晓") john=("金庸") lily=("金融",) print(type(ken),type(john),type(lily))#for item in ken: print(item)#元组是可迭代的
七.字典
1.字典的存在意义:就是快,根据hash值(散乱的)存储的,字典中所有的key必须是可哈希的.
2.字典用{}表示,以key:value的形式保存数据.
3.{}大括号是字典,[]中括号是列表,()小括号是元组.
比如:
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" }
4.不可变就是hash值.
###查询
要想查询,必须知道key
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } print(dictionary["北京"])#弊端就是:如果没有这个可以,就会报错. print(dictionary["台湾"])
print(dictionary["广州"])#报错
print(dictionary.get("广州","没有这个人" ))#没有这个人
###添加
方法1:直接添加
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } dictionary["重庆"]="辣椒之都" print(dictionary)
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } dictionary["重庆"]="辣椒之都"#不存在就添加 print(dictionary)#{'北京': '政治中心', '上海': '金融中心', '深圳': '改革中心', '台湾': '收复重心', '重庆': '辣椒之都'} dictionary["北京"]="外交中心"#存在就修改 print(dictionary)#{'北京': '外交中心', '上海': '金融中心', '深圳': '改革中心', '台湾': '收复重心', '重庆': '辣椒之都'}
方法2:dictionary.setdefault["西安","古都之城"]
#如果只有一个参数,value放空.如果有两个参数,就可以新增.
Setdifault执行流程:
1.首先判断你的key有没有出现,如果出现了,就不执行任何操作,如果没有出现,就执行新增.
2.不论前面是否执行新增,最后都会把对应的key的value查询出来.
不管key:value存在不存在,都查出一个结果.
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } dictionary.setdefault("西安","古都之城") print(dictionary)#{'北京': '政治中心', '上海': '金融中心', '深圳': '改革中心', '台湾': '收复重心', '西安': '古都之城'} dictionary.setdefault("西安") print(dictionary)#{'北京': '政治中心', '上海': '金融中心', '深圳': '改革中心', '台湾': '收复重心', '西安': None}
应用场景:对列表
[11,12,33,44,55,66,77,88,99],在key1放小于66,key2放大于60.
第一种方式:比较麻烦
lst= [11,22,33,44,55,66,77,88,99,100] ret ={} for item in lst: if item < 66: if not ret.get("key01"): ret["ken01"]=[item] else: ret["ken01"].append(item) else: if not ret.get("key02"): ret["key02"]=[item] else: ret["key02"].append(item) print(ret)
第二种方法:
lst= [11,22,33,44,55,66,77,88,99,100] ret={} for item in lst: if item < 60: ret.setdefault("key01",[]).append(item) else: ret.setdefault("key02",[]).append(item) print(ret)
###删除
dic.pop(“alex”)#根据key去删除
dic.clear()#清空
del dic[“wusir”]#根据key删除.
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } dictionary.pop("北京") print(dictionary)#{'上海': '金融中心', '深圳': '改革中心', '台湾': '收复重心'} del dictionary["上海"] print(dictionary)#{'深圳': '改革中心', '台湾': '收复重心'} dictionary.clear() print(dictionary)#{}
### 查询
Keys() #找到keys
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } print(dictionary.keys())#dict_keys(['北京', '上海', '深圳', '台湾']) print(dictionary.values())#dict_values(['政治中心', '金融中心', '改革中心', '收复重心']) print(dictionary.items())#dict_items([('北京', '政治中心'), ('上海', '金融中心'), ('深圳', '改革中心'), ('台湾', '收复重心')])
dic.value() #获取的所有value
字典只能通过key去找value,不能用value找key.
dic.item()#获取的是元组
通过元组拿到了key和value
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } print(dictionary.items()) for i in dictionary.items(): print(i) k = i[0] v = i[1] print(k,v)
解构和解包(数据和变量要一一对应)
a,b=1,2#1,2是元组,把元组中每一项赋值给前面的变量,叫解包.同a,b=(1,2),但a,b=(1,2,3,),不能解包.
dictionary={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } #方法一 for item in dictionary.items(): k,v = item print(k,v) #方法二: for k,v in dictionary.items(): print(k,v)
(4)字典的嵌套
字典不能当key,因为字典是可变的
当字典嵌套很多层,需要换行
wf = { "name":"wangfeng", "age":42, "wife":{ "name":"guojizhang", "age":41, "hobby":["拍戏","当导师"], "assit":{ "name":"zhulizhang", "age":28 } }, "children":[ {"name":"xiao1hao","age":18}, {"name":"xiao2hao","age":15}, {"name":"xiao3hao","age":2} ] } #查询汪峰二儿子的年龄 print(wf["children"][1]["age"])#15 #查询汪峰助理的年龄 print(wf["wife"]["assit"]["age"])#28 #该汪峰的小儿子加10岁 wf['children'][2]['age']=wf['children'][2]['age']+10 print(wf["children"][2]["age"])
八.集合set
1.set集合,无序\不重复\内部元素可hash
2.set集合用大括号表示,如果是空集合,用set().例如set{}这是字典,而set{1,2}是set集合.
3.打印出来的是无序的,每次都不一样.
4.最大的作用去重
5.添加s.add()
6.删除
s.pop()#随机删除
s.remove(“炖鸡”)#定向删除
7.集合不能修改,只能先删除再添加
8.查找
For el in s:
Print(s)
s = ["公平","正义","英雄","战役","公正","公平","战役"] a=set(s) print(a)#{'公平', '正义', '战役', '英雄', '公正'} a.add("自由") print(a)#{'战役', '正义', '公正', '英雄', '公平', '自由'} b=list(a) a.pop() print(a)#随机删除{'战役', '英雄', '公平', '正义', '自由'} a.remove("战役") print(a)#定向删除{'自由', '正义', '公正', '英雄'} print(b)#['公平', '正义', '战役', '英雄', '公正']
九.is和==
== 比较的是数据,这两个人长得是不是一样的
Is 比较的是内存地址,这两个人是不是同一个人.
a=[1,2,3] b=[1,2,3] print(a==b)#True print(a is b)#False
十.列表的循环删除
I=0,开始,jay删了,jj和jolin等前移.
如何删除
记录删除的元素:
#删除列表中所有内容 #错误展示 lst = ["Ken","Lucy","Tom","John","Lily","Kate"] for item in lst: lst.remove(item) print(lst)#['Lucy', 'John', 'Kate']
#正确的方式1 lst = ["Ken","Lucy","Tom","John","Lily","Kate"] s = lst[:] for item in s: lst.remove(item) print(lst)#[]
lst = ["Ken","Lucy","Tom","John","Lily","Kate"] s=[] for item in lst: s.append(item) for item in s: lst.remove(item) print(lst)#[] print(s)#['Ken', 'Lucy', 'Tom', 'John', 'Lily', 'Kate']
十一.range,让for循环数数
打印1-99
for i in range(99): print(i) for i in range(10,20): print(i) for i in range(10,20,2): print(i)
可以拿到索引和元素
lst =["金城武","李嘉诚","鹿晗","韩丽","李易峰","李明"] for i in range(len(lst)): print(i,lst[i]) # 0 金城武 # 1 李嘉诚 # 2 鹿晗 # 3 韩丽 # 4 李易峰 # 5 李明
十二.练习题
删除姓李的
lst =["金城武","李嘉诚","鹿晗","韩丽","李易峰","李明"] new_lst=lst[:] for i in new_lst: if i.startswith("李"): lst.remove(i) print(lst)#['金城武', '鹿晗', '韩丽']
字典删除
d={ "北京":"政治中心", "上海":"金融中心", "深圳":"改革中心", "台湾":"收复重心" } n = [] for k in d: n.append(k) for k in n: d.pop(k) print(d)#{}