搞iOS的,面试官问Hash干嘛?原因远比我下面要介绍的多
一、了解hash的重要性
在 iOS开发中 随处可见 Hash 的身影,难道我们不好奇吗?
下图只是列出了部分知识点(Hash在iOS中的应用分析整理)
摘自知乎的一句话:

算法、数据结构、通信协议、文件系统、驱动等,虽然自己不写那些东西,但是了解其原理对于排错、优化自己的代码有很大帮助,就好比虽然你不设计制造汽车,但如果你了解发动机、变速器、安全气囊等几项原理,对于你驾车如何省油、延长使用寿命、保证自身安全有很大好处学而不思则罔、思而不学则殆,开发人员就是个随波而进的行业,无论何时何地,保持学习的深度和广度对于自身发展是很重要的,谁都不想60岁退休了还停留在增删查改的层面。
1.1、关联对象的实现原理:
详细的原理可以查阅其他资料,这里只介绍一下实现中使用的基本数据结构。关联对象采用的是HashMap嵌套HashMap的结构存储数据的,简单来说就是根据对象从第一个HashMap中取出存储对象所有关联对象的第二个HashMap,然后根据属性名从第二个HashMap中取出属性对应的值和策略。
设计关联对象的初衷是,通过传入 对象 + 属性名字 ,就可以找到属性值。方案设计实现好后,查找一个对象的关联对象的基本步骤:
- 1、 已知条件一:对象 ,因此引出第一个HashMap(AssociationsHashMap),用一个能唯一代表对象的值作为key,用存储对象的所有关联对象的结构(名字:值+策略)作为value
- 2、 已知条件二:属性名字 ,因此引出第二个HashMap(ObjectAssociationMap),用属性名字作为key,用属性名字对应的结构体(值+策略)作为value
参考资料:
iOS底层原理总结 - 关联对象实现原理
关联对象 AssociatedObject 完全解析
1.2、weak的实现原理:
同样详细的原理可以查阅其他资料,这里只介绍一下实现中使用的基本数据结构。weak采用的是一个全局的HashMap嵌套数组的结构存储数据的,销毁对象(weak指针指向的对象)的时候,根据对象从HashMap中找到存放所有指向该对象的weak指针的数组,然后将数组中的所有元素都置为nil。
weak的最大特点就是在对象销毁的时候,自动置nil,减少访问野指针的风险,这也是设计weak的初衷。方案设计实现好后,weak指针置nil的基本步骤:
- 1、对象dealloc的时候,从全局的HashMap中,根据一个唯一代表对象的值作为key,找到存储所有指向该对象的weak指针的数组
- 2、将数组中的所有元素都置为nil
参考资料:
iOS 底层解析weak的实现原理(包含weak对象的初始化,引用,释放的分析)
weak实现原理
1.3、KVO实现使用的基本数据结构
比较复杂,一个对象可以被n个对象观察,一对象的n个属性又可以分别被n个对象观察。
详细参考: GNUstep KVC/KVO探索(二):KVO的内部实现
1.4、iOS App签名的原理
一句话:一致性哈希算法 + 非对称加解密算法
详细参考: iOS App 签名的原理
1.5、对象的引用计数存储的位置
具体参考 :苹果iOS系统源码思考:对象的引用计数存储在哪里?--从runtime源码得到的启示
if对象支持TaggedPointer {
return直接将对象的指针值作为引用计数返回
} elseif设备是64位环境 && Objective-C2.0{
return对象isa指针的一部分空间(bits_extra_rc)
} else{
returnhash表
}
1.6、Runloop与线程的存储关系
线程和 RunLoop 之间是一一(子线程可以没有)对应的,其关系是保存在一个全局的 Dictionary 里。线程刚创建时并没有 RunLoop,如果你不主动获取,那它一直都不会有。RunLoop 的创建是发生在第一次获取时,RunLoop 的销毁是发生在线程结束时。你只能在一个线程的内部获取其 RunLoop(主线程除外)。
1.7、NSDictionary的原理:
解释完Hash表后,下面简单解释下
二、哈希表
桶排序
2.1、哈希表定义
哈希表(hash table,也叫散列表),是根据键(key)直接访问访问在内存储存位置的数据结构。
哈希表本质是一个数组,数组中的每一个元素成为一个箱子,箱子中存放的是键值对。根据下标index从数组中取value。关键是如何获取index,这就需要一个固定的函数(哈希函数),将key转换成index。不论哈希函数设计的如何完美,都可能出现不同的key经过hash处理后得到相同的hash值,这时候就需要处理哈希冲突。
2.2、哈希表优缺点
优点 :哈希表可以提供快速的操作。
缺点 :哈希表通常是基于数组的,数组创建后难于扩展。 也没有一种简便的方法可以以任何一种顺序〔例如从小到大)遍历表中的数据项。
综上,如果不需要有序遍历数据,井且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
2.3、哈希查找步骤
- 1、使用哈希函数将被查找的键映射(转换)为数组的索引,理想情况下(hash函数设计合理)不同的键映射的数组下标也不同,所有的查找时间复杂度为O(1)。但是实际情况下不是这样的,所以哈希查找的第二步就是处理哈希冲突。
- 2、处理哈希碰撞冲突。处理方法有很多,比如拉链法、线性探测法。
2.4、哈希表存储过程:
- 1、使用hash函数根据key得到哈希值h
- 2、如果箱子的个数为n,那么值应该存放在底(h%n)个箱子中。h%n的值范围为[0, n-1]。
- 3、如果该箱子非空(已经存放了一个值)即不同的key得到了相同的h产生了哈希冲突,此时需要使用拉链法或者开放定址线性探测法解决冲突。
hash("张三") = 23;
hash("李四") = 30;
hash("王五") = 23;
2.5、常用哈希函数:
哈希查找第一步就是使用哈希函数将键映射成索引。这种映射函数就是哈希函数。如果我们有一个保存0-M数组,那么我们就需要一个能够将任意键转换为该数组范围内的索引(0~M-1)的哈希函数。哈希函数需要易于计算并且能够均匀分布所有键。比如举个简单的例子,使用手机号码后三位就比前三位作为key更好,因为前三位手机号码的重复率很高。再比如使用身份证号码出生年月位数要比使用前几位数要更好。
在实际中,我们的键并不都是数字,有可能是字符串,还有可能是几个值的组合等,所以我们需要实现自己的哈希函数。
- 1、直接寻址法
- 2、数字分析法
- 3、平方取中法
- 4、折叠法
- 5、随机数法
- 6、除留余数法
要想设计一个优秀的哈希算法并不容易,根据经验,总结了需要满足的几点要求:
从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法);
对输入数据非常敏感,哪怕原始数据只修改了一个 Bit,最后得到的哈希值也大不相同;
散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
2.6、负载因子 = 总键值对数/数组的个数
负载因子是哈希表的一个重要属性,用来衡量哈希表的空/满程度,一定程度也可以提现查询的效率。负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。所以当负载因子大于某个常数(一般是0.75)时,哈希表将自动扩容。哈希表扩容时,一般会创建两倍于原来的数组长度。因此即使key的哈希值没有变化,对数组个数取余的结果会随着数组个数的扩容发生变化,因此键值对的位置都有可能发生变化,这个过程也成为重哈希(rehash)。
哈希表扩容 在数组比较多的时候,需要重新哈希并移动数据,性能影响较大。
哈希表扩容 虽然能够使负载因子降低,但并不总是能有效提高哈希表的查询性能。比如哈希函数设计的不合理,导致所有的key计算出的哈希值都相同,那么即使扩容他们的位置还是在同一条链表上,变成了线性表,性能极低,查询的时候时间复杂度就变成了O(n)。
2.7、哈希冲突的解决方法:
方法一:拉链法
简单来说就是 数组 + 链表 。将键通过hash函数映射为大小为M的数组的下标索引,数组的每一个元素指向一个链表,链表中的每一个结点存储着hash出来的索引值为结点下标的键值对。
Java 8解决哈希冲突采用的就是拉链法。在处理哈希函数设计不合理导致链表很长时(链表长度超过8切换为红黑树,小于6重新退化为链表)。将链表切换为红黑树能够保证插入和查找的效率,缺点是当哈希表比较大时,哈希表扩容会导致瞬时效率降低。
Redis解决哈希冲突采用的也是拉链法。通过增量式扩容解决了Java 8中的瞬时扩容导致的瞬时效率降低的缺点,同时拉链法的实现方式(新插入的键值对放在链表头部)带来了两个好处:
- 一、头插法可以节省插入耗时。如果插到尾部,则需要时间复杂度为O(n)的操作找到链表尾部,或者需要额外的内存地址来保存尾部链表的位置。
- 二、头插法可以节省查找耗时。对于一个数据系统来说,最新插入的数据往往可能频繁的被查询。
方法二:开放定址线性探测法
使用两个大小为N的数组(一个存放keys,另一个存放values)。使用数组中的空位解决碰撞,当碰撞发生时(即一个键的hash值对应数组的下标被两外一个键占用)直接将下标索引加一(index += 1),这样会出现三种结果:
- 1、未命中(数组下标中的值为空,没有占用)。keys[index] = key,values[index] = value。
- 2、命中(数组下标中的值不为空,占用)。keys[index] == key,values[index] == value。
- 3、命中(数组下标中的值不为空,占用)。keys[index] != key,继续index += 1,直到遇到结果1或2停止。
拉链法的优点
与开放定址线性探测法相比,拉链法有如下几个优点:
- ①、拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
- ②、由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
- ③、开放定址线性探测法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④、在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放定址线性探测法构造的散列表,删除结点不能简单地将被删结 点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放定址线性探测法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放定址线性探测法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
拉链法的缺点
指针需要额外的空间,故当结点规模较小时,开放定址线性探测法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址线性探测法中的冲突,从而提高平均查找速度。
开放定址线性探测法缺点
- 1、容易产生堆积问题;
- 2、不适于大规模的数据存储;
- 3、散列函数的设计对冲突会有很大的影响;
- 4、插入时可能会出现多次冲突的现象,删除的元素是多个冲突元素中的一个,需要对后面的元素作处理,实现较复杂;
- 5、结点规模很大时会浪费很多空间;
2.8、Hash表的平均查找长度
Hash表的平均查找长度包括查找成功时的平均查找长度和查找失败时的平均查找长度。
查找成功时的平均查找长度=表中每个元素查找成功时的比较次数之和/表中元素个数;
查找不成功时的平均查找长度相当于在表中查找元素不成功时的平均比较次数,可以理解为向表中插入某个元素,该元素在每个位置都有可能,然后计算出在每个位置能够插入时需要比较的次数,再除以表长即为查找不成功时的平均查找长度。
例子:
给定一组数据{32,14,23,01,42,20,45,27,55,24,10,53},假设散列表的长度为13(最接近n的质数),散列函数为H(k) = k。分别画出用 线性探测法 和 拉链法 解决冲突时构造的哈希表,并求出在等概率下情况,这两种方法查找成功和查找不成功的平均查找长度。
一、拉链法
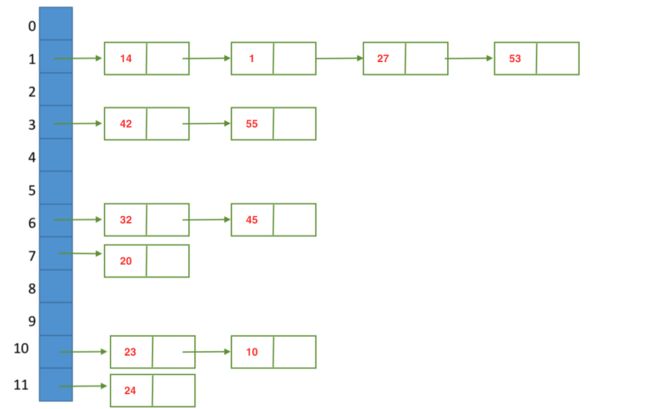
查找成功时的平均查找长度:
1ASL = (1*6+2*4+3*1+4*1)/12= 7/4
查找不成功时的平均查找长度:
1ASL = (4+2+2+1+2+1)/13
二、线性探测法
查找成功时查找次数=插入元素时的比较次数,查找成功的平均查找长度:
1ASL = (1+2+1+4+3+1+1+1+3+9+1+1+3)/12=2.5
查找不成功时的查找次数=第n个位置不成功时的比较次数为,第n个位置到第1个没有数据位置的距离:如第0个位置取值为1,第1个位置取值为2.查找不成功时的平均查找长度:
1ASL = (1+2+3+4+5+6+7+8+9+10+11+12)/ 13= 91/13
2.9、NSDictionary解释版本一:是使用NSMapTable实现的,采用拉链法解决哈希冲突
1
2
3
4
5
typedef struct {
NSMapTable *table;
NSInteger i;
struct _NSMapNode *j;
} NSMapEnumerator;
上述结构体描述了遍历一个NSMapTable时的一个指针对象,其中包含table对象自身的指针,计数值,和节点指针。
1
2
3
4
5
6
7
8
typedef struct {
NSUInteger (*hash)(NSMapTable *table,constvoid*);
BOOL (*isEqual)(NSMapTable *table,constvoid*,constvoid*);
void(*retain)(NSMapTable *table,constvoid*);
void(*release)(NSMapTable *table,void*);
NSString *(*describe)(NSMapTable *table,constvoid*);
constvoid*notAKeyMarker;
} NSMapTableKeyCallBacks;
上述结构体中存放的是几个函数指针,用于计算key的hash值,判断key是否相等,retain,release操作。
1
2
3
4
5
typedef struct {
void(*retain)(NSMapTable *table,constvoid*);
void(*release)(NSMapTable *table,void*);
NSString *(*describe)(NSMapTable *table, constvoid*);
} NSMapTableValueCallBacks;
上述存放的三个函数指针,定义在对NSMapTable插入一对key-value时,对value对象的操作。
1
2
3
4
5
6
7
@interfaceNSMapTable : NSObject {
NSMapTableKeyCallBacks *keyCallBacks;
NSMapTableValueCallBacks *valueCallBacks;
NSUInteger count;
NSUInteger nBuckets;
struct _NSMapNode **buckets;
}
从上面的结构真的能看出NSMapTable是一个 哈希表 + 链表 的数据结构吗?在NSMapTbale中插入或者删除一个对象的寻找时间 = O(1) + O(m) ,m为最坏时可能为n。
O(1) :对key进行hash得到bucket的位置
O(m) :不同的key得到相同的hash值的value存放到链表中,遍历链表的时间
上面的结论和对应的解释似乎很合理?看看下面的分析再说也不迟!
2.10、NSDictionary解释版本二:是对_CFDictionary的封装,解决哈希冲突使用的是开放定址线性探测法
1
2
3
4
5
6
7
8
9
10
11
12
struct __CFDictionary {
CFRuntimeBase _base;
CFIndex _count;
CFIndex _capacity;
CFIndex _bucketsNum;
uintptr_t _marker;
void*_context;
CFIndex _deletes;
CFOptionFlags _xflags;
constvoid**_keys;
constvoid**_values;
};
从上面的数据结构可以看出NSDictionary内部使用了两个指针数组分别保存keys和values。采用的是连续方式存储键值对。拉链法会将key和value包装成一个结果存储(链表结点),而Dictionary的结构拥有keys和values两个数组(开放寻址线性探测法解决哈希冲突的用的就是两个数组),说明两个数据是被分开存储的,不像是拉链法。
NSDictionary使用开放定址线性探测法解决哈希冲突的原理:
可以看到,NSDictionary设置的key和value,key值会根据特定的hash函数算出建立的空桶数组,keys和values同样多,然后存储数据的时候,根据hash函数算出来的值,找到对应的index下标,如果下标已有数据,开放定址法后移动插入,如果空桶数组到达数据阀值,这个时候就会把空桶数组扩容,然后重新哈希插入。
这样把一些不连续的key-value值插入到了能建立起关系的hash表中,当我们查找的时候,key根据哈希>值算出来,然后根据索引,直接index访问hash表keys和hash表values,这样查询速度就可以和连续线性存储的数据一样接近O(1)了,只是占用空间有点大,性能就很强悍。
如果删除的时候,也会根据_maker标记逻辑上的删除,除非NSDictionary(NSDictionary本体的hash值就是count)内存被移除。
NSDictionary之所以采用这种设计,
其一出于查询性能的考虑;
其二NSDictionary在使用过程中总是会很快的被释放,不会长期占用内存;
2.11、Apple方案选择:
解决哈希冲突的拉链法和开放定址线性探测法,Apple都是用了。具体使用哪一种是根据存储数据的生命周期和特性决定的。
@synchronized使用的是拉链法。拉链法多用于存储的数据是通用类型,能够被反复利用,就像@synchronized存储的是锁是一种无关业务的实现结构,程序运行时多个对象使用同一个锁的概率相当高,有效的节省了内存。
weak对象 associatedObject采用的是开放定址线性探测法。开放定址线性探测法用于存储的数据是临时的,用完尽快释放,就像associatedObject,weak。
2.12、NSDictionary的存储过程:
具体参考我写的另一篇博客:iOS笔记:进一步认识 ==、isEqual、hash
1、通过方法- (void)setObject:(id)anObject forKey:(id)aKey;可以看出key必须遵循NSCopy协议,也就是说NSDictionary的key是copy一份新的,而value是浅拷贝的(如果想深拷贝可以使用NSMapTable)。
2、不过这还不够,key还必须要继承NSObject,并且重写-(NSUInteger)hash;和-(BOOL)isEqual:(id)object;两个方法。第一个函数用于计算hash值,第二个函数用来判断当哈希值相同的时候value是否相同(解决哈希冲突)。
参考博客
浅谈算法和数据结构: 十一 哈希表
NSDictionary和NSMutableArray底层原理(哈希表和环形缓冲区)
Swift中字典的实现原理
深入理解哈希表
解读Objective-C的NSDictionary
iOS重做轮子,写一个NSDictionary(一)
iOS重做轮子,写一个NSDictionary(一)
哈希表——线性探测法、链地址法、查找成功、查找不成功的平均长度
哈希表、哈希算法、一致性哈希表
细说@synchronized和dispatch_once
链接:https://juejin.im/post/5c6abfc86fb9a049c04396a7