背景知识
在使用sql的过程中经常需要建立索引,而每种索引是怎么处罚的又是怎么起到作用的,首先必须知道索引和索引的类型。
索引类型type

我们可以清楚的看到type那一栏有index ALL eq_ref,他们都代表什么意思呢?
首先类型有许多,这里我只给大家介绍用的最多的几种类型:
system>const>eq_ref>ref>range>index>ALL
越往左边,性能越高,比如system就比ALL类型性能要高出许多,其中system、const只是理想类型,基本达不到;
我们自己实际能优化到ref>range这两个类型,就是你自己写SQL,如果你没优化基本上就是ALL,如果你优化了,那就尽量达到ref>range这两个级别;
左边基本达不到!
所以,要对type优化的前提是,你需要有索引,如果你连索引都没有创建,那你就不用优化了,肯定是ALL.....;
Type级别详解
一.system级别
索引类型能是system的只有两种情况:
1.只有一条数据的系统表
只有一条数据的系统表,就是系统里自带一张表,并且这个表就一条数据,这个基本上就达不到,这个是系统自带的表,而且就一条数据,所以基本达不到;
2.或衍生表只能有一条数据的主查询
这个是可以实现的,但是在实际开发当中,你不可能去写一个这么个玩意儿,不可能公司的业务去让你把SQL索引类型写实system...
SQL语句:select * From (select * From test01) t where tid = 1;//前面需要加explain
执行结果:
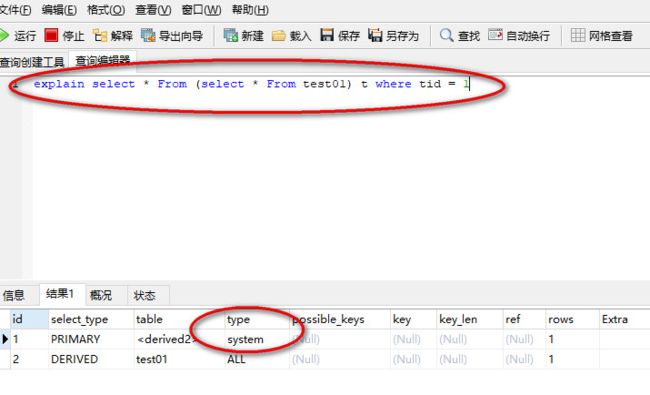
就是把它凑出来即可;
我之所以能达到system,是因为我满足了它的第二个条件;
二.const级别
const条件稍微低一点,但是基本上也达不到;
1.仅仅能查出一条的SQL语句并且用于Primary key 或 unique索引;
这个我就不说了把,都知道,所以在企业里根本不可能实现,能查出来一条SQL语句,你的索引还必须是Primary key或unique;
SQL语句:select * tid From test01 where tid = 1;//前面需要加explain
执行结果:
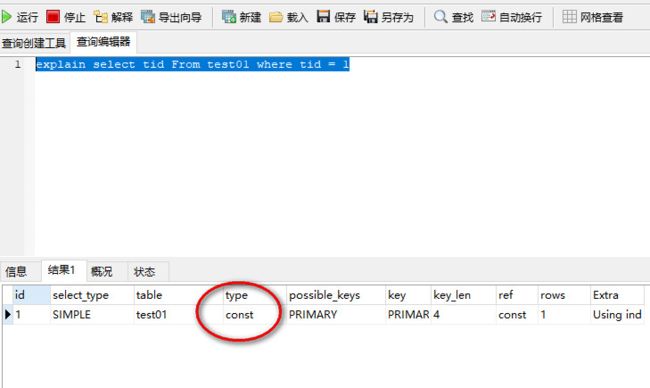
根据tid找,因为tid是我设置的主键,主键就是Primary key,并且只能有一条数据,我表里面本来就一条,所以我满足了;
三.eq_ref级别
唯一性索引:对于每个索引键的查询,返回 匹配唯一行数据(有且只有1个,不能多,不能0);
解说:比如你select ...from 一张表 where 比方说有一个字段 name = 一个东西,也就是我们以name作为索引,假设我之前给name加了一个索引值,我现在根据name去查,查完后有20条数据,我就必须保证这二十条数据每行都是唯一的,不能重复不能为空!
只要满足以上条件,你就能达到eq_ref,当然前提是你要给name建索引,如果name连索引都没,那你肯定达不到eq_ref;
此种情况常见于唯一索引和主键索引;
比如我根据name去查,但是一个公司里面或一个学校里面叫name的可能不止一个,一般你想用这个的时候,就要确保你这个字段是唯一的,id就可以,你可以重复两个张三,但是你身份证肯定不会重复;
添加唯一键语法:alter table 表名 add constraint 索引名 unique index(列名)
检查字段是否唯一键:show index form 表名;被展示出来的皆是有唯一约束的;
以上级别,均是可遇不可求!!!!
四 .ref级别
到ref还是问题不大的,只要你上点心,就可以达到;
非唯一性索引:对于每个索引键的查询,返回匹配的所有行(可以是0,或多个)
假设我现在要根据name查询,首先name可能有多个,因为一个公司或学校叫小明的不止一个人,但是你要用name去查,你必须name是索引,我们先给它加个索引,因为要达到ref级别,所以这里我给它加一个单值索引,
单值索引语法:alter table 表名 索引类型 索引名(字段)
现在我们根据索引来查数据,这里我假设我写的单值索引;
alter table student add index index_name (name);
这个时候我们再去编写sql语句:
alter table student add index index_name (name);
因为name是索引列,这里假设有两个叫张三的,ref级别规则就是能查出多个或0个,很显然能查出来多个,那这条SQL语句,必然是ref级别!
执行结果:

数据:
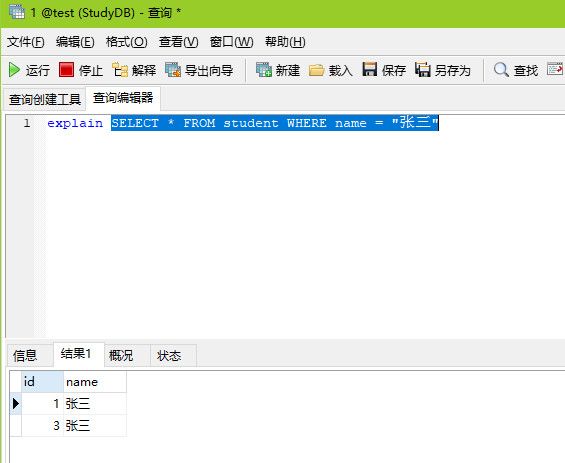
五.range级别
检索指定范围的行,查找一个范围内的数据,where后面是一个范围查询 (between,in,> < >=);
注:in 有时会失效,导致为ALL;
现在我们写一个查询语句,前提是,tid一定是一个索引列,如果是id的话,就用主键索引,也就是唯一索引,值不可以重复,这个时候我们范围查询的时候要用它来做条件:
EXPLAIN SELECT t.* FROM student t WHERE t.tid BETWEEN 1 AND 2; ;//查询tid是1到2;
查看执行结果:

六.index级别
查询全部索引中的数据
讲解:假设我有一张表,里面有id name age,这个时候name是一个单值索引,一旦name被设定成索引,它就会成为B树一样,经过各种算法将name里面的值像树一样进行分类,这个时候我where name = **,就相当于把这颗B树查了一个遍,
也就是说,你把name这一列给查了一遍;
SQL语句:select id From student;//我只查被索引声明的列,必然就是index了;
执行结果:
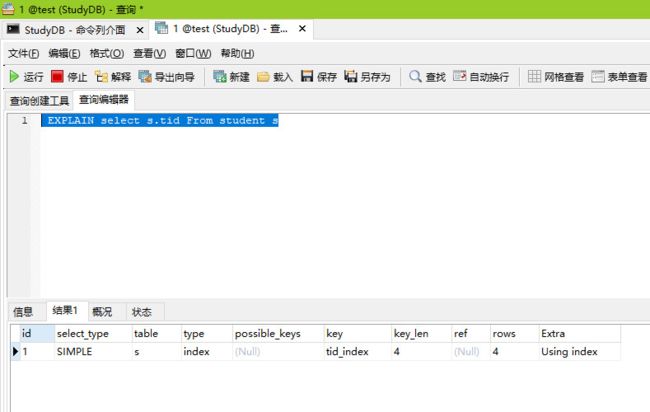
七.ALL级别
查询全部表数据,就是select name From student;
其中 name 不是索引;
如果你查的这一列不是索引,就会导致全表扫描,所以要避免全表扫描;
执行结果:

索引的分类:
主键索引(PRIMAY KEY)
唯一索引(UNIQUE)
常规索引(INDEX)
全文索引(FULLTEXT)
主键索引
主键:
某一个属性组能唯一标识一条记录
如:学生表(学号,姓名,班级,性别等等),学号时唯一标识的,可以作为主键
特点:
最常见的索引类型
确保数据记录的唯一性
确定特定数据记录在数据库中的位置
实例:
CREATE TABLE `表名`(、
`GradeID` INT(11) AUTO_INCREMENT PRIMARY KEY,
#或 PRIMARY KEY(`GradeID`)
)
唯一索引
作用:
避免同一个表中某数据列中的值重复
与主键索引的区别
主键索引只能有一个
唯一索引可有多个
实例:
CREATE TABLE `Grade`(、
`GradeID` INT(11) AUTO_INCREMENT PRIMARY KEY,
`GradeName` VARCHAR(32) NOT NULL UNIQUE
#或 UNIQUE KEY ` GradeID`(`GradeID`)
常规索引
作用:
快速定位特定数据
注意:
index 和 key 关键字都可以设置常规索引
应加在查询条件的字段
不易添加太多常规索引,影响数据的插入,删除和修改操作
实例:
##创建表时添加
CREATE TABLE `result`{
//省略一些代码
INDEX / KEY `ind` (`studentNo`,`subjectNo`)
}
##创建后追加
ALTER TABLE `result` ADD INDEX `ind` (`studentNo`,`subjectNo`);
全文索引
作用:
快速定位特定数据
注意:
只能用于MyISAM类型的数据表
只能用于CHAR ,VARCHAR,TEXT数据列类型
使用大型数据集
实例:
CREATE TABLE `student`(
#省略一些sql语句
FULLTEXT(`StudentName`)
)ENDINE=MYISAM;
ALTER TABLE employee ADD FULLTEXT(`first_name`)