一、 Python介绍
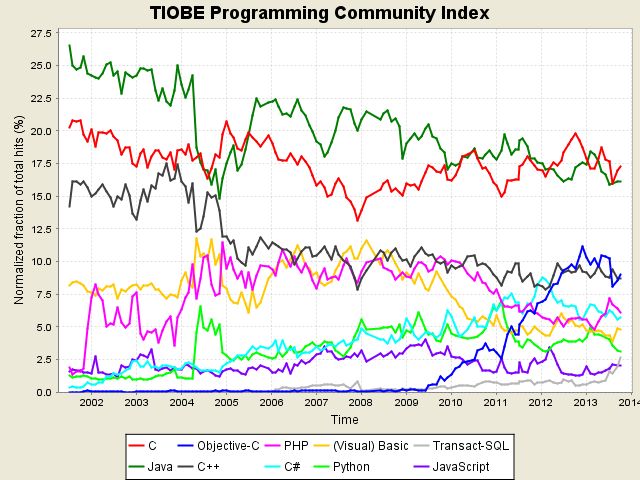
总的来说,这几种编程语言各有千秋。C语言是可以用来编写操作系统的贴近硬件的语言,所以,C语言适合开发那些追求运行速度、充分发挥硬件性能的程序。而Python是用来编写应用程序的高级编程语言。
当你用一种语言开始作真正的软件开发时,你除了编写代码外,还需要很多基本的已经写好的现成的东西,来帮助你加快开发进度。比如说,要编写一个电子邮件客户端,如果先从最底层开始编写网络协议相关的代码,那估计一年半载也开发不出来。高级编程语言通常都会提供一个比较完善的基础代码库,让你能直接调用,比如,针对电子邮件协议的SMTP库,针对桌面环境的GUI库,在这些已有的代码库的基础上开发,一个电子邮件客户端几天就能开发出来。
Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
许多大型网站就是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣。很多大公司,包括Google、Yahoo等,甚至NASA(美国航空航天局)都大量地使用Python。
龟叔给Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
总的来说,Python的哲学就是简单优雅,尽量写容易看明白的代码,尽量写少的代码。如果一个资深程序员向你炫耀他写的晦涩难懂、动不动就几万行的代码,你可以尽情地嘲笑他。
那Python适合开发哪些类型的应用呢?
首选是网络应用,包括网站、后台服务等等;
其次是许多日常需要的小工具,包括系统管理员需要的脚本任务等等;
另外就是把其他语言开发的程序再包装起来,方便使用。
最后说说Python的缺点。
任何编程语言都有缺点,Python也不例外。优点说过了,那Python有哪些缺点呢?
第一个缺点就是运行速度慢,和C程序相比非常慢,因为Python是解释型语言,你的代码在执行时会一行一行地翻译成CPU能理解的机器码,这个翻译过程非常耗时,所以很慢。而C程序是运行前直接编译成CPU能执行的机器码,所以非常快。
但是大量的应用程序不需要这么快的运行速度,因为用户根本感觉不出来。例如开发一个下载MP3的网络应用程序,C程序的运行时间需要0.001秒,而Python程序的运行时间需要0.1秒,慢了100倍,但由于网络更慢,需要等待1秒,你想,用户能感觉到1.001秒和1.1秒的区别吗?这就好比F1赛车和普通的出租车在北京三环路上行驶的道理一样,虽然F1赛车理论时速高达400公里,但由于三环路堵车的时速只有20公里,因此,作为乘客,你感觉的时速永远是20公里。

第二个缺点就是代码不能加密。如果要发布你的Python程序,实际上就是发布源代码,这一点跟C语言不同,C语言不用发布源代码,只需要把编译后的机器码(也就是你在Windows上常见的xxx.exe文件)发布出去。要从机器码反推出C代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解释型的语言,则必须把源码发布出去。
这个缺点仅限于你要编写的软件需要卖给别人挣钱的时候。好消息是目前的互联网时代,靠卖软件授权的商业模式越来越少了,靠网站和移动应用卖服务的模式越来越多了,后一种模式不需要把源码给别人。
再说了,现在如火如荼的开源运动和互联网自由开放的精神是一致的,互联网上有无数非常优秀的像Linux一样的开源代码,我们千万不要高估自己写的代码真的有非常大的“商业价值”。那些大公司的代码不愿意开放的更重要的原因是代码写得太烂了,一旦开源,就没人敢用他们的产品了。

编译和解释的区别是什么?
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
这是因为计算机不能直接认识并执行我们写的语句,它只能认识机器语言(是二进制的形式)
在这里就不对python做太多介绍了,每个语言都有优点也有缺点。
推荐2个python介绍的博客:
金角大王 徐亮
二、 Python 2 or Python 3
1.性能
Py3.0运行 pystone benchmark的速度比Py2.5慢30%。Guido认为Py3.0有极大的优化空间,在字符串和整形操作上可
以取得很好的优化结果。
Py3.1性能比Py2.5慢15%,还有很大的提升空间。
2.编码
Py3.X源码文件默认使用utf-8编码,这就使得以下代码是合法的:
>>> 中国 = 'china'
>>>print(中国)
china
3. 语法
1)去除了<>,全部改用!=
2)去除``,全部改用repr()
3)关键词加入as 和with,还有True,False,None
4)整型除法返回浮点数,要得到整型结果,请使用//
5)加入nonlocal语句。使用noclocal x可以直接指派外围(非全局)变量
6)去除print语句,加入print()函数实现相同的功能。同样的还有 exec语句,已经改为exec()函数
例如:
2.X: print "The answer is", 2*2
3.X: print("The answer is", 2*2)
2.X: print x, # 使用逗号结尾禁止换行
3.X: print(x, end=" ") # 使用空格代替换行
2.X: print # 输出新行
3.X: print() # 输出新行
2.X: print >>sys.stderr, "fatal error"
3.X: print("fatal error", file=sys.stderr)
2.X: print (x, y) # 输出repr((x, y))
3.X: print((x, y)) # 不同于print(x, y)!
7)改变了顺序操作符的行为,例如x
2.X:guess = int(raw_input('Enter an integer : ')) # 读取键盘输入的方法
3.X:guess = int(input('Enter an integer : '))
9)去除元组参数解包。不能def(a, (b, c)):pass这样定义函数了
10)新式的8进制字变量,相应地修改了oct()函数。
2.X的方式如下:
>>> 0666
438
>>> oct(438)
'0666'
3.X这样:
>>> 0666
SyntaxError: invalid token (
>>> 0o666
438
>>> oct(438)
'0o666'
11)增加了 2进制字面量和bin()函数
>>> bin(438)
'0b110110110'
>>> _438 = '0b110110110'
>>> _438
'0b110110110'
12)扩展的可迭代解包。在Py3.X 里,a, b, *rest = seq和 *rest, a = seq都是合法的,只要求两点:rest是list
对象和seq是可迭代的。
13)新的super(),可以不再给super()传参数,
>>> class C(object):
def __init__(self, a):
print('C', a)
>>> class D(C):
def __init(self, a):
super().__init__(a) # 无参数调用super()
>>> D(8)
C 8
<__main__.D object at 0x00D7ED90>
14)新的metaclass语法:
class Foo(*bases, **kwds):
pass
15)支持class decorator。用法与函数decorator一样:
>>> def foo(cls_a):
def print_func(self):
print('Hello, world!')
cls_a.print = print_func
return cls_a
>>> @foo
class C(object):
pass
>>> C().print()
Hello, world!
class decorator可以用来玩玩狸猫换太子的大把戏。更多请参阅PEP 3129
4. 字符串和字节串
1)现在字符串只有str一种类型,但它跟2.x版本的unicode几乎一样。
2)关于字节串,请参阅“数据类型”的第2条目
5.数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
>>> b = b'china'
>>> type(b)
str对象和bytes对象可以使用.encode() (str -> bytes) or .decode() (bytes -> str)方法相互转化。
>>> s = b.decode()
>>> s
'china'
>>> b1 = s.encode()
>>> b1
b'china'
3)dict的.keys()、.items 和.values()方法返回迭代器,而之前的iterkeys()等函数都被废弃。同时去掉的还有
dict.has_key(),用 in替代它吧
6.面向对象
1)引入抽象基类(Abstraact Base Classes,ABCs)。
2)容器类和迭代器类被ABCs化,所以cellections模块里的类型比Py2.5多了很多。
>>> import collections
>>> print('\n'.join(dir(collections)))
Callable
Container
Hashable
ItemsView
Iterable
Iterator
KeysView
Mapping
MappingView
MutableMapping
MutableSequence
MutableSet
NamedTuple
Sequence
Set
Sized
ValuesView
__all__
__builtins__
__doc__
__file__
__name__
_abcoll
_itemgetter
_sys
defaultdict
deque
另外,数值类型也被ABCs化。关于这两点,请参阅 PEP 3119和PEP 3141。
3)迭代器的next()方法改名为__next__(),并增加内置函数next(),用以调用迭代器的__next__()方法
4)增加了@abstractmethod和 @abstractproperty两个 decorator,编写抽象方法(属性)更加方便。
7.异常
1)所以异常都从 BaseException继承,并删除了StardardError
2)去除了异常类的序列行为和.message属性
3)用 raise Exception(args)代替 raise Exception, args语法
4)捕获异常的语法改变,引入了as关键字来标识异常实例,在Py2.5中:
>>> try:
... raise NotImplementedError('Error')
... except NotImplementedError, error:
... print error.message
...
Error
在Py3.0中:
>>> try:
raise NotImplementedError('Error')
except NotImplementedError as error: #注意这个 as
print(str(error))
Error
5)异常链,因为__context__在3.0a1版本中没有实现
8.模块变动
1)移除了cPickle模块,可以使用pickle模块代替。最终我们将会有一个透明高效的模块。
2)移除了imageop模块
3)移除了 audiodev, Bastion, bsddb185, exceptions, linuxaudiodev, md5, MimeWriter, mimify, popen2,
rexec, sets, sha, stringold, strop, sunaudiodev, timing和xmllib模块
4)移除了bsddb模块(单独发布,可以从http://www.jcea.es/programacion/pybsddb.htm获取)
5)移除了new模块
6)os.tmpnam()和os.tmpfile()函数被移动到tmpfile模块下
7)tokenize模块现在使用bytes工作。主要的入口点不再是generate_tokens,而是 tokenize.tokenize()
9.其它
1)xrange() 改名为range(),要想使用range()获得一个list,必须显式调用:
>>> list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2)bytes对象不能hash,也不支持 b.lower()、b.strip()和b.split()方法,但对于后两者可以使用 b.strip(b’
\n\t\r \f’)和b.split(b’ ‘)来达到相同目的
3)zip()、map()和filter()都返回迭代器。而apply()、 callable()、coerce()、 execfile()、reduce()和reload
()函数都被去除了
现在可以使用hasattr()来替换 callable(). hasattr()的语法如:hasattr(string, '__name__')
4)string.letters和相关的.lowercase和.uppercase被去除,请改用string.ascii_letters 等
5)如果x < y的不能比较,抛出TypeError异常。2.x版本是返回伪随机布尔值的
6)__getslice__系列成员被废弃。a[i:j]根据上下文转换为a.__getitem__(slice(I, j))或 __setitem__和
__delitem__调用
7)file类被废弃,在Py2.5中:
>>> file
在Py3.X中:
>>> file
Traceback (most recent call last):
File "
file
NameError: name 'file' is not defined
二、 Python环境的安装
windows
1、下载安装包https://www.python.org/downloads/2、安装默认安装路径:C:\python273、配置环境变量【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】如:原来的值;C:\python27,切记前面有分号
无需安装,原装Python环境ps:如果自带2.6,请更新至2.7
三、 Python的Hello world
print("Hello World!")#3.xprint "Hello World!"#2.xprint("Hello World!")#2.x
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下:
#!/usr/bin/env pythonprint ("hello,world")
如此一来,执行: ./hello.py 即可。
ps:执行前需给予 hello.py 执行权限,chmod 755 hello.py
在交互器执行
除了把程序写在文件里,还可以直接调用python自带的交互器运行代码,
localhost:~ wdh$ pythonPython2.7.10(default,Oct232015,18:05:06)[GCC 4.2.1CompatibleApple LLVM 7.0.0(clang-700.0.59.5)] on darwinType"help","copyright","credits"or"license"for more information.>>>print("Hello World!")HelloWorld!
三、 Python的变量与字符编码
#_*_coding:utf-8_*_name ="Alex Li"
述代码声明了一个变量,变量名为: name,变量name的值为:"Alex Li"
变量定义的规则:
-
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
name ="Alex Li"name2 = nameprint(name,name2)name ="Jack"print("What is the value of name2 now?")
hon解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。
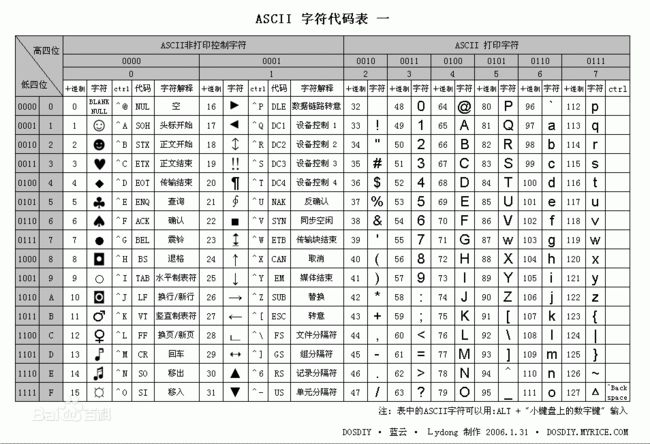
关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
#!/usr/bin/env pythonprint"你好,世界"
#!/usr/bin/env python# -*- coding: utf-8 -*-print"你好,世界"
四、 Python怎么注释
当行注视:# 被注释内容
多行注释:""" 被注释内容 ""
五、 交互式输入
#!/usr/bin/env python#_*_coding:utf-8_*_#name = raw_input("What is your name?") #only on python 2.xname = input("What is your name?")print("Hello "+ name )
#!/usr/bin/env python# -*- coding: utf-8 -*-import getpass# 将用户输入的内容赋值给 name 变量pwd = getpass.getpass("请输入密码:")# 打印输入的内容print(pwd)
六、Python编辑器的选择
Python的交互式命令行写程序,好处是一下就能得到结果,坏处是没法保存,下次还想运行的时候,还得再敲一遍。
所以,实际开发的时候,我们总是使用一个文本编辑器来写代码,写完了,保存为一个文件,这样,程序就可以反复运行了。
现在,我们就把上次的'hello, world'程序用文本编辑器写出来,保存下来。
那么问题来了:文本编辑器到底哪家强?
推荐两款文本编辑器:
一个是Sublime Text,免费使用,但是不付费会弹出提示框:
一个是Notepad++,免费使用,有中文界面:

请注意,用哪个都行,但是绝对不能用Word和Windows自带的记事本。Word保存的不是纯文本文件,而记事本会自作聪明地在文件开始的地方加上几个特殊字符(UTF-8 BOM),结果会导致程序运行出现莫名其妙的错误。
安装好文本编辑器后,输入以下代码:
print('hello, world')
注意print前面不要有任何空格。然后,选择一个目录,例如C:\work,把文件保存为hello.py,就可以打开命令行窗口,把当前目录切换到hello.py所在目录,就可以运行这个程序了:
C:\work>python hello.py
hello, world
也可以保存为别的名字,比如first.py,但是必须要以.py结尾,其他的都不行。此外,文件名只能是英文字母、数字和下划线的组合。
直接运行py文件
有同学问,能不能像.exe文件那样直接运行.py文件呢?在Windows上是不行的,但是,在Mac和Linux上是可以的,方法是在.py文件的第一行加上一个特殊的注释:
#!/usr/bin/env python3print('hello, world')
然后,通过命令给hello.py以执行权限:
$ chmod a+x hello.py
就可以直接运行hello.py了,比如在Mac下运行:

七、Python基础
Python是一种计算机编程语言。计算机编程语言和我们日常使用的自然语言有所不同,最大的区别就是,自然语言在不同的语境下有不同的理解,而计算机要根据编程语言执行任务,就必须保证编程语言写出的程序决不能有歧义,所以,任何一种编程语言都有自己的一套语法,编译器或者解释器就是负责把符合语法的程序代码转换成CPU能够执行的机器码,然后执行。Python也不例外。
Python的语法比较简单,采用缩进方式,写出来的代码就像下面的样子:
# print absolute value of an integer:
a = 100if a >= 0:
print(a)
else:
print(-a)
以#开头的语句是注释,注释是给人看的,可以是任意内容,解释器会忽略掉注释。其他每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。按照约定俗成的管理,应该始终坚持使用4个空格的缩进。
缩进的另一个好处是强迫你写出缩进较少的代码,你会倾向于把一段很长的代码拆分成若干函数,从而得到缩进较少的代码。
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE很难像格式化Java代码那样格式化Python代码。
最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
注意:Python使用缩进来组织代码块,请务必遵守约定俗成的习惯,坚持使用4个空格的缩进。
在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。
八、Python 数据类型和变量
数据类型
计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值。但是,计算机能处理的远不止数值,还可以处理文本、图形、音频、视频、网页等各种各样的数据,不同的数据,需要定义不同的数据类型。在Python中,能够直接处理的数据类型有以下几种:
整数
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:1,100,-8080,0,等等。
计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
浮点数
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差。
字符串
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这3个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这6个字符。
如果字符串内部既包含'又包含"怎么办?可以用转义字符\来标识,比如:
'I\'m \"OK\"!'
表示的字符串内容是:
I'm "OK"!
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\,可以在Python的交互式命令行用print()打印字符串看看:
>>> print('I\'m ok.')
I'm ok.
>>> print('I\'m learning\nPython.')
I'm learning
Python.
>>> print('\\\n\\')
\
\
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用r''表示''内部的字符串默认不转义,可以自己试试:
>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\
如果字符串内部有很多换行,用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容,可以自己试试:
>>> print('''line1
... line2
... line3''')
line1
line2
line3
上面是在交互式命令行内输入,注意在输入多行内容时,提示符由>>>变为...,提示你可以接着上一行输入。如果写成程序,就是:
print('''line1
line2
line3''')
多行字符串'''...'''还可以在前面加上r使用,请自行测试。
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来:
>>> TrueTrue>>> FalseFalse>>> 3 > 2True>>> 3 > 5False布尔值可以用and、or和not运算。
and运算是与运算,只有所有都为True,and运算结果才是True:
>>> True and TrueTrue>>> True and FalseFalse>>> False and FalseFalse>>> 5 > 3 and 3 > 1Trueor运算是或运算,只要其中有一个为True,or运算结果就是True:
>>> True or TrueTrue>>> True or FalseTrue>>> False or FalseFalse>>> 5 > 3 or 1 > 3Truenot运算是非运算,它是一个单目运算符,把True变成False,False变成True:
>>> not TrueFalse>>> not FalseTrue>>> not 1 > 2True布尔值经常用在条件判断中,比如:
if age >= 18:
print('adult')
else:
print('teenager')
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
此外,Python还提供了列表、字典等多种数据类型,还允许创建自定义数据类型,我们后面会继续讲到。
变量
变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
变量在程序中就是用一个变量名表示了,变量名必须是大小写英文、数字和_的组合,且不能用数字开头,比如:
a = 1变量a是一个整数。
t_007 = 'T007'变量t_007是一个字符串。
Answer = True变量Answer是一个布尔值True。
在Python中,等号=是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量,例如:
a = 123 # a是整数print(a)
a = 'ABC' # a变为字符串print(a)
这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言,赋值语句如下(// 表示注释):
int a = 123; // a是整数类型变量
a = "ABC"; // 错误:不能把字符串赋给整型变量和静态语言相比,动态语言更灵活,就是这个原因。
请不要把赋值语句的等号等同于数学的等号。比如下面的代码:
x = 10x = x + 2如果从数学上理解x = x + 2那无论如何是不成立的,在程序中,赋值语句先计算右侧的表达式x + 2,得到结果12,再赋给变量x。由于x之前的值是10,重新赋值后,x的值变成12。
最后,理解变量在计算机内存中的表示也非常重要。当我们写:
a = 'ABC'时,Python解释器干了两件事情:
-
在内存中创建了一个
'ABC'的字符串; -
在内存中创建了一个名为
a的变量,并把它指向'ABC'。
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如下面的代码:
a = 'ABC'
b = a
a = 'XYZ'print(b)
最后一行打印出变量b的内容到底是'ABC'呢还是'XYZ'?如果从数学意义上理解,就会错误地得出b和a相同,也应该是'XYZ',但实际上b的值是'ABC',让我们一行一行地执行代码,就可以看到到底发生了什么事:
执行a = 'ABC',解释器创建了字符串'ABC'和变量a,并把a指向'ABC':

执行b = a,解释器创建了变量b,并把b指向a指向的字符串'ABC':

执行a = 'XYZ',解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:

所以,最后打印变量b的结果自然是'ABC'了。
常量
所谓常量就是不能变的变量,比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
PI = 3.14159265359但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
最后解释一下整数的除法为什么也是精确的。在Python中,有两种除法,一种除法是/:
>>> 10 / 33.3333333333333335/除法计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数:
>>> 9 / 33.0还有一种除法是//,称为地板除,两个整数的除法仍然是整数:
>>> 10 // 33你没有看错,整数的地板除//永远是整数,即使除不尽。要做精确的除法,使用/就可以。
因为//除法只取结果的整数部分,所以Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 31无论整数做//除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
九、Python 的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65>>> ord('中')
20013>>> chr(66)
'B'>>> chr(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587''中文'两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
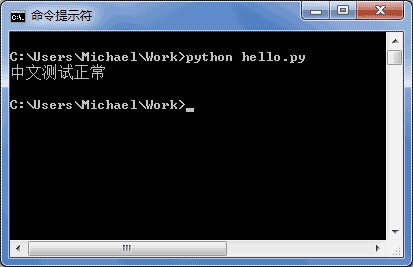
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:

如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
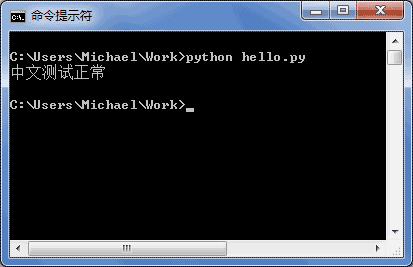
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。

在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world''Hello, world'>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1)
' 3-01'>>> '%.2f' % 3.1415926'3.14'如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7'growth rate: 7 %'字符串和编码
字符编码
我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。

因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
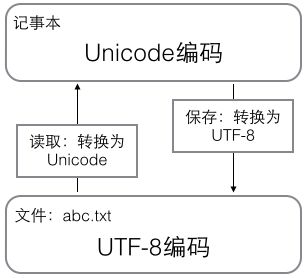
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
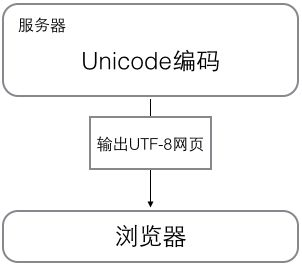
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65>>> ord('中')
20013>>> chr(66)
'B'>>> chr(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587''中文'两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:

如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似'亲爱的xxx你好!你xx月的话费是xx,余额是xx'之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。

在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world''Hello, world'>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
>>> '%2d-%02d' % (3, 1)
' 3-01'>>> '%.2f' % 3.1415926'3.14'如果你不太确定应该用什么,%s永远起作用,它会把任何数据类型转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True)
'Age: 25. Gender: True'有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7'growth rate: 7 %'
Python 3的字符串使用Unicode,直接支持多语言。
str和bytes互相转换时,需要指定编码。最常用的编码是UTF-8。Python当然也支持其他编码方式,比如把Unicode编码成GB2312:
>>> '中文'.encode('gb2312')
b'\xd6\xd0\xce\xc4'但这种方式纯属自找麻烦,如果没有特殊业务要求,请牢记仅使用UTF-8编码。
格式化字符串的时候,可以用Python的交互式命令行测试,方便快捷。
参考源码
#!/usr/bin/env python3# -*- coding: utf-8 -*-s ='Python-中文'print(s)b = s.encode('utf-8')print(b)print(b.decode('utf-8'))
十、使用list和tuple
list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
比如,列出班里所有同学的名字,就可以用一个list表示:
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates
['Michael', 'Bob', 'Tracy']
变量classmates就是一个list。用len()函数可以获得list元素的个数:
>>> len(classmates)
3用索引来访问list中每一个位置的元素,记得索引是从0开始的:
>>> classmates[0]
'Michael'
>>> classmates[1]
'Bob'
>>> classmates[2]
'Tracy'
>>> classmates[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引是len(classmates) - 1。
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
>>> classmates[-1]
'Tracy'以此类推,可以获取倒数第2个、倒数第3个:
>>> classmates[-2]
'Bob'
>>> classmates[-3]
'Michael'
>>> classmates[-4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
当然,倒数第4个就越界了。
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
>>> classmates.append('Adam')
>>> classmates
['Michael', 'Bob', 'Tracy', 'Adam']
也可以把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
要删除list末尾的元素,用pop()方法:
>>> classmates.pop()
'Adam'>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy']
要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'>>> classmates
['Michael', 'Bob', 'Tracy']
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
>>> classmates[1] = 'Sarah'>>> classmates
['Michael', 'Sarah', 'Tracy']
list里面的元素的数据类型也可以不同,比如:
>>> L = ['Apple', 123, True]
list元素也可以是另一个list,比如:
>>> s = ['python', 'java', ['asp', 'php'], 'scheme']
>>> len(s)
4要注意s只有4个元素,其中s[2]又是一个list,如果拆开写就更容易理解了:
>>> p = ['asp', 'php']
>>> s = ['python', 'java', p, 'scheme']
要拿到'php'可以写p[1]或者s[2][1],因此s可以看成是一个二维数组,类似的还有三维、四维……数组,不过很少用到。
如果一个list中一个元素也没有,就是一个空的list,它的长度为0:
>>> L = []
>>> len(L)
0tuple
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,比如同样是列出同学的名字:
>>> classmates = ('Michael', 'Bob', 'Tracy')
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
tuple的陷阱:当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
>>> t = (1, 2)
>>> t
(1, 2)
如果要定义一个空的tuple,可以写成():
>>> t = ()
>>> t
()
但是,要定义一个只有1个元素的tuple,如果你这么定义:
>>> t = (1)
>>> t
1定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
最后来看一个“可变的”tuple:
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'>>> t[2][1] = 'Y'>>> t
('a', 'b', ['X', 'Y'])
这个tuple定义的时候有3个元素,分别是'a','b'和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素:
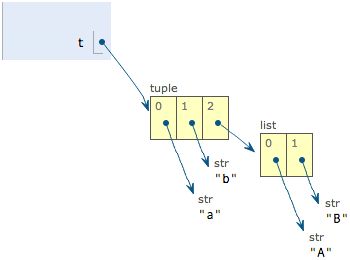
当我们把list的元素'A'和'B'修改为'X'和'Y'后,tuple变为:

表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b',指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
十一、条件判断 if
条件判断
计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
比如,输入用户年龄,根据年龄打印不同的内容,在Python程序中,用if语句实现:
age = 20if age >= 18:
print('your age is', age)
print('adult')
根据Python的缩进规则,如果if语句判断是True,就把缩进的两行print语句执行了,否则,什么也不做。
也可以给if添加一个else语句,意思是,如果if判断是False,不要执行if的内容,去把else执行了:
age = 3if age >= 18:
print('your age is', age)
print('adult')
else:
print('your age is', age)
print('teenager')
注意不要少写了冒号:。
当然上面的判断是很粗略的,完全可以用elif做更细致的判断:
age = 3if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')
elif是else if的缩写,完全可以有多个elif,所以if语句的完整形式就是:
if <条件判断1>:
<执行1>
elif <条件判断2>:
<执行2>
elif <条件判断3>:
<执行3>
else:
<执行4>if语句执行有个特点,它是从上往下判断,如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else,所以,请测试并解释为什么下面的程序打印的是teenager:
age = 20if age >= 6:
print('teenager')
elif age >= 18:
print('adult')
else:
print('kid')
if判断条件还可以简写,比如写:
if x:
print('True')
只要x是非零数值、非空字符串、非空list等,就判断为True,否则为False。
再议 input
最后看一个有问题的条件判断。很多同学会用input()读取用户的输入,这样可以自己输入,程序运行得更有意思:
birth = input('birth: ')
if birth < 2000:
print('00前')
else:
print('00后')
输入1982,结果报错:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: str() > int()
这是因为input()返回的数据类型是str,str不能直接和整数比较,必须先把str转换成整数。Python提供了int()函数来完成这件事情:
s = input('birth: ')
birth = int(s)
if birth < 2000:
print('00前')
else:
print('00后')
再次运行,就可以得到正确地结果。但是,如果输入abc呢?又会得到一个错误信息:
Traceback (most recent call last):
File "" , line 1, in <module>
ValueError: invalid literal for int() with base 10: 'abc'原来int()函数发现一个字符串并不是合法的数字时就会报错,程序就退出了。
十一、循环 for和while
循环
要计算1+2+3,我们可以直接写表达式:
>>> 1 + 2 + 36要计算1+2+3+...+10,勉强也能写出来。
但是,要计算1+2+3+...+10000,直接写表达式就不可能了。
为了让计算机能计算成千上万次的重复运算,我们就需要循环语句。
Python的循环有两种,一种是for...in循环,依次把list或tuple中的每个元素迭代出来,看例子:
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
执行这段代码,会依次打印names的每一个元素:
Michael
Bob
Tracy
所以for x in ...循环就是把每个元素代入变量x,然后执行缩进块的语句。
再比如我们想计算1-10的整数之和,可以用一个sum变量做累加:
sum = 0for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum)
如果要计算1-100的整数之和,从1写到100有点困难,幸好Python提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
>>> list(range(5))
[0, 1, 2, 3, 4]range(101)就可以生成0-100的整数序列,计算如下:
sum = 0for x in range(101):
sum = sum + x
print(sum)
请自行运行上述代码,看看结果是不是当年高斯同学心算出的5050。
第二种循环是while循环,只要条件满足,就不断循环,条件不满足时退出循环。比如我们要计算100以内所有奇数之和,可以用while循环实现:
sum = 0
n = 99while n > 0:
sum = sum + n
n = n - 2print(sum)
在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。
break
在循环中,break语句可以提前退出循环。例如,本来要循环打印1~100的数字:
n = 1
while n <= 100:print(n)
n = n + 1print('END')
上面的代码可以打印出1~100。
如果要提前结束循环,可以用break语句:
n = 1while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句break # break语句会结束当前循环print(n)
n = n + 1print('END')
执行上面的代码可以看到,打印出1~10后,紧接着打印END,程序结束。
可见break的作用是提前结束循环。
continue
在循环过程中,也可以通过continue语句,跳过当前的这次循环,直接开始下一次循环。
n = 0
while n < 10:n = n + 1print(n)
上面的程序可以打印出1~10。但是,如果我们想只打印奇数,可以用continue语句跳过某些循环:
n = 0while n < 10:
n = n + 1if n % 2 == 0: # 如果n是偶数,执行continue语句continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行print(n)
执行上面的代码可以看到,打印的不再是1~10,而是1,3,5,7,9。
可见continue的作用是提前结束本轮循环,并直接开始下一轮循环。
pass
pass语句,该语句什么也不做,也就是说它是一个空操作
十一、dict和set
dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
举个例子,假设要根据同学的名字查找对应的成绩,如果用list实现,需要两个list:
names = ['Michael', 'Bob', 'Tracy']scores = [95, 75, 85]给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长。
如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下:
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
dict就是第二种实现方式,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
把数据放入dict的方法,除了初始化时指定外,还可以通过key放入:
>>> d['Adam'] = 67>>> d['Adam']
67由于一个key只能对应一个value,所以,多次对一个key放入value,后面的值会把前面的值冲掉:
>>> d['Jack'] = 90>>> d['Jack']
90>>> d['Jack'] = 88>>> d['Jack']
88如果key不存在,dict就会报错:
>>> d['Thomas']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Thomas'
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False二是通过dict提供的get方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1注意:返回None的时候Python的交互式命令行不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75>>> d
{'Michael': 95, 'Tracy': 85}
请务必注意,dict内部存放的顺序和key放入的顺序是没有关系的。
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
>>> key = [1, 2, 3]
>>> d[key] = 'a list'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}
注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
重复元素在set中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
再议不可变对象
上面我们讲了,str是不变对象,而list是可变对象。
对于可变对象,比如list,对list进行操作,list内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']
而对于不可变对象,比如str,对str进行操作呢:
>>> a = 'abc'>>> a.replace('a', 'A')
'Abc'>>> a
'abc'虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc',应该怎么理解呢?
我们先把代码改成下面这样:
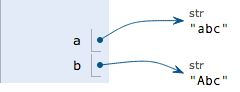
>>> a = 'abc'>>> b = a.replace('a', 'A')
>>> b
'Abc'>>> a
'abc'要始终牢记的是,a是变量,而'abc'才是字符串对象!有些时候,我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc':

当我们调用a.replace('a', 'A')时,实际上调用方法replace是作用在字符串对象'abc'上的,而这个方法虽然名字叫replace,但却没有改变字符串'abc'的内容。相反,replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了:
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
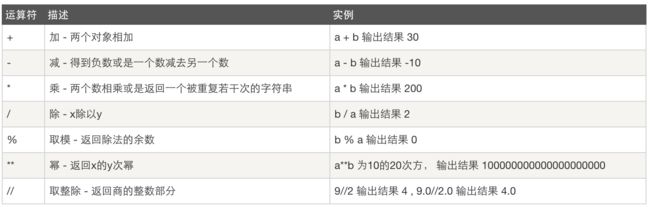
十一、数据运算
比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:
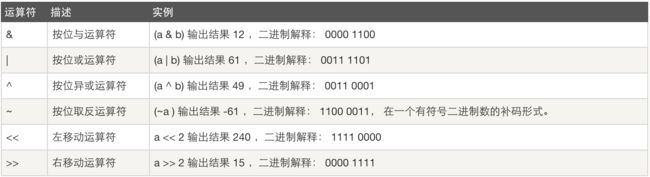
#!/usr/bin/python
a
=
60
# 60 = 0011 1100
b
=
13
# 13 = 0000 1101
c
=
0
c
=
a & b;
# 12 = 0000 1100
print
"Line 1 - Value of c is "
, c
c
=
a | b;
# 61 = 0011 1101
print
"Line 2 - Value of c is "
, c
c
=
a ^ b;
# 49 = 0011 0001
print
"Line 3 - Value of c is "
, c
c
=
~a;
# -61 = 1100 0011
print
"Line 4 - Value of c is "
, c
c
=
a <<
2
;
# 240 = 1111 0000
print
"Line 5 - Value of c is "
, c
c
=
a >>
2
;
# 15 = 0000 1111
print
"Line 6 - Value of c is "
, c
*按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265
运算符优先级:
更多内容:猛击这里
十二、入门知识拾遗
一、基本操作
下面列举一下字节的基本操作,可以看出来它和字符串还是非常相近的:
如果想要修改一个字节串中的某个字节,不能够直接修改,需要将其转化为bytearray后再进行修改:
二、字节与字符的关系
上面也提到字节跟字符很相近,其实它们是可以相互转化的。字节通过某种编码形式就可以转化为相应的字符。字节通过encode()方法传入编码方式就可以转化为字符,而字符通过decode()方法就可以转化为字节:
我们可以看到用不同的编码方式解析出来的字符和字节的方式是完全不同,如果编码和解码用了不同的编码方式,就会产生乱码,甚至转换失败。因为每种编码方式包含的字节种类数目不同,如上例中的\xc8就超出了utf-8的最大字符。
三、应用
举个最简单的例子,我要爬取一个网页的内容,现在来爬取用百度搜索Python时返回的页面,百度用的是utf-8编码格式,如果不对返回结果解码,那它就是一个超级长的字节串。而进行正确解码后就可以显示一个正常的html页面。
import urllib.request
url = "http://www.baidu.com/s?ie=utf-8&wd=python"
page = urllib.request.urlopen(url)
mybytes = page.read()
encoding = "utf-8"
print(mybytes.decode(encoding))
page.close()
result = 值1 if 条件 else 值2'Out[49]:'
如果条件为真:result = 值1
如果条件为假:result = 值2
三、进制
- 二进制,01
- 八进制,01234567
- 十进制,0123456789
- 十六进制,0123456789ABCDEF 二进制到16进制转换
附件列表
- day1-流程图.png