【确认】Master就是AlphaGo升级版!60连胜背后看专家怎么评说
1月4日晚间,此前横扫围棋界的神秘大师“Master” 忽然发声,自亮身份,它写道:我是AlphaGo 黄博士。
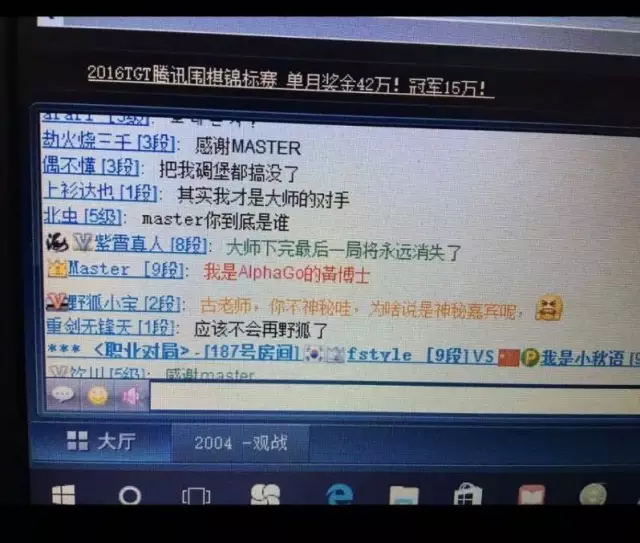
此时,Master 刚刚取得第59场不败纪录,将对战人类棋手的纪录变为59:0。此前,人们的猜测是Master在完成60场比赛后,会隐退,或者发声。但是,没有人想到,在59场的时候,Master自己亮明了身份。
官方声明:

Master 已经在线上平台上接连战胜了聂卫平、柯洁、朴廷桓、唐韦星、范廷钰、王古力、周俊勋和黄云嵩等多位围棋高手。
2017年下午3点04分,聂卫平执白3又1/4子之差负于Master,Master取得第54胜!
聂卫平在围棋圈有“棋圣”之称,只是这次,他也拿Master没办法。对弈结束后,Master 用繁体字打出了“谢谢聂老师”的消息。这个时候,其实Master的身份已经有所暗示了。后来Master所说的“黄博士”,指的是黄士杰博士。黄博士是台湾人,习惯用繁体。
如果大家有看3月份李世石与 AlphaGo 的对奕的话,应该会注意到在李世石对面有个将 AlphaGo 的棋步下到棋盘,并且将李世石的棋步再输到电脑上的人。这位就是谷歌 DeepMind 的资深研究员,也是 AlphaGo 的主要程序开发者,台湾出身的黄士杰博士。

黄士杰(前左)在替AlphaGo 执子
黄士杰博士毕业于台湾师范大学,博士论文就是以“应用于电脑围棋之蒙地卡罗树搜索法的新启发式演算法”,本身也是业余六段的围棋棋手。
此前,黄士杰在接受Engadget的采访时曾说,如果再给 AlphaGo 一年半载的话,说不定李世石真的就是史上唯一赢过 AlphaGo 一场的人了...
果然,半载之后,我们看到令人叹服的结果。
Master的技术没有想象的那么好?
对于此次掀起风暴的Master,新智元智库专家白硕评价说:
-
第一,并不意外。如果世界上还有另外一个团队达到这样的水平反而是意外。
-
第二,又有进步。现在的AlphaGo水平比去年战胜李世石的时候发挥更稳定、对人类棋手更有启发性,对人类观众更有观赏性,导致人类对棋理的认识正在酝酿重大的突破。
-
第三,还有潜力。按现在势头发展,基于对弈棋谱的深度学习和基于左右互搏的增强学习正在形成良性互动的局面,但愿这一阶段不要过快结束(否则就跑步进入机器跟人类没得可学的阶段了)。
-
第四,除了不断增强对弈能力外,让机器以人类能理解的方式讲述其棋路,以全新的体验变革人类传授和学习围棋的方式,其意义不亚于战胜人类。
新智元问及其他的机器包括国内的一些围棋AI是否有机会超越Master呢?是否需要重大算法突破才能破解Master的时间积累优势?
白硕说:“我知道有人在做。如果能大幅提高算法的效率,就意味着在同样时间内可以遍历更多有意义的变化,增强学习会做得越好。个人判断,算法上的优化仍有空间,赶超仍有机会。未来机器之间的对弈会是新的看点。”
然而,也有专业人士表示有些失望。一位要求匿名的中国某大型互联网公司AI开发者对新智元表示,Master 横扫人类棋手毫不意外,但是对过程有点失望,Master的技术没有想象的那么好,毕竟去年7月份 Aja Huang 在一次演讲中透漏可以让顶尖棋手2子,半年过去了,看不出一定能让2子。也许这并不是最新版。
棋风奔放怪异,因为没有学习过人类棋谱?
在DeepMind官宣之前,“Master”的身份激发了多方猜测,有不少人认为这就是AlphaGo的升级版,但与后者不同的是“Master”的招法极其奔放,推翻了很多人类棋手常走的定式,棋风与去年3月的AlphaGo大不相同。
值得注意的是,DeepMind公司创始人Hassabis 曾在一次采访中透露,他们正在尝试训练一个没有学习过人类棋谱的人工智能,而这可能就是Master和AlphaGo不同的原因。
CMU 博士邓侃对新智元表示:
“3月份AlphaGo 与李世石对决第一盘,取得胜利后,就说明算法已经超越人类顶级高手。接下去的几盘,AlphaGo 赢了,这是预料之中。输了一盘,反倒有点奇怪。因为算法只会越变越强大。
随着训练越来越强化,AlphaGo 的棋艺越来越精致,这是自然而然的趋势。战胜所有人类高手,只不过是时间的问题。但是看不出 (现在的)AlphaGo 的算法,有本质突破。至少没有读到 DeepMind 在这个领域的新论文。
AlphaGo 系统中,有 Monte Carlo tree search(蒙特卡洛树搜索),不妨把它理解为左右手互博。互博时间越长,实际上就是把各种可能的对弈方案,统统演练一遍。所以,AlphaGo 的训练时间越长,它对各种对弈方案的了解就越全面。”
在自我对弈中成长起来的新AlphaGo,可能完全不需要人类棋谱。
被认为与AlphaGo“必有一战”的世界第一柯洁,在这次对战中也败下阵来,但是柯洁在微博上写的感想倒是很值得深思。
他写道:“新的风暴即将来袭。我从3月份到现在研究了大半年的棋软,无数次的理论、实践,就是想知道计算机到底强在哪里。昨夜辗转反侧,不想竟一夜难眠,人类数千年的实战演练进化,计算机却告诉我们人类全是错的。我觉得,甚至没有一个人沾到围棋真理的边。但我想说,从现在开始,我们棋手将结合计算机,迈进全新的领域达到全新的境界。
专访中国围棋队总教练俞斌:慢棋是人类最后的机会,但是悬念不大
在Master身份明确后,新智元第一时间联系了中国围棋队总教练俞斌进行专访。
新智元:您觉得人类棋手还有机会吗?
俞斌:基本上没有。只留有一丝悬念,就是长时间的慢棋,但只是悬念,我判断慢棋也不行。
新智元:如果下慢棋,人类棋手最后的突破口可能是什么呢?
俞斌:慢棋人的错误会少很多,但能否一争胜负有悬念。感觉可能性很小。
新智元:之前有人认为,人类棋手以后只和人类比,而机器棋手只会和机器棋手对决了,您认为围棋最后是这样嘛?
俞斌:人与人比会,机器与机器比也有,但不会只是这两种。人与机器,人带机器,用时、让子等等,还是会有不少比的类型的。也许会有机器参加的团队赛等等
新智元:看来机器的加入反而有了更多玩法。那么您认为机器的出现,看起来像人类的天花板,人类围棋是否会放下胜负心,真正实现人和人对围棋本身的享受呢?
俞斌:哲学问题 。围棋是胜负的游戏。享受的是胜负的乐趣。有人工智能高手,并不影响享受围棋的乐趣。没有胜负而享受围棋,我理解不了。这是我个人的哲学观点。
12月29日晚19点多,一位名叫“Master”的新手登录弈城,起初没有高手搭理,但在战胜谢尔豪四段、孟泰龄六段、於之莹五段、韩一洲四段、乔智健四段后这个账号热度陡增。这晚Master十战全胜,已注定其出世不凡。
第二天中午“Master”再度现身,在对王昊洋六段、严在明三段等职业棋手4连胜后,终于引出了韩国第一人朴廷桓九段。重头戏开始上演,结果也是重量级的,朴廷桓在必败局面下超时负。此结果在高手中炸了锅,接着等级分排名第7的连笑七段登场挑战,却连败两场!值得注意的是,紧接着Master与账号为“吻别”的网络棋手交锋两次,均以中盘获胜。弈城网工作人员表示,“吻别”很有可能就是拥有4个世界冠军头衔的当今世界围棋第一人柯洁。如果“吻别”真是柯洁,那就意味着Master对当今中、韩第一人的战绩是6:0。
31号,“Master”又连续战胜各大挑战者,其中新科百灵杯冠军陈耀烨九段也以失败告终,最后的最后,这位堪比“扫地僧”的神秘高手连续30盘不败,像是在逗大伙玩似的来了句:“今天累了,明天休息一天。”
最终败在“Master”棋下的有江维杰九段、辜梓豪五段、朴永训九段、柁嘉熹九段、井山裕太九段、孟泰龄六段、金志锡九段……
连一旁观战的柯洁九段都大惊失色:“从来没见过这样的招法,围棋还能这么下?”为此他感叹:看Master的着法,等于说以前学的围棋都是错误的,原来学棋的时候要被骂的着法现在Master都下出来了。”同样的,知乎网友 @赵小康 评论道,Master对阵这些围棋高手,“大多数对局都是中盘取胜,人类数千年时间总结出的定式、大局观在master面前显得陈腐可笑。”
1月3日9:30,棋手古力九段按捺不住,最终发出10万元悬赏,奖励给战胜Master的勇士。但其后又有4位顶尖棋手被击败……
不过就在51场连胜之后,1月4日,“Master”第52盘以和棋结束,“Master”的51连胜纪录就此终止。这场比赛中,“Master”挑战中国围棋职业选手陈耀烨。“Master”执黑棋、陈耀烨执白棋,30秒3次快棋。不过陈耀烨出现了断线情况,30秒没有落子,系统判定和棋。
今日,“Master”出现以来最受瞩目的比赛在Master和聂卫平之间进行。年届64岁的中国棋圣和“Master”的比赛也是这个人工智能程序进行的第54局比赛。本局“Master”特意把比赛用时调整为每方1分钟一手,以示对聂卫平的尊敬。
最终本局进行至手,执白的聂卫平以7目半的劣势落败。本局“Master”在右上角下出犀利的手段,吃掉了聂卫平一块棋由此确立优势,并保持到了最后。而随着棋圣聂卫平落败,“Master”将自己的不败纪录延续至54场,中日韩高手无一能在这次“快棋”对决中取胜。
4日晚,随着古力败下阵来,Master 对人类棋手获得了60场不败的记录。
AlphaGo 技术原理
AlphaGo 从三月份至今,经过10个月的发展,已经有了非常长足的进步,不过要追溯其技术原理,最详细的还是三月份发表在Nature 的封面论文:Mastering the game of Go with deep neural networks and tree search(通过深度神经网络和树搜索,学会围棋游戏)。
AlphaGo 给围棋带来了新方法,它背后主要的方法是 Value Networks(价值网络)和 Policy Networks(策略网络),其中 Value Networks 评估棋盘位置,Policy Networks 选择下棋步法。这些神经网络模型通过一种新的方法训练,结合人类专家比赛中学到的监督学习,以及在自己和自己下棋(Self-Play)中学到强化学习。这不需要任何前瞻式的 Lookahead Search,神经网络玩围棋游戏的能力,就达到了最先进的蒙特卡洛树搜索算法的级别(这种算法模拟了上千种随机自己和自己下棋的结果)。我们也引入了一种新搜索算法,这种算法将蒙特卡洛模拟和价值、策略网络结合起来。
通过将 Value Networks、Policy Networks 与树搜索结合起来,AlphaGo 达到了专业围棋水准,让我们看到了希望:在其他看起来无法完成的领域中,AI 也可以达到人类级别的表现!
DeepMind 团队对围棋项目的介绍(新智元翻译)
所有完全信息(perfect information)博弈都有一个最优值函数(optimal value function),![]() ,它决定了在所有参与博弈的玩家都做出了完美表现的情况下,博弈的结果是什么:无论你在棋盘的哪个位置落子(或者说是状态s)。这些博弈游戏是可能通过在含有大约
,它决定了在所有参与博弈的玩家都做出了完美表现的情况下,博弈的结果是什么:无论你在棋盘的哪个位置落子(或者说是状态s)。这些博弈游戏是可能通过在含有大约![]() 个可能行动序列(其中b是博弈的宽度,也就是在每个位置能够移动的步数,而d是博弈的深度)的搜索树(search tree)上反复计算最优值函数来解决的。在象棋(
个可能行动序列(其中b是博弈的宽度,也就是在每个位置能够移动的步数,而d是博弈的深度)的搜索树(search tree)上反复计算最优值函数来解决的。在象棋(![]() )和围棋之类(
)和围棋之类(![]() )的大型博弈游戏中,穷尽地搜索是不合适的,但是有效搜索空间是可以通过2种普遍规则得到降低的。首先,搜索的深度可能通过位置估计(position evaluation)来降低:在状态s时截取搜索树,将随后的子树部分(subtree)替换为根据状态s来预测结果的近似的值函数
)的大型博弈游戏中,穷尽地搜索是不合适的,但是有效搜索空间是可以通过2种普遍规则得到降低的。首先,搜索的深度可能通过位置估计(position evaluation)来降低:在状态s时截取搜索树,将随后的子树部分(subtree)替换为根据状态s来预测结果的近似的值函数![]() 。这种方法使程序在象棋、跳棋、翻转棋(Othello)的游戏中表现超越了人类,但人们认为它无法应用于围棋,因为围棋极其复杂。其次,搜索的宽度可能通过从策略概率
。这种方法使程序在象棋、跳棋、翻转棋(Othello)的游戏中表现超越了人类,但人们认为它无法应用于围棋,因为围棋极其复杂。其次,搜索的宽度可能通过从策略概率![]() ——一种在位置s时表示出所有可能的行动的概率分布——中抽样行动来降低。比如,蒙特卡洛法通过从策略概率p中为博弈游戏双方抽样长序列的行动来让搜索达到深度的极限、没有任何分支树。将这些模拟结果进行平均,能够提供有效的位置估计,让程序在西洋双陆棋(backgammon)和拼字棋(Scrabble)的游戏中展现出超越人类的表现,在围棋方面也能达到低级业余爱好者水平。
——一种在位置s时表示出所有可能的行动的概率分布——中抽样行动来降低。比如,蒙特卡洛法通过从策略概率p中为博弈游戏双方抽样长序列的行动来让搜索达到深度的极限、没有任何分支树。将这些模拟结果进行平均,能够提供有效的位置估计,让程序在西洋双陆棋(backgammon)和拼字棋(Scrabble)的游戏中展现出超越人类的表现,在围棋方面也能达到低级业余爱好者水平。
文章转自新智元公众号,原文链接