集合相关
List跟Set的区别
两个接口都继承Collection,区别list有序且可以添加多个null元素,也可以添加重复元素;set不能添加重复元素,最多允许一个null,若要有序需实现comprable接口;
list 子类:ArrayList,LinkedList,Vector
ArrayList,源码比较简单,实际内部是Object[]数组,可以传入大小,默认是10,最大是Integer最大值,最大特点是增容,在add的时候判断容器大小是否需要扩容
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
还有一个特殊的部分是Iterator类
/**
* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator {
// The "limit" of this iterator. This is the size of the list at the time the
// iterator was created. Adding & removing elements will invalidate the iteration
// anyway (and cause next() to throw) so saving this value will guarantee that the
// value of hasNext() remains stable and won't flap between true and false when elements
// are added and removed from the list.
protected int limit = ArrayList.this.size;
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor < limit;
}
@SuppressWarnings("unchecked")
public E next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor;
if (i >= limit)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
limit--;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
/**
* An optimized version of AbstractList.ListItr
*/
private class ListItr extends Itr implements ListIterator {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
limit++;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
Vector跟ArrayList同样继承AbstractList,方法都一样只是在跟数组操作的相关方法都加上了synchronized关键字,由此可知他是线程安全的ArrayList;
LinkedList,通过查看LinkedList源码我们很容易发现,他同样继承了AbstractList,但是多实现了Deque(双向队列),进一步查看顾名思义内部使用了双向列表的数据结构。
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node last;
/**
* Constructs an empty list.
*/
public LinkedList() {
}
看node代码
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
当然既然是链表就不能向ArrayList的Iterator那样通过移动cursor了,下面是它的Iterator的实现,里面也是链表。
private class ListItr implements ListIterator {
private Node lastReturned = null;
private Node next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
@Override
public void forEachRemaining(Consumer action) {
Objects.requireNonNull(action);
while (modCount == expectedModCount && nextIndex < size) {
action.accept(next.item);
lastReturned = next;
next = next.next;
nextIndex++;
}
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
到此,list分析完毕,ArrayList内部使用数组存储,LinkedList是双向链表,ArrayList查询效率高,LinkedList插入,删除效率高;
Set的实现子类HashSet、LinkedHashSet 以及 TreeSet
对比list的接口发现主要有以下的方法不同,从中可以发现主要是跟index的相关的也就是顺序相关的操作,由此得知set的基因就跟序列无关,即无序
// Positional Access Operations
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException if the index is out of range
* (index < 0 || index >= size())
*/
E get(int index);
/**
* Replaces the element at the specified position in this list with the
* specified element (optional operation).
*
* @param index index of the element to replace
* @param element element to be stored at the specified position
* @return the element previously at the specified position
* @throws UnsupportedOperationException if the set operation
* is not supported by this list
* @throws ClassCastException if the class of the specified element
* prevents it from being added to this list
* @throws NullPointerException if the specified element is null and
* this list does not permit null elements
* @throws IllegalArgumentException if some property of the specified
* element prevents it from being added to this list
* @throws IndexOutOfBoundsException if the index is out of range
* (index < 0 || index >= size())
*/
E set(int index, E element);
/**
* Inserts the specified element at the specified position in this list
* (optional operation). Shifts the element currently at that position
* (if any) and any subsequent elements to the right (adds one to their
* indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws UnsupportedOperationException if the add operation
* is not supported by this list
* @throws ClassCastException if the class of the specified element
* prevents it from being added to this list
* @throws NullPointerException if the specified element is null and
* this list does not permit null elements
* @throws IllegalArgumentException if some property of the specified
* element prevents it from being added to this list
* @throws IndexOutOfBoundsException if the index is out of range
* (index < 0 || index > size())
*/
void add(int index, E element);
/**
* Removes the element at the specified position in this list (optional
* operation). Shifts any subsequent elements to the left (subtracts one
* from their indices). Returns the element that was removed from the
* list.
*
* @param index the index of the element to be removed
* @return the element previously at the specified position
* @throws UnsupportedOperationException if the remove operation
* is not supported by this list
* @throws IndexOutOfBoundsException if the index is out of range
* (index < 0 || index >= size())
*/
E remove(int index);
// Search Operations
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index i such that
* (o==null ? get(i)==null : o.equals(get(i))),
* or -1 if there is no such index.
*
* @param o element to search for
* @return the index of the first occurrence of the specified element in
* this list, or -1 if this list does not contain the element
* @throws ClassCastException if the type of the specified element
* is incompatible with this list
* (optional)
* @throws NullPointerException if the specified element is null and this
* list does not permit null elements
* (optional)
*/
int indexOf(Object o);
/**
* Returns the index of the last occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the highest index i such that
* (o==null ? get(i)==null : o.equals(get(i))),
* or -1 if there is no such index.
*
* @param o element to search for
* @return the index of the last occurrence of the specified element in
* this list, or -1 if this list does not contain the element
* @throws ClassCastException if the type of the specified element
* is incompatible with this list
* (optional)
* @throws NullPointerException if the specified element is null and this
* list does not permit null elements
* (optional)
*/
int lastIndexOf(Object o);
HashSet继承AbstractSet,打开源码,一惊,竟然是基于HashMap实现的,源码完全没什么内容,等等,hashmap是键值对啊,看代码:
private transient HashMap map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Constructs a new set containing the elements in the specified
* collection. The HashMap is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing HashMap instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity,
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
add操作实际就是放了一个空Object当value,这有点浪费内存吧,存疑,等分析HashMap再来分析这块;
LinkedHashSet继承HashSet方法上没有差异只是复写了构造方法,内部实现是LinkedHashMap
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
TreeSet内部实现是TreeMap
接下来看一下Map
Map是一个接口里面Entry接口来存储键值对
Map的子类主要包含HashMap,TreeMap,HashTable,LinkedHashMap几个,下面分别从源码来分析一下几个子类;
HashMap,了解hashMap之前我们先带着几点疑问,1,HashSet是基于HashMap他们之前是什么关系?2,HashMap是怎么快速根据key拿到值的?3,HashMap内部的数据结构是什么样的?带着思考去做事情往往能获取更高的效率。
查询HashMap源码,首先寻找数据结构:发现了HashMapEntry结构的数组,接着查看HashMapEntry的实现,HashMapEntry实现了 Map.Entry的接口,内部是个单向链表,一个单向列表的数组?轮廓已经有了,继续看
/**
* An empty table instance to share when the table is not inflated.
*/
static final HashMapEntry[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient HashMapEntry[] table = (HashMapEntry[]) EMPTY_TABLE;
/** @hide */ // Android added.
static class HashMapEntry implements Map.Entry {
final K key;
V value;
HashMapEntry next;
int hash;
/**
* Creates new entry.
*/
HashMapEntry(int h, K k, V v, HashMapEntry n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap m) {
}
}
瞅瞅构造方法,没有发现什么数据结构初始化相关。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY) {
initialCapacity = MAXIMUM_CAPACITY;
} else if (initialCapacity < DEFAULT_INITIAL_CAPACITY) {
initialCapacity = DEFAULT_INITIAL_CAPACITY;
}
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Android-Note: We always use the default load factor of 0.75f.
// This might appear wrong but it's just awkward design. We always call
// inflateTable() when table == EMPTY_TABLE. That method will take "threshold"
// to mean "capacity" and then replace it with the real threshold (i.e, multiplied with
// the load factor).
threshold = initialCapacity;
init();
}
看put方法, inflateTable(threshold);threshold这个值在构造方法里见过,果然这里就是初始化table的地方,一部一部分析,感觉有意思了
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
int i = indexFor(hash, table.length);
for (HashMapEntry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// Android-changed: Replace usage of Math.min() here because this method is
// called from the of runtime, at which point the native libraries
// needed by Float.* might not be loaded.
float thresholdFloat = capacity * loadFactor;
if (thresholdFloat > MAXIMUM_CAPACITY + 1) {
thresholdFloat = MAXIMUM_CAPACITY + 1;
}
threshold = (int) thresholdFloat;
table = new HashMapEntry[capacity];
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
int rounded = number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (rounded = Integer.highestOneBit(number)) != 0
? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded
: 1;
return rounded;
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
初始化时候传过来的容量这时候被更改了 int capacity = roundUpToPowerOf2(toSize);实际把toSize变为2的乘幂,table = new HashMapEntry[capacity];table初始成了2的乘幂的数组,回到put方法,if (key == null) return putForNullKey(value);发现key可以为空;int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);这句关键了HashMap,hash来了,这里通过key生成一个hash值,int i = indexFor(hash, table.length);
length 为2的乘幂,length-1说就是111111·····h & 11111,就会消掉不同的值,通过这个方法可以得到key在table里面的一个索引,这里就有一个疑问了,那不同的hash值& (length-1)后是会相同的,这应该就是传说中的hash碰撞吧,这也就明白了为什么数组中放的是链表了,如果出现了hash碰撞,值就可以像列表中添加了,但是列表越来越长,又怎么来保证get(key)的效率呢?先记录一下问题,慢慢解开谜团;
接下来通过循环看索引下的链表中是否存在此hash的entry如果存在,更新entry值,否则add entry
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
HashMapEntry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
HashMapEntry[] newTable = new HashMapEntry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(HashMapEntry[] newTable) {
int newCapacity = newTable.length;
for (HashMapEntry e : table) {
while(null != e) {
HashMapEntry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
resize(2 * table.length)扩容,扩容就可以减小hash碰撞,从而提高效率,问题又来了,扩容后h & (length-1)就会变了,key的hash还能正确找到位置吗?进入
resize方法transfer(newTable);解决我的疑问遍历老的table,将所有的HashMapEntry元素重新indexFor放入新的table这样就没问题了;至此我们解决了上述3的问题和2的问题indexFor拿到index可以高效的拿到HashMapEntry,通过扩容来减少hash碰撞;关于上述问题1肯定跟Iterator相关
public Set keySet() {
Set ks = keySet;
return (ks != null ? ks : (keySet = new KeySet()));
}
private final class KeySet extends AbstractSet {
public Iterator iterator() {
return newKeyIterator();
}
public int size() {
return size;
}
public boolean contains(Object o) {
return containsKey(o);
}
public boolean remove(Object o) {
return HashMap.this.removeEntryForKey(o) != null;
}
public void clear() {
HashMap.this.clear();
}
public final Spliterator spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer action) {
HashMapEntry[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (HashMapEntry e = tab[i]; e != null; e = e.next) {
action.accept(e.key);
// Android-modified - this was outside of the loop, inconsistent with other
// collections
if (modCount != mc) {
throw new ConcurrentModificationException();
}
}
}
}
}
}
private abstract class HashIterator implements Iterator {
HashMapEntry next; // next entry to return
int expectedModCount; // For fast-fail
int index; // current slot
HashMapEntry current; // current entry
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
HashMapEntry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
HashMapEntry e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
HashMapEntry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
public void remove() {
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
}
private final class ValueIterator extends HashIterator {
public V next() {
return nextEntry().getValue();
}
}
private final class KeyIterator extends HashIterator {
public K next() {
return nextEntry().getKey();
}
}
说一下这段有意思的代码:先取当前链表中的节点,直到为空if ((next = e.next) == null) ,接着 while (index < t.length && (next = t[index++]) == null),将next指向table的下一个元素,不得不感慨这样的代码看着太过清爽;;;;;
if ((next = e.next) == null) {
HashMapEntry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
到此hashMap分析完成,解决了自己的疑问;
LinkedHashSet继承了HashMap,不同之处LinkedHashMapEntry记录了插入顺序
private transient LinkedHashMapEntry header;
/**
* LinkedHashMap entry.
*/
private static class LinkedHashMapEntry extends HashMapEntry {
// These fields comprise the doubly linked list used for iteration.
LinkedHashMapEntry before, after;
LinkedHashMapEntry(int hash, K key, V value, HashMapEntry next) {
super(hash, key, value, next);
}
/**
* Removes this entry from the linked list.
*/
private void remove() {
before.after = after;
after.before = before;
}
/**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(LinkedHashMapEntry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
void recordRemoval(HashMap m) {
remove();
}
}
private abstract class LinkedHashIterator implements Iterator {
LinkedHashMapEntry nextEntry = header.after;
LinkedHashMapEntry lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
Entry nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
LinkedHashMapEntry e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
HashTable,因为已经完成的看了HashMap,所以再看跟他相关的类的时候,我就先看他们的不同点,首先他并没有跟前面两个map一样继承AbstractMap而是继承了Dictionary(Dictionary是干嘛的?),然后看到了一大堆synchronized修饰的方法,可知HashTable操作都是线程安全的;接着又发现一张陌生的面孔
public synchronized Enumeration
return this.
}
看样子跟iterator有点相似啊?是不是呢?等会看再接下来
if (value == null) {
throw new NullPointerException();
}
哎,值为空的话会报空指针,这是个坑,HashTable的值不能等于空,以后使用的时候要判断,那key呢?相关联想,
int hash = hash(key);
private static int hash(Object k) {
return k.hashCode();
}
哎,这个跟之前的hash算法不同,key不能等于null的疑问也能揭晓,
int index = (hash & 0x7FFFFFFF) % tab.length;通过构造方法我们也能看到初始化的initialCapacity也并不是2的乘幂了,通过上述 int index = (hash & 0x7FFFFFFF) % tab.length;HashTable是对数组长度取模,也是为了数组的均匀分布,减少碰撞,但是这个计算效率比h&length-1,那就差很多了,但是为什么HashTable不采取效率更高的方式呢?
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new HashtableEntry[initialCapacity];
threshold = (initialCapacity <= MAX_ARRAY_SIZE + 1) ? initialCapacity : MAX_ARRAY_SIZE + 1;
}
回头看Enumeration,比Iterator少了remove的方法,从他的实现类也可以看出他同时实现了Iterator接口,这就有点矛盾了,在remove方法中
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
可以看到boolean iterator;是来控制Enumeration还是Iterator的
public interface Enumeration {
/**
* Tests if this enumeration contains more elements.
*
* @return true if and only if this enumeration object
* contains at least one more element to provide;
* false otherwise.
*/
boolean hasMoreElements();
/**
* Returns the next element of this enumeration if this enumeration
* object has at least one more element to provide.
*
* @return the next element of this enumeration.
* @exception NoSuchElementException if no more elements exist.
*/
E nextElement();
}
private class Enumerator implements Enumeration, Iterator {
HashtableEntry[] table = Hashtable.this.table;
int index = table.length;
HashtableEntry entry = null;
HashtableEntry lastReturned = null;
int type;
/**
* Indicates whether this Enumerator is serving as an Iterator
* or an Enumeration. (true -> Iterator).
*/
boolean iterator;
/**
* The modCount value that the iterator believes that the backing
* Hashtable should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
protected int expectedModCount = modCount;
Enumerator(int type, boolean iterator) {
this.type = type;
this.iterator = iterator;
}
public boolean hasMoreElements() {
HashtableEntry e = entry;
int i = index;
HashtableEntry[] t = table;
/* Use locals for faster loop iteration */
while (e == null && i > 0) {
e = t[--i];
}
entry = e;
index = i;
return e != null;
}
public T nextElement() {
HashtableEntry et = entry;
int i = index;
HashtableEntry[] t = table;
/* Use locals for faster loop iteration */
while (et == null && i > 0) {
et = t[--i];
}
entry = et;
index = i;
if (et != null) {
HashtableEntry e = lastReturned = entry;
entry = e.next;
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
}
throw new NoSuchElementException("Hashtable Enumerator");
}
// Iterator methods
public boolean hasNext() {
return hasMoreElements();
}
public T next() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
return nextElement();
}
public void remove() {
if (!iterator)
throw new UnsupportedOperationException();
if (lastReturned == null)
throw new IllegalStateException("Hashtable Enumerator");
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
synchronized(Hashtable.this) {
HashtableEntry[] tab = Hashtable.this.table;
int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length;
for (HashtableEntry e = tab[index], prev = null; e != null;
prev = e, e = e.next) {
if (e == lastReturned) {
modCount++;
expectedModCount++;
if (prev == null)
tab[index] = e.next;
else
prev.next = e.next;
count--;
lastReturned = null;
return;
}
}
throw new ConcurrentModificationException();
}
}
}
Dictionary没看出有什么特殊的功能多了两个方法,说白了是返回不能删除的Iterator
abstract public Enumeration keys();
/**
* Returns an enumeration of the values in this dictionary. The general
* contract for the elements method is that an
* Enumeration is returned that will generate all the elements
* contained in entries in this dictionary.
*
* @return an enumeration of the values in this dictionary.
* @see java.util.Dictionary#keys()
* @see java.util.Enumeration
*/
abstract public Enumeration elements();
TreeMap,同样带着思考,HashMap跟TreeMap选择的时候,无需排序选择HashMap需要就选择TreeMap,所以TreeMap是怎么实现排序的?
查看源码先找不同点,跟HashMap一样继承AbstractMap类,但是多实现了NavigableMap接口,可通行的Map是个什么鬼?迎面向我们走来的是
private final Comparator comparator;
跟心想的一样,排序吗怎少得了Comparator,当然陌生苗孔SortedMap出现,
数据结构这不想其他entry[]了,而是出现了
private transient TreeMapEntry
根节点,???非hash怎么保证效率,往下看,好吧,这货跟上面的不是一回事,没有什么一样的,那就只能细细读了
从SortedMap开始吧,他只是一个接口继承Map,多了一些head,tail,frist,last的字眼,NavigableMap多了一些比较的名词在上面,可知这些都跟排序有着极大的关系;
public interface SortedMap extends Map {
Comparator comparator();
SortedMap headMap(K toKey);
SortedMap tailMap(K fromKey);
···
}
public interface NavigableMap extends SortedMap {
···
K floorKey(K key);
Map.Entry ceilingEntry(K key);
····
}
查看结构TreeMapEntry,left ,right ,parent代表它是一颗树,color = BLACK,红黑二叉树,treeMap内部使用了红黑树来实现有序排列
private static final boolean RED = false;
private static final boolean BLACK = true;
static final class TreeMapEntry implements Map.Entry {
K key;
V value;
TreeMapEntry left = null;
TreeMapEntry right = null;
TreeMapEntry parent;
boolean color = BLACK;
构造方法没什么特别,添加构造器了,添加map集合了这些,应该从查找,添加,删除操作,揭开它的神秘面纱;
从getEntry可以看出key不能等于null
if (key == null)
throw new NullPointerException();
如果Comparator不等于空的,就从根节点,通过比较逐步找到节点,否则key就要实现Comparable接口,然后也是通过比较找到;看到这里又有疑问如果可以没有实现Comparable接口,是不是在put的时候有什么特殊的处理?如果有多个key比较相同呢?可能还得往下看
public TreeMap(Comparator comparator) {
this.comparator = comparator;
}
···
final TreeMapEntry getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
TreeMapEntry p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
//构造器不空
final TreeMapEntry getEntryUsingComparator(Object key) {
@SuppressWarnings("unchecked")
K k = (K) key;
Comparator cpr = comparator;
if (cpr != null) {
TreeMapEntry p = root;
while (p != null) {
int cmp = cpr.compare(k, p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
}
return null;
}
接下来查看put方法,当根节点为null,比较器不为null的时候key可以为null,否则key不等于null,解决上述key不实现comparable的疑问 (!(key instanceof Comparable)是会报异常的;
else if (!(key instanceof Comparable)) {
throw new ClassCastException(
"Cannot cast" + key.getClass().getName() + " to Comparable.");
}
如果找到相同节点只会更新value, t.setValue(value);所以不会有重复节点,key比较相同的,可能会被替换,慎用;
下面的插入很简单就是比较大于右边,小于左边,直至插入合适的位置;那么疑问来了,有可能根节点一侧的数据特别特别多,另外一侧没有数据,偏树,这样查询效率就会低了;接着看,肯定有让树平衡的算法,下面有个方法fixAfterInsertion,插入后修理,那应该就是他了,看了一下他的算法,然后用笔在纸上花了一下,就明白了他的算法,之前看了红黑二叉树的算法,不是特别的理解,看了这个一下就通了;下面在系统的说明一下:
public V put(K key, V value) {
TreeMapEntry t = root;
if (t == null) {
if (comparator != null) {
if (key == null) {
comparator.compare(key, key);
}
} else {
if (key == null) {
throw new NullPointerException("key == null");
} else if (!(key instanceof Comparable)) {
throw new ClassCastException(
"Cannot cast" + key.getClass().getName() + " to Comparable.");
}
}
root = new TreeMapEntry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
TreeMapEntry parent;
// split comparator and comparable paths
Comparator cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable k = (Comparable) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
TreeMapEntry e = new TreeMapEntry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
/** From CLR */
private void fixAfterInsertion(TreeMapEntry x) {
x.color = RED;
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
TreeMapEntry y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
} else {
TreeMapEntry y = leftOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == leftOf(parentOf(x))) {
x = parentOf(x);
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
之前就通过各种途径了解过红黑二叉树,因为没有看实际的例子所以有些抽象,集合TreeMap一下就通了,以此记录一下:
首先什么是红黑二叉树,有什么特点?
1.根节点是黑色
2.叶子节点是黑色
3.每个节点只能是黑色或者红色的一种
4.不可能出现两个连续的红色节点
5.从任何一个节点出发,包含黑色节点的个数是一样的
顺序是left
put方法显示根据一系列比较算法将对应的节点插入对应的父亲下,接着进入fixAfterInsertion方法(这个就是红黑树保持平衡的关键所在),首先将最后插入的节点颜色设置为红, while (x != null && x != root && x.parent.color == RED) 说明根节点或者父节点为黑色的话,树不需要平衡,大家动手画画还是画画吧比较清晰
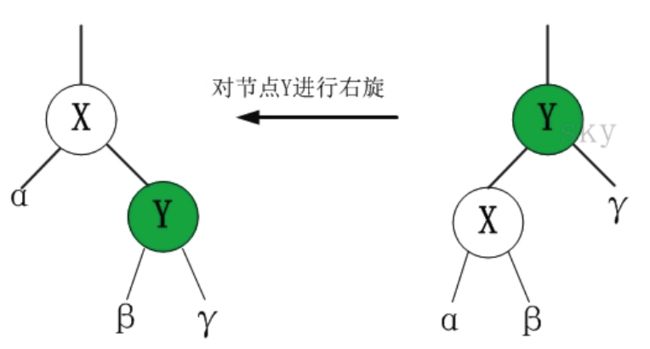
接着判断父节点在爷爷节点的左侧还是右侧,如果是在左侧判断叔叔节点是不是红色,如果是红色把父亲和叔叔的颜色设置成黑色,爷爷改成红色,然后把当前节点移到爷爷节点继续遍历;如果叔叔节点是黑色,判断当前节点如果在右侧,然后做一个左旋转,将父设置成黑色,爷爷设成红色对爷爷右旋。左旋右旋看图片可能比较好,自己照着画一下,就更清晰了
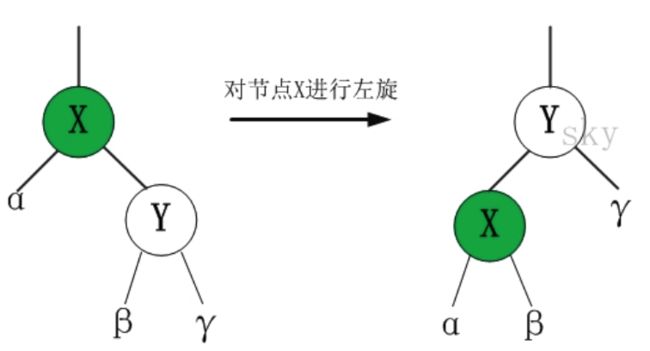
/** From CLR */
private void rotateLeft(TreeMapEntry p) {
if (p != null) {
TreeMapEntry r = p.right;
p.right = r.left;
if (r.left != null)
r.left.parent = p;
r.parent = p.parent;
if (p.parent == null)
root = r;
else if (p.parent.left == p)
p.parent.left = r;
else
p.parent.right = r;
r.left = p;
p.parent = r;
}
}
/** From CLR */
private void rotateRight(TreeMapEntry p) {
if (p != null) {
TreeMapEntry l = p.left;
p.left = l.right;
if (l.right != null) l.right.parent = p;
l.parent = p.parent;
if (p.parent == null)
root = l;
else if (p.parent.right == p)
p.parent.right = l;
else p.parent.left = l;
l.right = p;
p.parent = l;
}
}
"删除常规二叉查找树中删除节点的方法是一样的"。分3种情况:
① 被删除节点没有儿子,即为叶节点。那么,直接将该节点删除就OK了。
② 被删除节点只有一个儿子。那么,直接删除该节点,并用该节点的唯一子节点顶替它的位置。
③ 被删除节点有两个儿子。那么,先找出它的后继节点;然后把“它的后继节点的内容”复制给“该节点的内容”;之后,删除“它的后继节点”。在这里,后继节点相当于替身,在将后继节点的内容复制给"被删除节点"之后,再将后继节点删除。这样就巧妙的将问题转换为"删除后继节点"的情况了,下面就考虑后继节点。 在"被删除节点"有两个非空子节点的情况下,它的后继节点不可能是双子非空。既然"的后继节点"不可能双子都非空,就意味着"该节点的后继节点"要么没有儿子,要么只有一个儿子。若没有儿子,则按"情况① "进行处理;若只有一个儿子,则按"情况② "进行处理。
处理完后这个树可能就不符合二叉树的要求,需要做一下修整修整算法
/** From CLR */
private void fixAfterDeletion(TreeMapEntry x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
TreeMapEntry sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
} else { // symmetric
TreeMapEntry sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
}
setColor(x, BLACK);
}
看着代码都能看懂,但是这样的操作是怎么保持平衡的,画一画,就会清晰
从网上截一些图,主要是跟兄弟节点,和侄子节点有关系
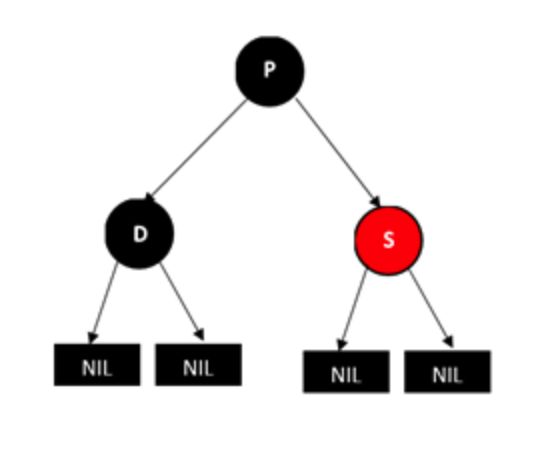
待删除节点D的兄弟节点S为红色,D没了这个树肯定就无法保持平衡。
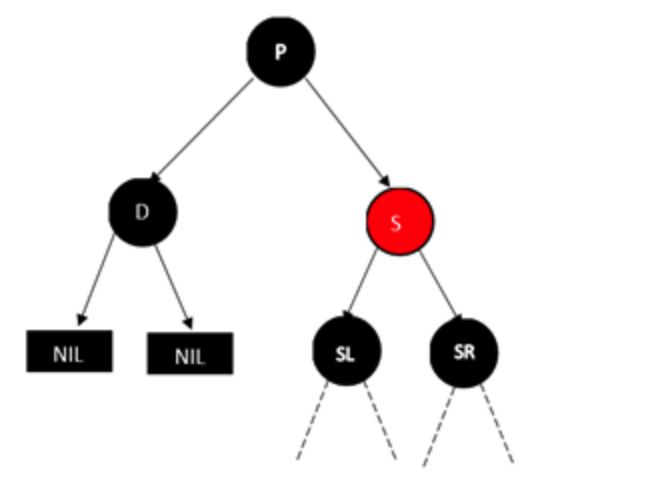
调整做法是将父亲节点和兄弟节点的颜色互换,也就是p变成红色,S变成黑色,然后将P树进行左旋型操作,结果如下图,D删掉,同样不平衡,还需要继续向下操作,等会说明
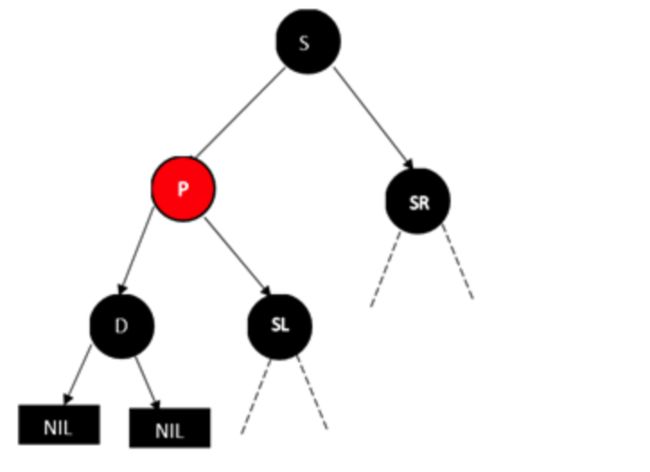
D是右节点的情况,跟上面一样只是操作的方向相反
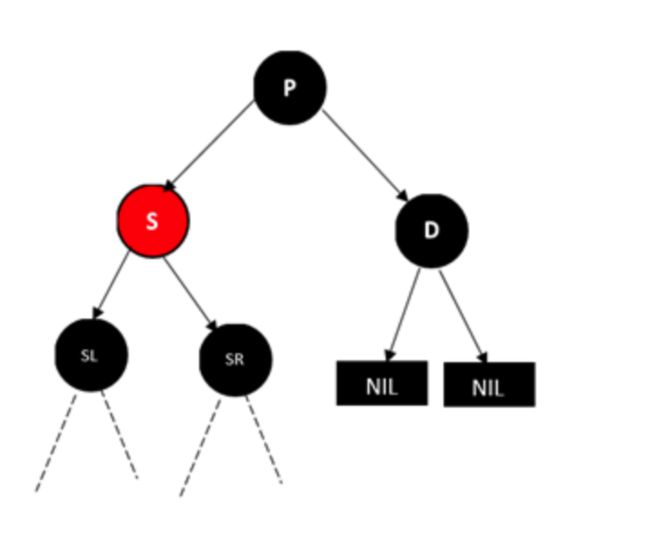
情况2:兄弟节点为黑色,且远侄子节点为红色。
D为左孩子对的情况,这时D的远侄子节点为S的右孩子
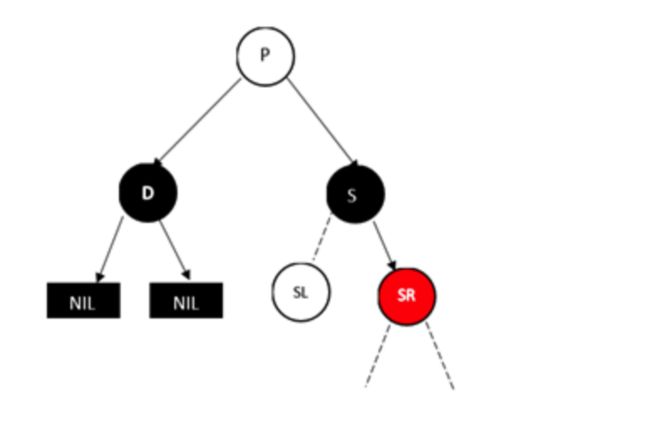
没有上色的节点表示黑色红色均可,注意如果SL为黑色,则SL必为NULL节点。
这个时候,如果我们删除D,这样经过D的子节点(NULL节点)的路径的黑色节点个数就会减1,但是我们看到S的孩子中有红色的节点,如果我们能把这棵红色的节点移动到左侧,并把它改成黑色,那么就满足要求了,这也是为什么P的颜色无关,因为调整过程只在P整棵子树的内部进行。
调整过程为,将P和S的颜色对调,然后对P树进行类似AVL树RR型的操作,最后把SR节点变成黑色,并删除D即可。
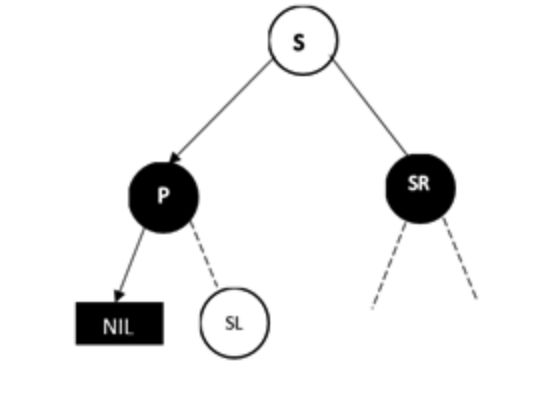
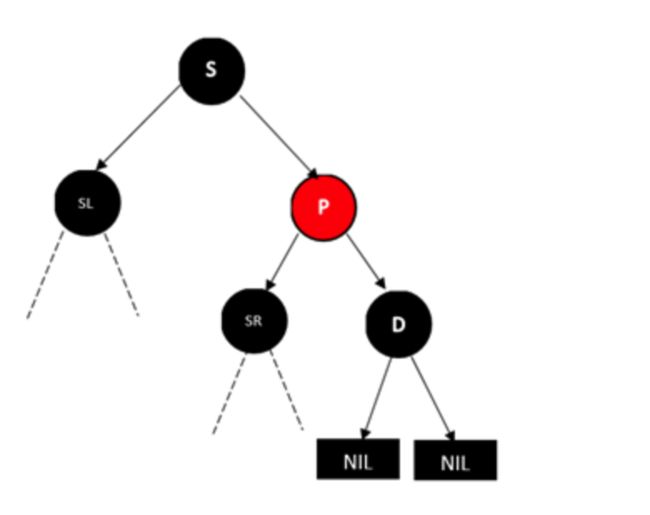
另外一边也一样
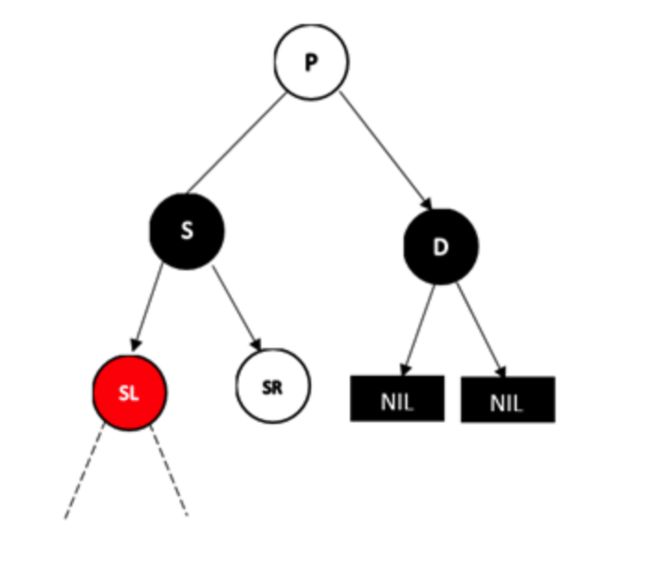
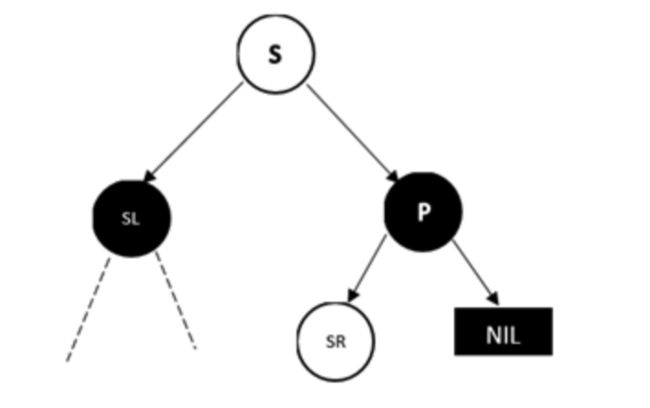
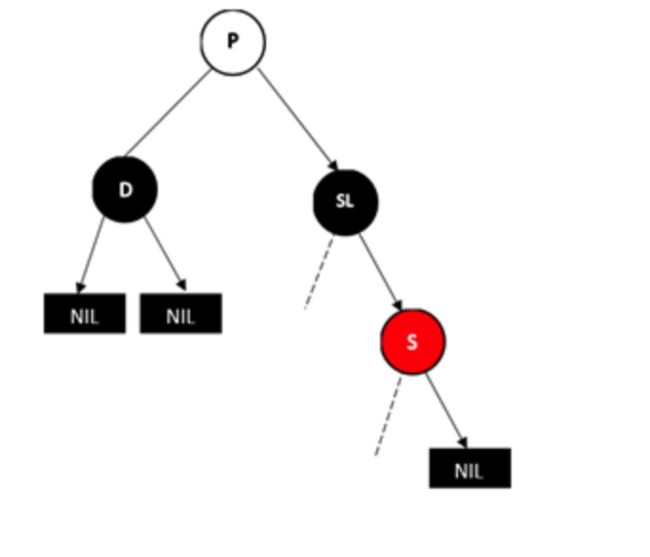
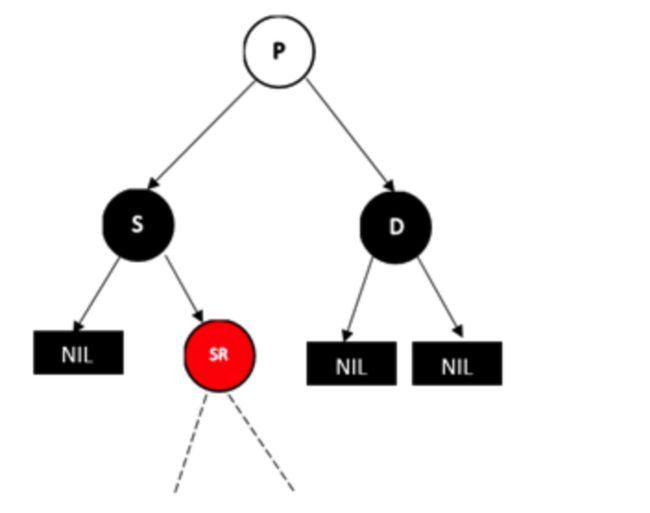
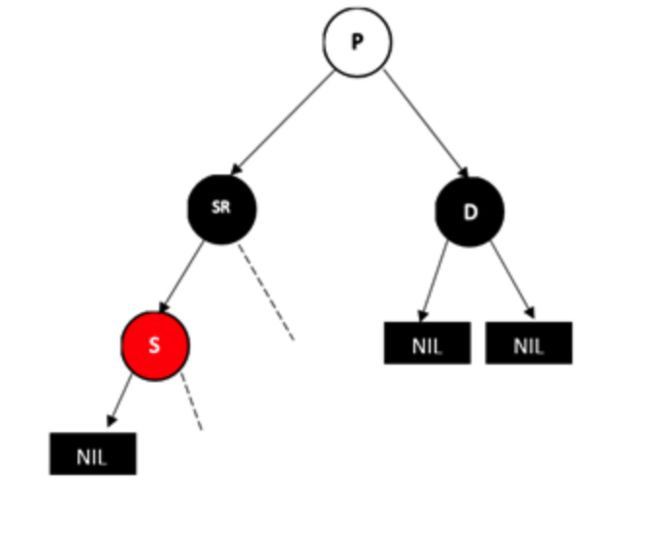
情况3:兄弟节点S为黑色,远侄子节点为黑色,近侄子节点为红色
D为左孩子的情况,此时近侄子节点为S的左孩子
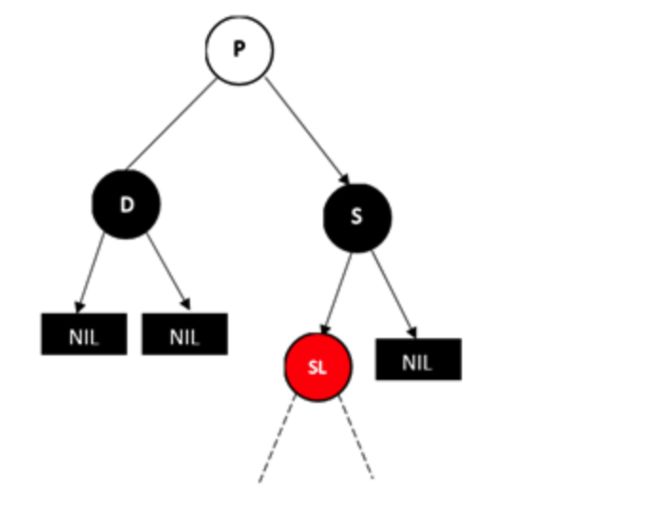
做法是,将SL右旋,并将S和SL的颜色互换
相反情况
情况4:父亲节p为红色,兄弟节点和兄弟节点的两个孩子(只能是NULL节点)都为黑色的情况。
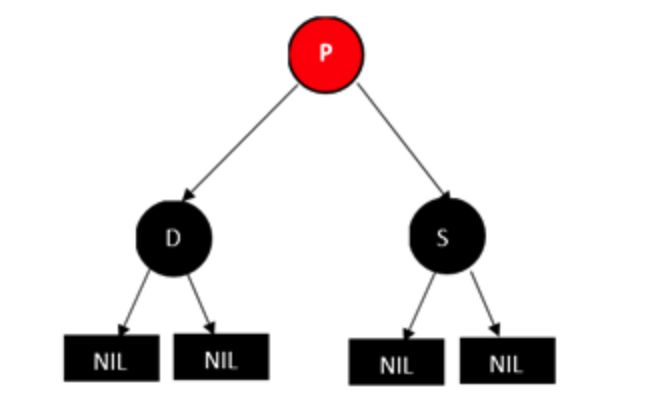
如果删除D,那经过P到D的子节点NULL的路径上黑色就少了一个,这个时候我们可以把P变成黑色,这样删除D后经过D子节点(NULL节点)路径上的黑色节点就和原来一样了。但是这样会导致经过S的子节点(NULL节点)的路径上的黑色节点数增加一个,所以这个时候可以再将S节点变成红色,这样路径上的黑色节点数就和原来一样啦!
所以做法是,将父亲节点P改成黑色,将兄弟节点S改成红色,然后删除D即可。如下图:
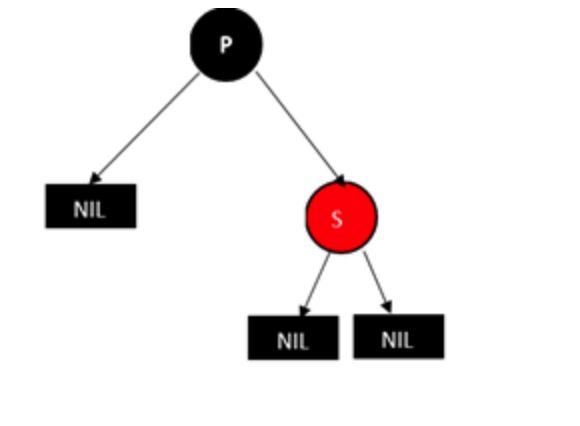
情况5:父亲节点p,兄弟节点s和兄弟节点的两个孩子(只能为NULL节点)都为黑色的情况
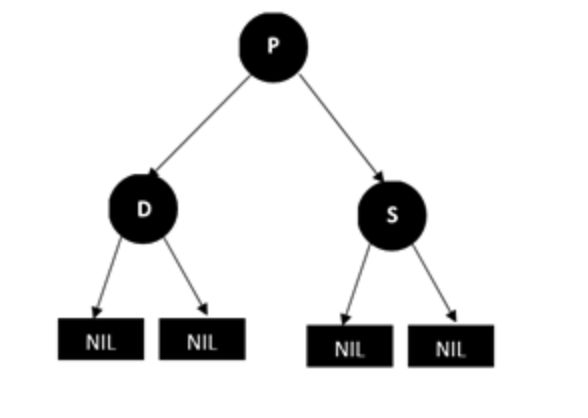
方法是将兄弟节点S的颜色改成红色,这样删除D后P的左右两支的黑节点数就相等了,但是经过P的路径上的黑色节点数会少1,这个时候,我们再以P为起始点,继续根据情况进行平衡操作(这句话的意思就是把P当成D(只是不要再删除P了),再看是那种情况,再进行对应的调整,这样一直向上,直到新的起始点为根节点)。结果如下图: