手把手教你实现 Docker 部署 Redis 集群

作者:我为什么要写这个
cnblogs.com/cxbhakim/p/9151720.html
摘要
接触docker以来,似乎养成了一种习惯,安装什么应用软件都想往docker方向做,今天就想来尝试下使用docker搭建redis集群。
首先,我们需要理论知识:Redis Cluster是Redis的分布式解决方案,它解决了redis单机中心化的问题,分布式数据库——首要解决把整个数据集按照分区规则映射到多个节点的问题。
这边就需要知道分区规则——哈希分区规则。Redis Cluster 采用哈希分区规则中的虚拟槽分区。所有的键根据哈希函数映射到0 ~ 16383,计算公式:slot = CRC16(key)&16383。每一个节点负责维护一部分槽以及槽所映射的键值数据。
一、创建redis docker基础镜像
1.下载redis安装包,使用版本为:4.0.1
[root@etcd1 tmp]# mkdir docker_redis_cluster
[root@etcd1 tmp]# cd docker_redis_cluster/
[root@etcd2 docker_redis_cluster]# wget http://download.redis.io/releases/redis-4.0.1.tar.gz
2.解压编译redis
[root@etcd1 docker_redis_cluster]# tar zxvf redis-4.0.1.tar.gz
[root@etcd1 docker_redis_cluster]# cd redis-4.0.1/
[root@etcd1 redis-4.0.1]# make
3.修改redis配置
[root@etcd3 redis-4.0.1]# vi /tmp/docker_redis_cluster/redis-4.0.1/redis.conf
修改bind ip地址
# ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the
# internet, binding to all the interfaces is dangerous and will expose the
# instance to everybody on the internet. So by default we uncomment the
# following bind directive, that will force Redis to listen only into
# the IPv4 lookback interface address (this means Redis will be able to
# accept connections only from clients running into the same computer it
# is running).
#
# IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES
# JUST COMMENT THE FOLLOWING LINE.
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#bind 127.0.0.1
bind 0.0.0.0
将守护进程yes改成no
# By default Redis does not run as a daemon. Use 'yes' if you need it.
# Note that Redis will write a pid file in /var/run/redis.pid when daemonized.
daemonize no
将密码项注释去掉,添加新密码
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
# requirepass foobared
修改为
# Warning: since Redis is pretty fast an outside user can try up to
# 150k passwords per second against a good box. This means that you should
# use a very strong password otherwise it will be very easy to break.
#
requirepass 123456
因为配置了密码,所以,配置中另外一处主从连接也需要配置密码
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the slave to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the slave request.
#
# masterauth
修改为
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the slave to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the slave request.
#
# masterauth
masterauth 123456
设置日志路径
# Specify the log file name. Also the empty string can be used to force
# Redis to log on the standard output. Note that if you use standard
# output for logging but daemonize, logs will be sent to /dev/null
logfile "/var/log/redis/redis-server.log"
配置集群相关信息,去掉配置项前面的注释
# Normal Redis instances can't be part of a Redis Cluster; only nodes that are
# started as cluster nodes can. In order to start a Redis instance as a
# cluster node enable the cluster support uncommenting the following:
#
cluster-enabled yes
# Every cluster node has a cluster configuration file. This file is not
# intended to be edited by hand. It is created and updated by Redis nodes.
# Every Redis Cluster node requires a different cluster configuration file.
# Make sure that instances running in the same system do not have
# overlapping cluster configuration file names.
#
cluster-config-file nodes-6379.conf
# Cluster node timeout is the amount of milliseconds a node must be unreachable
# for it to be considered in failure state.
# Most other internal time limits are multiple of the node timeout.
#
cluster-node-timeout 15000
4.镜像制作
[root@etcd3 docker_redis_cluster]# cd /tmp/docker_redis_cluster
[root@etcd3 docker_redis_cluster]# vi Dockerfile
# Redis
# Version 4.0.1
FROM Centos:7
ENV REDIS_HOME /usr/local
ADD redis-4.0.1.tar.gz / # 本地的redis源码包复制到镜像的根路径下,ADD命令会在复制过后自动解包。被复制的对象必须处于Dockerfile同一路径,且ADD后面必须使用相对路径
RUN mkdir -p $REDIS_HOME/redis # 创建安装目录
ADD redis-4.0.1/redis.conf $REDIS_HOME/redis/ # 将一开始编译产生并修改后的配置复制到安装目录
RUN yum -y update # 更新yum源
RUN yum install -y gcc make # 安装编译需要的工具
WORKDIR /redis-4.0.1
RUN make
RUN mv /redis-4.0.1/src/redis-server $REDIS_HOME/redis/ # 编译后,容器中只需要可执行文件redis-server
WORKDIR /
RUN rm -rf /redis-4.0.1 # 删除解压文件
RUN yum remove -y gcc make # 安装编译完成之后,可以删除多余的gcc跟make
VOLUME ["/var/log/redis"] # 添加数据卷
EXPOSE 6379 # 暴露6379端口,也可以暴露多个端口,这里不需要如此
PS.当前镜像非可执行镜像,所以没有包含ENTRYPOINT和CMD指令
5.构建镜像
# 切换中国源
[root@etcd3 docker_redis_cluster]# vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
# 编译
[root@etcd3 docker_redis_cluster]# docker build -t hakimdstx/cluster-redis .
...
Complete!
---> 546cb1d34f35
Removing intermediate container 6b6556c5f28d
Step 14/15 : VOLUME /var/log/redis
---> Running in 05a6642e4046
---> e7e2fb8676b2
Removing intermediate container 05a6642e4046
Step 15/15 : EXPOSE 6379
---> Running in 5d7abe1709e2
---> 2d1322475f79
Removing intermediate container 5d7abe1709e2
Successfully built 2d1322475f79
镜像制作完成,制作中间可能会报: Public key for glibc-headers-2.17-222.el7.x86_64.rpm is not installed 错误,这时候需要在镜像配置中添加一句命令:
...
RUN rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
RUN yum -y update # 更新yum源
RUN yum install -y gcc make # 安装编译需要的工具
查看镜像:
[root@etcd3 docker_redis_cluster]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hakimdstx/cluster-redis 4.0.1 1fca5a08a4c7 14 seconds ago 435 MB
centos 7 49f7960eb7e4 2 days ago 200 MB
以上,redis 基础镜像就制作完成了
二、制作redis节点镜像
1.基于此前制作的redis基础镜像创建一个redis节点镜像
[root@etcd3 tmp]# mkdir docker_redis_nodes
[root@etcd3 tmp]# cd docker_redis_nodes
[root@etcd3 docker_redis_nodes]# vi Dockerfile
# Redis Node
# Version 4.0.1
FROM hakimdstx/cluster-redis:4.0.1
# MAINTAINER_INFO
MAINTAINER hakim [email protected]
ENTRYPOINT ["/usr/local/redis/redis-server", "/usr/local/redis/redis.conf"]
2.构建redis节点镜像
[root@etcd3 docker_redis_nodes]# docker build -t hakimdstx/nodes-redis:4.0.1 .
Sending build context to Docker daemon 2.048 kB
Step 1/3 : FROM hakimdstx/cluster-redis:4.0.1
---> 1fca5a08a4c7
Step 2/3 : MAINTAINER hakim [email protected]
---> Running in cc6e07eb2c36
---> 55769d3bfacb
Removing intermediate container cc6e07eb2c36
Step 3/3 : ENTRYPOINT /usr/local/redis/redis-server /usr/local/redis/redis.conf
---> Running in f5dedf88f6f6
---> da64da483559
Removing intermediate container f5dedf88f6f6
Successfully built da64da483559
3.查看镜像
[root@etcd3 docker_redis_nodes]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hakimdstx/nodes-redis 4.0.1 da64da483559 51 seconds ago 435 MB
hakimdstx/cluster-redis 4.0.1 1fca5a08a4c7 9 minutes ago 435 MB
centos 7 49f7960eb7e4 2 days ago 200 MB
三、运行redis集群
1.运行redis容器
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6379 -p 6379:6379 hakimdstx/nodes-redis:4.0.1
1673a7d859ea83257d5bf14d82ebf717fb31405c185ce96a05f597d8f855aa7d
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6380 -p 6380:6379 hakimdstx/nodes-redis:4.0.1
df6ebce6f12a6f3620d5a29adcfbfa7024e906c3af48f21fa7e1fa524a361362
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6381 -p 6381:6379 hakimdstx/nodes-redis:4.0.1
396e174a1d9235228b3c5f0266785a12fb1ea49efc7ac755c9e7590e17aa1a79
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6382 -p 6382:6379 hakimdstx/nodes-redis:4.0.1
d9a71dd3f969094205ffa7596c4a04255575cdd3acca2d47fe8ef7171a3be528
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6383 -p 6383:6379 hakimdstx/nodes-redis:4.0.1
73e4f843d8cb28595456e21b04f97d18ce1cdf8dc56d1150844ba258a3781933
[root@etcd3 docker_redis_nodes]# docker run -d --name redis-6384 -p 6384:6379 hakimdstx/nodes-redis:4.0.1
10c62aafa4dac47220daf5bf3cec84406f086d5261599b54ec6c56bb7da97d6d
2.查看容器信息
[root@etcd3 redis]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
10c62aafa4da hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 seconds ago Up 2 seconds 0.0.0.0:6384->6379/tcp redis-6384
73e4f843d8cb hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 12 seconds ago Up 10 seconds 0.0.0.0:6383->6379/tcp redis-6383
d9a71dd3f969 hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 20 seconds ago Up 18 seconds 0.0.0.0:6382->6379/tcp redis-6382
396e174a1d92 hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6381->6379/tcp redis-6381
df6ebce6f12a hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6380->6379/tcp redis-6380
1673a7d859ea hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6379->6379/tcp redis-6379
3.运行 redis 集群容器
a.通过远程连接,查看redis info replication 信息
[root@etcd2 ~]# redis-cli -h 192.168.10.52 -p 6379
192.168.10.52:6379> info replication
NOAUTH Authentication required.
192.168.10.52:6379> auth 123456
OK
192.168.10.52:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:2f0a7b50aed699fa50a79f3f7f9751a070c50ee9
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
192.168.10.52:6379>
# 其余基本信息同上
可以看到,客户连接之后,因为之前设置了密码,所以需要先输入密码认证,否则就无法通过。以上信息,我们知道所有的redis都是master角色 role:master ,这显然不是我们所希望的。
b.在配置之前我们需要查看所有容器当前的IP地址
[root@etcd3 redis]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
10c62aafa4da hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 seconds ago Up 2 seconds 0.0.0.0:6384->6379/tcp redis-6384
73e4f843d8cb hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 12 seconds ago Up 10 seconds 0.0.0.0:6383->6379/tcp redis-6383
d9a71dd3f969 hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 20 seconds ago Up 18 seconds 0.0.0.0:6382->6379/tcp redis-6382
396e174a1d92 hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6381->6379/tcp redis-6381
df6ebce6f12a hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6380->6379/tcp redis-6380
1673a7d859ea hakimdstx/nodes-redis:4.0.1 "/usr/local/redis/..." 3 days ago Up 3 days 0.0.0.0:6379->6379/tcp redis-6379
[root@etcd3 redis]#
[root@etcd3 redis]# docker inspect 10c62aafa4da 73e4f843d8cb d9a71dd3f969 396e174a1d92 df6ebce6f12a 1673a7d859ea | grep IPA
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.7",
"IPAMConfig": null,
"IPAddress": "172.17.0.7",
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.6",
"IPAMConfig": null,
"IPAddress": "172.17.0.6",
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.5",
"IPAMConfig": null,
"IPAddress": "172.17.0.5",
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.4",
"IPAMConfig": null,
"IPAddress": "172.17.0.4",
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.3",
"IPAMConfig": null,
"IPAddress": "172.17.0.3",
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.2",
"IPAMConfig": null,
"IPAddress": "172.17.0.2",
可以知道:redis-6379:172.17.0.2,redis-6380:172.17.0.3,redis-6381:172.17.0.4,redis-6382:172.17.0.5,redis-6383:172.17.0.6,redis-6384:172.17.0.7
c.配置redis
d.ert
4.Redis Cluster 的集群感知操作
//集群(cluster)
CLUSTER INFO 打印集群的信息
CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
//节点(node)
CLUSTER MEET 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
CLUSTER FORGET 从集群中移除 node_id 指定的节点。
CLUSTER REPLICATE 将当前节点设置为 node_id 指定的节点的从节点。
CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面。
//槽(slot)
CLUSTER ADDSLOTS [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
CLUSTER DELSLOTS [slot ...] 移除一个或多个槽对当前节点的指派。
CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
CLUSTER SETSLOT NODE 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
CLUSTER SETSLOT MIGRATING 将本节点的槽 slot 迁移到 node_id 指定的节点中。
CLUSTER SETSLOT IMPORTING 从 node_id 指定的节点中导入槽 slot 到本节点。
CLUSTER SETSLOT STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
//键 (key)
CLUSTER KEYSLOT 计算键 key 应该被放置在哪个槽上。
CLUSTER COUNTKEYSINSLOT 返回槽 slot 目前包含的键值对数量。
CLUSTER GETKEYSINSLOT 返回 count 个 slot 槽中的键。
redis 集群感知:节点握手——是指一批运行在集群模式的节点通过Gossip协议彼此通信,达到感知对方的过程。
192.168.10.52:6379> CLUSTER MEET 172.17.0.3 6379
OK
192.168.10.52:6379> CLUSTER MEET 172.17.0.4 6379
OK
192.168.10.52:6379> CLUSTER MEET 172.17.0.5 6379
OK
192.168.10.52:6379> CLUSTER MEET 172.17.0.6 6379
OK
192.168.10.52:6379> CLUSTER MEET 172.17.0.7 6379
OK
192.168.10.52:6379> CLUSTER NODES
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master - 0 1528697195600 1 connected
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528697195600 0 connected
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 master - 0 1528697195600 5 connected
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 master - 0 1528697194000 4 connected
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 master - 0 1528697194995 3 connected
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 myself,master - 0 1528697195000 2 connected
当前已经使这六个节点组成集群,但是现在还无法工作,因为集群节点还没有分配槽(slot)。
a.分配槽信息
查看172.17.0.2:6379 的槽个数
192.168.10.52:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:0 # 被分配槽的个数为0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:260418
cluster_stats_messages_pong_sent:260087
cluster_stats_messages_meet_sent:10
cluster_stats_messages_sent:520515
cluster_stats_messages_ping_received:260086
cluster_stats_messages_pong_received:260328
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:520415
上面看到集群状态是失败的,原因是槽位没有分配,而且需要一次性把16384个槽位完全分配了,集群才可用。
b.分配槽位
分配槽位:CLUSTER ADDSLOTS 槽位,一个槽位只能分配一个节点,16384个槽位必须分配完,不同节点不能冲突。
所以通过脚本进行分配 addslots.sh:
#!/bin/bash
# node1 192.168.10.52 172.17.0.2
n=0
for ((i=n;i<=5461;i++))
do
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6379 -a 123456 CLUSTER ADDSLOTS $i
done
# node2 192.168.10.52 172.17.0.3
n=5462
for ((i=n;i<=10922;i++))
do
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6380 -a 123456 CLUSTER ADDSLOTS $i
done
# node3 192.168.10.52 172.17.0.4
n=10923
for ((i=n;i<=16383;i++))
do
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6381 -a 123456 CLUSTER ADDSLOTS $i
done
其中, -a 123456 表示需要输入的密码。
192.168.10.52:6379> CLUSTER INFO
cluster_state:fail # 集群状态为失败
cluster_slots_assigned:16101 # 没有完全分配结束
cluster_slots_ok:16101
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:266756
cluster_stats_messages_pong_sent:266528
cluster_stats_messages_meet_sent:10
cluster_stats_messages_sent:533294
cluster_stats_messages_ping_received:266527
cluster_stats_messages_pong_received:266666
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:533194
192.168.10.52:6379> CLUSTER INFO
cluster_state:ok # 集群状态为成功
cluster_slots_assigned:16384 # 已经全部分配完成
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:266757
cluster_stats_messages_pong_sent:266531
cluster_stats_messages_meet_sent:10
cluster_stats_messages_sent:533298
cluster_stats_messages_ping_received:266530
cluster_stats_messages_pong_received:266667
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:533198
综上可知,当全部槽位分配完成之后,集群还是可行的,如果我们手欠,移除一个槽位,那么集群就立马那不行了,自己去试试吧 ——CLUSTER DELSLOTS 0 。
5.如何变成高可用性
以上我们已经搭建了一套完整的可运行的redis cluster,但是每个节点都是单点,这样子可能出现,一个节点挂掉,整个集群因为槽位分配不完全而崩溃,因此,我们需要为每个节点配置副本备用节点。
前面我们已经提前创建了6个备用节点,搭建集群花了三个,因此还有剩下三个直接可以用来做备用副本。
192.168.10.52:6379> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 # 总共6个节点
cluster_size:3 # 集群为 3 个节点
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:270127
cluster_stats_messages_pong_sent:269893
cluster_stats_messages_meet_sent:10
cluster_stats_messages_sent:540030
cluster_stats_messages_ping_received:269892
cluster_stats_messages_pong_received:270037
cluster_stats_messages_meet_received:1
cluster_stats_messages_received:539930
查看所有节点的id
192.168.10.52:6379> CLUSTER NODES
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master - 0 1528704114535 1 connected 5462-10922
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528704114000 0 connected 10923-16383
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 master - 0 1528704114023 5 connected
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 master - 0 1528704115544 4 connected
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 master - 0 1528704114836 3 connected
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 myself,master - 0 1528704115000 2 connected 0-5461
编写脚本,添加副本节点
[root@etcd2 tmp]# vi addSlaveNodes.sh
#!/bin/bash
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6382 -a 123456 CLUSTER REPLICATE 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6383 -a 123456 CLUSTER REPLICATE 54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c
/usr/local/bin/redis-cli -h 192.168.10.52 -p 6384 -a 123456 CLUSTER REPLICATE f45f9109f2297a83b1ac36f9e1db5e70bbc174ab
注意:
1、作为备用的节点,必须是未分配槽位的,否者会操作失败 (error) ERR To set a master the node must be empty and without assigned slots 。
2、需要从需要添加的节点上面执行操作,CLUSTER REPLICATE [node_id] ,使当前节点成为 node_id 的副本节点。
3、添加从节点(集群复制),复制的原理和单机的Redis复制原理一样,区别是:集群下的从节点也需要运行在cluster模式下,要先添加到集群里面,再做复制。
查看所有节点信息:
192.168.10.52:6379> CLUSTER NODES
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master - 0 1528705604149 1 connected 5462-10922
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528705603545 0 connected 10923-16383
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 slave f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 0 1528705603144 5 connected
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 slave 54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 0 1528705603000 4 connected
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 slave 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 0 1528705603000 3 connected
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 myself,master - 0 1528705602000 2 connected 0-5461
可以看到我们现在实现了三主三从的一个高可用集群。
6.高可用测试——故障转移
查看当前运行状态:
192.168.10.52:6379> CLUSTER NODES
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master - 0 1528705604149 1 connected 5462-10922
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528705603545 0 connected 10923-16383
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 slave f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 0 1528705603144 5 connected
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 slave 54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 0 1528705603000 4 connected
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 slave 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 0 1528705603000 3 connected
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 myself,master - 0 1528705602000 2 connected 0-5461
以上,运行正常
尝试关闭一个master,选择端口为6380的容器,停掉之后:
192.168.10.52:6379> CLUSTER NODES
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master,fail - 1528706408935 1528706408000 1 connected 5462-10922
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528706463000 0 connected 10923-16383
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 slave f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 0 1528706462980 5 connected
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 slave 54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 0 1528706463000 4 connected
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 slave 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 0 1528706463985 3 connected
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 myself,master - 0 1528706462000 2 connected 0-5461
192.168.10.52:6379>
192.168.10.52:6379> CLUSTER INFO
cluster_state:fail
cluster_slots_assigned:16384
cluster_slots_ok:10923
cluster_slots_pfail:0
cluster_slots_fail:5461
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:275112
cluster_stats_messages_pong_sent:274819
cluster_stats_messages_meet_sent:10
cluster_stats_messages_fail_sent:5
cluster_stats_messages_sent:549946
cluster_stats_messages_ping_received:274818
cluster_stats_messages_pong_received:275004
cluster_stats_messages_meet_received:1
cluster_stats_messages_fail_received:1
cluster_stats_messages_received:549824
以上,发现整个集群都失败了,从节点没有自动升级为主节点,怎么回事??
重启停掉的容器,经排查日志信息 [root@df6ebce6f12a /]# tail -f /var/log/redis/redis-server.log :
1:S 11 Jun 09:57:46.712 # Cluster state changed: ok
1:S 11 Jun 09:57:46.718 * (Non critical) Master does not understand REPLCONF listening-port: -NOAUTH Authentication required.
1:S 11 Jun 09:57:46.718 * (Non critical) Master does not understand REPLCONF capa: -NOAUTH Authentication required.
1:S 11 Jun 09:57:46.719 * Partial resynchronization not possible (no cached master)
1:S 11 Jun 09:57:46.719 # Unexpected reply to PSYNC from master: -NOAUTH Authentication required.
1:S 11 Jun 09:57:46.719 * Retrying with SYNC...
1:S 11 Jun 09:57:46.719 # MASTER aborted replication with an error: NOAUTH Authentication required.
1:S 11 Jun 09:57:46.782 * Connecting to MASTER 172.17.0.6:6379
1:S 11 Jun 09:57:46.782 * MASTER <-> SLAVE sync started
1:S 11 Jun 09:57:46.782 * Non blocking connect for SYNC fired the event.
可以看到,主从之间访问需要auth,之前忘记了配置 redis.conf 中的 # masterauth
有时候需要实施人工故障转移
登录6380端口的从节点:6383,执行 CLUSTER FAILOVER 命令:
192.168.10.52:6383> CLUSTER FAILOVER
(error) ERR Master is down or failed, please use CLUSTER FAILOVER FORCE
发现因为master已经down了,所以我们需要执行强制转移
192.168.10.52:6383> CLUSTER FAILOVER FORCE
OK
查看当前 cluster node 情况:
192.168.10.52:6383> CLUSTER NODES
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 slave 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 0 1528707535332 3 connected
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 slave f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 0 1528707534829 5 connected
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528707534527 0 connected 10923-16383
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 myself,master - 0 1528707535000 6 connected 5462-10922
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 master - 0 1528707535834 2 connected 0-5461
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 master,fail - 1528707472833 1528707472000 1 connected
从节点已经升级为master节点。这时候,我们尝试重启了,6380节点的redis(其实是重新启动停掉的容器):
192.168.10.52:6383> CLUSTER NODES
0bbdc4176884ef0e3bb9b2e7d03d91b0e7e11f44 172.17.0.5:6379@16379 slave 760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 0 1528707556044 3 connected
ae86224a3bc29c4854719c83979cb7506f37787a 172.17.0.7:6379@16379 slave f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 0 1528707555000 5 connected
f45f9109f2297a83b1ac36f9e1db5e70bbc174ab 172.17.0.4:6379@16379 master - 0 1528707556000 0 connected 10923-16383
98aebcfe42d8aaa8a3375e4a16707107dc9da683 172.17.0.6:6379@16379 myself,master - 0 1528707556000 6 connected 5462-10922
760e4d0039c5ac13d04aa4791c9e6dc28544d7c7 172.17.0.2:6379@16379 master - 0 1528707556000 2 connected 0-5461
54cb5c2eb8e5f5aed2d2f7843f75a9284ef6785c 172.17.0.3:6379@16379 slave 98aebcfe42d8aaa8a3375e4a16707107dc9da683 0 1528707556547 6 connected
我们发现,6380节点反而变成了 6383节点的从节点。
现在集群应该是完整的了,所以,集群状态应该已经恢复了,我们查看下:
192.168.10.52:6383> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:6
cluster_stats_messages_ping_sent:19419
cluster_stats_messages_pong_sent:19443
cluster_stats_messages_meet_sent:1
cluster_stats_messages_auth-req_sent:5
cluster_stats_messages_update_sent:1
cluster_stats_messages_sent:38869
cluster_stats_messages_ping_received:19433
cluster_stats_messages_pong_received:19187
cluster_stats_messages_meet_received:5
cluster_stats_messages_fail_received:4
cluster_stats_messages_auth-ack_received:2
cluster_stats_messages_received:38631
OK,没有问题。
7.集群访问
客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如 get key ,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端,客户端可以去该节点执行命令
192.168.10.52:6383> get hello
(error) MOVED 866 172.17.0.2:6379
192.168.10.52:6379> set number 20004
(error) MOVED 7743 172.17.0.3:6379
另外,redis集群版只使用db0,select命令虽然能够支持select 0。其他的db都会返回错误。
192.168.10.52:6383> select 0
OK
192.168.10.52:6383> select 1
(error) ERR SELECT is not allowed in cluster mode
报错问题
docker redis集群连接报错的问题,具体报错如下:
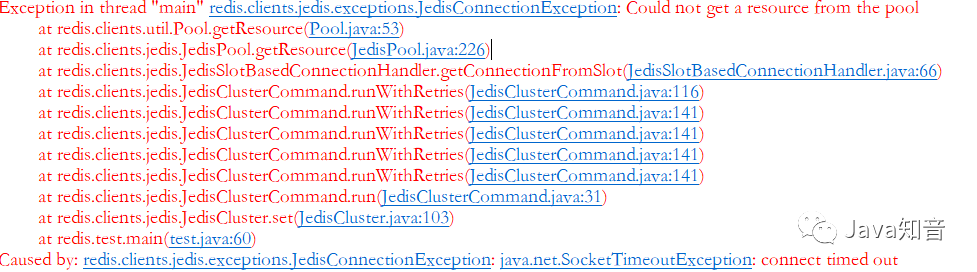
node节点没有全部添加进去,添加之后,依然有上述问题。想到是跨主机访问,应该是路由寻址不了导致的。当初写上述教程的时候,docker是以默认的网络模式bridge模式运行的,毕竟当初是以学习整理文档为主,主要是单机访问。
但是,实际应用化场景中,多是公网跨主机访问,问题明朗了,想着集群这东西最好还是设置成共享主机公网ip比较好,于是解决如下:
1.在docker运行时,执行网络模式为:host。
2.端口冲突解决,毕竟host模式下,容器会占用宿主机的端口,于是,我们就从配置下手,在宿主机上生成配置redis-60001.conf,redis-60002.conf,redis-60003.conf…,有多少端口建多少个文件,最终运行一个容器,挂载一个配置到容器中用于覆盖主机中的配置。
最终的运行方式如下:
docker run -d --name redis-6380 --net host -v /tmp/redis.conf:/usr/local/redis/redis.conf hakimdstx/nodes-redis:4.0.1
至此,网络问题得到解决。
PS.生产环境需要注意防火墙问题,不然也是会报错的。
参考
https://www.cnblogs.com/zhoujinyi/p/6477133.html
http://www.cnblogs.com/vipzhou/p/8580495.html
END
Java面试题专栏
【51期】一道阿里面试题:说说你知道的关于BeanFactory和FactoryBean的区别
【52期】记一道简单的Java面试题,但答错率很高!
【53期】面试官:谈一下数据库分库分表之后,你是如何解决事务问题?
【54期】Java序列化三连问,是什么?为什么需要?如何实现?
【55期】面试中经常被问到Java引用类型原理,带你深入剖析
【56期】你说你熟悉并发编程,那么你说说Java锁有哪些种类,以及区别
【57期】面试官问,MySQL建索引需要遵循哪些原则呢?
【58期】盘点那些面试中最常问的MySQL问题,第一弹!
【59期】MySQL索引是如何提高查询效率的呢?(MySQL面试第二弹)
【60期】事务隔离级别中的可重复读能防幻读吗?(MySQL面试第三弹)

我知道你 “在看”