每日一学--如何处理缺失值
https://www.kaggle.com/rtatman/data-cleaning-challenge-handling-missing-values
今天学习kaggle上的缺失值处理课程,学习记录,可能不太严谨,请指正。
1.观察
观察几个样本数据或者所有数据有无NaN 或者None
1.1读取数据,显示数据,肉眼观察

1.2 python中用下列方法
a.data.isnull( ) ----对整体的series或者dataframe判断
isnan(data) ----对某一行进行判断(这里我也不是特别明白)
二者返回False和True,False代表没有缺失值,True代表有缺失值
参考:https://blog.csdn.net/xidianliutingting/article/details/62041891
b.统计有多少缺失值
missing_count = data.isnull( ).sum( )
返回每列中缺失值个数
c.统计缺失值占比
total = np.product(data.shape) ---计算矩阵一共有多少个元素,行数乘以列数
missing = missing_count.sum( ) ---总共的缺失值的个数
(missing / total )*100 ---缺失值占比(该统计用于判断如何更好地处理缺失值)
2.判断
判断为什么有有缺失值
2.1 确实不存在
2.2 未被记录
3.处理缺失值
3.1 整行或者整列删除(一般不推荐该方法)
data.dropna( ) 或者 data.dropna(axis=0) 按行删除,如果有缺失值的话,就把整行删除
data.dropna(axis = 1) 按列删除
3.2 数据补齐
3.2.1用“0”值代替缺失值(用值代替缺失值称为imputation)
data.fillna(0)
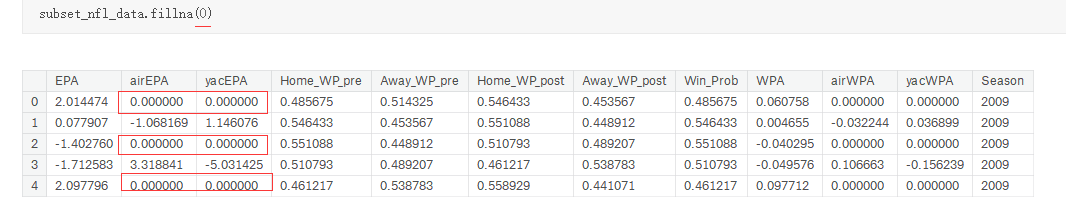
3.2.2 用同一列或者同一行的值代替缺失值
data.fillna(method = 'bfill',axis=0) ---将缺失值同一列后一行的值赋值给缺失值,对于没有后一行的值仍然是缺失值

data.fillna(method = 'bfill',axis=0).fillna(0) ---将缺失值同一列后一行的值赋值给缺失值,对于没有后一行的值用“0”填充
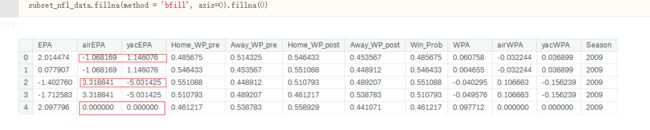
data.fillna(method = 'bfill',axis=1).fillna(0) ---将缺失值同一列后一行的值赋值给缺失值,对于没有后一行的值用“0”填充

fillna 的用法可以参见
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.fillna.html
主要说下其中参数method:backfill/bfill:同列或者同行后一值填充,pad/ffill:同列或者同行前一值填充,默认是None(None这边的意思是?看具体用什么值填充吗?如果fillna()括号里没有值的话会报错的)
3.2.3 用均值、中位数、众数代替NaN值
参见:https://www.kaggle.com/dansbecker/handling-missing-values
Imputer 用法
from sklearn.preprocessing import Imputer
my_Imputer = Imputer( )
data_imputer = my_Imputer.fit_transform(data)
imputer参数中有个strategy:mean(用均值填充),median(用中位数填充),most_frquent(用众数填充),默认值是mean,用均值填充
3.2.4 有时3.4的方法得到的替代值高于或者低于实际值(可能有些真实值并未采集到,在数据中无法体现),或者缺失值在某方面具有唯一性。(直译,还没完全理解该方法)
a.复制数据以防更改原数据
new_data = data.copy( )
b.新增一列,推算出缺失值可能的值
cols_with_missing = (col for col in new_data.columns
if new_data[c],isnull( ).any( ))
for col in cols_with_missing:
new_data[col+'_was_missing'] = new_data[col].isnull( )
my_imputer = Imputer( )
new_data = my_imputer.fit_transform
还有其他很多处理方法,详见:http://blog.sina.com.cn/s/blog_670445240102v08m.html
3.3 不处理
直接在包含空值的数据上进行数据挖掘。这类方法包括贝叶斯网络和人工神经网络等。
贝叶斯网络是用来表示变量间连接概率的图形模式,它提供了一种自然的表示因果信息的方法,用来发现数据间的潜在关系。在这个网络中,用节点表示变量,有向边表示变量间的依赖关系。贝叶斯网络仅适合于对领域知识具有一定了解的情况,至少对变量间的依赖关系较清楚的情况。否则直接从数据中学习贝叶斯网的结构不但复杂性较高(随着变量的增加,指数级增加),网络维护代价昂贵,而且它的估计参数较多,为系统带来了高方差,影响了它的预测精度。当在任何一个对象中的缺失值数量很大时,存在指数爆炸的危险。
人工神经网络可以有效的对付空值,但人工神经网络在这方面的研究还有待进一步深入展开。人工神经网络方法在数据挖掘应用中的局限性。这种做法的缺点是在模型的选择上有局限