考试总结
二简述题
题目一:scala 源于java 但高于java
Scala 的 类和方法的修饰符与java 不同
Scala 默认是public java 默认是protected
Java 支持接口 scala 不支持接口 采用trait
Scala 支持函数式编程
题目二:rdd 不支持sparlsql
DataFrame = rdd + schema
Dataset = rdd + schema
DataFrame = Dataset[Row]
题目三:自定义分区器。
提高shuffle操作的并行度。说白了就是增多分区的个数。让Task增多。让之前一个分区中的数据分散成多个分区
加盐打散数据局部聚合、去盐再全局聚合
题目四:collect把executor中的数据,收集到driver端
fitler并不会改变分区的数量,之前有几个,现在仍然有几个分区
flatMap: map之后,再flatten
reduce展示的结果数据,是没有顺序的
reducebykey 按key 聚合计算
sortBy:按照指定的条件进行排序
foreach: 迭代的是每一条数据,在数据所在的executor 中打印结果
题目五:避免创建重复的RDD
对多次使用的RDD进行缓冲持久化
尽量避免使用shuffle类算子(广播变量)
使用性能较高的算子
题目六:累加器使得变量在driver 端有了分布式计数功能
广播变量是在driver端给每个executor 发送一个
题目七:
Blink是Flink的一个分支版本
Blink对flink 进行改进了Table API更强大的YARN模式
题目八:spark 是以批处理为根本在此基础上做的流计算
Flink 是以流计算为根本在此基础上做的批处理
Spark基于微批处理方式需要同步,无法在延时上做到极致
在大数据低延时场景flink有很大优势
题目九:
求之前行到当前行的pv和。不加范围限定,默认也是这种
sum(pv) over()
求之前行到当前行的pv平均值。不加范围限定,默认也是这种
avg(pv) over()
求之前行到当前行的pv最小值。不加范围限定,默认也是这种
min(pv) over()
求之前行到当前行的pv最大值。不加范围限定,默认也是这种
max(pv) over()
row_number() over()
分组排序,并记录名次,一般用来取前n名
题目十:
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值的hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
分区就是表目录中的一个子目录。
三编程题
题目一
第(1)file.txt
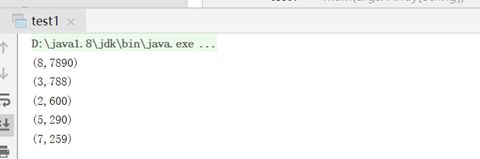
object test1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master(“local[1]”)
.getOrCreate()
val ssc = session.sparkContext
val SourceFile = ssc.textFile(“C:\Users\Jerry\Desktop\作业\考試0314\file1.txt”)
SourceFile.map(line=>{
val splits = line.split(",")
(splits(0),splits(2).toInt)
}).sortBy(-_._2)
.take(5)
.foreach(println)
}
}
file2.txt
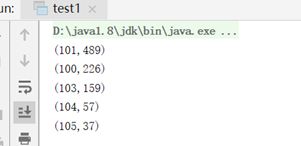
object test1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master(“local[1]”)
.getOrCreate()
val ssc = session.sparkContext
val SourceFile = ssc.textFile(“C:\Users\Jerry\Desktop\作业\考試0314\file2.txt”)
SourceFile.map(line=>{
val splits = line.split(",",-1)
(splits(0),splits(2).toInt)
}).sortBy(-_._2)
.take(5)
.foreach(println)
}
}
第(2)file1.txt
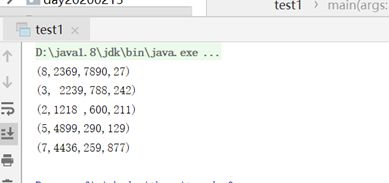
object test1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master(“local[1]”)
.getOrCreate()
val ssc = session.sparkContext
val SourceFile = ssc.textFile(“C:\Users\Jerry\Desktop\作业\考試0314\file1.txt”)
SourceFile.map(line=>{
val splits = line.split(",")
(splits(0),splits(1),splits(2).toInt,splits(3))
}).sortBy(-_._3)
.take(5)
.foreach(println)
}
}
file2.txt
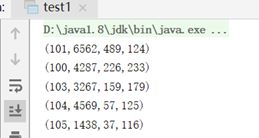
object test1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master(“local[1]”)
.getOrCreate()
val ssc = session.sparkContext
val SourceFile = ssc.textFile(“C:\Users\Jerry\Desktop\作业\考試0314\file2.txt”)
SourceFile.map(line=>{
val splits = line.split(",",-1)
(splits(0),splits(1),splits(2).toInt,splits(3))
}).sortBy(-_._3)
.take(5)
.foreach(println)
}
}
第(3)
题目二
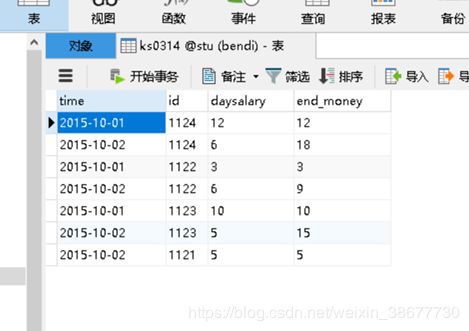
object test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster(“local”).setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
val sQLContext = new SQLContext(sc)
import sQLContext.implicits._
val SourceFile = sc.textFile(“C:\Users\Jerry\Desktop\作业\考試0314\test2.txt”)
val df = SourceFile.map(line => {
val splits = line.split(",", -1)
(splits(0), splits(1), splits(2))
}).toDF(“time”, “id”, “salary”)
df.createTempView(“sales “)
val result = sQLContext.sql(
“””
select time ,id,daysalary,
sum(daysalary) over(partition by id order by time ) end_money
from
(select time,id,sum(salary) as daysalary from sales
group by time,id)
“””.stripMargin)
val url:String="jdbc:mysql://localhost:3306/stu?characterEncoding=utf-8&serverTimezone=Asia/Shanghai"
val table:String="ks0314"
val conn = new Properties()
conn.setProperty("user","root")
conn.setProperty("password","123")
conn.setProperty("driver","com.mysql.jdbc.Driver")
result.write.mode(SaveMode.Overwrite).jdbc(url,table,conn)
sc.stop()
}
}