Kaggle KNN实现Digit Recognizer
本文参考了https://blog.csdn.net/u012162613/article/details/41929171,然后总结一下自己的理解。主要从数据准备、数据分析、核心算法三个方面介绍。
数据准备
Kaggle官网中搜索Digit Recognizer,从‘Data’中下载csv文件:train.csv,test.csv,sample_submission.csv。
从github下载knn_benchmark.csv(官方给出的参考结果,可与自己训练的结果对比)https://github.com/clytwynec/digit_recognition/blob/master/data/knn_benchmark.csv
数据分析
训练集和测试集是包含0-9共10个手写数字的灰度图像,每张图的像素是28*28=784,每个像素有一个单一的像素值,像素值是0-255的整数。
train.csv
train.csv是训练样本集,大小42001*785,第一行是文字描述,所以实际的样本数据大小是42000*785。其中第一列的每一个数字是它对应行的label,可以将第一列单独取出来,得到42000*1的向量trainLabel,剩下的就是42000*784的特征向量集trainData。代码如下:
def loadTrainData():
l=[]
with open('train.csv') as file: #open()返回了一个文件对象file
lines=csv.reader(file) #reader()返回reader()对象lines,lines是一个列表
for line in lines: #按行加入到l列表中
l.append(line) #42001*785
l.remove(l[0]) #第一行是文字描述,删除第一行
l=array(l) #列表转换为数组
label=l[:,0] #取l中所有行的第0个数据
data=l[:,1:] #取l中所有行,第一列到最后一列的数据
return nomalizing(toInt(data)),toInt(label) #label 1*42000 data 42000*784其中有两个函数需要说明一下,toInt()函数,是将字符串转换为整数,因为从csv文件读取出来的,是字符串类型的,而运算过程中需要整数类型的,因此需要转换。toInt()函数如下:
def toInt(array):
array=mat(array) #用mat()转换为矩阵之后可以进行一些线性代数的操作
m,n=shape(array)
newArray=zeros((m,n))
for i in range(m):
for j in range(n):
newArray[i,j]=int(array[i,j])
return newArraynomalizing()函数做的工作是归一化,因为train.csv里面提供的表示图像的数据是0~255的,为了简化运算,我们可以将其转化为二值图像,因此将所有非0的数字,即1~255都归一化为1。nomalizing()函数如下:
def nomalizing(array):
m,n=shape(array)
for i in range(m):
for j in range(n):
if array[i,j]!=0:
array[i,j]=1
return arraytest.csv
test.csv里的数据大小是28001*784,第一行是文字描述,因此实际的测试数据样本是28000*784,与train.csv不同,没有label,28000*784即28000个测试样本,需要做的工作就是为这28000个测试样本找出正确的label。
knn_benchmark.csv
knn_benchmark.csv里的数据是28001*2,第一行是文字说明,可以去掉,第一列表示图片序号1~28000,第二列是图片对应的数字。
核心算法
采用KNN算法来分类。K最近邻分类算法是数据挖掘分类技术中最简单的方法之一。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。本文衡量样本间的距离使用的是欧式距离。核心代码:
def classify(inX, dataSet, labels, k):
inX=mat(inX) #inX是输入的单个样本
dataSet=mat(dataSet) #训练样本集
labels=mat(labels) #对应的标签向量
dataSetSize = dataSet.shape[0] #得出dataSet的行数,即样本个数
diffMat = tile(inX, (dataSetSize,1)) - dataSet #tile(A,(m,n))将数组A作为元素构造m行n列的数组
sqDiffMat = array(diffMat)**2
sqDistances = sqDiffMat.sum(axis=1) #array.sum(axis=1)按行累加,axis=0为按列累加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort() #array.argsort()返回数组值从小到大的索引值
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i],0]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #get(key,x)从字典中获取key对应的value,没有key的话返回0
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) #sorted()函数,按照第二个元素即次序逆向(reverse=True)排序
return sortedClassCount[0][0]简单说明一下,inX就是输入的单个样本,是一个特征向量。dataSet是训练样本,对应上面的trainData,labels对应trainLabel,k是knn算法选定的k,一般选择0~20之间的数字。这个函数将返回inX的label,即图片inX对应的数字。
对于测试集里28000个样本,调用28000次这个函数即可。
运行结果
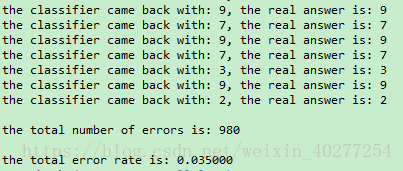
以上使用了20000个训练样本进行训练,最后预测的错误率为3.5%。