利用百度api进行文字识别
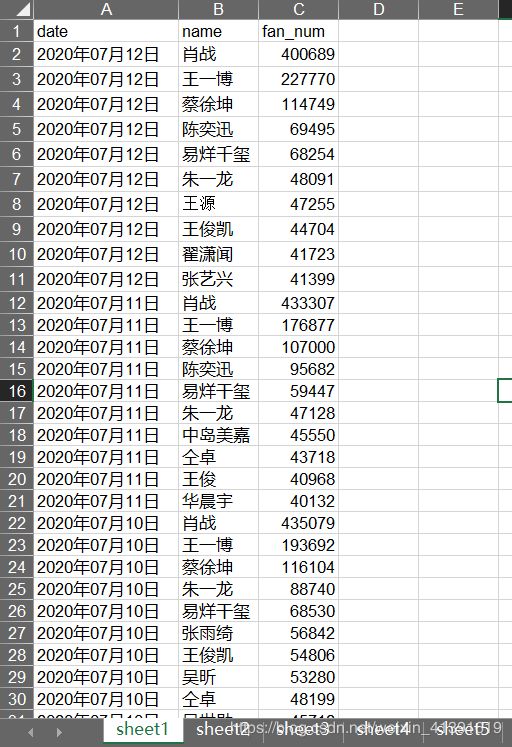
首先看看待识别的图片所在文件夹和图片本身是什么样:

我们要识别的是每张图片里的日期、前10名的艺人的姓名和粉丝人数
from aip import AipOcr
APP_ID = 'XXXX'
API_KEY = 'XXXX'
SECRET_KEY = 'XXXX'
client = AipOcr(appId=APP_ID,apiKey=API_KEY,secretKey=SECRET_KEY)
from PIL import Image
import time
import xlwt
#import xlrd
#from xlutils.copy import copy
APP_ID\API_KEY\SECRET_KEY登录百度智能云获得
date_list = []
name_list = []
fan_num_list = []
start = 0
for i in range(start,start+35): #每次识别35张图片
img = Image.open('./pic/{}.jpg'.format(i)) #截取图片中的日期部分
date = img.crop((100,100,320,150)).save('date.jpg')
date = (client.basicGeneral(open('date.jpg','rb').read())).get('words_result')[0]['words'] #进行图片识别,并拿到识别结果
if '年' in date and '月' in date and '日' in date: #这个条件保证我们识别的是日榜的图片,而不是周榜、月榜的图片
date_list.append(date)
name_in_oneday = []
fan_num_in_oneday = []
for j in range(10): #10:只要每张图片里前10个艺人的信息
name_box = (150,270+j*106.7,260,295+j*106.7)
name = img.crop((name_box)).save('name.jpg')
name = client.basicGeneral(open('name.jpg','rb').read())
name = name.get('words_result')
if name == []: #如果未识别出该艺人的姓名
name_in_oneday.append('未识别出')
print('name',i,date,j+1)
else:
name_in_oneday.append(name[0]['words'])
time.sleep(1)
for j in range(10):
fan_num_box = (500,288+j*106.7,600,313+j*106.7)
fan_num = img.crop((fan_num_box)).save('fan_num.jpg')
fan_num = client.basicGeneral(open('fan_num.jpg','rb').read())
fan_num = fan_num.get('words_result')
if fan_num==[]:
fan_num_in_oneday.append(0)
print('fan_num',i,date,j+1)
else:
fan_num_in_oneday.append(fan_num[0]['words'])
time.sleep(1)
name_list.append(name_in_oneday)
fan_num_list.append(fan_num_in_oneday)
#一个workbook里建立5张sheet 每张sheet包含一周(7天)的信息
workbook = xlwt.Workbook(encoding='utf-8')
sheet1 = workbook.add_sheet('sheet1')
sheet2 = workbook.add_sheet('sheet2')
sheet3 = workbook.add_sheet('sheet3')
sheet4 = workbook.add_sheet('sheet4')
sheet5 = workbook.add_sheet('sheet5')
sheet_list = [sheet1,sheet2,sheet3,sheet4,sheet5]
for sheet in sheet_list:
sheet.write(0,0,'date')
sheet.write(0,1,'name')
sheet.write(0,2,'fan_num')
for sheet_num in range(len(sheet_list)):
sheet = sheet_list[sheet_num]
for i in range(7): #7:一周7天
for j in range(10): #10:每天10个艺人的信息
sheet.write(10*i+j+1,0,date_list[sheet_num*7+i])
sheet.write(10*i+j+1,1,name_list[sheet_num*7+i][j])
try:
fan_num = int(fan_num_list[sheet_num*7+i][j].replace(',','').replace('.','').replace(':','').replace('、',''))
except:
fan_num = fan_num_list[sheet_num*7+i][j]
sheet.write(10*i+j+1,2,fan_num)
workbook.save('workbook1.xls')
1.为什么每次只识别35张图片?
-这是百度api和电脑本身的性能决定的。多次实验发现,图片数目多了的话,识别的准确率会降低,并且容易报错。如果你想识别70张图片,
那么就运行两次,第二个workbook保存为workbook2.xls就可以。
2.为什么艺人的姓名和粉丝人数要一个一个地切割出来识别,不能一张图片里所有艺人的信息同时识别吗?
-可以同时识别,但是有时识别出来的准确率超级低,保险起见,我们就一个一个切割出来之后再识别
3.为什么要time.sleep?
-也是这个api和电脑本身性能决定的。多次实验发现,连续进行识别时,容易报错;但是每次识别后歇一下,报错的概率大大下降(我也不知道为什么)