
从零开始入门推荐算法工程师
点击上方“大数据与人工智能”,“星标或置顶公众号”
第一时间获取好内容

作者丨gongyouliu
作者在《推荐算法工程师的成长之道》这篇文章中讲到推荐算法工程师是一个好的职业选择,并且讲解了职业发展路径及定位、怎么成长等话题(还没看的可以看起来)。
如果大家认可我讲的并且也愿意将来从事推荐算法的工作,但是不知道需要学什么才可以更好地入门,那么你一定要读读这篇文章。
在本篇文章中,作者基于自己近10年的大数据与推荐系统项目经验来讲讲我们该怎么入门推荐算法工程师,怎样更容易找一个推荐算法的职位,以及找到相关职位后怎么更快的融入工作。
希望本文对于毕业后想从事推荐算法的学生以及有工作经验但是准备转行推荐算法的读者提供一些指导。让大家可以轻松应对面试,入职时快速上手。
本文从我自己的学习成长经历、如何判断自己是否适合从事推荐算法、推荐算法工程师需要的知识储备、怎么找一份合适的推荐算法工作、怎么可以更快的适应工作5个部分来讲解。
在作者正式介绍怎么入门推荐算法工程师时,先讲讲自己入门推荐算法工程师的经历,可以给大家一些启发和思考。
Part 1
作者从零开始学习推荐系统的心路历程
作者算是从零开始学习推荐系统的。2010年到2011年之间在一家公司做了一年算法工程师,其中有大半年研究了Netflix Prize相关的推荐算法(2006年Netflix公司发起了一次推荐算法竞赛,希望参赛团队可以将Netflix的推荐预测算法的RMSE提升10%,第一个做到的团队将获得100w美元大奖,最终这个奖在3年后的2009年被三个团队的混合算法拿到了),当时用matlab的分布式计算实现了几个推荐算法。算是对推荐系统的初步入门。
然后2012年9月份加入现在的公司,从零开始搭建大数据平台和推荐系统,一直到现在。虽然之前做过半年的推荐算法研究,但是作者当时对Java编程是零基础,也从未学习过大数据相关技术,对机器学习也不太了解,所有这些都需要从零开始学习。当时公司没有一个人懂大数据与推荐系统,学习难度可想而知。
好在作者学的是数学专业,自认为数学学得不错,自学能力强。经过自己多年的努力学习和实践,看过大量相关的书和材料,参加过很多线下的分享,通过无数次的掉坑与填坑,边学习、边实践、边总结,最终对大数据与推荐系统有了比较全面深入的了解。
我自己的整个学习过程是比较曲折的,写作本文及这一系列公众号文章的目的也是想通过自己的经验帮助更多有志于从事推荐系统的读者可以少走弯路,尽快成长起来。
经过近10年的学习成长,我发现自己还是非常喜欢这个职业的,并且自认为做得还可以。那么是不是推荐算法就没有门槛,所有人都适合从事推荐算法呢?其实是不一定的,要想在这个方向上做得好,是有一定前提条件的。
Part 2
如何判断自己是否适合从事推荐算法
推荐算法工程师对数学、机器学习、编程等技能都有一定的要求,在这些方面是需要有一定基础的。如果想做好推荐算法,还是有一定难度的。如果你这些方面基础还不错,并且对推荐算法也非常感兴趣,那么你将推荐算法作为自己的职业是比较好的选择。
但是如果你不具备上面这些基础(比如数学基础太差、非常讨厌数学等),但是觉得推荐算法工资高,现在是人工智能时代,推荐算法职位很火,完全凭工资和追热点去选择推荐算法,那么你很难在这个职位上做的好。
作者强烈建议数学基础需要足够好才更适合做推荐系统,否则很难在这个领域做到足够深,后面肯定会遇到瓶颈的。如果数学基础太差或者非常不喜欢数学,就不要选择推荐算法作为自己的终生职业了。
推荐系统是一门实用的综合性学科,构建一套完善的、对业务产生价值的推荐系统需要了解很多知识、掌握大量相关技术,并且需要不断思考、不断总结,结合产品的发展和用户的诉求,逐步完善,好的推荐系统不是一天建成的,是一个持续优化和迭代的过程。下面对构建推荐系统需要的知识储备做一个比较全面的说明,方便立志从事推荐系统研发并将推荐系统作为自己事业的读者有一个大致了解,初步指明学习的方向。
Part 3
推荐系统推荐算法工程师需要的知识储备
下面图1是一种可行的推荐系统业务流图,用户通过终端(如手机)访问推荐业务,终端调用推荐系统web服务接口(可能会用CDN加速,同时通过Nginx等web服务做反向代理),推荐接口从推荐结果库中将用户的推荐结果取出来,组装成合适的数据格式再返回用户。从另外一侧,用户在终端上的行为会通过日志收集系统收集到大数据平台,通过ETL处理进入数据仓库,我们构建推荐算法模型为用户生成推荐结果,将推荐结果通过kafka管道存入推荐库中。
我会结合该图来说明学习推荐系统需要用到哪些技术,需要学习哪些相关知识点。当然,你去一个公司做推荐算法并非一定会接触到下图的所有方面(如果是创业公司,很有可能都会接触,因为创业公司没有这么多资源招聘各个模块的人,一般一个人要顶几个人,所以覆盖的面也会更广,在大公司可能只会接触其中某一个小点)。但是如果你对所有模块有更好的认识和了解,对帮助你形成推荐系统全局认识是大有裨益的。
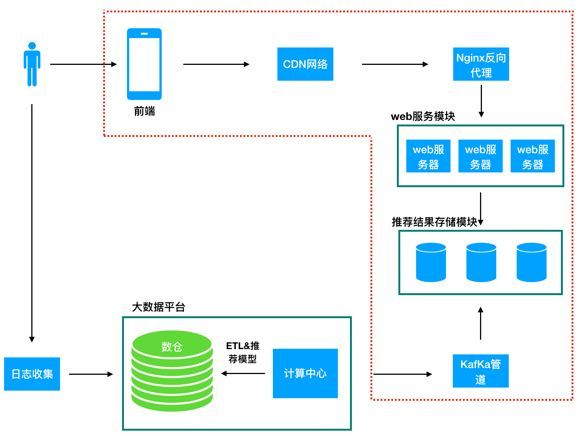 图1:推荐系统的业务流
图1:推荐系统的业务流
我们可以将上图中涉及到的知识点分为基本技能、核心技能、补充技能三大块。推荐算法工程师一般也分为偏算法类与偏工程类,偏算法类主要是根据产品特性、已有的数据资源设计一个高效可行的算法,也可能会涉及到实现相关算法,而偏工程类主要是推荐算法相关模块编码及推荐支撑模块开发等。
偏算法类的工程师需要数学基础好,机器学习理论扎实,最好有相关学术经验。偏工程类的需要编程能力强,熟悉软件架构设计、向对象思想、设计模式等,最好有开发较大工程项目的经验。
推荐算法工程师的核心技能主要是机器学习相关技术、推荐算法理论、推荐算法工程实现等。数学知识、编程知识、数据结构与算法、数据库、大数据相关知识、英文阅读能力等是基础技能。而产品UI交互、网络协议、web服务、CDN、数据交互协议等属于补充技能。
入门推荐算法工程师,基础技能和核心技能是需要学习的,如算法基础、机器学习相关技术、推荐系统相关常用算法是需要掌握的。但是为了完整性,我将推荐系统涉及到的所有知识点都罗列出来了,其他非必须掌握的知识点读者可以分阶段选择性学习。
下面我们对推荐系统涉及到的技术和知识点做一个较全面的整理说明,作为大家学习的参考指南。你可以根据刚刚提到的基本技能、核心技能、补充技能等选择性学习。
01 数学基础
数学是一切自然科学的基础,任何自然科学(甚至人文科学)的发展离不开数学的贡献,甚至有人说过一个学科发展的成熟程度与它使用数学知识的深度正相关。
要想学好推荐算法,是需要具备一定数学基础的,具体需要对如下几个领域的数学知识有所了解。
我认为只要学好大学的高等数学、线性代数、概率与统计这三门课就足够了,是完全可以应付推荐系统需要的数学储备的。
离散数学作为计算机系的必修课程,对理解计算机体系结构、更好地理解很多机器学习算法是非常有帮助的。如果你想在推荐上有更深的造诣是需要学习了解的,初学者前期可以不必花很多时间在这门课上。
a.高等数学
微积分是整个高等数学的核心,现代科技的发展得益于微积分的发明,它让整个高等数学知识在工程科技领域得到非常广泛的运用,大大促进了自然科学和工程学科的发展壮大。机器学习是计算机与数学的交叉学科,当然也离不开高等数学。
推荐模型(甚至绝大多数机器学习算法模型)其实最终可以归结为一个最优化问题。简单来说,最优化问题就是求函数极值的问题,需要利用各种数学技术来求解模型的最优参数,常用的有极大似然估计,梯度下降算法等。
深度学习的激活函数、机器学习模型的目标函数的性质我们需要了解,需要计算梯度来逐步迭代求解最优解,这些都涉及到微积分相关知识。
另外,关于算法的时间空间复杂度(比如归并排序的时间复杂度是O(nlogn))等都需要用高等数学无穷小的形式来描述。
我们需要掌握的高等数学知识主要有初等函数的基本性质、极限、积分、微分、求极值、无穷小量等。
b 线性代数
矩阵运算是非常简洁高效的一种数学运算。如果用矩阵来描述线性方程组是非常简单的(Ax=b,A是系数矩阵,b是数值向量,x是未知向量),有很多机器学习算法都利用了矩阵相关知识,如奇异值分解、降维方法等。矩阵运算非常适合在GPU等现代芯片架构上做并行处理。
推荐系统中比较出名的利用矩阵运算的算法是矩阵分解算法,深度学习中从一层到下一层的信息传递本质上就是矩阵乘法。计算相似度的余弦相似计算也需要利用向量的内积运算。
我们需要掌握基、矩阵及向量相关运算、解线性方程、正交性、特征值、特征向量等基本知识点。
c 概率统计
用于模型训练的样本可以看成是从满足某个概率分布中的一次抽样,基于该观点,任何一个推荐算法可以看成是一个概率估计问题。很多机器学习问题可以采用概率的思想来解释,最后通过极大似然估计相关参数。
很多推荐算法可以利用概率的思想来建模,推荐系统的navie bayes方法就是一种简单的利用概率方法来做推荐的算法。我们也可以将推荐系统看成是二分类问题,可以将用户是否喜欢某个标的物看成一个概率,概率值的大小代表用户喜欢的程度,从而可以用logistic回归来做推荐。贝叶斯估计也是常用的概率估计方法,在推荐系统中得到了大量的使用,比如主题模型。
我们需要掌握什么是概率、概率的计算、频率与概率的关系、常用分布、贝叶斯公式、极大似然估计、先验估计、概率密度函数、均值、方差、样本、抽样、置信度、置信区间等相关概率统计知识。
d 离散数学
学计算机专业的同学本科时必学的一门课程是离散数学,包括的内容有集合论、图论、代数结构、组合数学、数理逻辑等部分。
计算机运算本质上就是布尔代数,通过二进制数来解决所有计算问题。深度学习的神经网络模型其实就是一种有向图的结构,像滴滴打车为司机寻找最短路径到达目的地其实是图的最短路径问题。机器学习的维度灾难就是一种组合爆炸。
对于这部分的理解有助于大家更好的理解计算机体系结构及相关算法原理。
02 机器学习推荐系统是机器学习的一个分支,主要是解决为海量用户推荐标的物的问题,可以将推荐系统看成是一个监督学习问题。机器学习中的各种算法都可以用于推荐系统中,比如回归、聚类、奇异值分解、深度学习、强化学习、迁移学习等。
对传统机器学习算法有深入的了解和掌握,对学好推荐系统,对推荐系统算法的深刻理解非常有帮助。常用的聚类、分类、回归、集成学习需要有较好的掌握。
另外,对于机器学习的一些基本概念和相关知识点,如训练集、测试集、验证集、模型训练、模型推断、特征工程、模型效果评估等要有所了解和掌握。这些是构建推荐算法模型过程中一定会涉及到的概念和知识点。
03 推荐系统
既然是入门推荐算法工程师,当然需要对推荐算法有所了解了。首先,需要知道推荐系统是一种解决信息过载的技术手段,知道在什么场景下需要推荐算法、什么场景不需要推荐算法、推荐算法会面临哪些挑战、推荐算法在工业界的应用场景等。
推荐系统常用的算法有基于内容的推荐和协同过滤推荐(包括基于用户的协同过滤和基于物品的协同过滤)。对这两类算法要有比较好的理解,能够说清楚算法原理,能够大致推导这些算法的实现方案。同时,也需要知道怎么评估推荐算法的好坏,有哪些衡量推荐算法质量的指标,这些指标是怎么计算的,怎么解决推荐系统冷启动问题等。
最好可以基于一些开源的数据集,采用第三方开源机器学习框架,自己能够独立实现这些算法,这样你会理解比较深刻。
04 编程能力
推荐算法工程师除了设计算法外,可能需要将算法付诸实践,自己实现算法,即使是利用现有的算法框架做推荐,在处理数据、模型训练、模型推断等阶段也需要动手编程。所以,推荐算法工程师一定需要有一定的编程基础。
在工业界最常用的编程语言是Java语言,Java有非常成熟的生态系统,并且推荐系统前期数据处理是需要依赖大数据技术的,而大数据技术基本是基于Java(或者基于JVM的Scala语言)生态系统的。所以掌握Java/Scala开发是可以帮助你快速熟悉掌握各类大数据开源技术的。
随着深度学习驱动的第三次人工智能浪潮的到来,出现了越来越多的深度学习框架,如Tensorflow、Pytorch、MxNet等等,这些框架基本是采用python语言来跟用户交互的(底层是用C++写的),间接促使Python语言火爆起来。Python作为一个较古老的编程语言,生态相对丰富,易于学习,并且Python有非常成熟的数据处理分析库及流行的机器学习框架scikit-learn。
作为推荐算法工程师,熟悉Java/Scala、Python两类编程语言基本就够了。
05 数据结构与算法
上面一节提到了做推荐算法需要掌握编程技能,任何类型的编程都或多或少会涉及到一些数据结构与算法。我们需要了解常用的数据结构,比如集合、列表、哈希、链表等。常用的排序算法等肯定是需要掌握的。同时要对算法的时间复杂度和空间复杂度要有一定的了解。布隆过滤器,压缩算法,加密算法等更高深的算法也需要有所了解,知道他们可以解决哪些问题,在需要的时候可以通过搜索相关材料快速学习。
06 工程技能
推荐算法的实现也需要考虑很多工程问题,数据处理平台采用什么,用什么编程语言,推荐结果存储在哪里,推荐结果怎么给到用户,这些问题都需要很好的工程实现。
随着用户规模的扩大,数据量越来越大,处理数据和训练推荐模型花的时间越来越长,怎么有效的处理大规模数据和并发计算是摆在大家面前的棘手问题。
用户访问推荐页面是否有延迟,是否会开天窗,怎么应对开天窗,怎么缩短访问时长,怎么提升推荐服务的并发能力,这些问题都需要结合工程的知识和行业经验来改善和优化。
怎么设计一套高效的推荐算法组件,让整个团队开发效率更高,更容易将推荐算法落地到实际产品中,怎么在算法精准度、效率、计算复杂度上做平衡是一种工程实现的哲学。
总之,你需要有足够多的工程实践经验,才可以设计一套高效易用的、有业务价值的推荐算法体系。
07 大数据相关开源技术
推荐系统是一个系统性工程,从上面图1可以知道,要搭建一个稳定有效的推荐系统还是相当复杂的,涉及到很多知识。toC互联网产品是构建在规模用户基础上的生意,好的toC互联网产品一定是服务于大量用户的,大量用户的行为会产生海量数据,这时大数据相关技术就有了用武之地。
幸好随着互联网和信息技术的发展,随着开源技术的流行和开源社区的壮大,出现了很多优秀的开源框架,如Hadoop、Spark、Flink、Tensorflow、Pytorch等,这些框架是我们构建工业级推荐系统的基石,下面我对推荐系统需要用到的一些开源技术做一些简单介绍,方便大家了解熟悉,基于这些开源技术是非常容易构建一套推荐系统的。
a 数据收集系统
构建推荐算法模型需要依赖用户行为数据等各类数据,而这些数据来源于用户在客户端的操作,所以我们需要将这些操作日志“运输”到数据中心,这个过程就是数据收集。
大数据生态系统中常用的收集转运数据的组件有flume、kafka等。当我们将所有需要的数据收集到数据中心存下来后就可以进行处理、训练、构建推荐算法模型了。
b 数据存储系统
通过上面收集到的数据后,我们需要将数据存下来。由于互联网公司数据量很大,单台服务器一般存不下,这时就需要利用分布式数据存储技术,因此Hadoop的HDFS分布式文件系统就派上用场了。HDFS可以横向扩容,具备数据读取等常用文件操作,并且每个数据块可以保留多份副本,即使一台服务器坏了也不会丢失数据,安全可靠性极高。
在做数据分析时,我们需要更好的存储、获取、处理数据,我们一般将数据采用Parquet的数据格式存储,Parquet是基于Hadoop生态之上的一种列式数据存储格式,不管采用Hadoop生态上的什么分析组件,不管什么数据模型及编程语言,Parquet格式都可以轻松应对。Parquet对数据有比较好的压缩,可以极大减少存储资源的消耗。
另外,随着公司数据的增大,业务规模的扩大,我们会从更多的维度对数据进行分析处理,这时就有必要构建一套完善的数据仓库了,大数据社区构建数仓的组件主要有Hive和HBase。Hive是基于关系型数据库查询语言SQL的结构化数据存储组件,Hive采用表的形式存储结构化数据,利用SQL查询,非常适合批处理的数据分析形式。如果你需要对数据进行实时的分析处理,可以将数据存到HBase上,它是一种列式数据存储组件。
c 数据分析系统
随着Google在2003发表了3篇划时代意思的论文(见参考文献1,2,3),大数据逐步从萌芽到繁荣壮大,这其中最重要的大数据技术当属2006年启动的Hadoop工程,Hadoop包含HDFS和MapReduce两个组件,HDFS用于存储海量数据,可以利用廉价的服务器构建分布式集群,方便存储大量数据,并且数据有很好的容错性。而MapReduce是一个基于HDFS之上的数据分析组件。经常十几年的发展,围绕Hadoop形成了一套完善的大数据生态系统,正式Hadoop生态系统引爆了大数据浪潮。
后续陆续出现的Spark、Flink等基于Hadoop之上的数据分析软件,拓展了大数据分析的能力,这些软件的发展也壮大了整个大数据生态系统。Spark、Flink上有非常多的算子操作,同时也有相关机器学习库(Spark的mllib机器学习库包括ALS推荐算法),这些算法和库方便我们构建各种推荐模型。
08 其他支撑技术
除了上面提到的技能点外,我们还需要对下面的一些知识有所了解。这些技能点有些是构建完备的推荐系统必不可少的部分,有些是支撑推荐系统服务更好运转的基础能力。
a 数据库
在推荐系统架构中,需要将为用户生成的推荐结果存入数据库中,方便web服务提取推荐结果返回给用户,而业界主要有关系型数据库和NoSQL数据库两大类。
关系型数据库是最早被大量使用的数据库,在整个互联网发展史上占有非常重要的地位,大量用于各类公司作为最核心的数据存储(如交易数据、用户注册信息等)。关系型数据库最大的特点是采用行列的形式存储数据,类似二维的电子表格,现实生活中非常多的数据都可以抽象为这种表格的形式。从这些表格数据中操作数据(增删改查)采用SQL语言,它简单易学,非常高效。目前比较火的开源关系型数据库有MySQL和ProgreSQL等。
推荐系统虽然不直接利用关系型数据库作为最终推荐结果的存储,但是推荐的标的物相关的信息、用户相关的信息等基本会存放在关系型数据库中,推荐算法工程师至少需要了解熟悉一种关系型数据库,并且需要熟练使用SQL语言。
推荐系统每天(甚至是每分钟或者每秒)需要为每个用户计算推荐结果,如果用户量大的话,将这些推荐结果插入数据库是一个非常频繁的读写操作,采用关系型数据库是非常不合适的,这时
NoSQL就派上用场了。NoSQL采用key-value的形式存储数据,是非常适合用于存储用户的推荐结果的,key就是用户的id,value就是为用户的推荐结果。非常流行的NoSQL如CouchBase, Redis等都适合做推荐的结果存储,他们读写都是非常高效的,并且可以横向扩容。我们公司的推荐结果存储就是采用的这两个NoSQL数据库。
b 操作系统
除了微软体系外,整个互联网行业的基础架构基本是构建在Linux操作系统之上的,推荐系统的任务调度、任务监控等都是部署在linux服务器上,所以作为推荐算法工程师是需要熟悉linux操作系统的。常用的磁盘、内存、核、进程、网络、文件目录结构、基础命令等常用操作是必须熟练掌握的。
c 网络
推荐系统的结果需要存到数据库,用户访问推荐服务时需要从数据库中将推荐结果取出来,这个过程中都会涉及到数据在网络上的传输,因此需要对网络延迟、网络传输等过程有所了解。同时数据传输遵守网络协议,我们需要对http、https、tcp等网络协议有所了解。为了加速用户获取推荐结果,让用户体验更好,一般互联网公司都会通过CDN来加速用户查询过程,对CDN技术也需要有所了解。
d 互联网上常用的数据交互协议
像 json,xml,protobuf,Avro等常用的数据交互和序列化协议需要大家熟悉。特别是json,可读性强,很多互联网公司采用json格式来作为数据交互的协议,大量用于数据接口中。
e Web服务
从上面图1可以知道,用户获取推荐数据,需要通过web服务模块,该模块的作用是通过从推荐结果数据库中将用户的推荐结果取出来,组装成合适的格式返回给用户。
常用的web服务组件有基于java语言的Tomcat,基于go语言的gin、Beego,以及基于python语言的Flask等等。如果你的工作中涉及到为推荐业务开发接口,就需要对这块熟悉,否则只要知道即可。
f AB测试与指标体系
前面讲过推荐算法是一个逐步迭代优化的过程,我们需要根据公司业务场景构建一套完善的指标体系,搭建一套好用的AB测试平台来评估推荐算法的好坏及对业务的价值,通过不断优化迭代,让推荐算法朝着驱动公司业务发展的方向前进。
作为一个推荐算法工程师,在平时工作中是会经常接触到这两块的,因此是有义务也是有必要对这两块知识点有所了解的。由于这两块比较偏业务,初学者提前知道就可以了,未来在需要的时候希望可以针对性地学习。
09 实践(项目)经验
在你准备找一个推荐算法工作时,如果你有推荐或者机器学习相关项目经验,简历是更容易被选中,有更多面试机会的。我建议可以参加一些推荐或者机器学习的竞赛,比如阿里的天池竞赛。通过竞赛可以提前接触工业级的数据,提前熟悉整个算法的流程,对个人学习成长是非常有帮助的。
当然,如果你还没有毕业,在实验室做过相关项目,或者找一份相关的实习锻炼一下,对找到相关的职位也是非常有帮助的。有相关的项目经验,也会让你在入职时更容易上手。
10 产品与交互
产品是推荐系统价值呈现的载体。用户通过使用产品中推荐模块,获得推荐结果。所以推荐系统怎么和用户交互,操作是否便捷流畅,这些因素都会影响推荐系统的最终效果。往往好的UI及交互方式产生的价值比好的算法还大。
推荐算法工程师对UI展示与交互逻辑需要有一定的了解,虽然不必对这块了解太深入,知道一些基本的交互和展示逻辑有助于更好的理解推荐业务,并通过适当的算法逻辑来满足特定的UI交互。
11 英文文献阅读能力目前关于推荐系统、机器学习等计算机相关书本及学习资料,比较好的还是国外的。遇到复杂的问题,自己搞不定,也需要去google上搜索解决方案的。好的开源项目也基本是国外的,参考学习材料都是英文的。平时学习参考相关专业论文,也基本是英文的。因此为了让自己的能力得到更大的提升,需要具备读懂英文原版材料或者书籍的能力。
英文看起来比较难的就是一些专业的词汇,我建议可以尝试先看英文的,遇到不懂的单词查查,当你看完弄懂3本以上的英文参考书时,基本就具备阅读计算机行业英文文献的能力了。
至此,推荐算法工程师需要的知识储备基本讲完了,我们在下表中对相关知识点及比较好的学习资源做了一个归类整理,方便大家参考。
类别 |
知识点 |
学习材料 |
掌握程度 |
数学基础 |
高等数学 |
本科《高等数学》教材,如同济大学版 |
对基本概念、原理要比较熟悉 |
线性代数 |
本科《线性代数》教材,如同济大学版 |
||
概率与统计 |
本科《概率论与数理统计》教材,如浙大版 |
||
离散数学 |
如,普通高等教育"十一五"国家级规划教材:离散数学(第2版) |
||
机器学习 |
监督学习 无监督学习 |
周志华的《机器学习》西瓜书 李航的《统计学习方法》 |
必须掌握常用监督与无监督算法 |
推荐系统 |
推荐系统解决什么问题 什么时候需要推荐系统 推荐系统常用算法 怎么评估推荐系统 推荐系统冷启动 |
项亮的《推荐系统实践》 《推荐系统:技术、评估及高效算法》(原书第2版)
|
熟悉基于内容的推荐算法和协同过滤算法原理,并会公式推导 |
编程能力 |
Java/Scala,Python 熟悉面向对象编程 |
《计算机科学丛书:Java语言程序设计(基础篇)》 《Learning Scala》 《Python学习手册》(第4版) |
有较好的编程能力 |
数据结构与算法 |
常用数据结构 常用算法
|
图灵程序设计丛书:算法(第4版)
|
熟悉集合、列表、链表、哈希等数据结构 熟悉排序等常用算法 了解算法时间空间复杂度 |
工程技能 |
熟悉常用设计模式 |
Head First设计模式(中文版)
|
掌握常用设计模式 多读一些优秀开源软件源码,如Hadoop、Spark、Flink源码等 |
大数据相关技术 |
数据收集 |
熟悉flume、Kafka等 |
了解常用API,会使用即可 |
数据存储系统 |
熟悉HDFS、Parquet、Hive、HBase等 |
熟悉常用API,会使用 |
|
数据分析系统 |
熟悉Hadoop、Spark、Flink等 |
Spark、Flink是非常火的两个数据分析平台,需要较熟悉,会利用他们来做数据分析处理,并且他们都有相关的机器学习组件 |
|
其他支撑技术 |
数据库 |
熟悉Mysql、Redis、CouchBase等数据库 |
了解基本原理,会进行数据的crud操作[增加(Create)、读取查询(Retrieve)、更新(Update)和删除(Delete)] |
操作系统 |
鸟哥的Linux私房菜:基础学习篇(第四版) |
熟悉linux操作系统常用操作 |
|
网络 |
熟悉http、https、tcp等网络协议,对CDN有所了解 |
需要有基本的了解即可 |
|
数据交互协议 |
熟悉json,xml,protobuf,Avro等协议 |
特别是json和xml是需要了解的,会利用相关包进行处理 protobuf,Avro了解即可 |
|
web服务 |
熟悉tomcat、gin、beego、Flask等web服务框架 |
建议可以学习一下Flask,比较容易上手 |
表1:推荐系统需要具备的知识点汇总
Part 4
怎么找一份合适的推荐算法工程师的工作
如果你已经对上面介绍的技能有比较好的了解和掌握了,就可以尝试找一份推荐算法工程师的工作了。下面这些点是你在找工作之前及找工作过程中必须要思考关注的。
0 1 自己的诉求是什么
如果你刚毕业想找一份推荐算法工程师的工作,我觉得你一定要将是否能够学习成长作为自己最重要的诉求,不要太在乎短期薪资,成长性比薪资更重要。我知道很多同学之间是会比较offer的,如果别人成绩比你差但是找到的工作薪资比你高,你肯定会有一些不爽的,但是最好还是不要放在心上,不要跟别人做比较。人生是一场长跑,不要太在乎短期的利益,成长性比短期薪资更重要,一定要有这种意识。当你努力几年后有了真正的成长,往往薪资是有一个非常大的跳跃式增长的。
如果你你已经工作了好几年,是中途转推荐算法工程师,也要有一定的心里预期,可能给你的工资会比原来工资低。如果你能力足够强,在努力工作两三年后,工资一定会大幅反弹的。如果你一定要找推荐算法工程师并且还要薪资比原来高,我敢肯定你不容易找到。从用人单位的角度考虑,你工作了几年工资相对高,之前也没做过推荐算法,凭什么要你啊,还不如招聘一个刚毕业的大学生呢。
02 找什么公司什么行业
推荐算法工程师一般是互联网行业才会有的职位,或者传统行业的子公司及创新部门也会有相关的职位招聘。所以如果找推荐算法工程师,基本需要在互联网行业找,下面给出了主流的互联网行业类别及有代表性的公司,方便大家选择参考。
互联网公司种类很多,具体有如下几大主流类别:
电商类(如阿里,京东,拼多多等),搜索类(如百度、搜狗等),社交类(如微信、脉脉等),视频类(爱奇艺,腾讯视频等),广告类(阿里妈妈、腾讯广点通等),互联网金融类(陆金所,蚂蚁金服等),生活服务类(携程、美团、滴滴等),娱乐休闲类(游戏公司、网易云音乐等),新闻短视频类(头条、快手等),知识社区类(如知乎,豆瓣等),互联网医疗(如平安好医生、丁香园等),云计算(阿里云,七牛,Ucloud等),互联网教育(vipkids,英语流利说等),大数据与AI类(科大讯飞,出门问问,第四范式,face++等),招聘类(51job,boss直聘等),硬件类(地平线,小米等)等等。
大家可以结合自己的专业背景及偏好选择,我个人比较看好云计算、互联网教育、大数据与AI类垂直创业公司,未来成长空间大。
另外,关于是选择大公司还是小公司的问题,相信很多读者都在其他地方看到过对这个问题的解读,大公司做螺丝钉,但是文化制度相对健全,小公司接触面广,可以承担更大的责任,但是流程制度比较缺失。如果是大公司的核心部门肯定去大公司好,可以接触到的技术更先进,往往资源也比较多,去大公司的边缘部门个人觉得没啥意思。如果选择小公司,一定要选择成长型的创业公司,在面试时多跟公司创始人沟通交流,对该公司的行业及创始人的性格特点有较深入的了解。理想比较远大,格局大,有想法的创始人更容易成功。该公司从事的行业也必须是与大众生活息息相关(衣食住行等)的必须产业,不能太小众,否则成长性不大。
03 怎么写简历投简历我见过很多候选人,简历写得毫无特色。写简历一定要突出自己的优势和核心技能及相关项目经验。这块需要写在比较靠前的地方,并且需要写的非常清晰细致。如果自己核心技能比较缺,可以多学习,特别是项目经验,很多公司是很看重的,如果没有可以提前找一个相关的实习职位实习一段时间或者参加一些竞赛。
对于应届毕业生,简历可以按照“基本信息,学校专业,所获奖励,核心技能,项目经验,个性特长”的顺序写简历(学校较好的,可以将学校专业放到前面,学校很一般可以将学校专业放到项目经验之后),对于已经工作的可以按照“基本信息,核心技能,项目经验,学校专业,个性特长”的顺序来写简历。之所以按照这个顺序,是因为,对于应届生,用人单位往往比较看重学校专业,而对于已经工作过的候选人,用人单位更在乎的是你的核心技能和项目经验。这里再提一下,这些只是一些写简历的技巧,简历写得好虽然可以增加你面试的概率,但是能不能面试得上,还是要靠自己真本事的。
另外,真诚是做人的第一准则,简历需要保证真实,不要写一些假的项目或者经历。如果简历都伪造,那公司怎么相信你,公司如果知道了,即使入职了,被辞退的可能性也是非常大的。
简历投放的渠道有很多,校园招聘,招聘网站,内推等等,拉勾网、boss直聘、51job等是比较出名的网站。
确定了自己喜欢什么行业什么类型的公司了,就比较好投简历了。具体投哪家公司时,需要仔细看jd(工作描述),了解清楚用人单位的需求点是否跟自己匹配,如果有一些能够匹配上,我觉得就可以投了,完全匹配的上是不可能的。如果一点都不匹配我建议不要投,这是浪费大家时间。我也不建议海投简历,海投是对自己和用人单位的不负责。
04 怎么面试
简历准备好后,需要对自己简历上的内容非常熟悉,特别是简历的中提到的知识点,需要了然于心,包括相关的概念,算法,项目等。对于算法,需要了解基本原理,并且最好可以推导相关公式和算法。对于项目的实现方案,优缺点,项目中自己负责哪块,是怎么做的,是否遇到了困难,怎么解决的,最终效果,是否有优化的方案等等都需要知道。
面试前最好自己提前排练几次,可以让关系好的朋友当面试官,将排练过程录下来,让朋友多提建议,反复琢磨,回答问题的时间节奏,语气,语速,逻辑性等需要控制好。
另外,好好琢磨一下自我介绍,基本所有的面试官都会让你介绍一下自己的,自我介绍要突出自己的优势特长,简洁干练,不要拖泥带水,最好控制在3-5分钟之间。很多面试官喜欢问你的优缺点,优点大家可以讲一堆,但是缺点,很多人想了很久都答不上来。
有一个理论是说如果你在前几分钟没有给别人留下好的印象,那么你基本就没有机会了,营销学有一个很有名的电梯测验,说的是在乘电梯的30秒内清晰准确地向客户解释清楚解决方案,这也说明了在短时间内给别人留下印象的重要性。
从面试官的角度来说,希望候选人沟通能力较强,在自我介绍阶段能够抓住重点,突出自己的能力特长,给面试官留下好印象。
现场面试时 ,尽量提前规划好路线,预估时间,尽量提前15分钟到场,最好不要迟到。衣着得体,礼貌沟通。在面试交谈过程中,学会聆听,不要抢话,理解清楚再作答。在面试过程中思路要开阔,应变能力强,对于任何问题,即使自己不太会,也要给出自己的理解和思考。
面试完成后,可以主动询问面试结果,有很多公司流程很长,还有绝大部分公司觉得你不合适就不给反馈的。自己主动了解会更好一些,自己掌控节奏。
面试过程可能会遇到挫折,面试不上,不要泄气,多总结反思,针对自己不足的点,补充学习。一定要保持良好的心态,持续努力,一定会有收获的。
05 可能遇到的坑
前年李文星遇害案,充分说明了招聘网站上,有很多不法分子利用漏洞来做坏事,所以在去一个不是很知名的公司面试时需要查一下这个公司的背景,对公司的合法性做验证,看是否有负面新闻,一来保证自己的安全,二来可以侧面了解这个公司的情况,比如融资情况,股东情况,专利情况等等。这类可以查询企业情况的APP有“企查查”和“天眼查”,百度和知乎上也可以提前搜索了解。
另外,一个可能遇到的坑是公司不按照法律的规定缴纳社保、五险一金等,不过由于今年税制改革这种情况会好些,大家最好选择规范合法的公司。
还有,公司可能承若给你的职位,真正入职时却分配的是另外一个职位,这种情况确实无法完全避免。不过入职前需要跟面试官确认一下工作内容,以及目前团队情况,负责哪些业务,还需要在各种渠道了解一下这个部门相关的情况。做一个比较细致的了解,可以帮助你判断降低这种事情出现的概率。
Part 5
怎么更快地适应工作
当你通过自己努力找到了一份还算不错的推荐算法工程师的工作后,就需要尽快熟悉业务,让自己尽快上手。下面提供一些参考点帮助你更快的适应工作。
平时除了自己自学,完成领导布置的任务外,遇到实在不懂的问题需要多向同事请教,不要什么问题都不问,也不要过度依赖别人,在自己解决问题和问别人之间做好平衡。自己搞不定的问题,可以多百度,Google,知乎等搜索解决方案,需要有自己独立思考独立解决问题的能力。公司的wiki等文档系统可以多看看,从中了解公司的业务。另外,相关的源代码自己下去多读读,多学习。
平时跟同事保持良好的沟通交流,自己主动点,跟同事一起吃饭,一起聊天,尽快融入氛围,切记一个人搞自己的,这样很容易被孤立。
平时多做事,主动问一个组的同事,是否有事情需要帮忙,刚入职时,自己辛苦一下,多承担一些,可以更多的获得同事的信任。
养成良好的编码习惯,多注释,多总结,利用空余时间多学习与工作相关的技能,比如你只做推荐模型的特征提取这块,需要多学习这方面的技术,在网上搜集其他公司是怎么做的,学术上是怎么做的,保持对这块的持续关注和学习。
认真对待领导交给你的每一件事,不光将每件事做完,更应该做好,做到极致,通过一段时间的磨砺,你的能力一定会得到提升,做出成果了也会受到领导的认可,从而更容易转正,更容易得到重用。
除了认真完成领导交代的工作,学习相关专业技能外,还需要在工作中有意培养自己的软实力,比较重要的软实力有:沟通协调能力、长远规划能力、目标导向、是否能够把握问题的重点、自制力、执行力等等。在刚工作时可能不觉得这些软实力重要,但是当你工作越久、职位越高,这些能力会越重要,甚至起到决定性的作用。
当你能够完全应付工作时,走上正轨后,除了在自己做的这块逐渐深入学习了解,同时需要对整个推荐业务流(即上面图1涉及到的各个方面)做学习了解,形成自己整体的认知能力。剩下的时间就是你跟着公司业务发展一起成长了,你可以参考我写的另外一篇《推荐算法工程师的成长之道》了解该怎么学习成长。
Part 6
写在最后
至此,作者结合自己的亲身经历及思考写完了怎么入门推荐算法工程师,希望这份指南可以帮助你更好地入门,帮助你做好准备,找到一份推荐算法工程师的工作并且快速融入工作中。
-end-
参考文献:
1.《The Google File System》
2.《MapReduce: Simplified Data Processing on Large Clusters》
3.《Bigtable: A Distributed Storage System for Structured Data》
