Oracle 系列(oracle分区)
为什么要分区
表分区有以下优点:
1、数据查询:数据被存储到多个文件上,减少了I/O负载,查询速度提高。
2、数据修剪:保存历史数据非常的理想。
3、备份:将大表的数据分成多个文件,方便备份和恢复。
4、并行性:可以同时向表中进行DML操作,并行性性能提高。
创建分区空间
先创建4个测试分区,每个表空间作为一个独立分区
建议:考虑到Oracle中分区映射的实现方式,建议将表中的分区数设置为2的乘方,以便使数据均匀分布
创建分区语句格式(注意账号权限,一般账号没有权限)
create tablespace {分区名称} datafile {路径/分区名}.dbf size 大小
示例:(以下为自己装的Oracle软件使用SYS账号执行)
SYS>create tablespace partition1 datafile '/home/oracle/app/oradata/orcl/partition1.dbf' size 20m;
SYS>create tablespace partition2 datafile '/home/oracle/app/oradata/orcl/partition2.dbf' size 20m;
SYS>create tablespace partition3 datafile '/home/oracle/app/oradata/orcl/partition3.dbf' size 20m;
SYS>create tablespace partition4 datafile '/home/oracle/app/oradata/orcl/partition4.dbf' size 20m;
分区类型
1、范围分区
范围分区就是对数据表中的某个值的范围进行分区,根据某个值的范围,决定将该数据存储在哪个分区上。如根据序号分区,根据业务记录的创建日期进行分区
需求:有一个交易信息表material_transactions(存储交易时间,交易物品信息),该表未来可能数据会很庞大(近亿级数据),要求建表考虑分区。
分析:由于交易编号是个连续值,符合范围分区特点
建表分区结构:
partition by range(分区字段)(
partition 分区名称 values less than(数值) tablespace 分区空间名称,
partition 分区名称 values less than(maxvalue) tablespace 分区空间名称
);
示例:根据交易记录的序号分区建表(受数据数量限制,分区值先调小点,方便测试)
create table dinya_test(
transaction_id number primary key
,item_id number(8) not null
,item_description varchar2(300)
,trunsaction_date date not null
)partition by range(transaction_id)(
partition part_01 values less than(2) tablespace partition1,
partition part_02 values less than(4) tablespace partition2,
partition part_03 values less than(6) tablespace partition3,
partition part_04 values less than(maxvalue) tablespace partition4
);注:以上空间存储的[0,2),[2,4),[4,6),其他(maxvalue)
maxvalue 表示出上述3个区间以外的其他值
1.1 分区插入数据
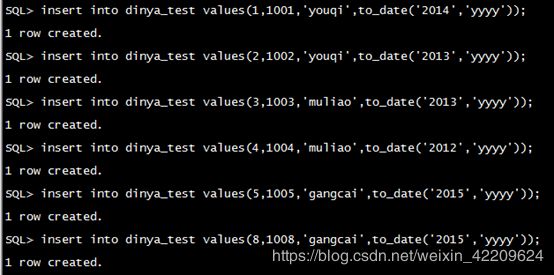
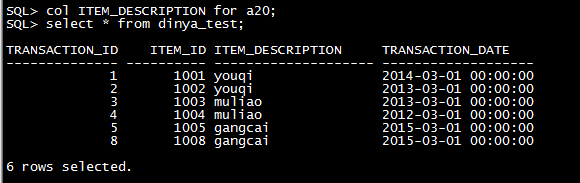
1.2 查询表数据
不指定分区:
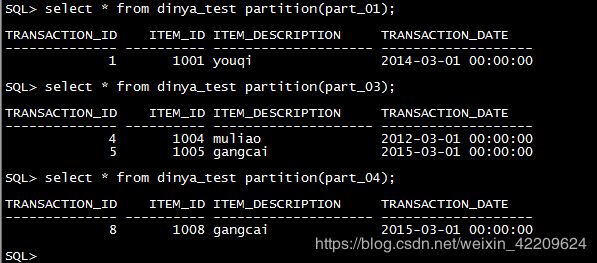
指定分区:
1.3,更改表数据

1.4,删除表数据
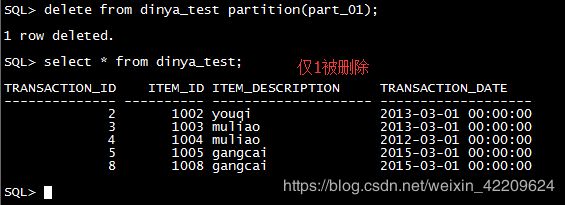
2 列表分区
列表分区告诉Oracle所有可能的值,并指定应该插入相应行的分区,它适用于表的数据量很大但是某一列的值只有少量几种。
create table dinya_test2(
transaction_id number primary key
,item_id number(8) not null
,item_description varchar2(300)
)partition by list(item_id)(
partition part_01 values (10001,10002) tablespace partition1,
partition part_02 values (10003,10004) tablespace partition1,
partition part_03 values (10005) tablespace partition1,
partition part_04 values (deafult) tablespace partition1
);
在列表分区中,可以使用关键字default来指定未列出的所有情况。(上述4个分区创建在一个表空间中)3 散列分区(hash分区)
第一种:散列分区通过在分区键值上执行一个散列函数来说决定数据的物理位置。在范围分区中,分区键的连续值通常储存在相同的分区中。而在散列分区中,连续的分区键值不必储存在相同的分区中。散列分区把记录分布在比范围分区更多的分区上,这减少了I/O争用的可能性。
create table dinya_test3(
transaction_id number primary key
,item_id number(8) not null
,item_description varchar2(300)
,trunsaction_date date
)partition by hash(transaction_id)(
partition part_01 tablespace partition1,
partition part_02 tablespace partition2,
partition part_03 tablespace partition3,
partition part_04 tablespace partition4
);第二种:partition by hash(column) partition n store in (tbs1,,,tbsm)。
表空间的数目不必等于分区的数目,即n不一定等于m,如果指定的分区数目比表空间的数目多,则分区将会以循环的方式分配到表空间中,一个表空间可以含有多个分区:
create table dinya_test4(
transaction_id number primary key
,item_id number(8) not null
,item_description varchar2(300)
,trunsaction_date date
)partition by hash(transaction_id)
partitions 4
store in(partition1,partition2);4 复合分区(子分区)
简易理解:在原有分区上再往下深入一层细分
如下示例:将交易的记录按产品金额分区,然后每个分区中的数据分三个子分区,将数据散列地存储在三个指定的表空间中
create table sale(
product_id varchar2(5)
,sale_date date
,sale_cost number(10)
,status varchar2(20)
)partition by range(sale_cost) Subpatition by list(status)(
partition p1 values less than (1) tablespace partition1
(
Subpartition p1sub1 values('Active') tablespace partition3,
Subpartition p1sub2 values('InActive') tablespace partition4
)
partition p2 values less than (3) tablespace partition2
(
Subpartition p2sub1 values('Active') tablespace partition3,
Subpartition p2sub2 values('InActive') tablespace partition4
)
);
补充:如果插入的值不在自定义的所有分区范围内,将由Oracle来分配。
分区注释:
p1:sales_cost小于1
p1sub1:sales_cost小于1,且status为Active
p1sub2:sales_cost小于1,且status为InActive
p2:sales_cost大于等于1,小于3
p2sub1:sales_cost大于等于1,小于3,且status为Active
p2sub2:sales_cost大于等于1,小于3,且status为InActive操作示例:
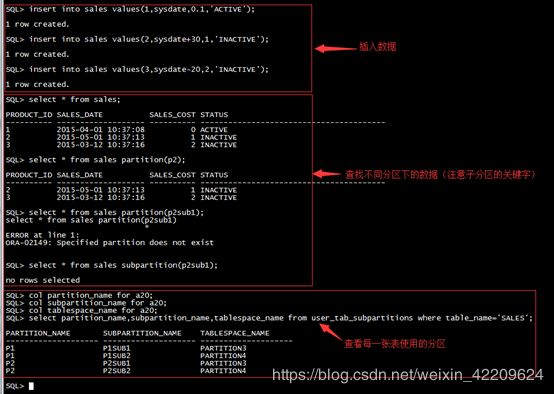
分区维护操作
1、添加分区
以下代码给SALES表添加了一个P3分区:
ALTER TABLE SALES ADD PARTITION P3 VALUES LESS THAN(TO_DATE('2003-06-01','YYYY-MM-DD'));
注意:以上添加的分区界限应该高于最后一个分区界限。
以下代码给SALES表的P3分区添加了一个P3SUB1子分区
ALTER TABLE SALES MODIFY PARTITION P3 ADD SUBPARTITION P3SUB1 VALUES('COMPLETE');
2、删除分区
ALTER TABLE SALES DROP PARTITION P3;
在测试中遇到这样的情况。如果表创建了分区,如果要删除数据文件(表空间文件),则要先删除分区,然后才能删除数据文件(但是在删除数据文件时,必须要保留一个分区才能最终删除数据文件&表空间文件)。当然,也可以直接就删除表也行,刚所有的全删除,但是表空间文件还在。
在以下代码删除了P4SUB1子分区:
ALTER TABLE SALES DROP SUBPARTITION P4SUB1;
注意:如果删除的分区是表中唯一的分区,那么此分区将不能被删除,要想删除此分区,必须先删除表。
3、截断分区
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。
ALTER TABLE SALES TRUNCATE PARTITION P2;
通过以下代码截断子分区:
ALTER TABLE SALES TRUNCATE SUBPARTITION P2SUB2;4、合并分区
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区
ALTER TABLE SALES MERGE PARTITIONS P1,P2 INTO PARTITION P2;5、拆分分区
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
ALTER TABLE SALES SBLIT PARTITION P2 AT(TO_DATE('2003-02-01','YYYY-MM-DD')) INTO (PARTITION P21,PARTITION P22);6、接合分区
结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。
ALTER TABLE SALES COALESCA PARTITION;7、重命名表分区
P21更改为P2
ALTER TABLE SALES RENAME PARTITION P21 TO P2;8、跨分区查询
select sum( *) from (
select count(*) cn from t_table_SS PARTITION (P200709_1)
union all
select count(*) cn from t_table_SS PARTITION (P200709_2)
);
9、与分区相关的表和视图:
| 分区 |
--查询表上有多少分区: SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='tableName'
--显示表分区信息 显示数据库所有分区表的详细分区信息: select * from DBA_TAB_PARTITIONS
--显示当前用户可访问的所有分区表的详细分区信息: select * from ALL_TAB_PARTITIONS
--显示当前用户所有分区表的详细分区信息: select * from USER_TAB_PARTITIONS |
| 子分区 |
--显示子分区信息 显示数据库所有组合分区表的子分区信息: select * from DBA_TAB_SUBPARTITIONS
--显示当前用户可访问的所有组合分区表的子分区信息: select * from ALL_TAB_SUBPARTITIONS
--显示当前用户所有组合分区表的子分区信息: select * from USER_TAB_SUBPARTITIONS |
| 分区表 |
--显示数据库所有分区表的信息: select * from DBA_PART_TABLES where table_name=upper('dinya_test')
--显示当前用户可访问的所有分区表信息: select * from ALL_PART_TABLES
--显示当前用户所有分区表的信息: select * from USER_PART_TABLES |
| 分区列 |
--显示分区列 显示数据库所有分区表的分区列信息: select * from DBA_PART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的分区列信息: select * from ALL_PART_KEY_COLUMNS
--显示当前用户所有分区表的分区列信息: select * from USER_PART_KEY_COLUMNS |
| 子分区列 |
--显示子分区列 显示数据库所有分区表的子分区列信息: select * from DBA_SUBPART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的子分区列信息: select * from ALL_SUBPART_KEY_COLUMNS
--显示当前用户所有分区表的子分区列信息: select * from USER_SUBPART_KEY_COLUMNS |
| 特例 |
查询出oracle数据库中所有的的分区表: select * from user_tables a where a.partitioned='YES' |
删除分区表一个分区的数据
alter table table_name truncate partition p2;
注:本文部分内容来源于很久以前网络整理的面试题文档,无源作者,若有侵权,请留言提供源地址更改。