AdaBoost公式简单版本的推导
读书随处净土,闭门即是深山。假期夜时,突然想到了《小窗幽记》这句话,补上这一篇很久之前就应该记录的笔记。
背景
集成学习
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。
集成学习在各个规模的数据集上都有很好的策略。
数据集大:划分成多个小数据集,学习多个模型进行组合
数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合
https://www.cnblogs.com/zongfa/p/9304353.html
1、Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
2、决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
AdaBoost的基本思想与举例
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。Boosting是用在弱的基分类器(erro rate小于0.5就可以)上,通过集成弱分类器,可以得到一个效果较好的综合分类器。
具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
AdaBoost算法流程
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例,而实例空间,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):

b. 计算Gm(x)在训练数据集上的分类误差率
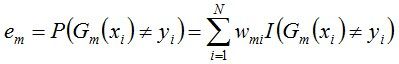
由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。
c. 计算Gm(x)的系数,am表示Gm(x)在最终分类器中的重要程度(目的:得到基本分类器在最终分类器中所占的权重。注:这个公式写成am=1/2ln((1-em)/em) 更准确,因为底数是自然对数e,故用In,写成log容易让人误以为底数是2或别的底数,下同)
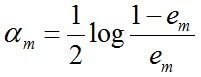
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代。
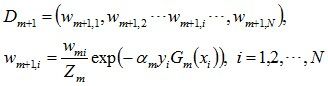
使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。这个步骤需要特别说明一下,这个公式是最后的整理版本,核心也在于此为什么am=1/2ln((1-em)/em)是这样的一个公式,以及Wm+1,i会以这样的方式更新??这样更新的目的是为了使得Wm+1这一次更新的e(m+1)即错误率占比为0.5。这一部分在后文会详细推导。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器
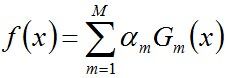
从而得到最终分类器如下:
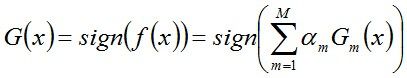
AdaBoost算法举例
给定下列训练样本,请用AdaBoost算法学习一个强分类器。
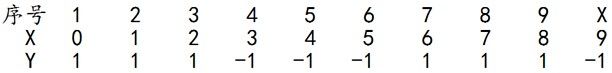
求解过程:初始化训练数据的权值分布,令每个权值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, ..., 10,然后分别对于m = 1,2,3, ...等值进行迭代。
拿到这10个数据的训练样本后,根据 X 和 Y 的对应关系,要把这10个数据分为两类,一类是“1”,一类是“-1”,根据数据的特点发现:“0 1 2”这3个数据对应的类是“1”,“3 4 5”这3个数据对应的类是“-1”,“6 7 8”这3个数据对应的类是“1”,9是比较孤独的,对应类“-1”。抛开孤独的9不讲,“0 1 2”、“3 4 5”、“6 7 8”这是3类不同的数据,分别对应的类是1、-1、1,直观上推测可知,可以找到对应的数据分界点,比如2.5、5.5、8.5 将那几类数据分成两类。当然,这只是主观臆测,下面实际计算下这个具体过程。
迭代过程1
对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
- 阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
- 阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
可以看到,无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:
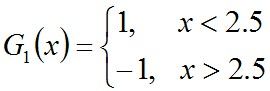
上面说阈值v取2.5时则6 7 8分错,所以误差率为0.3,更加详细的解释是:因为样本集中
- 0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
- 3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
- 但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
- 9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数: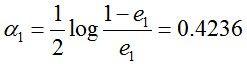
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代:
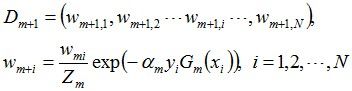
值得一提的是,由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
即如果某个样本被分错了,则yi * Gm(xi)为负,负负得正,结果使得整个式子变大(样本权值变大),否则变小。
第一轮迭代后,最后得到各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
此时,得到的第一个基本分类器sign(f1(x))在训练数据集上有3个误分类点(即6 7 8)。
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重。
迭代过程2
对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
- 阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
- 阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
所以,阈值v取8.5时误差率最低,故第二个基本分类器为: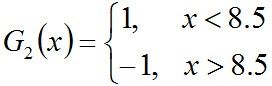
面对的还是下述样本:
很明显,G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
计算G2的系数:
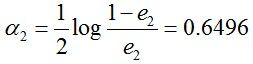
更新训练数据的权值分布:
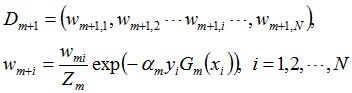
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
此时,得到的第二个基本分类器sign(f2(x))在训练数据集上有3个误分类点(即3 4 5)。
迭代过程3
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
- 阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
- 阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为:
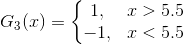
依然还是原样本:
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,
所以G3(x)在训练数据集上的误差率e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
计算G3的系数:
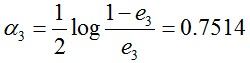
更新训练数据的权值分布:
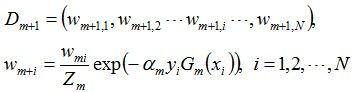
D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
现在,咱们来总结下3轮迭代下来,各个样本权值和误差率的变化,如下所示(其中,样本权值D中加了下划线的表示在上一轮中被分错的样本的新权值):
- 训练之前,各个样本的权值被初始化为D1 = (0.1, 0.1,0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1);
- 第一轮迭代中,样本“6 7 8”被分错,对应的误差率为e1=P(G1(xi)≠yi) = 3*0.1 = 0.3,此第一个基本分类器在最终的分类器中所占的权重为a1 = 0.4236。第一轮迭代过后,样本新的权值为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715);
- 第二轮迭代中,样本“3 4 5”被分错,对应的误差率为e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143,此第二个基本分类器在最终的分类器中所占的权重为a2 = 0.6496。第二轮迭代过后,样本新的权值为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455);
- 第三轮迭代中,样本“0 1 2 9”被分错,对应的误差率为e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820,此第三个基本分类器在最终的分类器中所占的权重为a3 = 0.7514。第三轮迭代过后,样本新的权值为D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。
从上述过程中可以发现,如果某些个样本被分错,它们在下一轮迭代中的权值将被增大,同时,其它被分对的样本在下一轮迭代中的权值将被减小。就这样,分错样本权值增大,分对样本权值变小,而在下一轮迭代中,总是选取让误差率最低的阈值来设计基本分类器,所以误差率e(所有被Gm(x)误分类样本的权值之和)不断降低。
综上,将上面计算得到的a1、a2、a3各值代入G(x)中,G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],得到最终的分类器为:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
AdaBoost算法推导
稍微改变一下上文的公式表述,将每一个弱分类器命名为f1(x),f2(x),f3(x)....现在的一笔数据可以表示为:![]() ,原来我们的目标函数是:
,原来我们的目标函数是:![]() ,现在变为
,现在变为 ![]() 。
。



在这里我们可以整理一下之前的符号表示和我们的目的,我们是想求d1是怎么得来的,以及上文中Wm+1与此处的U2n的更新为什么是这样的一种形式,整理如下:
我们已知:
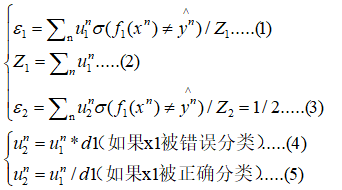
根据以上五个公式可以进行如下推导:
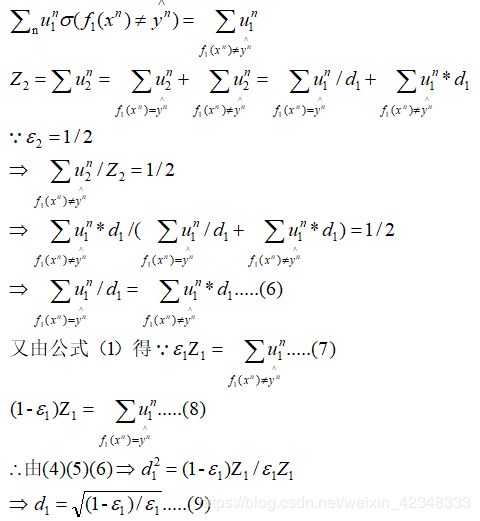
又因为我们希望把乘除合并为一个公式,所以进行如下化简:

参考:
https://blog.csdn.net/v_JULY_v/article/details/40718799
https://zhuanlan.zhihu.com/p/56634616