著名的CNN网络结构和Keras实现
一些著名的CNN网络结构总览
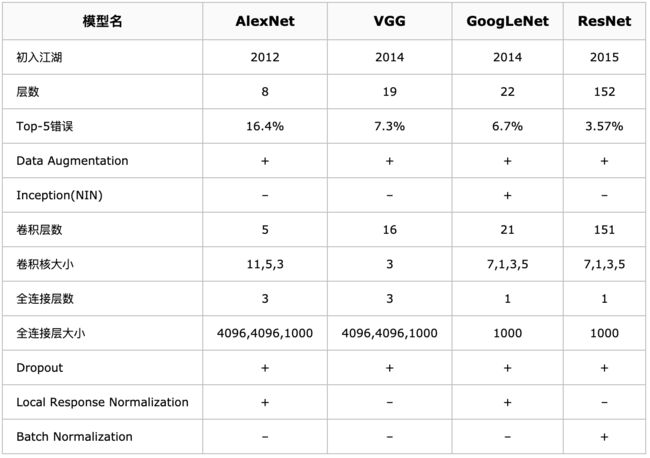
ILSVRC历年的Top-5错误率

LeNet 1989
论文《Gradient-Based Learning Applied to Document Recognition》
 A layered model composed of convolution and subsampling operations followed by a holistic representation and ultimately a classifier for handwritten digits.
A layered model composed of convolution and subsampling operations followed by a holistic representation and ultimately a classifier for handwritten digits.
LeNet是CNN的开山之作,意义:定义了CNN的基本组件,是CNN的鼻祖。
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。
LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。

LeNet - Keras版本
def LeNet():
model = Sequential()
model.add(Conv2D(32,(5,5),strides=(1,1),input_shape=(28,28,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(5,5),strides=(1,1),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(100,activation='relu'))
model.add(Dense(10,activation='softmax'))
return model
AlexNet 2012
NIPS2012 《ImageNet Classification with Deep Convolutional Neural Networks》
PaperLink
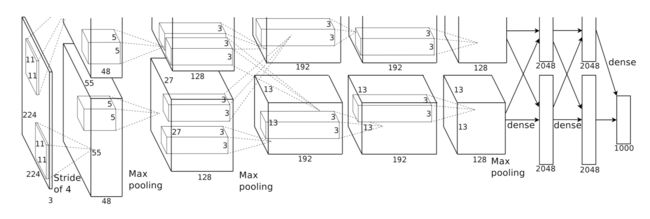
AlexNet是2012年的ImageNet竞赛冠军
主要特点:更深的网络、数据增广、ReLU、dropout、LRN
详见另一篇:https://blog.csdn.net/weixin_43318626/article/details/88895352
基本参数:
输入:224×224大小的图片,3通道
第一层卷积:11×11大小的卷积核96个,每个GPU上48个。
第一层max-pooling:2×2的核。
第二层卷积:5×5卷积核256个,每个GPU上128个。
第二层max-pooling:2×2的核。
第三层卷积:与上一层是全连接,3*3的卷积核384个。分到两个GPU上个192个。
第四层卷积:3×3的卷积核384个,两个GPU各192个。该层与上一层连接没有经过pooling层。
第五层卷积:3×3的卷积核256个,两个GPU上个128个。
第五层max-pooling:2×2的核。
第一层全连接:4096维,将第五层max-pooling的输出连接成为一个一维向量,作为该层的输入。
第二层全连接:4096维
Softmax层:输出为1000,输出的每一维都是图片属于该类别的概率。
AlexNet - Keras版本
def AlexNet():
model = Sequential()
model.add(Conv2D(96,(11,11),strides=(4,4),input_shape=(227,227,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
ZF-Net
论文 《Visualizing and Understanding Convolutional Networks》

ZFNet是2013ImageNet分类任务的冠军。
在结构上:ZF-Net只是将AlexNet第一层卷积核由11变成7,步长由4变为2,第3,4,5卷积层转变为384,384,256。
主要特点:对AlexNet进行了反卷积、特征可视化、移除某些网络层测试、遮蔽图像部分区域测试哪里是关键部位等骚操作,说是为了“理解卷积神经网络”。
ZFNet - Keras版本
def ZF_Net():
model = Sequential()
model.add(Conv2D(96,(7,7),strides=(2,2),input_shape=(224,224,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(2,2),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
VGG 2014
论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》
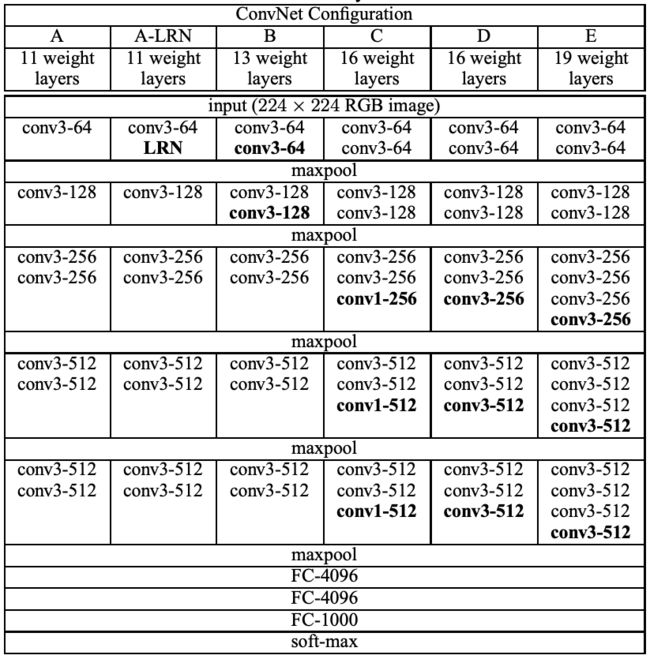
上面一个表格是描述的是VGG-Net的网络结构以及诞生过程。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,这种方式在经典的神经网络中经常见得到,就是先训练一部分小网络,然后再确保这部分网络稳定之后,再在这基础上逐渐加深。表1从左到右体现的就是这个过程,并且当网络处于D阶段的时候,效果是最优的,因此D阶段的网络也就是VGG-16了!E阶段得到的网络就是VGG-19了!VGG-16的16指的是conv+fc的总层数是16,是不包括max pool的层数!
以下为VGG-16的结构:
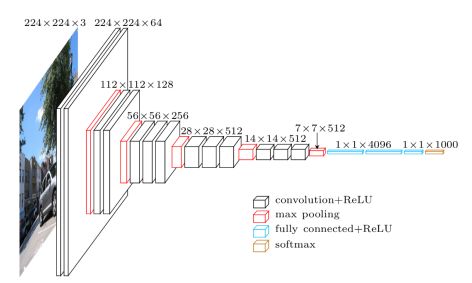
由上图看出,VGG-16的结构非常整洁,深度较AlexNet深得多,里面包含多个conv->conv->max_pool这类的结构,VGG的卷积层都是same的卷积,即卷积过后的输出图像的尺寸与输入是一致的,它的下采样完全是由max pooling来实现。
VGG网络后接3个全连接层,filter的个数(卷积后的输出通道数)从64开始,然后每接一个pooling后其成倍的增加,128、512,VGG的主要贡献是使用小尺寸的filter,及有规则的卷积-池化操作。
主要特点:
卷积层使用更小的filter尺寸和间隔
与AlexNet相比,可以看出VGG-Nets的卷积核尺寸还是很小的,比如AlexNet第一层的卷积层用到的卷积核尺寸就是11*11,这是一个很大卷积核了。而反观VGG-Nets,用到的卷积核的尺寸无非都是1×1和3×3的小卷积核,可以替代大的filter尺寸。
3×3卷积核的优点:
多个3×3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性
多个3×3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3×3的卷积层参数个数3×(3×3×C×C)=27CC;一个7×7的卷积层参数为49CC;所以可以把三个3×3的filter看成是一个7×7filter的分解(中间层有非线性的分解)
1*1卷积核的优点:
作用是在不影响输入输出维数的情况下,对输入进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
VGG16 - Keras版本
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
GoogLeNet 2014
CVPR2015 论文 《Going deeper with convolutions》
Inception V1
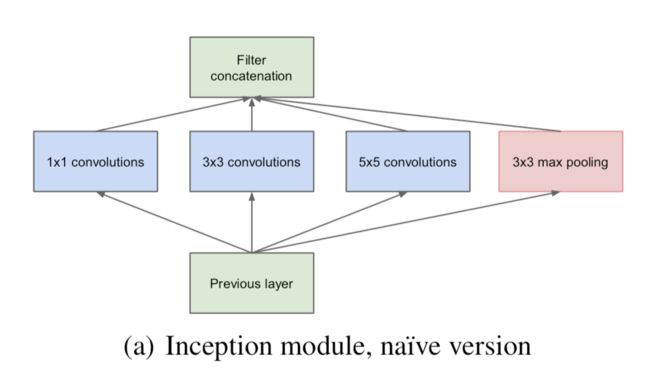

Inception V2
xception
GoogLeNet - Keras版本
def Conv2d_BN(x, nb_filter,kernel_size, padding='same',strides=(1,1),name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Inception(x,nb_filter):
branch1x1 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch3x3 = Conv2d_BN(branch3x3,nb_filter,(3,3), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(x,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branch5x5 = Conv2d_BN(branch5x5,nb_filter,(1,1), padding='same',strides=(1,1),name=None)
branchpool = MaxPooling2D(pool_size=(3,3),strides=(1,1),padding='same')(x)
branchpool = Conv2d_BN(branchpool,nb_filter,(1,1),padding='same',strides=(1,1),name=None)
x = concatenate([branch1x1,branch3x3,branch5x5,branchpool],axis=3)
return x
def GoogLeNet():
inpt = Input(shape=(224,224,3))
#padding = 'same',填充为(步长-1)/2,还可以用ZeroPadding2D((3,3))
x = Conv2d_BN(inpt,64,(7,7),strides=(2,2),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv2d_BN(x,192,(3,3),strides=(1,1),padding='same')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,64)#256
x = Inception(x,120)#480
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,128)#512
x = Inception(x,128)
x = Inception(x,128)
x = Inception(x,132)#528
x = Inception(x,208)#832
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Inception(x,208)
x = Inception(x,256)#1024
x = AveragePooling2D(pool_size=(7,7),strides=(7,7),padding='same')(x)
x = Dropout(0.4)(x)
x = Dense(1000,activation='relu')(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inpt,x,name='inception')
return model
ResNet 2015
CVPR2016 Best Paper 《Deep Residual Learning for Image Recognition》
解决退化问题:
随着网络层数的增加,模型的准确率下降了,这种退化并不是由过拟合造成的,在一个合理的深度模型中增加更多的层却导致了更高的错误。
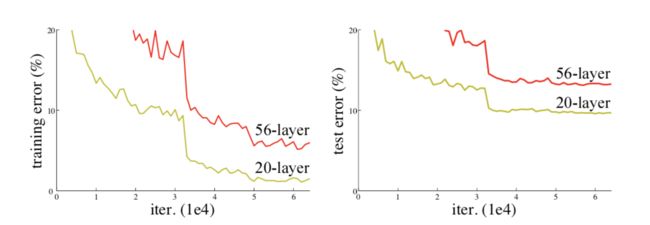
残差学习:

网络结构:
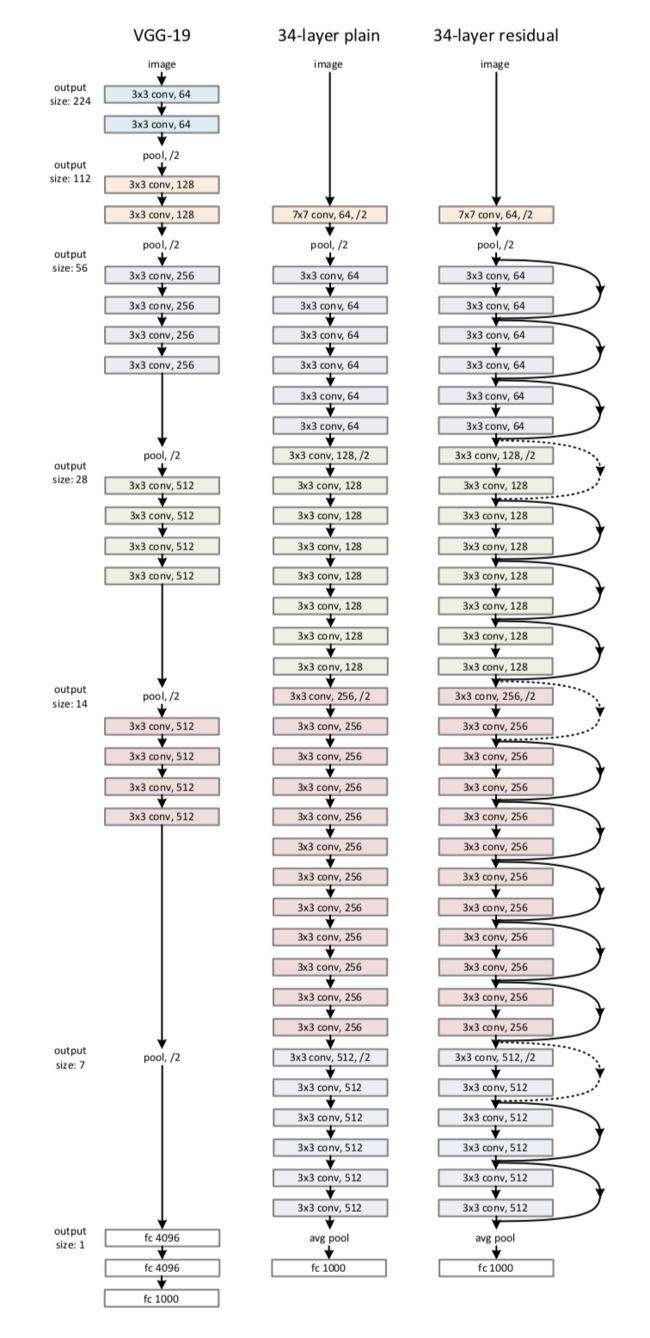
ResNet50 Keras版本
def Conv2d_BN(x, nb_filter,kernel_size, strides=(1,1), padding='same',name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Conv_Block(inpt,nb_filter,kernel_size,strides=(1,1), with_conv_shortcut=False):
x = Conv2d_BN(inpt,nb_filter=nb_filter[0],kernel_size=(1,1),strides=strides,padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[1], kernel_size=(3,3), padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[2], kernel_size=(1,1), padding='same')
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt,nb_filter=nb_filter[2],strides=strides,kernel_size=kernel_size)
x = add([x,shortcut])
return x
else:
x = add([x,inpt])
return x
def ResNet50():
inpt = Input(shape=(224,224,3))
x = ZeroPadding2D((3,3))(inpt)
x = Conv2d_BN(x,nb_filter=64,kernel_size=(7,7),strides=(2,2),padding='valid')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3),strides=(1,1),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = AveragePooling2D(pool_size=(7,7))(x)
x = Flatten()(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inputs=inpt,outputs=x)
return model
DenseNet
CVPR2017 Best Paper 《Densely Connected Convolutional Networks》
GAN 生成对抗
R-CNN Regions with CNN features
RCNN
CVPR2014 PaperLink
fast-RCNN
faster-RCNN
NASNet
CVPR2017 PaperLink
CodeLink
FCN全卷积网络
参考
CNN网络架构演进:从LeNet到DenseNet
“Visualizing and Understanding Convolutional Networks”文章学习