《House Prices: Advanced Regression Techniques》(房价预测模型)(Kaggle 练习讲解¶)
此文章,学习自https://my.oschina.net/Kanonpy/blog/3076731,但是链接中存在结果没有输出等问题,对此我在学习过程对该文章进行修改和补充,希望能为学习者提供一些帮助。
# -*- coding: utf-8 -*-
# =============================================================================
# 《House Prices: Advanced Regression Techniques》(房价预测模型)(Kaggle 练习讲解)
# https://my.oschina.net/Kanonpy/blog/3076731
# 数据来源:
# train_path = "http://kaggle.shikanon.com/house-prices-advanced-regression-techniques/train.csv"
# test_path = "http://kaggle.shikanon.com/house-prices-advanced-regression-techniques/test.csv"
# 思路
# (1) 数据可视化和数据分布变换
# (2) 缺省值处理
# (3) 数据特征变换
# (4) 数据建模及交叉检验
# (5) 模型组合
# =============================================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm, skew
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
from sklearn.model_selection import KFold, cross_val_score
from sklearn.preprocessing import LabelEncoder
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
#part1: 加载数据¶(并去除ID)
'''
train_path = "http://kaggle.shikanon.com/house-prices-advanced-regression-techniques/train.csv"
test_path = "http://kaggle.shikanon.com/house-prices-advanced-regression-techniques/test.csv"
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
'''
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
'''
##列名与数据对其显示
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
##显示所有列
pd.set_option('display.max_columns', None)
##显示所有行
pd.set_option('display.max_rows', None)
'''
print(train_df.head())
print(train_df.columns)
Id MSSubClass MSZoning ... SaleType SaleCondition SalePrice
0 1 60 RL ... WD Normal 208500
1 2 20 RL ... WD Normal 181500
2 3 60 RL ... WD Normal 223500
3 4 70 RL ... WD Abnorml 140000
4 5 60 RL ... WD Normal 250000
[5 rows x 81 columns]
Index(['Id', 'MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street',
'Alley', 'LotShape', 'LandContour', 'Utilities', 'LotConfig',
'LandSlope', 'Neighborhood', 'Condition1', 'Condition2', 'BldgType',
'HouseStyle', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd',
'RoofStyle', 'RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType',
'MasVnrArea', 'ExterQual', 'ExterCond', 'Foundation', 'BsmtQual',
'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1',
'BsmtFinType2', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating',
'HeatingQC', 'CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF',
'LowQualFinSF', 'GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath',
'HalfBath', 'BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual',
'TotRmsAbvGrd', 'Functional', 'Fireplaces', 'FireplaceQu', 'GarageType',
'GarageYrBlt', 'GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual',
'GarageCond', 'PavedDrive', 'WoodDeckSF', 'OpenPorchSF',
'EnclosedPorch', '3SsnPorch', 'ScreenPorch', 'PoolArea', 'PoolQC',
'Fence', 'MiscFeature', 'MiscVal', 'MoSold', 'YrSold', 'SaleType',
'SaleCondition', 'SalePrice'],
dtype='object')
写到这里,我们需要知道这些列名的含义,
MSSubClass: 建筑的等级,类型:类别型
MSZoning: 区域分类,类型:类别型
LotFrontage: 距离街道的直线距离,类型:数值型,单位:英尺
LotArea: 地皮面积,类型:数值型,单位:平方英尺
Street: 街道类型,类型:类别型
Alley: 巷子类型,类型:类别型
LotShape: 房子整体形状,类型:类别型
LandContour: 平整度级别,类型:类别型
Utilities: 公共设施类型,类型:类别型
LotConfig: 房屋配置,类型:类别型
LandSlope: 倾斜度,类型:类别型
Neighborhood: 市区物理位置,类型:类别型
Condition1: 主干道或者铁路便利程度,类型:类别型
Condition2: 主干道或者铁路便利程度,类型:类别型
BldgType: 住宅类型,类型:类别型
HouseStyle: 住宅风格,类型:类别型
OverallQual: 整体材料和饰面质量,类型:数值型
OverallCond: 总体状况评价,类型:数值型
YearBuilt: 建筑年份,类型:数值型
YearRemodAdd: 改建年份,类型:数值型
RoofStyle: 屋顶类型,类型:类别型
RoofMatl: 屋顶材料,类型:类别型
Exterior1st: 住宅外墙,类型:类别型
Exterior2nd: 住宅外墙,类型:类别型
MasVnrType: 砌体饰面类型,类型:类别型
MasVnrArea: 砌体饰面面积,类型:数值型,单位:平方英尺
ExterQual: 外部材料质量,类型:类别型
ExterCond: 外部材料的现状,类型:类别型
Foundation: 地基类型,类型:类别型
BsmtQual: 地下室高度,类型:类别型
BsmtCond: 地下室概况,类型:类别型
BsmtExposure: 花园地下室墙,类型:类别型
BsmtFinType1: 地下室装饰质量,类型:类别型
BsmtFinSF1: 地下室装饰面积,类型:类别型
BsmtFinType2: 地下室装饰质量,类型:类别型
BsmtFinSF2: 地下室装饰面积,类型:类别型
BsmtUnfSF: 未装饰的地下室面积,类型:数值型,单位:平方英尺
TotalBsmtSF: 地下室总面积,类型:数值型,单位:平方英尺
Heating: 供暖类型,类型:类别型
HeatingQC: 供暖质量和条件,类型:类别型
CentralAir: 中央空调状况,类型:类别型
Electrical: 电力系统,类型:类别型
1stFlrSF: 首层面积,类型:数值型,单位:平方英尺
2ndFlrSF: 二层面积,类型:数值型,单位:平方英尺
LowQualFinSF: 低质装饰面积,类型:数值型,单位:平方英尺
GrLivArea: 地面以上居住面积,类型:数值型,单位:平方英尺
BsmtFullBath: 地下室全浴室,类型:数值
BsmtHalfBath: 地下室半浴室,类型:数值
FullBath: 高档全浴室,类型:数值
HalfBath: 高档半浴室,类型:数值
BedroomAbvGr: 地下室以上的卧室数量,类型:数值
KitchenAbvGr: 厨房数量,类型:数值
KitchenQual: 厨房质量,类型:类别型
TotRmsAbvGrd: 地上除卧室以外的房间数,类型:数值
Functional: 房屋功用性评级,类型:类别型
Fireplaces: 壁炉数量,类型:数值
FireplaceQu: 壁炉质量,类型:类别型
GarageType: 车库位置,类型:类别型
GarageYrBlt: 车库建造年份,类别:数值型
GarageFinish: 车库内饰,类型:类别型
GarageCars: 车库车容量大小,类别:数值型
GarageArea: 车库面积,类别:数值型,单位:平方英尺
GarageQual: 车库质量,类型:类别型
GarageCond: 车库条件,类型:类别型
PavedDrive: 铺的车道情况,类型:类别型
WoodDeckSF: 木地板面积,类型:数值型,单位:平方英尺
OpenPorchSF: 开放式门廊区面积,类型:数值型,单位:平方英尺
EnclosedPorch: 封闭式门廊区面积,类型:数值型,单位:平方英尺
3SsnPorch: 三个季节门廊面积,类型:数值型,单位:平方英尺
ScreenPorch: 纱门门廊面积,类型:数值型,单位:平方英尺
PoolArea: 泳池面积,类型:数值型,单位:平方英尺
PoolQC:泳池质量,类型:类别型
Fence: 围墙质量,类型:类别型
MiscFeature: 其他特征,类型:类别型
MiscVal: 其他杂项特征值,类型:类别型
MoSold: 卖出月份,类别:数值型
YrSold: 卖出年份,类别:数值型
SaleType: 交易类型,类型:类别型
SaleCondition: 交易条件,类型:类别型
#part2: 数据处理和特征分析
##另存IDS
train_ID = train_df['Id']
test_ID = test_df['Id']
##删除原来的Ids
train_df.drop("Id", axis = 1, inplace = True)
test_df.drop("Id", axis = 1, inplace = True)
#part3: 数据观察和可视化
## 根基常识,一般和房价最相关的是居住面积(GrLivArea),我们查看GrLivArea和SalePrice的关系
## GrLivArea: 居住面积
## SalePrice: 销售价格
fig, ax = plt.subplots()
ax.scatter(x = train_df['GrLivArea'], y = train_df['SalePrice'], c = 'r',alpha='0.6')
plt.ylabel('SalePrice', fontsize=8)
plt.xlabel('GrLivArea', fontsize=8)
plt.axhline(y = 200000, c="gray", ls="--", lw=1) #axh轴代表水平
plt.axvline(x = 4250, c="gray", ls="--", lw=1) #axv代表竖直
plt.title('销售价格和居住面积的关系图')
plt.show()
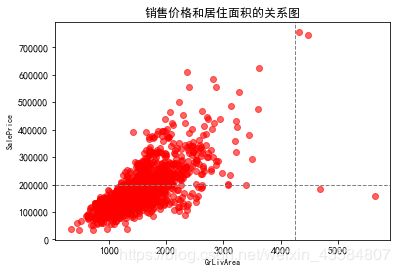
从图中可以看出,有个别值特别偏离,(如图右下角)GrLivArea有两个点在4250以上,但其价格不到200000,首先这种点特别少(不到总数的3%),所以我们把他作为异常值去掉(其实是否去掉我们可以多做几次实验来验证)
# 去掉异常值
train_df.drop(train_df[(train_df['GrLivArea']>4250)&(train_df['GrLivArea']<20000)].index,inplace=True)
fig, ax = plt.subplots()
ax.scatter(x = train_df['GrLivArea'], y = train_df['SalePrice'], c = 'r',alpha='0.6')
plt.ylabel('SalePrice', fontsize=8)
plt.xlabel('GrLivArea', fontsize=8)
plt.title('销售价格和居住面积的关系图')
plt.show()
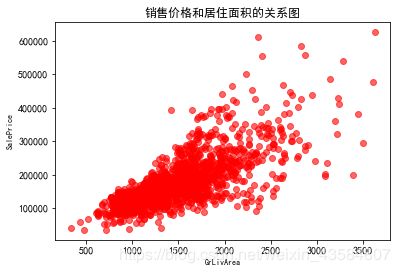
在机器学习中,对数据的认识是很重要的,他会影响我们的特征构建和建模,特别对于偏态分布,我们要做一些变换
先补充下知识:
- Q-Q图,全称 Quantile Quantile Plot,中文名叫分位数图,Q-Q图是一个概率图,用于
比较观测与预测值之间的概率分布差异,这里的比较对象一般采用正态分布,Q-Q图可以用于检验数据分布的相似性,而 - P-P图是根据变量的累积概率对应于所指定的理论分布累积概率绘制的散点图,两者基本一样
#观察数据分布
##统计表述
print(train_df['SalePrice'].describe())
##绘制分布图
sns.distplot(train_df['SalePrice'],
kde_kws={"color": "black", "lw": 1, "label": "KDE"},
hist_kws={"histtype": "stepfilled", "linewidth": 3, "alpha": 0.7, "color": "r"});
##绘制P-P图(红色线是正态分布,蓝色线是我们的数据)
fig = plt.figure()
res = stats.probplot(train_df['SalePrice'], dist="norm", plot=plt)
plt.show()
count 1456.000000
mean 180151.233516
std 76696.592530
min 34900.000000
25% 129900.000000
50% 163000.000000
75% 214000.000000
max 625000.000000
Name: SalePrice, dtype: float64
| SalePrice (原图) | P-P图 |
|---|---|
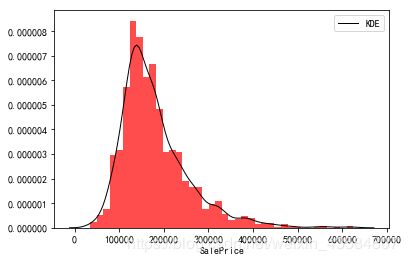 |
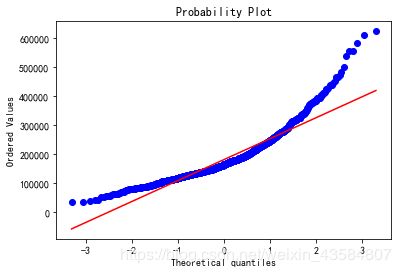 |
从P-P图中我们可以看出,我们的数据头尾都严重偏离了正太分布,对此需要尝试对数据进行变换,常用的变换方式有指数变换、对数变换、幂函数等。
##对数变换
train_df['SalePrice_Log'] = np.log(train_df['SalePrice'])
sns.distplot(train_df['SalePrice_Log'],
kde_kws={"color": "black", "lw": 1, "label": "KDE"},
hist_kws={"histtype": "stepfilled", "linewidth": 3, "alpha": 0.7, "color": "r"});
##偏度与峰值(skewness and kurtosis)
print("Skewness: %f" % train_df['SalePrice_Log'].skew())
print("Kurtosis: %f" % train_df['SalePrice_Log'].kurt())
##绘制P-P图
fig = plt.figure()
res = stats.probplot(train_df['SalePrice_Log'], plot=plt)
plt.show()
Skewness: 0.065449
Kurtosis: 0.666438
| SalePrice_Log(对数变换) | P-P图 |
|---|---|
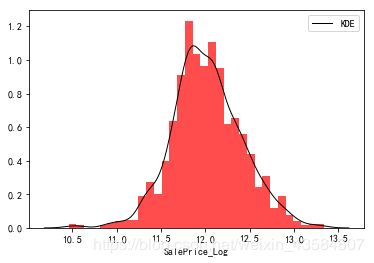 |
 |
##指数变换
train_df['SalePrice_Exp'] = np.exp(train_df['SalePrice']/train_df['SalePrice'].mean())
sns.distplot(train_df['SalePrice_Exp'],
kde_kws={"color": "black", "lw": 1, "label": "KDE"},
hist_kws={"histtype": "stepfilled", "linewidth": 3, "alpha": 0.7, "color": "r"});
##偏度与峰值(skewness and kurtosis)
print("Skewness: %f" % train_df['SalePrice_Exp'].skew())
print("Kurtosis: %f" % train_df['SalePrice_Exp'].kurt())
##绘制P-P图
fig = plt.figure()
res = stats.probplot(train_df['SalePrice_Exp'], plot=plt)
plt.show()
Skewness: 6.060076
Kurtosis: 56.822460
| SalePrice_Exp(指数变换) | P-P图 |
|---|---|
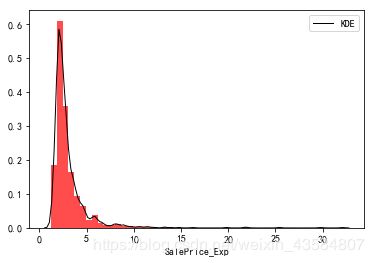 |
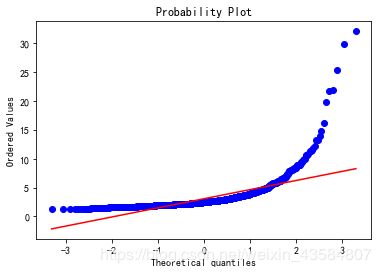 |
##幂函数变换
train_df['SalePrice_Square'] = train_df['SalePrice']**0.5
sns.distplot(train_df['SalePrice_Square'],
kde_kws={"color": "black", "lw": 1, "label": "KDE"},
hist_kws={"histtype": "stepfilled", "linewidth": 3, "alpha": 0.7, "color": "r"});
##偏度与峰值(skewness and kurtosis)
print("Skewness: %f" % train_df['SalePrice_Square'].skew())
print("Kurtosis: %f" % train_df['SalePrice_Square'].kurt())
##绘制P-P图
fig = plt.figure()
res = stats.probplot(train_df['SalePrice_Square'], plot=plt)
plt.show()
Skewness: 0.810797
Kurtosis: 1.245798
| SalePrice_Square(幂函数变换) | P-P图 |
|---|---|
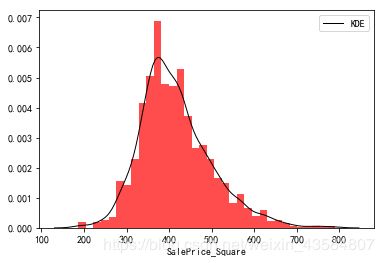 |
 |
三个函数拟合对比发现,对数变换最吻合,但是我们知道对数意味着小于1的时候为负数,这明显和认知不符合,应该采用log(1+x),也就是log1p,保证了x数据的有效性,当x很小时,如: 10^{-16} ,由于太小超过数值有效性,用log(x+1)计算得到结果为0
##更新对数变换
train_df['SalePrice_Log1p'] = np.log1p(train_df['SalePrice'])
sns.distplot(train_df['SalePrice_Log1p'],
kde_kws={"color": "black", "lw": 1, "label": "KDE"},
hist_kws={"histtype": "stepfilled", "linewidth": 3, "alpha": 0.7, "color": "r"});
##偏度与峰值(skewness and kurtosis)
print("Skewness: %f" % train_df['SalePrice_Log1p'].skew())
print("Kurtosis: %f" % train_df['SalePrice_Log1p'].kurt())
##绘制P-P图
fig = plt.figure()
res = stats.probplot(train_df['SalePrice_Log1p'], plot=plt)
plt.show()
Skewness: 0.065460
Kurtosis: 0.666423
| SalePrice_Log1p(更新对数变换) | P-P图 |
|---|---|
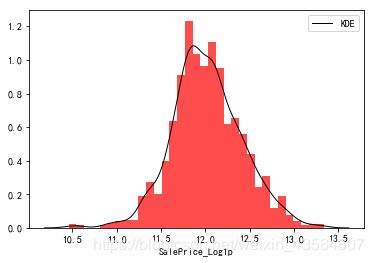 |
 |
##然后删除刚才测试后多余的变换
del train_df['SalePrice_Square']
del train_df["SalePrice_Exp"]
del train_df['SalePrice_Log']
del train_df["SalePrice"]
#part5:将测试数据和训练数据联合一起进行特征分析
size_train_df = train_df.shape[0]
size_test_df = test_df.shape[0]
target_variable = train_df['SalePrice_Log1p'].values
data = pd.concat((train_df, test_df),sort=False).reset_index(drop=True)
data.drop(['SalePrice_Log1p'], axis=1, inplace=True)
print(data)
MSSubClass MSZoning ... SaleCondition SalePrice
0 60 RL ... Normal 208500.0
1 20 RL ... Normal 181500.0
2 60 RL ... Normal 223500.0
3 70 RL ... Abnorml 140000.0
4 60 RL ... Normal 250000.0
5 50 RL ... Normal 143000.0
6 20 RL ... Normal 307000.0
7 60 RL ... Normal 200000.0
8 50 RM ... Abnorml 129900.0
9 190 RL ... Normal 118000.0
10 20 RL ... Normal 129500.0
11 60 RL ... Partial 345000.0
12 20 RL ... Normal 144000.0
13 20 RL ... Partial 279500.0
14 20 RL ... Normal 157000.0
15 45 RM ... Normal 132000.0
16 20 RL ... Normal 149000.0
17 90 RL ... Normal 90000.0
18 20 RL ... Normal 159000.0
19 20 RL ... Abnorml 139000.0
20 60 RL ... Partial 325300.0
21 45 RM ... Normal 139400.0
22 20 RL ... Normal 230000.0
23 120 RM ... Normal 129900.0
24 20 RL ... Normal 154000.0
25 20 RL ... Normal 256300.0
26 20 RL ... Normal 134800.0
27 20 RL ... Normal 306000.0
28 20 RL ... Normal 207500.0
29 30 RM ... Normal 68500.0
... ... ... ... ...
2885 30 RM ... Normal NaN
2886 50 RM ... Normal NaN
2887 30 C (all) ... Abnorml NaN
2888 190 C (all) ... Abnorml NaN
2889 50 C (all) ... Normal NaN
2890 120 RM ... Partial NaN
2891 120 RM ... Normal NaN
2892 20 RL ... Normal NaN
2893 90 RL ... Normal NaN
2894 20 RL ... Normal NaN
2895 80 RL ... Normal NaN
2896 20 RL ... Alloca NaN
2897 20 RL ... Normal NaN
2898 20 RL ... Partial NaN
2899 20 RL ... Partial NaN
2900 20 NaN ... Normal NaN
2901 90 RM ... Normal NaN
2902 160 RM ... Normal NaN
2903 20 RL ... Normal NaN
2904 90 RL ... Normal NaN
2905 180 RM ... Normal NaN
2906 160 RM ... Normal NaN
2907 20 RL ... Normal NaN
2908 160 RM ... Abnorml NaN
2909 160 RM ... Normal NaN
2910 160 RM ... Normal NaN
2911 160 RM ... Abnorml NaN
2912 20 RL ... Abnorml NaN
2913 85 RL ... Normal NaN
2914 60 RL ... Normal NaN
[2915 rows x 80 columns]
从上面的输出可以看出,该数据存在缺失值,对此,我们需要进行缺失值处理
缺失值是实际数据分析很重要的一块,在实际生产中一直都会有大量的缺失值存在,如何处理好缺失值是很关键也很重要的一步。
常见的缺失值处理有:
- (1)把缺失值单独作为一类,比如对类别型用none。
- (2)采用平均数、中值、众数等特定统计值来填充缺失值。
- (3)采用函数预测等方法填充缺失值。
# =============================================================================
# #part5:缺失值处理
# =============================================================================
print(data.count().sort_values().head(20)) # 通过 count 可以找出有缺失值的数据
PoolQC 8
MiscFeature 105
Alley 198
Fence 570
SalePrice 1456
FireplaceQu 1495
LotFrontage 2429
GarageFinish 2756
GarageYrBlt 2756
GarageCond 2756
GarageQual 2756
GarageType 2758
BsmtExposure 2833
BsmtCond 2833
BsmtQual 2834
BsmtFinType2 2835
BsmtFinType1 2836
MasVnrType 2891
MasVnrArea 2892
MSZoning 2911
dtype: int64
- 如果我们仔细观察一下数据描述里面的内容的话,会发现很多缺失值都有迹可循,比如PoolQC,表示的是游泳池的质量,其值本身表示有无游泳池,缺失代表这个房子没有游泳池,因此可以用 “None” 来填补;(判断有无型用“None”填充 )
- 特征为XX面积,比如 TotalBsmtSF 表示地下室的面积,如果一个房子本身没有地下室,则缺失值就用0来填补。(数值型用0来填充)
- 另外,LotFrontage这个特征与LotAreaCut和Neighborhood有比较大的关系,所以这里用这两个特征分组后的中位数进行插补。
所以,这里的各变量填充策略:
None:[‘PoolQC’,‘MiscFeature’,‘Alley’,‘Fence’,‘FireplaceQu’,‘GarageQual’,‘GarageCond’,‘GarageFinish’,‘GarageType’,‘BsmtExposure’,‘BsmtCond’,‘BsmtQual’,‘BsmtFinType1’,‘BsmtFinType2’, ‘MasVnrType’]
0:[‘GarageYrBlt’, ‘GarageArea’, ‘GarageCars’, ‘MasVnrArea’,‘BsmtFullBath’,‘BsmtHalfBath’, ‘BsmtFinSF1’, ‘BsmtFinSF2’, ‘BsmtUnfSF’, ‘TotalBsmtSF’]
中位数插补:[“LotFrontage”,“LotAreaCut”,“Neighborhood”]
众数插补:[“Functional”, “MSZoning”, “SaleType”, “Electrical”, “KitchenQual”, “Exterior2nd”, “Exterior1st”]
# 处理缺失值并绘制条形图
data_na = (data.isnull().sum() / len(data)) * 100 # 存在缺失值数据列总和在所有数据的占比
data_na.drop(data_na[data_na==0].index,inplace=True) # 删除占比为0的data_na
data_na = data_na.sort_values(ascending=False) # 从大到小排序
f, ax = plt.subplots(figsize=(10, 8))
plt.xticks(rotation='90')
sns.barplot(x=data_na.index, y=data_na)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
Text(0.5,1,‘Percent missing data by feature’)

# 填充None
features_fill_na_none = ['PoolQC','MiscFeature','Alley','Fence','FireplaceQu',
'GarageQual','GarageCond','GarageFinish','GarageType',
'BsmtExposure','BsmtCond','BsmtQual','BsmtFinType1','BsmtFinType2',
'MasVnrType']
# 填充0
features_fill_na_0 = ['GarageYrBlt', 'GarageArea', 'GarageCars', 'MasVnrArea',
'BsmtFullBath','BsmtHalfBath', 'BsmtFinSF1', 'BsmtFinSF2',
'BsmtUnfSF', 'TotalBsmtSF']
# 填众数
features_fill_na_mode = ["Functional", "MSZoning", "SaleType", "Electrical",
"KitchenQual", "Exterior2nd", "Exterior1st"]
for feature_none in features_fill_na_none:
data[feature_none].fillna('None',inplace=True)
for feature_0 in features_fill_na_0:
data[feature_0].fillna(0,inplace=True)
for feature_mode in features_fill_na_mode:
mode_value = data[feature_mode].value_counts().sort_values(ascending=False).index[0]
data[features_fill_na_mode] = data[features_fill_na_mode].fillna(mode_value)
# 用中值代替
data["LotFrontage"] = data.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
# 查看Utilities,在data_na中可以看到 (Utilities 0.068611)
var1 = 'Utilities'
train_var_count1 = train_df[var1].value_counts()
print(train_var_count1)
fig = sns.barplot(x=train_var_count1.index, y=train_var_count1)
plt.xticks();
plt.show()
# 查看MSZoning,在data_na中可以看到 ( MSZoning 0.137221)
var2 = 'MSZoning'
train_var_count2 = train_df[var2].value_counts()
fig = sns.barplot(x=train_var_count2.index, y=train_var_count2)
plt.xticks();
plt.show()
# 像 Utilities 这种总共才两个值,同时有一个值是作为主要的,这种字段是无意义的,应该删除
data.drop(['Utilities'], axis=1,inplace=True)
data_na = (data.isnull().sum() / len(data)) * 100
data_na.drop(data_na[data_na==0].index,inplace=True)
data_na = data_na.sort_values(ascending=False)
print(data_na) # data_na 为空
Series([], dtype: float64)
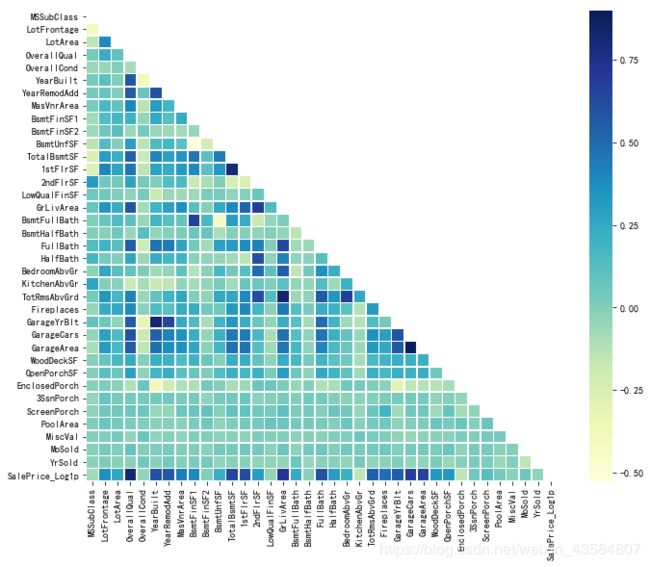
关系矩阵可以很直观的告诉我们那些变量之间相关,哪些变量并不相关
# =============================================================================
# part6: 绘制关系矩阵图
# 关系矩阵可以很直观的告诉我们那些变量之间相关,哪些变量并不相关
# =============================================================================
# 关系矩阵
corrmat = train_df.corr()
print(corrmat)
mask = np.zeros_like(corrmat) # 返回相同大小的0矩阵
mask[np.triu_indices_from(mask)] = True # triu_indices_from: 函数的上三角矩阵
print(mask)
# 绘制热力图
plt.subplots(figsize=(12,9))
sns.heatmap(corrmat, mask=mask, linewidths=.5, vmax=0.9, square=True, cmap="YlGnBu")
特征工程
对数据做特征变换:
- 对于类别数据,一般采用LabelEncoder的方式,把每个类别的数据变成数值型;也可以采用one-hot变成稀疏矩阵
- 对于数值型的数据,尽量将其变为正态分布。
对此, 我们需要对数据进行类型转换,将某些实际是类别类型但用数字表示的强制转换成文本,比如有些调查男表示1,女表示0,在这种情况下,如果我们直接通过dataframe类型判断会导致错误,我们要根据实际情况做转换
#MSSubClass=The building class
data['MSSubClass'] = data['MSSubClass'].apply(str)
#Changing OverallCond into a categorical variable
data['OverallCond'] = data['OverallCond'].astype(str)
#Year and month sold are transformed into categorical features.
data['YrSold'] = data['YrSold'].astype(str)
data['MoSold'] = data['MoSold'].astype(str)
encode_cat_variables = ('Alley', 'BldgType', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'BsmtQual', 'CentralAir',
'Condition1', 'Condition2', 'Electrical', 'ExterCond', 'ExterQual', 'Exterior1st', 'Exterior2nd', 'Fence',
'FireplaceQu', 'Foundation', 'Functional', 'GarageCond', 'GarageFinish', 'GarageQual', 'GarageType',
'Heating', 'HeatingQC', 'HouseStyle', 'KitchenQual', 'LandContour', 'LandSlope', 'LotConfig', 'LotShape',
'MSSubClass', 'MSZoning', 'MasVnrType', 'MiscFeature', 'MoSold', 'Neighborhood', 'OverallCond', 'PavedDrive',
'PoolQC', 'RoofMatl', 'RoofStyle', 'SaleCondition', 'SaleType', 'Street', 'YrSold')
numerical_features = [col for col in data.columns if col not in encode_cat_variables]
print("Categorical Features: %d" % len(encode_cat_variables))
print("Numerical Features: %d" % len(numerical_features))
## 特征工程
#for variable in encode_cat_variables:
# lbl = LabelEncoder()
# lbl.fit(list(data[variable].values))
# data[variable] = lbl.transform(list(data[variable].values))
for variable in data.columns:
if variable not in encode_cat_variables:
data[variable] = data[variable].apply(float)
else:
data[variable] = data[variable].apply(str)
print(data.shape)
data = pd.get_dummies(data)
print(data.shape)
Categorical Features: 46
Numerical Features: 32
(2915, 78)
(2915, 343)
##可以计算一个总面积指标
data['TotalSF'] = data['TotalBsmtSF'] + data['1stFlrSF'] + data['2ndFlrSF']
print(data['TotalSF'].head())
0 2566.0
1 2524.0
2 2706.0
3 2473.0
4 3343.0
Name: TotalSF, dtype: float64
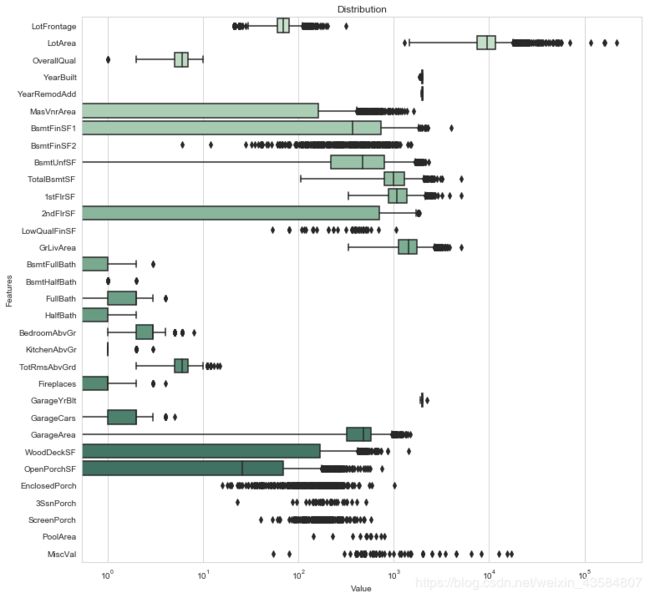
##数值型变量的分布
#Boxplot for numerical_features
sns.set_style("whitegrid")
f, ax = plt.subplots(figsize=(12, 12))
ax.set_xscale("log")
ax = sns.boxplot(data=data[numerical_features] , orient="h", palette="ch:2.5,-.2,dark=.3")
ax.set(ylabel="Features")
ax.set(xlabel="Value")
ax.set(title="Distribution",fontsize=10)
sns.despine(trim=True, left=True) # 边框控制
- Box-Cox变换是Box和Cox在1964年提出的一种广义幂变换方法,用于连续的响应变量不满足正态分布的情况。Box-Cox变换之后,可以一定程度上减小不可观测的误差和预测变量的相关性。Box-Cox变换的主要特点是引入一个参数,通过数据本身估计该参数进而确定应采取的数据变换形式。
# 计算数值型变量的偏态
skewed_features = data[numerical_features].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print(skewed_features+"\n")
skewed_features = skewed_features[abs(skewed_features) > 0.75]
print("There are {} skewed numerical features to Box Cox transform".format(skewed_features.shape[0]))
MiscVal 21.932147
PoolArea 18.701829
LotArea 13.123758
LowQualFinSF 12.080315
3SsnPorch 11.368094
KitchenAbvGr 4.298845
BsmtFinSF2 4.142863
EnclosedPorch 4.000796
ScreenPorch 3.943508
BsmtHalfBath 3.942892
MasVnrArea 2.600697
OpenPorchSF 2.529245
WoodDeckSF 1.848285
1stFlrSF 1.253011
LotFrontage 1.092709
GrLivArea 0.977860
BsmtFinSF1 0.974138
BsmtUnfSF 0.920135
2ndFlrSF 0.843237
TotRmsAbvGrd 0.749579
Fireplaces 0.725958
HalfBath 0.698770
TotalBsmtSF 0.662657
BsmtFullBath 0.622820
BedroomAbvGr 0.328129
GarageArea 0.217748
OverallQual 0.181902
FullBath 0.159917
GarageCars -0.219402
YearRemodAdd -0.449113
YearBuilt -0.598087
GarageYrBlt -3.903046
dtype: float64
There are 20 skewed numerical features to Box Cox transform
skewed_features_name = skewed_features.index
lam = 0.15 # 超参数
for feat in skewed_features_name:
tranformer_feat = boxcox1p(data[feat], lam)
data[feat] = tranformer_feat
data[numerical_features].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print(skewed_features)
MiscVal 21.932147
PoolArea 18.701829
LotArea 13.123758
LowQualFinSF 12.080315
3SsnPorch 11.368094
KitchenAbvGr 4.298845
BsmtFinSF2 4.142863
EnclosedPorch 4.000796
ScreenPorch 3.943508
BsmtHalfBath 3.942892
MasVnrArea 2.600697
OpenPorchSF 2.529245
WoodDeckSF 1.848285
1stFlrSF 1.253011
LotFrontage 1.092709
GrLivArea 0.977860
BsmtFinSF1 0.974138
BsmtUnfSF 0.920135
2ndFlrSF 0.843237
GarageYrBlt -3.903046
dtype: float64
#Boxplot for numerical_features
sns.set_style("whitegrid")
f, ax = plt.subplots(figsize=(12, 12))
ax.set_xscale("log")
ax = sns.boxplot(data=data[numerical_features] , orient="h", palette="ch:2.5,-.2,dark=.3")
ax.set(ylabel="Features")
ax.set(xlabel="Value")
ax.set(title="Distribution")
sns.despine(trim=True, left=True)

##特征处理完后可以将数据再分割开:
train = data[:size_train_df]
test = data[size_train_df:]
print(train.head())
print(test.head())
LotFrontage LotArea ... SaleCondition_5 TotalSF
0 5.831328 19.212182 ... 0 2566.0
1 6.221214 19.712205 ... 0 2524.0
2 5.914940 20.347241 ... 0 2706.0
3 5.684507 19.691553 ... 0 2473.0
4 6.314735 21.325160 ... 0 3343.0
[5 rows x 344 columns]
LotFrontage LotArea ... SaleCondition_5 TotalSF
1456 6.221214 20.479373 ... 0 1778.0
1457 6.244956 21.327220 ... 0 2658.0
1458 6.073289 21.196905 ... 0 2557.0
1459 6.172972 19.865444 ... 0 2530.0
1460 5.093857 17.257255 ... 0 2560.0
[5 rows x 344 columns]
# =============================================================================
# part8:建模
# 构建算法模型,常用的几个算法模型(7个)都试试,然后设置交叉检验
# =============================================================================
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import lightgbm as lgb
##定义一个交叉评估函数
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, target_variable, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
##尝试以下算法模型
##1:LASSO回归(LASSO Regression)
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
score = rmsle_cv(lasso)
print("\nLASSO回归 score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
##2:岭回归(Kernel Ridge Regression)
KRR = make_pipeline(RobustScaler(), KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5))
score = rmsle_cv(KRR)
print("\n岭回归 score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
##3:弹性网络回归(Elastic Net Regression)(弹性网络是结合了岭回归和Lasso回归,由两者加权平均所得。)
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
score = rmsle_cv(ENet)
print("\n弹性网络回归 score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
##组合模型(现在常用的组合模型有提升树(Gradient Boosting Regression)、XGBoost、LightGBM 等)
###4:提升树(Gradient Boosting Regression)
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state=5)
score = rmsle_cv(GBoost)
print("\n提升树 score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
###5:XGBoost
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
score = rmsle_cv(model_xgb)
print("\nXGBoost score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
###6:LightGBM([LightGBM算法总结](https://blog.csdn.net/weixin_39807102/article/details/81912566)
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
score = rmsle_cv(model_lgb)
print("\nLightGBM score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
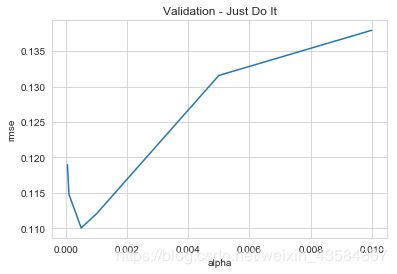
##7:寻找最优参数(通过可视化的方式来看看如何寻找模型最优参数)
alphas = [0.00005, 0.0001, 0.0005, 0.001, 0.005, 0.01]
cv_ridge_score = [rmsle_cv(make_pipeline(RobustScaler(), Lasso(alpha=alpha, random_state=1))).mean()
for alpha in alphas]
cv_ridge = pd.Series(cv_ridge_score, index = alphas)
cv_ridge.plot(title = "Validation - Just Do It")
plt.xlabel("alpha")
plt.ylabel("rmse")
LASSO回归 score: 0.1101 (0.0058)
岭回归 score: 0.1152 (0.0043)
弹性网络回归 score: 0.1100 (0.0059)
提升树 score: 0.1182 (0.0078)
XGBoost score: 0.1172 (0.0051)
LightGBM score: 0.1174 (0.0061)
##几个基础模型预测值的比较:
train_size = int(len(train)*0.7)
X_train = train.values[:train_size]
X_test = train.values[train_size:]
y_train = target_variable[:train_size]
y_test = target_variable[train_size:]
print(GBoost.fit(X_train, y_train))
print(ENet.fit(X_train, y_train))
GradientBoostingRegressor(alpha=0.9, criterion='friedman_mse', init=None,
learning_rate=0.05, loss='huber', max_depth=4,
max_features='sqrt', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=15, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=3000,
presort='auto', random_state=5, subsample=1.0, verbose=0,
warm_start=False)
Pipeline(memory=None,
steps=[('robustscaler', RobustScaler(copy=True, quantile_range=(25.0, 75.0), with_centering=True,
with_scaling=True)), ('elasticnet', ElasticNet(alpha=0.0005, copy_X=True, fit_intercept=True, l1_ratio=0.9,
max_iter=1000, normalize=False, positive=False, precompute=False,
random_state=3, selection='cyclic', tol=0.0001, warm_start=False))])
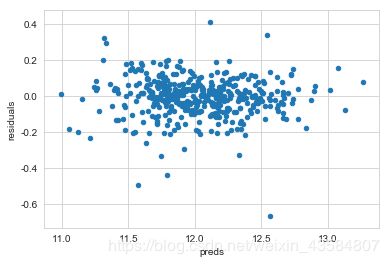
## 残差图
preds = pd.DataFrame({"preds":GBoost.predict(X_test), "true":y_test})
preds["residuals"] = preds["true"] - preds["preds"]
preds.plot(x = "preds", y = "residuals",kind = "scatter")
preds = pd.DataFrame({"preds":ENet.predict(X_test), "true":y_test})
preds["residuals"] = preds["true"] - preds["preds"]
preds.plot(x = "preds", y = "residuals",kind = "scatter")
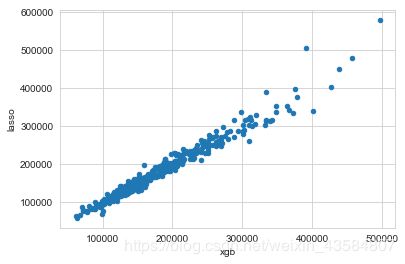
xgb_preds = np.expm1(GBoost.predict(X_test))
lasso_preds = np.expm1(ENet.predict(X_test))
predictions = pd.DataFrame({"xgb":xgb_preds, "lasso":lasso_preds})
predictions.plot(x = "xgb", y = "lasso", kind = "scatter")

# =============================================================================
# part9:集成学习(模型融合)
# =============================================================================
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
##输出:Averaged base models score: 0.1085 (0.0057)
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model) # 复制基准模型,因为这里会有多个模型
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
# 训练基准模型,基于基准模型训练的结果导出成特征
# that are needed to train the cloned meta-model
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y): #分为预测和训练
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
# 将基准模型预测数据作为特征用来给meta_model训练
self.meta_model_.fit(out_of_fold_predictions, y)
return self
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
meta_model = LinearRegression()
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR, lasso),
meta_model = meta_model,
n_folds=10)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))
#输出:Stacking Averaged models score: 0.1090 (0.0060)