Python-学习笔记之Pandas--排序sort_value
Python-学习笔记之Pandas–排序sort_value
一、排序
按照某一列的大小进行排序,Python3目前提供两个函数。
(一)sort_index
这个函数目前不建议使用,推荐使用sort_values
## 参数
sort_index(axis=0,level=None,ascending=Ture,inplace=False,kind='quicksort',na_position='last',sort_')
#### 参数说明
axis:0按照行名排序;1按照列名排序
level:默认None,否则按照给定的level顺序排列---貌似并不是,文档
ascending:默认True升序排列;False降序排列
inplace:默认False,Ture排序之后的数据直接替换原来的数据框
kind:默认quicksort,排序的方法
na_position:缺失值默认排在最后{"first","last"}
by:按照那一列数据进行排序,但是by参数貌似不建议使用
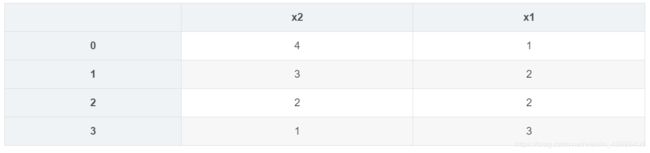
#对x1列升序排列,x2列升序。处理x1有相同值的情况
import pandas as pd
x = pd.DataFrame({"x1":[1,2,2,3],"x2":[4,3,2,1]})
x.sort_index(by = ["x1","x2"],ascending = [Flase,Ture])
(二)sort_value
DataFrame.sort_values(by,axis=0,ascending = Ture,inplace = Flase,kind = ‘quicksort’,na_position=‘last’)
## 参数
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
#### 参数说明
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照索引排序,即纵向排序,如果为1,则是横向排序
by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名";
ascending:布尔型,True则升序,可以是[True,False],即第一字段升序,第二个降序
inplace:布尔型,是否用排序后的数据框替换现有的数据框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心
na_position : {‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面
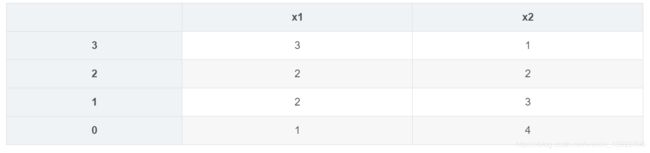
## 沿着轴方向按指定x1的值排序
x.sort_values(by="x1",ascending= False)
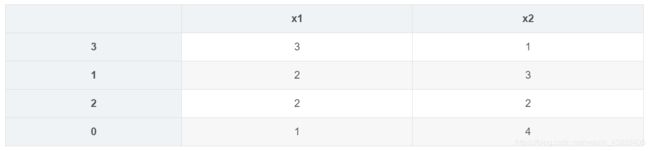
## 沿着行方向按指定的行排序
x.sort_values(by = 1,ascending=False,axis=1)