数据分析实战 We Rate Dogs’: Twitter 数据分析
通过本项目学习者有机会完成体验整个数据分析过程,从收集数据到清理和分析数据,最后进行可视化分析。
数据来自推特帐号 ‘We Rate Dogs’ 以诙谐幽默的方式对人们的宠物狗评分。这些评分通常以 10 作为分母。但是分子则一般大于 10:11/10、12/10、13/10 ,因此可以让大多数狗的评分高于10分
源代码和数据集:https://github.com/DongDongGe1/EDA
1. Gathering Data
我们有三个数据集文件
- twitter_archive_enhanced WeRateDogs twitter 的主要数据,从2015年到2017年
- image_archive_master WeRateDogs twitter 的图像机器学习算法的结果
- tweet_data 额外的 twitter 数据集,包括每条推文的转发次数,收藏次数等
# 导入相关工具包
import numpy as np
import pandas as pd
import requests
import json
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False # 显示负数
twitter_df = pd.read_csv('../data/twitter-archive-enhanced.csv')
twitter_df.head()
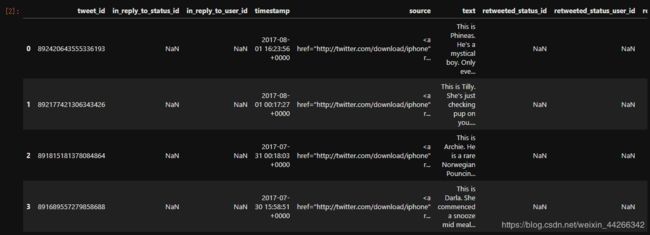
twi_pred_df = pd.read_csv(’…/data/tweet-predictions.tsv’,sep=’\t’)
twi_pred_df.head()

with open('../data/tweet_data.txt','r') as f:
data = json.load(f)
scrapped_df = pd.DataFrame(data)
scrapped_df.head()
2. Assessing The Data
我们的三个 data frames 是 twitter_df, twi_pred_df, scrapped_df
1.
twitter_df['in_reply_to_status_id'].count()
# 输出 78
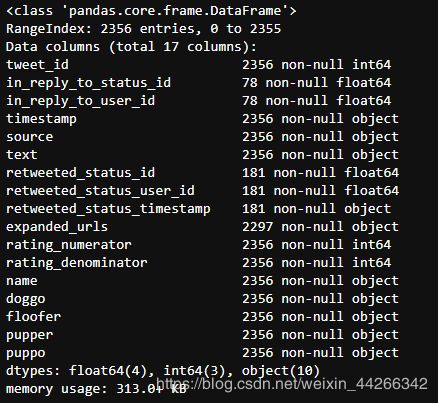
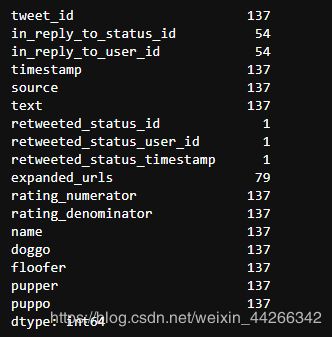
twitter_df.info()
plt.figure(figsize=(20,8))
sns.heatmap(twitter_df.isnull(), cbar=False)
plt.show()

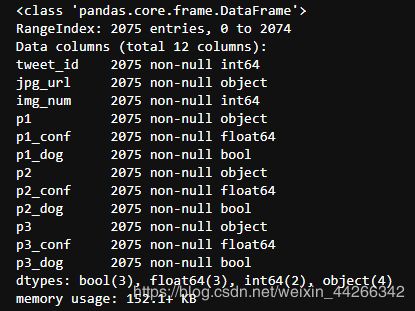
twi_pred_df.info()
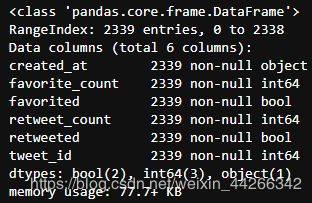
scrapped_df.info()
- 这些都是大数据集,所以我们可以清楚的看到一些问题,twitter_df 中的retweeted 需要删除。
- twitter_df 中有 2 列少于 100 行,缺失值太多,也需要删除。
- 三个数据框的行数都不同,scrapped_df 中有2342个,twi_pred_df 中有2075个,twitter_df 中有2356个,所以需要进行内连接。
通过缺失值热力图可视化分析,我们可以看到 source 和 expanded_urls 应该被删除,因为它们包含我们不需要的数据,所有网址都是独一无二的。doggo,floofer,pupper,puppo 代表狗的四个阶段,可以合为一列
2.
twitter_df[twitter_df['expanded_urls'].duplicated()].count()
twitter_df['expanded_urls'].value_counts()
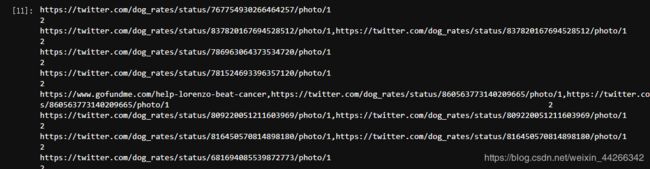
expanded url 可以让我知道 tweets 是重复的。所以 137 条 tweet 是重复的,为了证明这一点,我打开数据集发现有些 expanded url 有两条
twi_pred_df[twi_pred_df['jpg_url'].duplicated()].count()

predictions 的情况也一样,有66个重复行,不需要检查 scrapped_df,因为它将与twitter_df 合并,因此不会考虑重复的值。
3.
len(twi_pred_df) - len(twi_pred_df[(twi_pred_df['p1_dog']== True) & (twi_pred_df['p2_dog'] == True) & (twi_pred_df['p3_dog'] == True)])
# 输出 832
len(twi_pred_df) - len(twi_pred_df[(twi_pred_df['p1_dog']== True) | (twi_pred_df['p2_dog'] == True) | (twi_pred_df['p3_dog'] == True)])
# 输出 324
在 2075 项记录中,有 832 张可能是狗的图像。有 324 项,三个预测图像都不是狗,可以观察这 324 行,但可以肯定的是 342 张图肯定不是狗的图像
temp_df = twi_pred_df[(twi_pred_df['p1_dog']== False) | (twi_pred_df['p2_dog'] == False) | (twi_pred_df['p3_dog'] == False)]
temp_df.head()

打开第一个网址查看
from IPython.display import IFrame
IFrame('https://pbs.twimg.com/media/CT5KoJ1WoAAJash.jpg',width='100%', height=500)
很明显是乌龟
scrapped_df.info()
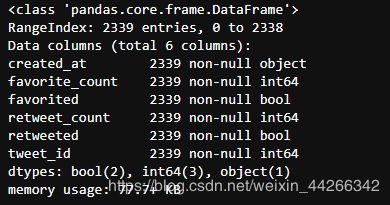
4.
twi_pred_df['p1'].value_counts()
5.
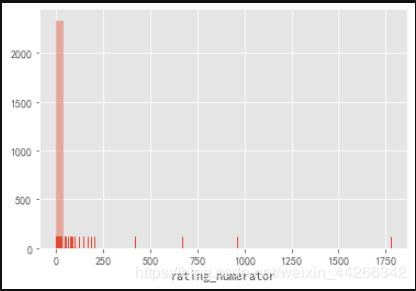
sns.distplot(twitter_df['rating_numerator'], kde=False, rug=True) # 评分分子
plt.show()
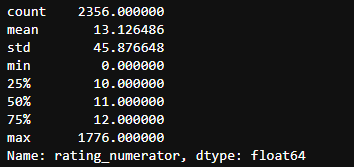
twitter_df['rating_numerator'].describe()
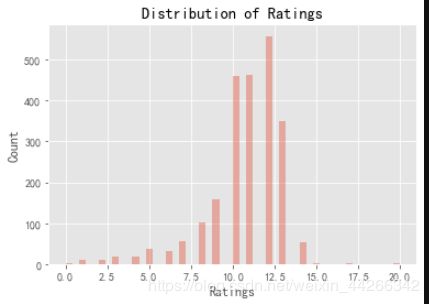
x = twitter_df[twitter_df['rating_numerator']<= 20.0].rating_numerator
sns.distplot(x, kde=False)
plt.xlabel('Ratings')
plt.ylabel('Count')
plt.title('Distribution of Ratings')
plt.show()
twitter_df['rating_numerator'].value_counts()
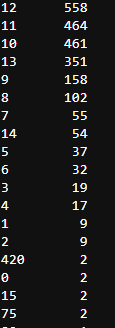
评分分子数据显示数据中有一些明显的异常值。为了检查这一点,我使用了describe 函数,很明显,我看到平均值是13,最大值是1776.为了获得更完整的计数器,我做了一个值计数,我发现有很多值是异常值,但也有低于 10 的值,这不太像他独特的评分系统。
6.
twitter_df['rating_denominator'].describe() # 评分分母

sns.distplot(twitter_df['rating_denominator'], kde=False, rug=True)
plt.show()
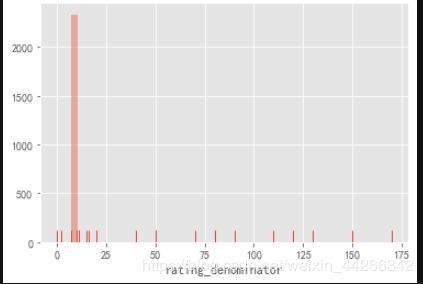
twitter_df['rating_denominator'].value_counts()
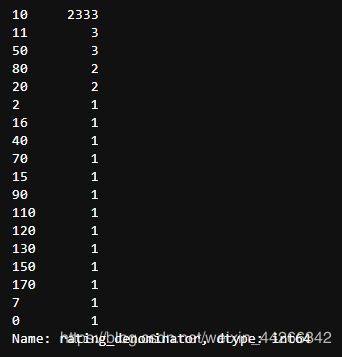
同样的题也出现在分母上,分母应该等于 10,但是我们也可以发现其他值
这是由以上分析所发现的问题:
质量问题
- 在 twitter_df 有 5 列有缺失值
- 大多数狗没有区分 doggo,floofer,pupper,puppo
- 狗的名字被贴错标签、打错标签、丢失。
- 为了更好分析
- 三个数据框都有重复值
- 评级问题:一些分母不是10,而一些分子低于10。有些推文没有评级。
- 所有的 tweet_id 都应该是字符串
- 数据类型不一致
整洁问题
- dog stage 包含4个不同的列
- 为了便于分析,可以将日期和时间分为日期列和时间列
3. Data Cleaning
# 备份原始数据
c_twitter_df = twitter_df.copy()
c_twitter_df.head()
c_pred = twi_pred_df.copy()
c_pred.head()
c_scrapped = scrapped_df.copy()
c_scrapped.head()
- 删除所 retweet_status 为空的行
c_twitter_df = c_twitter_df[c_twitter_df['retweeted_status_id'].notnull() == False]
- 删除 expanded_urls 的重复值
# keep='first' 保留第一次出现的项
c_twitter_df = c_twitter_df.drop_duplicates(subset = 'expanded_urls', keep='first')
- 删除 In c_twitter_df 所有缺失的行列
- in_reply_to_status_id
- in_reply_to_user_id
- retweeted_status_id
- retweeted_status_user_id
- retweeted_status_timestamp
c_twitter_df = c_twitter_df.drop(columns=['in_reply_to_status_id','in_reply_to_user_id','retweeted_status_id','retweeted_status_user_id','retweeted_status_timestamp'])
c_twitter_df.info()
c_twitter_df.head()
删除无用列 source,expanded_urls
c_twitter_df = c_twitter_df.drop(columns=['expanded_urls','source'])
c_twitter_df.info()
修改数据类型
使用 astype 将数据类型改为更合适的类型
c_twitter_df
- tweet_id => string
- timestamp => datetime
c_scrapped
- created_at => datetime
- tweet_id => string
c_pred
- tweet_id => string
c_twitter_df['tweet_id'] = c_twitter_df['tweet_id'].astype('str')
c_twitter_df['timestamp'] = pd.to_datetime(c_twitter_df['timestamp'])
c_scrapped['created_at'] = pd.to_datetime(scrapped_df['created_at'])
c_scrapped['tweet_id'] = c_scrapped['tweet_id'].astype('str')
c_pred['tweet_id'] = c_pred['tweet_id'].astype('str')
c_twitter_df.info()
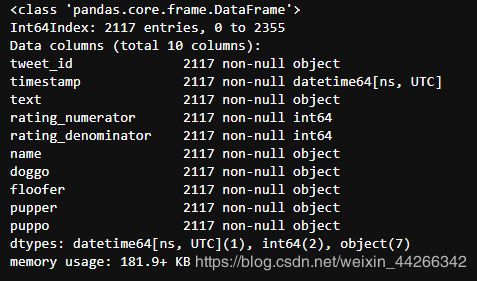
c_scrapped.info()
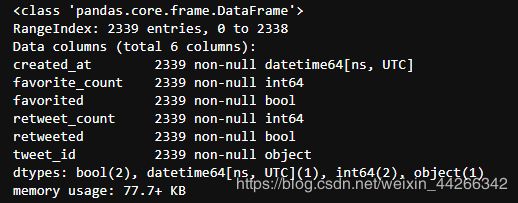
c_pred.info()
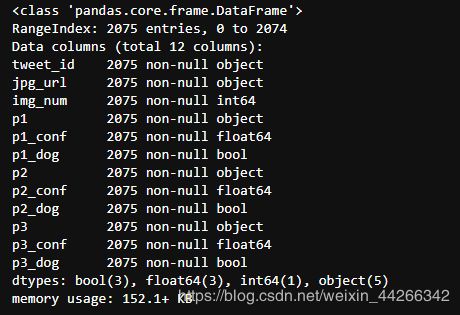
- doggo,floofer,pupper,puppo 列可融合为一列
- 但有些行不只一个 stage,这会干扰后面的分析,所以将这些行删除
c_twitter_df['doggo'] = c_twitter_df['doggo'].replace('None', 0)
c_twitter_df['doggo'] = c_twitter_df['doggo'].replace('doggo', 1)
c_twitter_df['floofer'] = c_twitter_df['floofer'].replace('None', 0)
c_twitter_df['floofer'] = c_twitter_df['floofer'].replace('floofer', 1)
c_twitter_df['pupper'] = c_twitter_df['pupper'].replace('None', 0)
c_twitter_df['pupper'] = c_twitter_df['pupper'].replace('pupper', 1)
c_twitter_df['puppo'] = c_twitter_df['puppo'].replace('None', 0)
c_twitter_df['puppo'] = c_twitter_df['puppo'].replace('puppo', 1)
c_twitter_df['None'] = 0
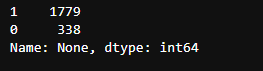
给没有 dog stage 行的 None 列赋值为 1
c_twitter_df.loc[(c_twitter_df['puppo']+c_twitter_df['floofer']+c_twitter_df['pupper']+c_twitter_df['doggo'] == 0),'None'] = 1
c_twitter_df['None'].value_counts()
检查一行是否有多个 dog stage
c_twitter_df[(c_twitter_df['puppo']+c_twitter_df['floofer']+c_twitter_df['pupper']+c_twitter_df['doggo']+c_twitter_df['None']> 1)]

将这 12 行删除,因为他们会对接下来的分析带来干扰
# ~ 反转
c_twitter_df = c_twitter_df[~(c_twitter_df['puppo']+c_twitter_df['floofer']+c_twitter_df['pupper']+c_twitter_df['doggo']> 1)]
len(c_twitter_df)
# 输出2105
c_twitter_df['None'].value_counts()

将doggo,floofer,pupper,puppo 融合为一列
# pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
# frame:要处理的数据
# id_vars:不需要被转换的列名
# value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了
# var_name和value_name是自定义设置对应的列名
# col_level :如果列是MultiIndex,则使用此级别。
values = ['doggo', 'floofer', 'pupper', 'puppo', 'None']
ids = [x for x in list(c_twitter_df.columns) if x not in values]
c_twitter_df = pd.melt(c_twitter_df, id_vars = ids, value_vars = values, var_name='stage')
c_twitter_df = c_twitter_df[c_twitter_df.value == 1]
c_twitter_df.drop('value', axis=1, inplace=True)
c_twitter_df.head()

# reset_index可以还原索引,重新变为默认的整型索引
# DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
# level控制了具体要还原的那个等级的索引
# drop为False则索引列会被还原为普通列,否则会丢失
c_twitter_df.reset_index(drop=True, inplace=True)
# 将 stage 转换为 category 类型
c_twitter_df.stage = c_twitter_df.stage.astype('category')
None 应该与之前相等
c_twitter_df['stage'].value_counts()
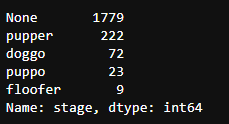
len(c_twitter_df)
# 输出 2105
清洗 Dog Predictions
c_pred['p1'].value_counts()

c_pred['p2'].value_counts()
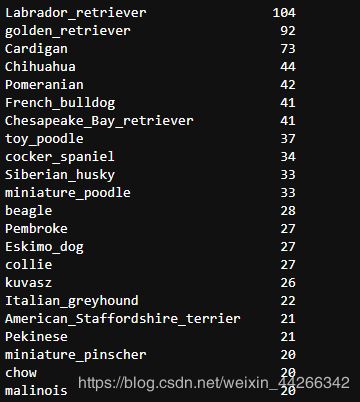
c_pred['p3'].value_counts()
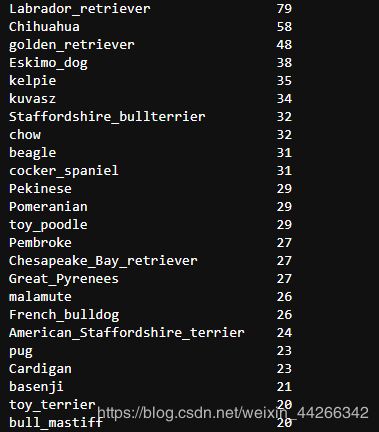
c_pred['p1'] = c_pred['p1'].str.lower()
c_pred['p1'] = c_pred['p1'].replace([' ','-'],'_')
c_pred['p2'] = c_pred['p2'].str.lower()
c_pred['p2'] = c_pred['p2'].replace([' ','-'],'_')
c_pred['p3'] = c_pred['p3'].str.lower()
c_pred['p3'] = c_pred['p3'].replace([' ','-'],'_')
c_pred['p1'].value_counts()
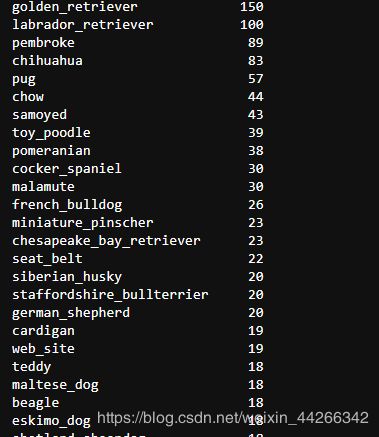
c_pred['p2'].value_counts()
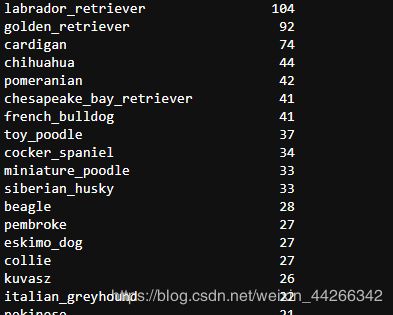
c_pred['p3'].value_counts()
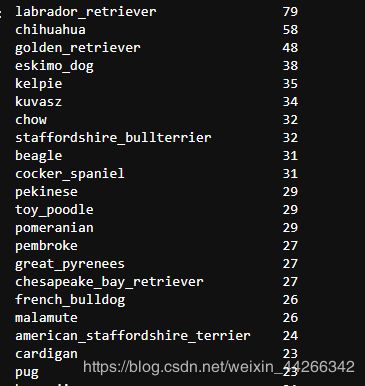
被预测的对象可能不是狗,如果三个预测结果都为真,那就创建 dog 做一个单独的预测栏,如果这三个预测都是错误的,那就不是dog
pred = ['p1_dog', 'p2_dog', 'p3_dog']
for p in pred:
c_pred[p] = c_pred[p].astype(int)
c_pred.loc[(c_pred['p1_dog']+c_pred['p2_dog']+c_pred['p3_dog'] == 0),'Prediction'] = 'not dog'
c_pred.loc[(c_pred['p1_dog']+c_pred['p2_dog']+c_pred['p3_dog'] == 1),'Prediction'] = 'mixed'
c_pred.loc[(c_pred['p1_dog']+c_pred['p2_dog']+c_pred['p3_dog'] == 2),'Prediction'] = 'mixed'
c_pred.loc[(c_pred['p1_dog']+c_pred['p2_dog']+c_pred['p3_dog'] == 3),'Prediction'] = 'dog'
c_pred['Prediction'].value_counts()

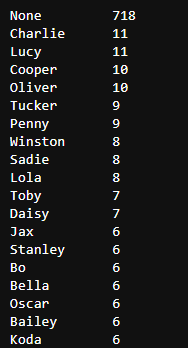
c_twitter_df['name'].value_counts()
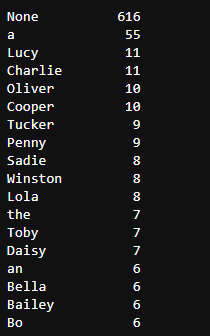
- Name 有明显错误,‘an’,‘a’和’the’ 都能被认为是名字,所以先将错误的名字去除
- 名字应该以大写开头,找出那些不是大写字母开头的名字
pd.set_option('display.max_colwidth', -1)
vals = c_twitter_df[~c_twitter_df['name'].str[0].str.isupper()]['name'].value_counts()
vals.keys()

# 将不正确的名字都变为 None
for val in vals.keys():
c_twitter_df['name'] = c_twitter_df['name'].replace(val,'None')
c_twitter_df['name'] = c_twitter_df['name'].replace('a','None')
c_twitter_df['name'] = c_twitter_df['name'].replace('an','None')
c_twitter_df['name'] = c_twitter_df['name'].replace('the','None')
c_twitter_df['name'].value_counts()
- rating_numerator、rating_denominator 列部分数据与text列中的原信息不符
- 删除错误的评分
rating_denominator
print("Count of tweets without '/10' in the text : {}".format(c_twitter_df[~c_twitter_df['text'].str.contains('/10')]['tweet_id'].count()))
print("Count of tweets without 10 rating_denominator : {}".format(c_twitter_df[c_twitter_df['rating_denominator'] != 10]['tweet_id'].count()))

c_twitter_df = c_twitter_df[c_twitter_df['text'].str.contains('/10')]
print("Count of tweets without 10 rating_denominator {}:".format(c_twitter_df[c_twitter_df['rating_denominator'] != 10].tweet_id.count()))
![]()
检查这 5 行,看看是否能手动修复
c_twitter_df[c_twitter_df['rating_denominator'] != 10].text
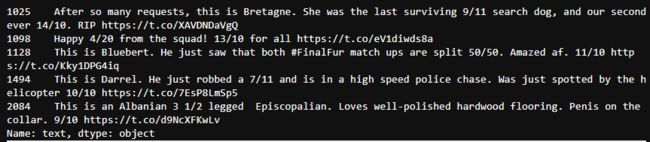
我们可以看到推文是正确的,因此手动修复数据
idx = c_twitter_df[c_twitter_df['rating_denominator'] != 10].index
for i in idx:
c_twitter_df.at[i, 'rating_denominator'] = 10
c_twitter_df['rating_denominator'].value_counts()
![]()
rating_numerator
c_twitter_df['rating_numerator'].value_counts()
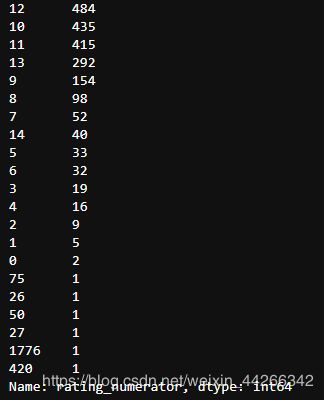
# strip 默认去除首尾空格
cannot_parse = set()
incorrect = set()
for i in c_twitter_df.index:
index = int(c_twitter_df.loc[i].text.find('/10'))
try:
numerator = int(c_twitter_df.loc[i].text[index-2:index].strip())
except:
cannot_parse.add(i)
continue
if numerator != c_twitter_df.loc[i].rating_numerator:
incorrect.add(i)
print('Indexes this code cannot parse: {}'.format(len(cannot_parse)))
print('Incorrect rating_numerator indexes:{}'.format(len(incorrect)))
![]()
for i in incorrect:
print('{} - {}'.format(i, c_twitter_df.loc[i]['text']))
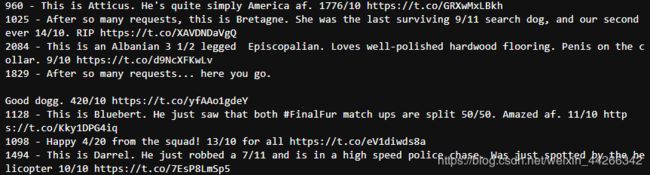
可以看到这些评分遵循了推文独特的评分机制,所以我们可以手动修复分子
c_twitter_df.loc[995,'rating_numerator'] = 9
c_twitter_df.loc[232,'rating_numerator'] = 8
c_twitter_df.loc[363,'rating_numerator'] = 13.5
c_twitter_df.loc[1198,'rating_numerator'] = 12
c_twitter_df.loc[1328,'rating_numerator'] = 8
c_twitter_df.loc[1457,'rating_numerator'] = 9
c_twitter_df.loc[1275,'rating_numerator'] = 9
c_twitter_df['rating_numerator'].value_counts()

连接表
由于 c_pred 是一组不同的信息,所以不需要将他与 c_twitter_df 结合
print(len(c_twitter_df))
print(len(c_pred))
print(len(c_scrapped))

# 移除不需要的信息
c_pred = c_pred.drop(columns=['p1_dog','p2_dog','p3_dog'])
c_scrapped = c_scrapped.drop(columns=['created_at','favorited','retweeted'])
c_twitter_df = c_twitter_df.drop(columns=['text'])
# 将 c_twitter 与 c_scrapped 连接
main_df = c_twitter_df.merge(c_scrapped, on='tweet_id',how='inner')
main_df.head()

Storing
将清洗好的数据保存
main_df.to_csv('../data/twitter_archive_master.csv', index=False)
c_pred.to_csv('../data/image_archive_master.csv', index=False)
Analysis
tweet_df = pd.read_csv('../data/twitter_archive_master.csv')
tweet_df.head()

image_df = pd.read_csv('../data/image_archive_master.csv')
image_df.head()
我们围绕以下几个问题进行分析:
- 评分对转发数有怎样的影响?
- 随着时间的推移,转发量和点赞数如何变化?
- 模型表现如何?
- 最受欢迎的狗名是什么?
- 有哪些类型的狗?
1. 评分如何影响推文转发量?
import seaborn as sns
plt.style.use('ggplot')
# 删除分子超过 20 的评分
ratings = tweet_df[tweet_df['rating_numerator'] < 20]['rating_numerator']
count = tweet_df[tweet_df['rating_numerator'] < 20]['retweet_count']
sns.scatterplot(ratings,count)
plt.xlabel('评分')
plt.ylabel('转发量')
plt.title('评分如何影响推文转发量?')
plt.show()

- 我们可以看到评分低于 10 的转发量都很少,评分高于 10 的,转发量也较多,评分为 13 的转发量最多
- 然而这可能是其他因素导致的,还不能说明两者间存在因果关系
2. 随着时间的推移,转发量和点赞数如何变化?
time = pd.to_datetime(tweet_df[tweet_df.favorite_count < 10000].timestamp).dt.date
fig, ax = plt.subplots(figsize=(20,10))
plt.plot_date(time,tweet_df[tweet_df.favorite_count < 10000].retweet_count,color='b' , label='retweet_count')
plt.plot_date(time,tweet_df[tweet_df.favorite_count < 10000].favorite_count, color='r', label='favorite_count')
plt.xlabel('时间')
plt.ylabel('数量')
plt.title('随着时间的推移,转发量和点赞数如何变化?')
plt.legend()
ax.xaxis.set_tick_params(rotation=90, labelsize=10)
plt.show()
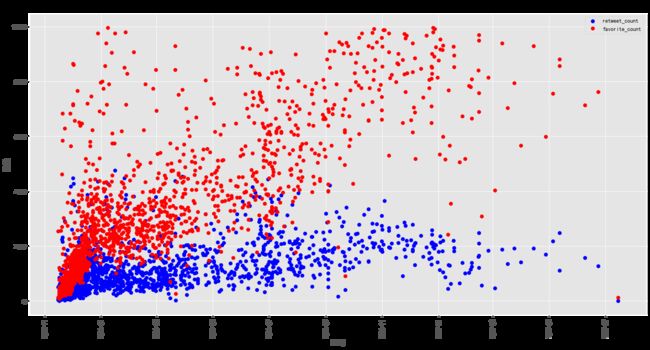
- 一个明显的趋势是:一开始,点赞数和转发数相似,但转发的数量更多。但是到了 2016 年和 2017 年,推特的数量变得越来越少 (通过蓝色和红色的小点的数量可以看出,但是点赞数越来越多。) 另一个值得注意的趋势是,点赞数在大幅增加,但在整个过程中,转发数最多也没有超过 5000
3. 模型表现如何?
image_df.describe()
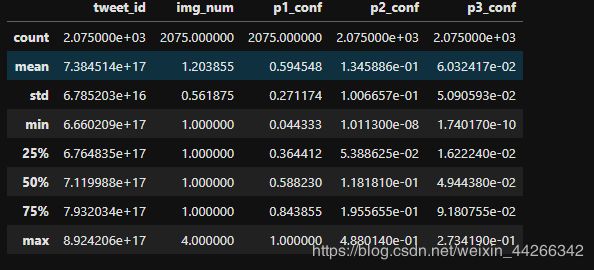
- 有些推文的 p1_conf 值为1,说明神经网络对其很有信心
- 但是 p2_conf,p3_conf 这两种预测好像信心较弱啊
我们看看 p1_conf 值为 1 的图吧
tweet = image_df[image_df.p1_conf == 1.0]
tweet

from IPython.display import IFrame
IFrame('https://pbs.twimg.com/media/CUS9PlUWwAANeAD.jpg',width='100%', height=500)

我们发现模型判定这张图片不是狗,但是当我们手动打开网址时,发现这是一只在看拼图的狗,模型可能没有抓取到狗,而将重点放到了拼图上。
4. 最受欢迎的狗名是什么?
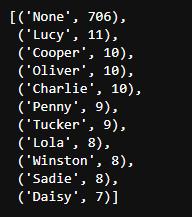
from collections import Counter
x = tweet_df['name']
count = Counter(x)
count.most_common(11)
5. 有哪些类型的狗?
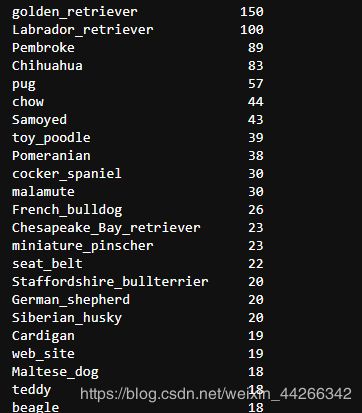
types = image_df[image_df.Prediction == 'dog'].p1.value_counts()
types
plt.bar(types[0:10].index,types[0:10])
plt.xticks(rotation='vertical')
plt.xlabel('Dog Types')
plt.ylabel('Number')
plt.title('有哪些类型的狗?')
plt.show()
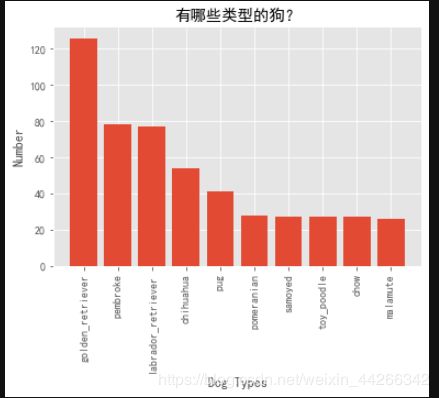
可以看到,最受大家喜欢的是金毛,接着是彭布罗克和拉布拉多犬。
通过这个项目我们了解到数据可视化的重要性,对于很多人来说,从一堆文字数据中发现规律是很难的,但是我们通过数据可视化,可以很明显发现其中的规律和错误。
最开始的数据探索是十分的重要,可以帮我们发现数据中存在的问题,有助于进一步分析和理解数据。