MySQL数据类型中的那些“坑”
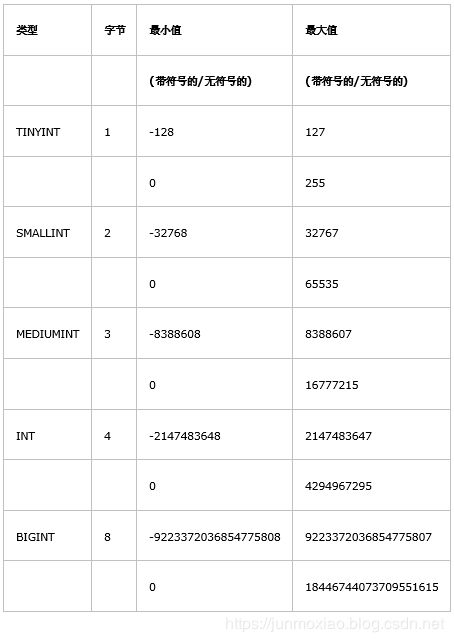
MySQL数据类型
- Int类型
- 有无符号
- INT(N),N是什么
- 自动增长
- 字符类型
- 排序规则
- 时间类型
- DATATIME与TIMESTAMP区别
- JSON类型
- JSON函数
- JSON索引
首先声明,文中说到的“坑”,其实都是MySQL的实现方式,只是你在用的时候可能自以为会这样,结果却是那样。所以,请让我代替MySQL借用“明学”的话:我不要你以为,我要我以为,你以为的没用,我以为的有用,好吗?大家都听我的!和我一起排“坑”吧!
Int类型
有无符号
无符号数,也就是正数。如果较小的无符号数减去较大的无符号数会怎么样呢?
create table test_unsigned(a int unsigned, b int unsigned);
insert into test_unsigned values(1, 2);
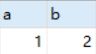
select a - b from test_unsigned;

这里报错,预料之中。但为什么是“BIGINT UNSIGNED”呢?笔者也没找到一个靠谱的答案,希望有高手可以留言解惑。
从这里可以看到,用无符号数在操作表的时候很可能会出现报错,这是需要避免的。这和 java 里要排除入参为 null 的道理一样。所以我们通常用有符号数。
INT(N),N是什么
create table test_int_n(a int(4) );
insert into test_int_n values(1);
insert into test_int_n values(123456);

感觉和没用设置(N)效果过一样。
其实设置(N)和zerofill搭配在一起才有效果:
create table test_int_n1(a int(4) zerofill);
insert into test_int_n1 values(1);
insert into test_int_n1 values(123456);
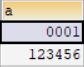
如图,十进制长度没有4(这里N为4)位大小的前面会用0填充。
其实你不设置N,MySQL也会默认给你设置为11。是11这个数是因为,设置的INT默认是有符号数,而有符号的INT最大值2147483647,这个十进制数是11位长的。
注:这里用的软件是SQLyog,用Navicat是看不到前面补充的0的。当然使用命令行的形式也是可以的。
自动增长
这列语法有错误吗?
create table test_auto_increment(a int auto_increment);
![]()
以下来玩猜一猜的游戏:
create table test_auto_increment(a int auto_increment primary key);
以下结果是什么?
insert into test_auto_increment values(NULL);
![]()
神(keng)奇(die)!插入null,实际上是插入了整数1。
继续插入:
insert into test_auto_increment values(0);
![]()
神(keng)奇(die)!插入0,实际上是插入了整数2。
大胆猜测,0 和 null 都是插不进去的,没有数据的时候插入任何一个都是 1 。再这之后,再插入,因为 1 已经有了,就会插入 1 的自增,2。实际上也就是这样。
继续插入:
insert into test_auto_increment values(-1);
![]()
神(keng)奇(die)!-1竟然可以插入,明明0都不行的。
继续插入:
insert into test_auto_increment values(null),(100),(null),(10),(null)
大胆猜测,这次应该插入的是 3,100,101,10,11,结果:
![]()
神(keng)奇(die)!居然没有11,来了个102!为什么呢?
因为MySQL自增是在最大主键的基础之上。如果插入了一个不可能插入的null,MySQL会给你插入最大的101之后。
继续插入:
insert into test_auto_increment values(0);
这下没毛病,绝对是插入103了,结果:
![]()
神(keng)奇(die)!居然整了个104!这里面就涉及到了自增锁的知识,这是MySQL非常底层的内容了,如果一定要解决可以把 innodb_autoinc_lock_mode 设置为0,但是性能会降低,好吧,试一试。
show VARIABLES like 'innodb_autoinc_lock_mode';

set innodb_autoinc_lock_mode = 0;

好吧,劝退了。应该是要去配置文件配置了。我也不深究了。深究的意义对于我来说意义不大。
其实规避这个问题最好的办法,就是写逻辑的时候,对于自增主键,要避免插入 0 和 null 。
注:别以为这不是干货,面试题哟~
字符类型

你需要注意的是,只有CHAR(N)和VARCHAR(N)里的N代表的是字符个数,其它都是字节个数。
排序规则
字符集我们通常会选择utf8mb4,每4个字节存储一个utf8字符。而MySQL里的utf8字符集,每3个字节存储一个utf8字符,汉字在utf8里一般占2~4个字节。这其实也是一个“坑”,如果你还在傻乎乎的使用utf8,那就…
那么排序规则选什么呢?
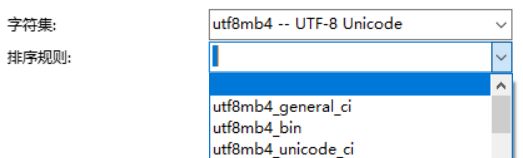
bin代表用二进制比较字符,是区分大小写的
ci( casesensitive ignore)代表不区分大小写,其中:
utf8mb4_unicode_ci 是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
utf8mb4_general_ci 没有实现Unicode排序规则,在遇到某些特殊语言或字符是,排序结果可能不是所期望的,当然它的排序更快了,我们一般也不用它
建表:
create table test_ci (a varchar(10), key(a));
insert into test_ci values('a');
insert into test_ci values('A');
当你的数据库设置的字符排序规则是utf8mb4_bin的时候,默认创建出来的表排序规则也是utf8mb4_bin
select * from test_ci where a = 'a';
![]()
改变数据库的字符排序规则为utf8mb4_unicode_ci ,默认创建出来的表排序规则也是utf8mb4_unicode_ci
重新创建表,然后
select * from test_ci where a = 'a';
![]()
当然,你可以在创建表的时候就选择好排序规则从而不受数据库的影响
在数据库的字符排序规则为utf8mb4_unicode_ci 的情况下,重新创建表
create table test_ci (a varchar(10), key(a)) DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
insert into test_ci values('a');
insert into test_ci values('A');
select * from test_ci where a = 'a';
![]()
当然,还有更高级的操作:
- 修改数据库
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci; - 修改表
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; - 修改表字段
ALTER TABLE table_name CHANGE column_name column_name VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
那么坑来了,在数据库和表都是utf8mb4_bin的情况下,进行如下查询,你认为会出现什么呢:
select 'a' = 'A';
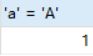
还是无法区分a和A啊!这是因为这个查询无关数据库和表,无关服务端,它只和客户端有关。
set names utf8mb4 collate utf8mb4_bin;
这条语句能改变客户端的字符集和排序规则,再查询:
select 'a' = 'A';
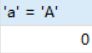
而且,你另外创建一个窗口查询如果还是想让select 'a' = 'A';的结果为0得重新
set names utf8mb4 collate utf8mb4_bin;,所以基本上这句话是没什么用的。
但你要注意不要写出这样的语句:select * from test_ci where 'a' = 'A';:
set names utf8mb4 collate utf8mb4_bin;
select * from test_ci where 'a' = 'A';
![]()
set names utf8mb4 collate utf8mb4_unicode_ci;
select * from test_ci where 'a' = 'A';

这算是干货吧!
时间类型
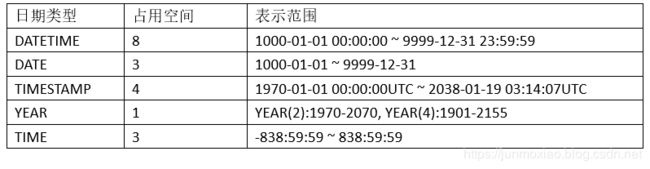
DATATIME与TIMESTAMP区别
创建表
create table test_time(a timestamp, b datetime);
insert into test_time values (now(), now());
select * from test_time;

select @@time_zone;

set time_zone='+00:00';
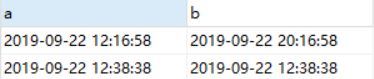
select * from test_time;

由此可见,timestamp 是支持换时区的,而 datetime 一直使用的系统时区。
-
修改全局的time_zone
set global time_zone='+8:00'; -
修改当前会话的time_zone
set time_zone='+8:00'; -
查看全局的time_zone
select @@global.time_zone; -
查看当前会话的time_zone
select @@time_zone;或者
select @@session.time_zone;
至于修改系统时区,那就得修改操作系统上的时区了
在Windows上:
insert into test_time values (now(), now());
select * from test_time;
那么,用哪个好呢?
- 考虑使用范围
- 考虑时区问题
- 考虑占用空间
JSON类型
create table json_user (
uid int auto_increment,
data json,
primary key(uid)
);
insert into json_user values (
null, '{
"name":"Jack",
"age":18,
"address":"Beijing"
}' );
insert into json_user values (
null, '{
"name":"Rose",
"age":18,
"mail":"[email protected]"
}');
用SQLyog,Navicat看不到json(可能是我版本低了):

JSON函数
- json_extract(抽取)
SELECT json_extract('[10, 20, [30, 40]]', '$[0]'); #10
SELECT json_extract('[10, 20, [30, 40]]', '$[1]');#20
SELECT json_extract('[10, 20, [30, 40]]', '$[2]');# [30, 40]
select
json_extract(data, '$.name'),
json_extract(data, '$.address')
from json_user;

- json_object(将对象转为json)
select json_object("name", "John", "email", "[email protected]", "age",19);
![]()
- json_insert (插入数据)
SET @json = '{ "a": 1, "b": [2, 3]}';
SELECT json_insert(@json, '$.a', 10, '$.c', '[true, false]');
![]()
已有的插不了,没有的才能插进去
- json_merge(合并数据)
select json_merge('{"name": "Tom"}', '{"id": 7}');
![]()
- 更多
https://dev.mysql.com/doc/refman/5.7/en/json-function-reference.html
JSON索引
JSON 类型数据本身无法直接创建索引,需要将需要索引的 JSON数据重新生成虚拟列(Virtual Columns) 之后,对该列进行索引
create table test_inex_1(
data json,
gen_col varchar(10) generated always as (json_extract(data, '$.name')),
index idx (gen_col)
);
insert into test_index_1(data) values ('{"name":"Jack", "age":18}');
insert into test_index_1(data) values ('{"name":"Rose", "age":17}');
select * from test_inex_1;

那么,“坑”来了:
select data from test_inex_1 where gen_col="Jack";
这执行句话的结果是什么呢?
答案是什么都查不出来。因为存储的是"Jack" ,而不是Jack。
正确的做法是:
select data from test_inex_1 where gen_col='"Jack"';
![]()
当然也有更优雅的做法:
create table test_index_2 (
data json,
gen_col varchar(10) generated always as (
json_unquote(
json_extract(data, "$.name")
)),
index idx (gen_col)
);
insert into test_index_2(data) values ('{"name":"Jack", "age":18}');
insert into test_index_2(data) values ('{"name":"Rose", "age":17}');
select * from test_inex_2;

select data from test_index_2 where gen_col="Jack";
![]()
结语:用上一款应用之前,或是遇到问题之后,最好是看官方文档。当然,官方文档中也是有“坑”的(你可能不信),而且如果你想来得快的话,看博客真心是一种不错的方式。
参考:Deer——mysql优化
相关文章:
常用的Mysql的权限控制介绍
MySQL存储引擎
详解MySQL中的锁
详解MySQL中的事务(四种隔离级别、间隙锁等),看完还不懂你来打我