Python爬虫之xpath的基本使用
1.XPath介绍
这篇文章比较混,emmm,基础使用就是我写的这三种方法,详细可以看看参考的那个链接。
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
我的理解就很像路径查找法,就像你在windows里面找文件一样,找到对应路径就可以了,然后bs4更想标签选择法,根据标签迭代定位。
官方帮助文档:https://www.w3.org/TR/xpath/
2.常用规则
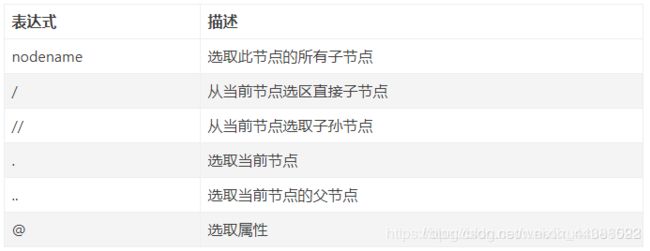
3.相关环境的安装
pip install lxml
4.示例
4.1 绝对路径查找内容
对应的xpath可以通过浏览器复制得到。
先通过F12或者检查等方法调出浏览器调试模式。
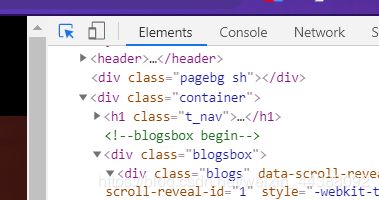
然后选中右上角的箭头去点击你想要的内容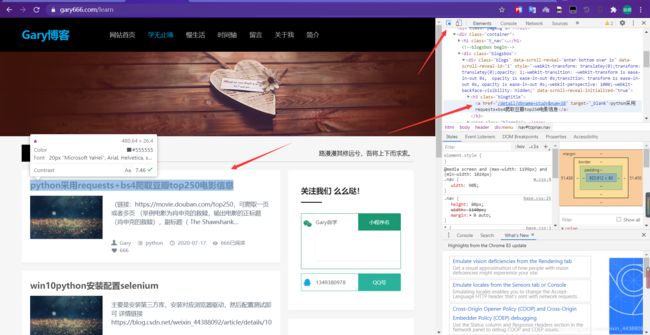
然后在右边下面的箭头右键,找到copy,然后扩展菜单中找到copy Xpath点击即可,然后复制到xpath(“复制的内容”)应用即可。
4.1.1获取某个标签的内容
注意,获取a标签的所有内容,a后面就不用再加正斜杠,否则报错。
# -*- coding: utf-8 -*-
# author:Gary
# 第一步,导入需要用到的库
import requests
from lxml import etree
res=requests.get('https://www.gary666.com/learn')#获取网页内容
res.encoding = res.apparent_encoding # 设置编码,防止由于编码问题导致文字错乱
# 利用 etree.HTML 把字符串解析成 HTML 文件
#res.text就是获取把网页内容转为字符串
html = etree.HTML(res.text)
#绝对路径定位:
title=html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a')#通过调用xpath这个方法就可以获取到对应路径的内容,返回一个列表,需要通过循环输出
for i in title:
print(i.text)#.text输出文本内容
title=html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a/text()')[0]#直接通过text()方法获取文本
print(title)
4.1.2获取某个标签的属性
这里可以通过遍历拿到某个属性的值,查找标签的内容,通过@属性名获取
title_href=html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a/@href')[0]#通过/@属性名即可获取对应的属性值
print(title_href)
4.1.3获取指定标签对应属性值的内容
使用xpath拿到得都是一个个的ElementTree对象,如果需要查找内容的话,还需要遍历拿到数据的列表。
查到绝对路径下a标签属性等于/detail?dbname=study&num=38的内容。
title2=html_data = html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a[@href="/detail?dbname=study&num=38"]/text()')[0]
print(title2)
5.完整代码
# -*- coding: utf-8 -*-
# author:Gary
# 第一步,导入需要用到的库
import requests
from lxml import etree
res = requests.get('https://www.gary666.com/learn') # 获取网页内容
res.encoding = res.apparent_encoding # 设置编码,防止由于编码问题导致文字错乱
# 利用 etree.HTML 把字符串解析成 HTML 文件
# res.text就是获取把网页内容转为字符串
html = etree.HTML(res.text)
# 获取某个标签的内容
# 绝对路径定位:
title = html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a') # 通过调用xpath这个方法就可以获取到对应路径的内容,返回一个列表,需要通过循环输出
for i in title:
print(i.text) # .text输出文本内容
# 获取某个标签的属性的值
title1 = html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a/text()')[0] # 直接通过text()方法获取文本
print(title1)
title_href = html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a/@href')[0] # 通过/@属性名即可获取对应的属性值
print(title_href)
# 获取指定标签对应属性值的内容
title2 = html_data = html.xpath('/html/body/div[2]/div[1]/div[1]/h3/a[@href="/detail?dbname=study&num=38"]/text()')[0]
print(title2)
6.参考
https://blog.csdn.net/xunxue1523/article/details/104584886