Python 字符串函数的学习演练
本文参考[python字符串函数用法大全]进行学习演练。(https://blog.csdn.net/qq_40678222/article/details/83032178?utm_source=copy)
在这里以截图的方式将自己练习的过程和结果呈现给大家。
一、关于大小写的函数
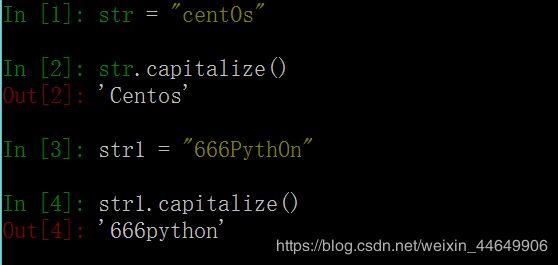
1. capitalize() # 将字符串的第一个字母变成大写,其余字母变为小写。请参照下图细细体会。
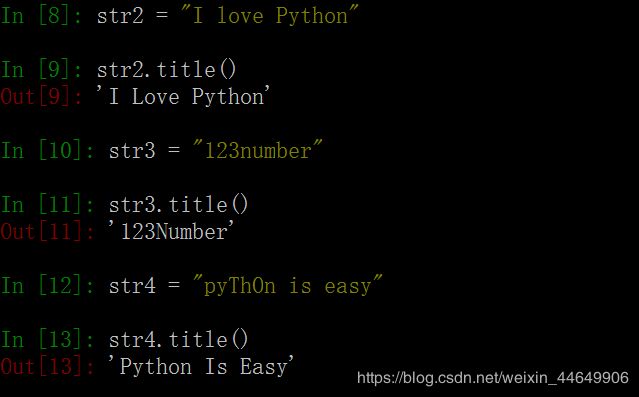
2. title()函数 # 返回一个 满足标题格式 的字符串。即所有英文单词首字母大写,其余英文字母小写。
3. swapcase()函数 # 将字符串str中的大小写字母同时进行互换。即将字符串str中的大写字母转换为小写字母,将小写字母转换为大写字母。
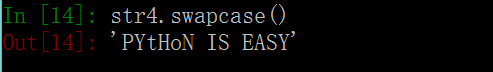
4. lower()函数 # 将字符串中的所有大写字母转换为小写字母。
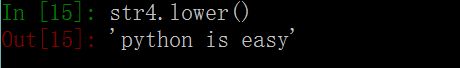
5. upper()函数 # 将字符串中的所有小写字母转换为大写字母。

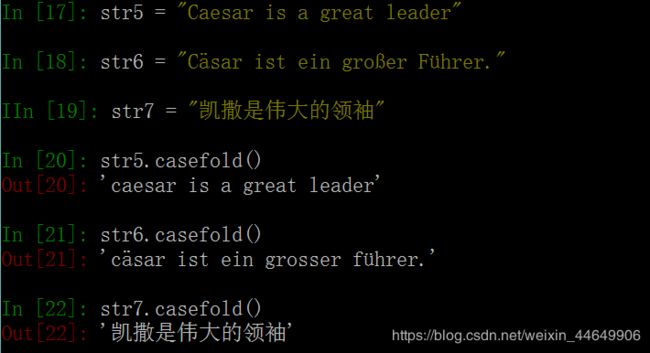
6. casefold()函数 # 将字符串中的所有大写字母转换为小写字母。也可以将非英文 语言中的大写转换为小写。
二、字符串填充
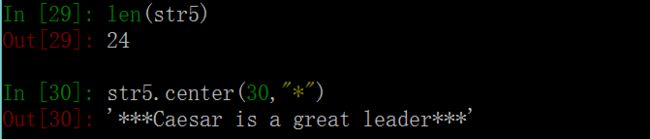
7. center()函数 # 返回一个长度为width,两边用fillchar(单字符)填充的字符串,即字符串str居中,两边用fillchar填充。若字符串的长度大于width,则直接返回字符串str。
语法:str.center(width , “fillchar”) -> str 返回字符串 注意:引号不可省 width
—— 指定字符串的输出长度。 fillchar—— 将要填充的单字符,默认为空格。
8. ljust()函数 # 返回一个原字符串左对齐,并使用fillchar填充(默认为空格)至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
语法: str.ljust(width, fillchar) -> str 返回一个新的字符串 width —— 指定字符串的输出长度。
fillchar—— 将要填充的单字符,默认为空格。

9. rjust()函数 # 返回一个原字符串右对齐,并使用fillchar填充(默认为空格)至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
语法: str.ljust(width, fillchar) -> str 返回一个新的字符串

10. zfill()函数 # 返回指定长度的字符串,使原字符串右对齐,前面用0填充到指定字符串长度。
语法:str.zfill(width) -> str 返回一个字符串 width ——
指定字符串的长度,但不能为空。若指定长度小于字符串长度,则直接输出原字符串。

三、统计字符次数
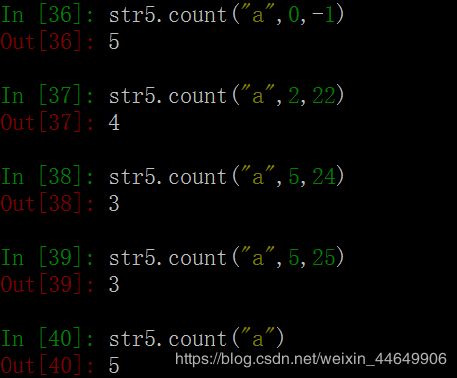
11. count()函数 # 统计字符串里某个字符出现的次数。可以选择字符串索引的起始位置和结束位置。
语法:str.count(“char”, start,end) 或 str.count(“char”) -> int 返回整数
str —— 为要统计的字符(可以是单字符,也可以是多字符)。 star —— 为索引字符串的起始位置,默认参数为0。 end —— 为索引字符串的结束位置,默认参数为字符串长度即len(str)。
本例中字符串str5长度是0-23总共24,故输入大于23的数也没影响。
四、查找指定字符(子字符串)位置
15. find()函数 # 查找字符串中指定的子字符串sub第一次出现的位置,可以规定字符串的索引查找范围。若无则返回 -1。
语法:str.find(sub,start,end) -> int 返回整数 sub —要索引的子字符串。 start
—索引的起始位置。默认值为0。 end —索引的结束位置。默认值为字符串长度len(str)。 [start,end) 不包括end。

16. rfind()函数 # 查找字符串中指定的子字符串sub最后一次出现的位置,可以规定字符串的索引查找范围。若无则返回 -1。
语法:str.rfind(sub,start,end) -> int 返回整数 sub —要索引的子字符串。 start
—索引的起始位置。默认值为0。 end —索引的结束位置。默认值为字符串长度len(str)。 [start,end) 不包括end。
注:rfind()函数用法与find()函数相似,rfind()函数返回指定子字符串最后一次出现的位置,find()函数返回指定子字符串第一次出现的位置。

17. index()函数
描述:查找字符串中第一次出现的子字符串的位置,可以规定字符串的索引查找范围[star,end)。若无则会报错。
语法:str.index(sub, start, end) -> int 返回整数
sub —— 查找的子字符串。 start —— 索引的起始位置,默认为0。 end —— 索引的结束位置,默认为字符串的长度。
[start,end) 不包括end。

注意:index()函数和find()函数类似,但index()函数没有找到子字符串会报错。
18. rindex()函数 # 查找字符串中最后一次出现的子字符串的位置,可以规定字符串的索引查找范围[star,end),若无则会报错。
语法:str.rindex(sub, start, end) -> int 返回整数。
sub —— 查找的子字符串。 start —— 索引的起始位置,默认为0。 end —— 索引的结束位置,默认为字符串的长度。
[star,end)
注:rindex()函数用法与index()函数相似,rindex()函数返回指定子字符串最后一次出现的位置,index()函数返回指定子字符串第一次出现的位置。

五、格式化输出
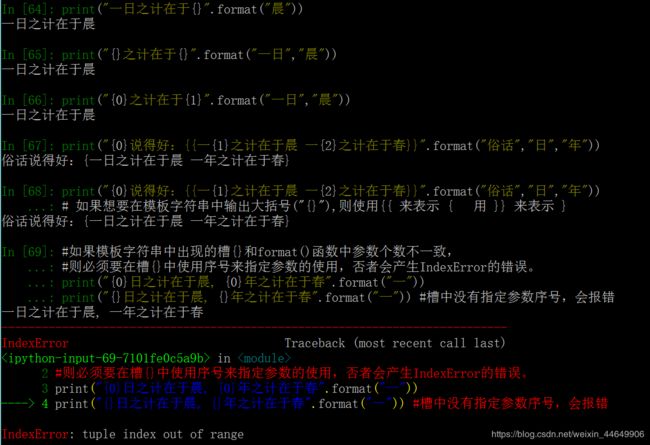
19. format()函数 # 返回一个格式化的字符串。
语法:str.format(*args, **kwargs) ——> str 返回字符串
[模板字符串].format(逗号分隔的参数) 或 {参数序号:格式控制标记}.format(逗号分隔的参数)
它是通过{}和:来代替%。 模板字符串是一个由槽(用大括号{}来表示)和字符串组成的字符串,用来控制字符串的显示效果。
大括号{}对应着format()中逗号分隔的参数。 format()基本用法 : 语法:[模板字符串].format(逗号分隔的参数)
通过列表格式化输出

通过字典格式化输出

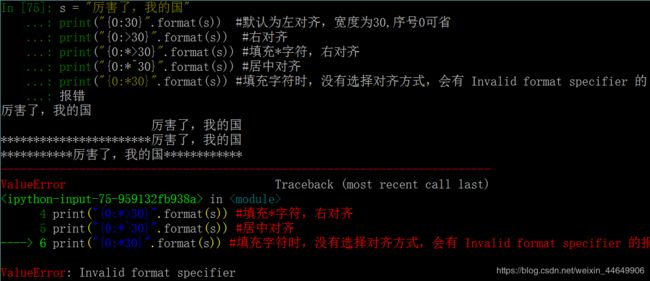
格式控制标记规则:[填充], [对齐], [宽度], [,], [.精度], [类型]
这六个规则是可以任意组合使用的,但要按以上顺序使用。不过一般可以分为两组。一组为:[填充] [对齐] [宽度] 主要用于规范字符串的显示格式。
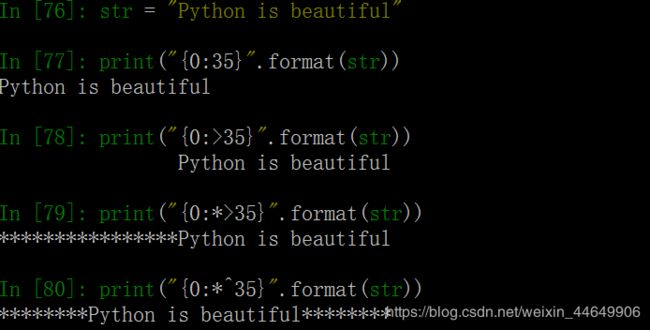
格式控制标记规则也可以用变量来表示,即用槽{}来指定对应的格式控制标记规则。
s = "厉害了,我的国"
a = "*"
b = "^"
c = 30
d = ["<","^",">"]
print("{0:{1}{2}{3}}".format(s,a,b,c)) #居中对齐,宽度为30,填充字符为*
print("{0:{1}{2[2]}{3}}".format(s,a,d,c))#右对齐,用列表选择对齐方式。
print("{0:{1}{2[0]}{3}}".format(s,a,d,c))
---------------------------------------------------------------------------------------------------------
***********厉害了,我的国************
***********************厉害了,我的国
厉害了,我的国***********************
另一组为:[,] [.精度] [类型] 主要于规范数字的输出格式和控制字符串的输出长度。
print("{0:,}".format(123456789)) # 千位分隔符
print("{:,.3}".format(123456.123)) #保留3为有效数字
print("{:.3}".format("厉害了,我的国")) # 输出前三个字符
#输出整数类型的格式化规则:
#print("输出整数的二进制形式:{0:b}\n输出整数对应的Unicode字符:{0:c}\n输出整数的十进制形式:{0:d}\n输出整数的八进制形式:{0:o}\n输出整数的小写十六进制形式:{0:x}\n输出整数的大写写十六进制形式:{0:X}".format(123456))
# 等效于一下语句:
print("输出整数的二进制形式: {:b}".format(123456))
print("输出整数对应的Unicode字符: {:c}".format(123456))
print("输出整数的十进制形式: {:d}".format(123456))
print("输出整数的八进制形式: {:o}".format(123456))
print("输出整数的小写十六进制形式: {:x}".format(123456))
print("输出整数的大写写十六进制形式: {:X}".format(123456))
#输出浮点数类型的格式化规则:
print("输出浮点数对应的小写字母e的指数形式: {:e}".format(123456.123456))
print("输出浮点数对应的大写字母E的指数形式: {:E}".format(123456.123456))
print("输出标准浮点数形式: {:f}".format(123456.123456))
print("输出浮点数的百分比形式: {:%}".format(123456.123456))
#对比 [.精度]可以控制小数部分的输出长度
print("输出浮点数对应的小写字母e的指数形式: {:.3e}".format(123456.123456))
print("输出浮点数对应的大写字母E的指数形式: {:.3E}".format(123456.123456))
print("输出标准浮点数形式: {:.3f}".format(123456.123456))
print("输出浮点数的百分比形式: {:.3%}".format(123456.123456))
----------------------------------------------------------------------------------------------------------------------
123,456,789
1.23e+05
厉害了
输出整数的二进制形式: 11110001001000000
输出整数对应的Unicode字符: ?
输出整数的十进制形式: 123456
输出整数的八进制形式: 361100
输出整数的小写十六进制形式: 1e240
输出整数的大写写十六进制形式: 1E240
输出浮点数对应的小写字母e的指数形式: 1.234561e+05
输出浮点数对应的大写字母E的指数形式: 1.234561E+05
输出标准浮点数形式: 123456.123456
输出浮点数的百分比形式: 12345612.345600%
输出浮点数对应的小写字母e的指数形式: 1.235e+05
输出浮点数对应的大写字母E的指数形式: 1.235E+05
输出标准浮点数形式: 123456.123
输出浮点数的百分比形式: 12345612.346%
六、判断问题(返回bool类型)
21. endswith()函数 # 判断字符串是否以指定字符或子字符串结尾。
22. startswith()函数 # 判断字符串是否以指定字符或子字符串开头。
23. isalnum()函数 # 检测字符串是否由字母和数字组成。
24. isalpha()函数 # 检测字符串是否只由字母组成。
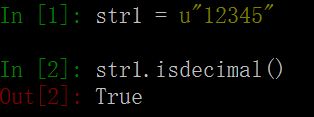
25. isdecimal()函数 # 检查字符串是否只包含十进制字符。该方法只存在于unicode对象中。
注意:定义一个十进制字符串,只需要在字符串前添加前缀 ‘u’ 即可。
26. isdigit()函数 # 检测字符串是否只由数字组成.
27. isidentifier()函数 # 判断str是否是有效的标识符。str为符合命名规则的变量,保留标识符则返回True,否则返回False。
28. islower()函数 # 检测字符串中的字母是否全由小写字母组成。(字符串中可包含非字母字符)
29. isupper()函数 # 检测字符串中的字母是否全由大写字母组成。(字符串中可包含非字母字符)。
30. isnumeric()函数 # 测字符串是否只由数字组成。这种方法是只适用于unicode对象。
注:把一个字符串定义为Unicode,只需要在字符串前添加 前缀 ‘u’
31. isprintable()函数 # 判断字符串中是否有打印后不可见的内容。如:\n \t 等字符。
32. isspace()函数 # 检测字符串是否只由空格组成。
33. istitle()函数 # 检测判断字符串中所有单词的首字母是否为大写,且其它字母是否为小写,字符串中可以存在其它非字母的字符。
七、字符串两端
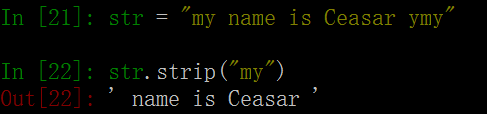
34. strip()函数 # 从字符串str中去掉在其左右两边chars中列出的字符。
注:chars传入的是一个字符数组,编译器去除两端所有相应的字符,直到出现第一个在chars中不匹配的字符。详看示例。

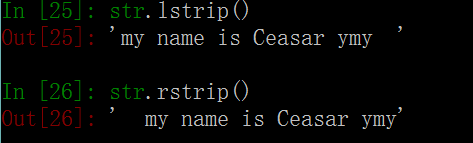
35. lstrip()函数 # 从字符串str中去掉在其左边chars中列出的字符。
36. rstrip()函数 # 从字符串str中去掉在其右边chars中列出的字符。
chars —— 要去除的字符 默认为空格或换行符。
八、解决 制表 翻译 问题
37. maketrans()函数 # 制作翻译表,删除表,常与translate()函数连用。
即:返回用于str.translate()函数翻译的的转换表。
语法:maketrans(x, y=None, z=None, /) 返回可用于str.translate()函数的转换表
如果只有一个参数x,它必须是一个字典且为Unicode形式的映射。
如果有两个参数x和y,它们必须是长度相等的字符串,并且在结果映射中,x中的每个字符都将映射到y中相同位置的字符(Unicode形式的映射)。
如果有三个参数x,y和z. x和y用法同上,z为指定要删除的字符串,其结果中的字符将一一映射为:None。 bytes.maketrans(x,y) 和
bytearray.maketrans(x,y) 必须要有x和y两个参数。 注:z的长度可以和x和y不同。
38. translate()函数 # 过滤(删除),翻译字符串。即根据maketrans()函数给出的字符映射转换表来转换字符串中的字符。
注:translate()函数是先过滤(删除),再根据maketrans()函数返回的转换表来翻译。
- table —— 转换表,转换表是通过maketrans()函数转换而来。
- deletechars —— 字符串中要过滤(删除)的字符。 解决分割字符串问题:
39. partition()函数 # 根据指定的分隔符(sep)将字符串进行分割。从字符串左边开始索引分隔符sep,索引到则停止索引。
语法: str.partition(sep) -> (head, sep, tail)
返回一个三元元组,head:分隔符sep前的字符串,sep:分隔符本身,tail:分隔符sep后的字符串。
- sep —— 指定的分隔符。 如果字符串包含指定的分隔符sep,则返回一个三元元组,第一个为分隔符sep左边的子字符串,第二个为分隔符sep本身,第三个为分隔符sep右边的子字符串。
- 如果字符串不包含指定的分隔符sep,仍然返回一个三元元组,第一个元素为字符串本身,第二第三个元素为空字符串
40. rpartition()函数 # 根据指定的分隔符(sep)将字符串进行分割。从字符串右边(末尾)开始索引分隔符sep,索引到则停止索引。
语法:str.rpartition(sep) -> (head, sep, tail)
返回一个三元元组,head:分隔符sep前的字符串,sep:分隔符本身,tail:分隔符sep后的字符串。
- sep —— 指定的分隔符。 如果字符串包含指定的分隔符sep,则返回一个三元元组,第一个为分隔符sep左边的子字符串,第二个为分隔符sep本身,第三个为分隔符sep右边的子字符串。
- 如果字符串不包含指定的分隔符sep,仍然返回一个三元元组,第一个元素为字符串本身,第二第三个元素为空字符串。 注:rpartition()函数与partition()函数用法相似,rpartition()函数从右边(末尾)开始索引,partition()函数从左边开始索引
41. split()函数 # 拆分字符串。通过指定分隔符sep对字符串进行分割,并返回分割后的字符串列表。
语法: str.split(sep=None, maxsplit=-1) -> list of strings 返回 字符串列表
或str.split(sep=None, maxsplit=-1)[n]
- sep —— 分隔符,默认为空格,但不能为空即(")。
- maxsplit —— 最大分割参数,默认参数为-1。
- [n] —— 返回列表中下标为n的元素。列表索引的用法。
42. rsplit()函数 # 拆分字符串。通过指定分隔符sep对字符串进行分割,并返回分割后的字符串列表,类似于split()函数,只不过 rsplit()函数是从字符串右边(末尾)开始分割。
语法: str.rsplit(sep=None, maxsplit=-1) -> list of strings 返回 字符串列表
或str.rsplit(sep=None, maxsplit=-1)[n]
- sep —— 分隔符,默认为空格,但不能为空即(")。
- maxsplit —— 最大分割参数,默认参数为-1。
- [n] —— 返回列表中下标为n的元素。列表索引的用法。
43. splitlines()函数 # 按照(’\n’, ‘\r’, \r\n’等)分隔,返回一个包含各行作为元素的列表,默认不包含换行符。
| 符号 | 描述 |
|---|---|
| \n | 换行符 |
| \r | 回车行 |
| – | – |
| \r\n | 回车+换行 |
语法:str.splitlines(keepends) -> list of strings 返回 字符串列表
- keepends —— 默认参数为False ,译为 不保留换行符。参数为True , 译为 保留换行符。
44. join()函数 # 将iterable变量的每一个元素后增加一个str字符串。
语法: str.join(iterable) -> str 返回字符串
即:返回一个以str作为分隔符,将iterable中的各元素合并连接成一个新的字符串。
- str——分隔符。可以为空。
- iterable—— 要连接的变量 ,可以是 字符串,元组,字典,列表等。
九、解决替换问题
45. replace()函数 # 返回字符串str的副本,所有old子字符串被替换为new字符串。
语法:str.replace(old, new, count) -> str 返回字符串str的副本
- old —— 将被替换的子字符串。
- new —— 新子字符串,用于替换old子字符串。
- count —— 替换的次数,默认全部替换。