Python之爬虫爬取豆瓣短评及可视化图表制作
中日版《深夜食堂》豆瓣短评爬取及数据分析-------Python爬虫以及词云图、折线图、饼图制作
文章目录
- 中日版《深夜食堂》豆瓣短评爬取及数据分析-------Python爬虫以及词云图、折线图、饼图制作
- 内容总述
- 数据收集
- 可视化图表制作
- 词云图
- 评论数量走势折线图
- 各级评分数量柱状图及各级评分占比饼图
- 数据分析
- 结论
内容总述
09年改编自同名漫画的日版《深夜食堂》播出后受到广泛好评,17年翻拍自日版《深夜食堂》的中版《深夜食堂》却骂声不断,还在豆瓣上创造了2.8分的低分记录,被调侃为黄小厨和他的明星朋友们。两部题材一致的剧,为何评价有如此的差别?我们在公认较有参考价值的平台豆瓣上爬取中日两版《深夜食堂》的短评来分析一下评价倾向以及话题焦点,探寻中版《深夜食堂》频遭吐槽的原因。
我们爬取了短评豆瓣中日两版《深夜食堂》短评各五百条收集至Excel文档,内容包括评论者昵称、时间、评分、评论内容。利用python的制作由评论内容生成的词云图、由评论时间生成的评论评论数量走势折线图、由评分生成的各级评分数量柱状图及各级评分占比饼图,根据可视化图表进行分析。*
*综合各项分析我们得出低评分原因:
1.原版内容深入人心,翻版瑕疵会被放大
2.部分观众在前几集弃剧,所评出评分不是基于全局剧情
3.广告硬性植入
4.演员演技让人不满意
*从这部剧的原版和翻拍版的对比可以看出,翻拍的影视剧要想有更大的吸引力,就要多感悟原版的精髓,仅靠明星的热度而没有出色的演技也无法博得观众眼球,同时内置营销要适度,过火的话必会引起观众反感。
数据收集
利用Python爬虫爬取短评豆瓣中日两版《深夜食堂》短评各五百条收集至Excel文档,内容包括评论者昵称、时间、评分、评论内容。
详见代码及注释:
import requests
from bs4 import BeautifulSoup
import pandas as pd
#豆瓣《深夜食堂》地址
url ='https://movie.douban.com/subject/3991933/comments?start=0&limit=20&sort=new_score&status=P'
#获取cookie值(略去cookie值则仅能爬取前二十页数据),模拟登陆
ck='ll="118238"; bid=hcbHNtzv8b4; gr_user_id=2d126497-b499-46ee-9275-15b478d0609e; _vwo_uuid_v2=D6AB96FFEF8D3BE49F1208E1EB25D60CC|0b87311fc6de84dd5f4b706249c2e57f; __gads=ID=d32ccef7e66c9bfb:T=1563062245:S=ALNI_MbzUKNVsCB0Cj_87-MG4YLb56QOAA; __yadk_uid=JKUEf8CExYOf76R1XPN903jLTjS3oVsz; viewed="4913064"; ct=y; trc_cookie_storage=taboola%2520global%253Auser-id%3Dedbcb957-d43c-475b-9ef7-4e0a24af6e4c-tuct42749ea; douban-fav-remind=1; ap_v=0,6.0; push_noty_num=0; push_doumail_num=0; __utma=30149280.1797971680.1563014790.1563321748.1563408714.12; __utmc=30149280; __utmz=30149280.1563408714.12.3.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utmv=30149280.16315; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1563408735%2C%22https%3A%2F%2Fwww.douban.com%2Fsearch%3Fsource%3Dsuggest%26q%3D%25E6%25B7%25B1%25E5%25A4%259C%25E9%25A3%259F%25E5%25A0%2582%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.1883369083.1563103010.1563321754.1563408735.4; __utmb=223695111.0.10.1563408735; __utmc=223695111; __utmz=223695111.1563408735.4.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/search; __utmt=1; __utmb=30149280.7.10.1563408714; dbcl2="163150289:pcJJ8qv7vVk"; ck=ALyo; _pk_id.100001.4cf6=fb693c531fbf9f1d.1563103009.4.1563410743.1563322323.'
#将cookie放在headers中一起发送请求
headers = {
'cookie':ck,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
r = requests.get(url,headers=headers)
#打印状态码,2##表示成功获取页面
print(r.status_code)
#利用BeautifulSoup解析页面
soup = BeautifulSoup(r.text,'lxml')
#CSS选择器指定选择元素
print('正在抽取500条短评')
comment_number = 500
n = comment_number//20
#pandas DataFrame表格,创建表格
df = pd.DataFrame([[1, 1, 1, 1]])
df.columns =['评论者', '时间', '评分','内容']
for i in range(n):
url = 'https://movie.douban.com/subject/3991933/comments?start={}&limit=20&sort=new_score&status=P'
url = url.format(i*20)
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
reviewer_v = soup.select('.comment .comment-info a')
data_v = soup.select('.comment .comment-time')
goal_v = soup.select('.comment .comment-info .rating')
content_v = soup.select('.comment .short')
print(len(goal_v))
#如果第i页没有数据,则跳出循环
if len(goal_v)==0:
break
#修改表格内容
for j in range(len(goal_v)):
r = reviewer_v[j].get_text()
d = data_v[j].get_text().replace(' ', '').replace('\n', '')
g = goal_v[j]['title']
c = content_v[j].get_text()
df.loc[i*20+j] = [r, d, g, c]
print('正在导出第%d页' % i)
#to_csv导出为.csv文件;to_excel导出为.xls或.xlsx文件
df.to_excel(r'C:\users\绿绿的小蚂蚱\Desktop\深夜食堂日文版.xlsx',index=False)
print('导出完成!')部分数据如下所示:
(其中评分列中对应关系中,很差——一星,较差——两星,还行——三星,推荐——四星,力荐——五星,在对数据进行处理时进行替换即可)

可视化图表制作
利用python制作由评论内容生成的词云图、由评论时间生成的评论数量走势折线图、由评分生成的各级评分数量柱状图及各级评分占比饼图。
词云图
首先利用python中jieba对评论内容进行分词,再者利用wordcloud模块绘制词云图,其中需要筛选掉一些词频较高的无效词,如:一个,还是,这样,觉得等,以求词云图达到更好的呈现效果。
代码及注释如下:
import matplotlib.pyplot as plt
from jieba import analyse
from wordcloud import WordCloud
#将爬取的评论内容保存至文本文档,将其导入python
text = open(r'C:\Users\绿绿的小蚂蚱\Desktop\.txt', "r",).read()
# 取Top50的词生成词云
tags = analyse.extract_tags(text, topK=50,withWeight=False)
new_text = ' '.join(tags)
print(new_text)
# 对分词文本生成词云
# 生成词云,需要指定中文字体,否则无法生成中文词云
#设置背景图片
#image = plt.imread('./wc.jpg')
stopwords=set('')
#停止词,即即使出现频次高也不可以出现在词云图中的内容
stopwords.update(['深夜','一个','几集','每集','这样','还是','一集','食堂','觉得'])
wc = WordCloud(
#参数设置,长宽高
max_words=200,
width=768,
stopwords = stopwords,
height=1024,
#字体设置
font_path='STZHONGS.TTF'
).generate(new_text)
plt.imshow(wc, cmap='rainbow', interpolation='bilinear')
plt.figure('db.wordcloud')
plt.axis('off')
#导出词云图
wc.to_file('日版.png')
plt.show()评论数量走势折线图
根据评论时间在Excel中做分类汇总,得出随时间评论数量的变化
整理后数据如下:
| 日期 | 评论数量 |
|---|---|
| 2017-06-12 | 49 |
| 2017-06-13 | 191 |
| 2017-06-14 | 87 |
| 2017-06-15 | 34 |
| 2017-06-16 | 28 |
| … | … |
利用python的pyecharts模块绘制折线图,代码:
import xlrd
#from pyecharts import Bar#(柱状图/条形图)
from pyecharts import Line#(折线/面积图)
#导入需要读取Excel表格的路径
data1 = xlrd.open_workbook(r'C:\Users\绿绿的小蚂蚱\Desktop\深夜食堂中文版.xlsx')
table1 = data1.sheets()[2]
#行x=table.row_values(1)
#列y=table.col_values(1)[:]
x=table1.col_values(0)
y=table1.col_values(1)
for i in range(len(x)):
x[i]=x[i].replace('计数','').replace(' ','')
#主副标题
line=Line("评论数量走势","折线图")
line.add("中",x,y)
line.render('中_评论数量走势.html')
各级评分数量柱状图及各级评分占比饼图
根据评分在Excel中做分类汇总,得出各评分数量,部分数据如下:
| 评分 | 数量 |
|---|---|
| 1 | 0 |
| 2 | 2 |
| 3 | 33 |
| 4 | 131 |
| 5 | 321 |
利用python的pyecharts模块绘制柱状图及饼图,代码如下:
from pyecharts import Pie
import xlrd
data1 = xlrd.open_workbook(r'C:\Users\绿绿的小蚂蚱\Desktop\深夜食堂中文版.xlsx')
data2 = xlrd.open_workbook(r'C:\Users\绿绿的小蚂蚱\Desktop\深夜食堂日文版.xlsx')
table1 = data1.sheets()[1]
table2 = data2.sheets()[1]
x = ['1分','2分','3分','4分','5分']
y1 =table1.col_values(1)
y2 = table2.col_values(1)
pie1 = Pie('各级评分占比','中')
pie1.add('', x, y1, is_label_show=True)
pie1.render('中_各级评分占比.html')
pie2 = Pie('各级评分占比','日')
pie2.add('', x, y2, is_label_show=True)
pie2.render('日_各级评分占比.html')数据分析
利用python制作所得的词云图、评论数量走势折线图、各级评分数量柱状图及各级评分占比饼图等一系列可视化图表进行分析。

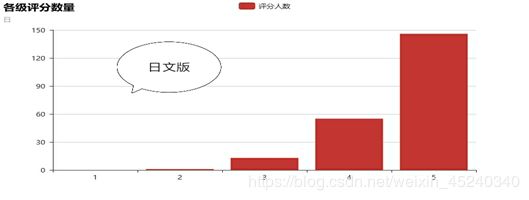
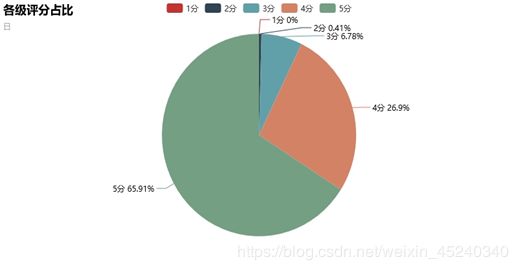

由扇形图可以看出,中文版低分占比重较大,4分5分高分只占6.77%,而日文版恰好相反,4分5分高分占比重较大,低分占比仅0.41%。
通过对比中日版《深夜食堂》评论数量图,可以看出观众对中版的评分一分的居多,但仍不少观众打了4分5分的高评分,相对于打1分2分的低评分的观众数量几可忽略评论一边倒的日版,可见对中版《深夜食堂》观众评价还是较不一致,有不同的声音。

由日版评论走势,可以看出日版的热度一直在持续,从09年开播以后,持续都有人关注这部剧,可见日版的形象已经深入人心,我们可以推测由于先入为主的观念,观众对于翻拍版并不买账。
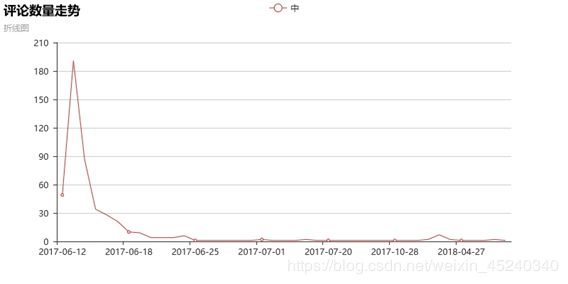
由中版评论走势,可以看出中版的热度在2017-06-12开播后暴增,在播放到2017-06-18第12集时关注人数已经大量减少,从2017-06-18第12集至2017年6月30日第三十六集播放结束,期间关注人数仍处于较低水平。中版从播放结束至今关注人数一直较低。
我们推测由于前期观众对中版预期过高,而前几集让大部分观众不满意,以至于较多观众在剧情尚未完全展开前就对其评了低分,大量的低分并不是基于全剧得出的客观评分。
前面提到的一部分高评分可能是部分观众基于后续剧情对本剧改观打出的分数。


对比基于中日两版评论制作的词云图,我们可以看出:
1.日版评论聚焦于治愈、人生、故事这样的字眼,可见其对观众的感情是有很深的触动。基于这样的背景,观众对于中版翻拍自然会报较高期望值。而中版词云图中的翻拍、原版字眼也印证了低评分可能是由于原版深入人心,翻版的任何瑕疵都会在对比之下被放大。
2.中版评论聚焦于黄磊,广告、泡面、演技尴尬等字眼。可见参演演员是本剧的关注点之一。广告植入是深被诟病的一点,故广告硬性植入是其低评分原因之一。而提到大量的泡面、老坛酸菜是出现在前四集的广告内容,结合我们之前的猜想, 以及第一集、两集字眼分析得部分观众对前几集内容不满意,并未观看到最后就留下了低评分也不再关注了。根据演技尴尬,演员字眼得出低评分也是因为观众对于演员的演技确实不满意。
结论
.综合各项分析我们得出低评分原因:
1.原版内容深入人心,翻版瑕疵会被放大。
2.部分观众在前几集弃剧,所评出评分不是基于全局剧情。
3.硬性广告植入。
4.演员演技让人不满意。
得出结论:
从这部剧的原版和翻拍版的对比可以看出,翻拍的影视剧要想有更大的吸引力,就要多感悟原版的精髓,仅靠明星的热度而没有出色的演技也无法博得观众眼球,同时内置营销要适度,过火的话必会引起观众反感。