SLAM代码(VO简介)
无人机很快会在灾难救援,工业检测环境保护方面祈祷重要作用。这样的应用中获取GPS信息是困难的。因此精确的全自动UAV备选的导航定位系统。使用惯导系统的缺点是累积误差,GPS在受限于使用环境。为了减低重量和功率消耗,视觉导航方法的优点一是不易被干扰,另外是大部分无人机已经配备了相机,视觉系统协同IMU(Inertial Measurement Unit)的方案被广泛采用。本文主要关于VO里程计简介。
定义
选择使用这个词因为它和轮式里程计类似,通过通过对轮子转动圈数积分,增量式估计机器的运动。VO由运动引起的机载相机捕获图像的变化增量式地估计机器的位姿。
assumptions
- Sufficient illumination in the environment
- Dominance of static scene over moving objects
- Enough texture to allow apparent motion to be extracted
- Sufficient scene overlap between consecutive frames
单目里程计
和双目例程计最大的区别就是尺度未知,这是因为3D结构必须从2D数据中获取,因此前两个相机位姿之间的距离设为1。 新的图像到来之后,相对尺度和相对于前两帧图像的相机位姿使用3D结构或者三焦张量trifocal tensor获取。
有三类方法,分别是feature-based methods, appearance-based methods, and hybrid methods。Feature-based methods 基于显著的可重复的特征,并在各帧图像中跟踪这些特征。appearance-based methods使用每个像素的秘籍信息或者图像的子区域进行匹配。hybrid method混合前两种方法。
减小漂移
因为VO通过增量式的计算相机的路径,每个新的帧间运动引入的误差随着时间累积。在真是的路径上会产生一个漂移。对于一些应用中,保持漂移尽量小至关重要,可以对局部几个位姿进行优化,叫sliding window bundle adjustment or windowed bundle adjustment。
VO is only concerned with the local consistency of the trajectory, whereas SLAM with the global consistency.
vo vs v-SLAM
| item | VO | v-SLAM |
|---|---|---|
| goal | a global, consistent estimate of the robot path | local consistency of the trajectory recovering t pose only over the last n poses |
| map | a map of the environment | local map |
| previously visited area | loop closure | - |
| Optimization | global | local/window |
| trade off | consistency | performance |
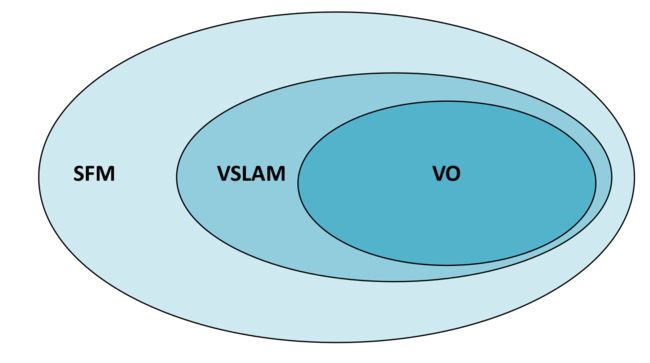
formulation
相邻两张图像对应的相机的位置之间的关系为一个刚体变换,如下表示
Tk,k−1=[Rk,k−10tk,k−11]
其中 Rk,k−1∈SO(3) 为旋转矩阵, tk,k−1∈R3 为平移向量,集合 T1:n={T1:0,...,Tn:n−1} 包含了运动的全部序列.VO的主要任务就是从图像 Ik 到图像 Ik−1 的相对变换T_{k,k-1}. 然后连接这些变换得到整个运动航迹。这意味这VO增量的恢复了运动的路径,pose after pose. 这里使用一种迭代方法调整最近m个位姿,这里通过最小化平方重投影误差。
流程
- Compute the relative motion Tk from images Ik−1 to image _k
- Concatenate them to recover the full trajectory
- An optimization over the last m poses can be done to refine locally the trajectory (Pose-Graph or Bundle Adjustment)
Feature-based Methods
Steps:
- Extract feature key-points and descriptors.
Common features: FAST, SIFT, SURF, ORB - Find the corresponding matches.
Brute-force or kNN match. - Estimate the ego-motion.
PnP or bundle adjustment.
Comments:
- Extraction and matching cannot be always guaranteed to be successful.
- Tracking may lost if the motion is too fast.
- Ego-motion solution does not always exist or global optimal.

对于每个图像,首先是检测并和之前帧的图像匹配2D特征,2D特征是相同的3D特征在在不同的帧之间的投影,又叫image correspondence. 第三步是计算相关运动 Tk,k−1 ,根据对应时所用的维数可以分为三类方法(下边介绍),然后相机的位姿可以计算出来.
最后使用一个迭代调整(bundle adjustment),该调整针对与最近m帧图像,来得到一个更加精确的局部轨迹.
大部分VO假设相机是经过校准的,也就内参数已知.
| item | features tracking | features Matching |
|---|---|---|
| detecting features | independently in all the images | in one image |
| relate to next frame | matching them | tracking them sing a local search |
| based on some | similarity metrics | correlation etc |
关键帧选择
现有的一些运动估计方法需要3D点和2D图像对应的三角测量。结构计算仍然需要bundle adjustment来计算局部轨迹的更精确的估计。三角测量的3D点由两张图像的2D图像点对应的投影射线的交点。理想的条件下,这些射线会相交于一个3D点。然后优于图像的噪声,相机模型和校正的误差,以及特征匹配的不确定性,他们从不相交。相对于景深来说相邻帧之间的距离间隔很近的时候上述情形容易发生。避免此种情形的一种方法是构成忽略的帧知道平均不确定性降低至小于一个阈值。选择的帧叫做关键帧。关键帧在VO中十分重要,而且应该在跟新运动之前完成。
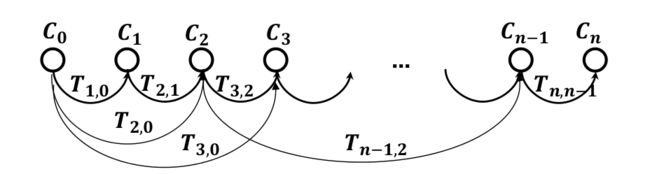
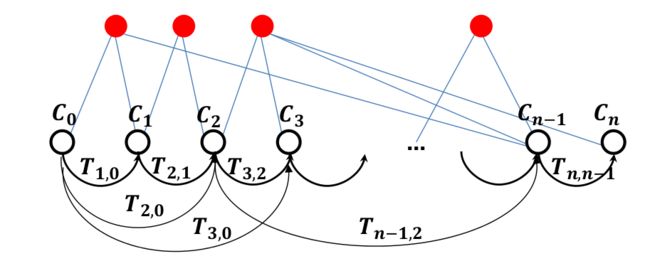
Pose-Graph Optimization vs BA
| Pose-Graph Optimization | BA |
|---|---|
 |
 |
 |
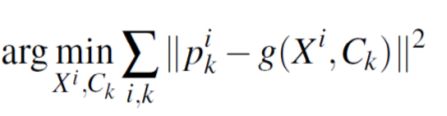 |
| only the last m keyframes are used | to not get stuck in local minima, the initialization should be close to the minimum |
| Gauss-Newton or Levenberg-Marquadt | Gauss-Newton or Levenberg-Marquadt |
| – | more precise |
| – | more costly |
特征选择和匹配
主要分为2种方法,一是在一张图像中检测特征,在随后的帧中使用局部搜索方法进行跟踪;另外一种方法是对于所用的图像独立的检测特征并根据相似度进行匹配。前者更适合于从较小分为的视角拍摄的图像,后者适合有较大的运动或者视角变化。早期研究比较倾向于前种方法,近期的方法比较集中于后种方法。原因是早前的工作大多设想于小范围的环境,图像拍摄于近景,近期的研究的焦点尽量使得场景的变化范围尽量远,进而解决运动漂移的限制。

每个特征检测子包含2各步骤,首先是应用feature-response function对于整张图像,之后是进行非最大值抑制,目标是找到feature-response function的局部极值. 使用检测子具有不变性的诀窍就是使用多尺度,如SIFT,SURF,FAST等.
移除outlier
点匹配经常被outlier,错误关联的数据污染,原因可能来自于图像噪声,遮挡,模糊,视角或光照的变化,这些一般会被检测子和描述子所忽略.一般的假设是关照均匀,单纯的相机旋转和尺度,和仿射畸变。
outlier的一种解决方案是利用运动模型的几何约束。鲁棒的估计方法如M估计法,RANSAC等。
误差传播
VO中的每个变换包含误差,以及不确定性,相机位姿的不确定性依赖于之前时刻的各变换估计结果。VO估计的变换结果的不确定性依赖于相机几何和图像特征。可以证明,当拼接变换时,相机位姿的不确定性总是增加的,因此保持每个变换的不确定性足够小十分重要,以此保证较小的漂移。
相机位姿的优化
最近n帧的图像以及变换已知,加上另外的约束使用图优化可以估计更精确的相机位姿结果。这样相机的估计转化为一个优化问题,从VO估计的相机的位姿表示为位姿graph,每个相机的位姿作为一个节点,每个刚体变换作为边。边的约束可以使用一个代价函数表示
∑eij∥Ci−TeijCj∥2 ,位姿寻找相机位姿参数最小化代价函数.变换的旋转部分使得代价函数非线性,因此该优化需要一个非线性优化算法。
loop detection
回环约束经常形成与相邻较远的节点,这些节点可能积累较大的漂移。通常这样记过一段长时间之后有看到之间经过路标landmark或者回到已经建图的区域成为回环检测。回环约束可以在评估当前图像和以前图像的视觉相似度中发生。视觉相似度使用全局图像描述子计算。进来使用局部描述子的视觉相似度进行回环检测被很多研究所关注,比较出众的方式视觉单词直方(visual word histgram)的距离。回环检测的第一步是检测视觉单词,找到最相似的n帧图像之后,使用极限月做一个几何验证。使用宽基线特征的刚体变换确认匹配
- Loop constraints are very valuable constraints for pose graph optimization
- Loop constraints can be found by evaluating visual similarity between the current camera images and past camera images.
- Visual similarity can be computed using global image descriptors (GIST descriptors) or local image descriptors (e.g., SIFT, BRIEF, BRISK features)
- Image retrieval is the problem of finding the most similar image of a template image in a database of billion images (image retrieval). This can be solved efficiently with Bag of Words [Sivic’03, Nister’06, FABMAP, Galvez-Lopez’12 (DBoW2)]
局部窗口bundle adjustment
In bundle adjustment, the error function to minimize is the image reprojection error:
argmin∑Xi,Ck∥Pik−g(xi,Ck)∥2
重建误差是一个非线性函数,优化方法经常使用LM方法,该方法需要一个靠近最小值的初始值。该优化问题的雅克比有一个特殊的结构可用来提高运算效率。
局部窗口bundle adjustment减小了两视图的漂移,原因是特征测量超过2帧图像。当前相机的位置连接通过3D路标,当前的估计和最近n帧图像的估计一致。窗口的大小由计算量决定。
method classification for image correspondence
- 2-D-to-2-D: In this case, both fk−1 and fk are specified in 2-D image coordinates.
- l 3-D-to-3-D: In this case, both fk−1 and fk are specified in 3-D. To do this, it is necessary to triangulate 3-D points at each time instant; for instance, by using a stereo camera system.
- 3-D-to-2-D: In this case, fk−1 are specified in 3-D and fk are their corresponding 2-D reprojections on the image I k . In the monocular case, the 3-D structure needs to be triangulated from two adjacent camera views (e.g., Ik2 and Ik1 ) and then matched to 2-D image features in a third view (e.g., Ik ). In the monocular scheme, matches over at least three views are necessary. Notice that features can be points or lin
运动估计方法的分类
瞬时从video中恢复相机姿态和视场结构的方法分为2类
- Feature-based method
- Directed method
前者提取显著特征点的稀疏集合并使用invariant descriptors 匹配,使用外极几何恢复相机运动和结构,最后最小化重投影误差调整pose and structure。这个方法的成功之处在于使用了鲁棒的特征监测子和描述子,这样允许帧间有较大的惯性运动。这方法的缺点是依赖于检测子和描述子的阈值,如何处理匹配错的情况,这样的需要使用很多的特征测量来弥补。
后者直接从灰度值估计结构和运动。局部的灰度梯度幅度和方向被使用。梯度值小的点也被直接法使用。光度的计算要比重投影误差要敏感。
sparse model-based image alignment
The maximum likelihood estimate of the rigid body transformation Tk,k−1 between two consecutive camera poses minimizes the negative log-likelihood of the intensity residuals:
δI(ξ,ui)=Ik(π(T^k,k−1⋅pi))−Ik−1(π(T^(ξ)⋅pi))
open sources
SFM for MAVs
MAVMAP: https://github.com/mavmap/mavmap
Pix4D: https://pix4d.com/
VO (i.e., no loop closing)
Modified PTAM: (feature-based, mono): http://wiki.ros.org/ethzasl_ptam
LIBVISO2 (feature-based, mono and stereo): http://www.cvlibs.net/software/libviso
SVO (semi-direct, mono, stereo, multi-cameras): https://github.com/uzh-rpg/rpg_svo
VIO
ROVIO (tightly coupled EKF): https://github.com/ethz-asl/rovio
OKVIS (non-linear optimization): https://github.com/ethz-asl/okvis
VSLAM
ORB-SLAM (feature based, mono and stereo): https://github.com/raulmur/ORB_SLAM
LSD-SLAM (semi-dense, direct, mono): https://github.com/tum-vision/lsd_slam
IMU-Vision fusion:
Multi-Sensor Fusion Package (MSF) (Weiss et al.) - EKF, loosely-coupled:
http://wiki.ros.org/ethzasl_sensor_fusion
SVO + GTSAM (Forster et al. RSS’15) (optimization based, pre-integrated IMU):
https://bitbucket.org/gtborg/gtsam
Instructions here: http://arxiv.org/pdf/1512.02363
optimisation Tools
GTSAM: https://collab.cc.gatech.edu/borg/gtsam?destination=node%2F299
G2o: https://openslam.org/g2o.html
Google Ceres Solver: http://ceres-solver.org/
Place recognition
DBoW2: https://github.com/dorian3d/DBoW2
FABMAP: http://mrg.robots.ox.ac.uk/fabmap/
data sets
These datasets include ground-truthed 6-DOF poses from Vicon and
synchronized IMU and images:
- EUROC MAV Dataset (forward-facing stereo):
http://projects.asl.ethz.ch/datasets/doku.php?id=kmavvisualinerti
aldatasets
- RPG-UZH dataset (downward-facing monocular)
http://rpg.ifi.uzh.ch/datasets/dalidation.bag
refer
- D. Scaramuzza, F. Fraundorfer, “Visual Odometry: Part I - The First 30 Years and Fundamentals IEEE Robotics and Automation Magazine”, Volume 18, issue 4, 2011.
- F. Fraundorfer and D. Scaramuzza, “Visual Odometry : Part II: Matching, Robustness, Optimization, and Applications,” in IEEE Robotics & Automation Magazine, vol. 19, no. 2, pp. 78-90, June 2012.
doi: 10.1109/MRA.2012.2182810