Windows Server AppFabric分布式缓存详解
本文转载自https://msdn.microsoft.com/zh-cn/library/ff384253.aspx,主要内容是对msdn中对AppFabric分布式缓存的详细介绍的整合以及一些自己的理解。
AppFabric是什么
AppFabric是微软提供的可以集成到 Web 应用程序和桌面应用程序的分布式缓存。其原名为Velocity,后更名为AppFabric。 AppFabric 能够提高性能、可伸缩性和可用性,而从开发人员的角度来看,其行为方式与普通的内存缓存一样。任何可序列化的对象都可以缓存,例如 DataSet、DataTable、二进制数据、XML、自定义实体以及数据传输对象。
体系结构和相关概念
物理架构
AppFabric由多个可以相互通信,统一的应用程序缓存服务的群集。物理模型的主要组件包括缓存服务器,缓存主机Windows服务,缓存群集,基于PowerShell的缓存管理工具,群集配置存储位置和缓存客户端。

物理模型主要包含以下几个概念:
缓存主机(cache host)
AppFabric 缓存服务是运行在一个或多个服务器上的 Windows 服务。运行缓存服务的每个服务器均称为一个缓存服务器。对于每个缓存服务器,只可安装缓存服务的一个实例。缓存服务主机与数据源主机最好是在同一个域下,缓存主机服运行在Network Service账户下,缓存主服务上的各种操作用域下的高速缓存认证凭据。
缓存集群(cache cluster)
缓存群集是以环状方式共同存储和分发数据的缓存服务的一个或多个实例的集合。数据存储在内存中,以最大程度地减少数据请求的响应次数。缓存群集的操作由角色进行管理,被命名为群集管理角色。它的职责主要包含以下三点:
- 让缓存群集一直处于运行状态;
- 监测缓存群集中的所有缓存主机;
- 帮助缓存主机加入缓存群集。
群集配置存储区(Cluster Configuration Storage Location)
集群每次启动时,必须从群集配置中的存储位置检索配置信息。下表显示了三种可能的方式,以及这些方法与群集管理选项的关系:
| 存储类型 | 存储位置 | 群集管理 |
|---|---|---|
| XML文件 | 共享网络文件夹 | 主要主机 |
| SQL Server数据库 | SQL Server | SQL Server(默认)或主要主机 |
| 自定义提供程序 | 自定义存储 | 自定义存储 |
基于PowerShell的管理工具(PowerShell-Based Cache Administration Tool)
Windows PowerShell 是缓存服务的专用管理工具。Windows PowerShell 缓存管理 cmdlet 可以安装在任何域计算机上或缓存服务器上。通过安装 AppFabric 的缓存管理功能可以完成此操作。您必须具有对所有缓存服务器的管理员权限,才能使工具正常运行。
缓存客户端(Cache Client)
AppFabric分布式缓存集群是设计用于应用服务器在企业数据中心,并部署在企业防火墙的内。任何使用服务器上运行的高速缓存的应用程序统称为缓存客户端。
逻辑架构
逻辑概念上将AppFabric分为:命名缓存(named caches),缓存域(regions)和缓存对象(cached objects)。
命名缓存(named caches)
命名缓存是一个通过配置在内存中形成的分布式缓存存储单元。你可以在一个应用程度中配置一个或多个name caches,每个name caches不会受其它配置的影响,这样你可根据程序的需要,配置多个name cache,并且每个name caches使用不同的缓存策略。
如上图所示:name caches跨越分布在每个缓存主机上,如果你不为缓存指定名称,你的数据将被存储在默认的“default”缓存命名下。
所有缓存都有群集配置来定义。使用PowerShell的缓存管理工具来创建或重新配置缓存。某些设置只能第一次创建缓存时配置。例如,您使用New-Cache命令启用高可用性或通知功能。其他设置可以以后改变,但可能需要重新启动整个缓存集群。
区域(regions)
区域是一个逻辑上的缓存存储域(感觉可以理解为一个命名空间吧)。regions是一个可选项,不是通过配置创建的,你必需在代码中用CreateRegion函数创建。可以通过regions查找该region下的所有cache objects。为了提供这种附加的搜索功能,在一个区域内的对象仅限于一个单一的缓存主机。因此,使用该数据的应用程序无法实现分布式缓存的可扩展性优势。相反,如果你不指定一个区域,缓存的对象,否则可以负载平衡集群中的所有缓存主机。
缓存对象(caches objects)
从缓存群集检索的对象采用其 System.Object 基类的形式,因此需要进行类型转换以将它们还原为其原始类型。当某个对象处于缓存中时,缓存群集会将附加信息与该对象关联。这些信息包括密钥、标记、版本号以及存储对象的缓存和区域。
编程架构
当数据不存在于你的客户端缓存中时,需要重新从Caches Host中加载。客户端使用DataCache类来添加客户端cache。
缓存策略(Caching Strategy)
应用程序就设计成在没有缓存存在时仍然可以正常运行,因为缓存并不是绝对持久有效的,它总有失效或不存在的可能性。AppFabric的高可用性可以有效的防止群集中的个别主机故障带来的问题,但是如果群集中有太多的主机挂了,那AppFabric还是会挂(相当与disk raid吧,坏了个别还可以跑)。
还有许多其他的原因会导致程序找不到缓存:缓存可能已经过期或者被移除,可能已重新启动缓存服务器,缓存主机服务可能已重新启动,或缓存群集可能已被意外重新启动。所以务必确保在没有缓存的情况下,应用程序仍然可以访问到正数据并正常运行。
缓存客户端(Cache Clients)
为了存储在缓存中的数据,可以使用GetCache方法用于返回一个DataCache对象, DataCache对象实例化后的实例被称为缓存客户端。有许多选项可用来配置缓存客户端的行为,编程方式或使用应用程序配置文件,或同时使用这两种方法。
应用程序级配置(Application Configuration)
AppFabric支持许多缓存配置。配置可分为3个级别:用程序级,缓存主机级,缓存群集级。 AppFabric还提供了用于指定和存储的缓存集群和客户端应用程序使用的配置。
缓存客户端与本地缓存
使用AppFabric缓存,应用程序中需要用到DataCache对象存储缓存对象。这个对象就是缓存客户端,它为应用程序提供了一个缓存群集服务的name cache的引用。该对象由DataCacheFacory对象的GetCache方法创建。
出于性能考虑,建议在应用程序中尽量少创建DataCacheFactory对象,在应用程序中创建一个全局变量,以便缓存客户端可以在任何地方都给使用--用单件模式吧
缓存客户端分为两种:路由客户端和普通客户端。两种缓存客户端都可以将缓存存储在本地,这种被存储在本地的缓存称为:本地缓存。缓存客户端的存储选项可以通过应用程序配置文件指定。
客户端类型
下图中有两个使用了缓存的应用程序:路由(routing)和普通(simple):
路由客户端(Routing Client)
路由客户端的性能要高于普通客户端,因为它在缓存的引导主机(Lead hots)上保存了一张路由表。该路由表用记录缓存群集中的所有缓存主机上的对象的地址并做唯一标示。路由客户端使用路由表可以直接找到对象的物理地址。
普通客户端(Simple Client)
只要有可能,尽量使用Routing Client,但在情况下,如网络拓扑中,可能有些客户端只能访问缓存服务群集的中的部分主机,这时就要用到Simple Cleint来做为分布式缓存的数据源。为了在有限的网络通信情况下工作,Simple Client被设计为只访问缓存群集中的一台主机。它没有路由选择功能,不能跟踪对象的地,要获取缓存中的一个对象通常需要遍历所有主机。
本地缓存
缓存主机存储的是序列化后的对象,客户端要使用该对象,必需先反序列化,为了提高取出对象的效率,可以启用本地缓存。路由客户端和普通客户端都可以使用本地缓存。
当启用本地缓存后,对象将以复本的文本保本地计算机的内在中,客户端应用程序在从缓存主机取出对象时,先检查本地缓存是否已存在该对象。如果本地缓存已存在该对象,将直接从本地取出。
本地缓存有两种过期策略:超时过期和通知过期。
线程并发(Object Consistency)
本地缓存对象和缓存客户端对象在同一个进程空间中,只为DataCache是引用方式获取这些对象,在多线程应用程序中可能会存在线程同步问题。为了避免潜在的多线程中的问题,多线程应用程序在使用缓存对象时应先生成一个对象的复本,或对取其它方式来避免线程并发问题。另一种方法是为每一个线程创建一个DataCache对象。
并发模型
AppFabric允许任何有网络权限和相关配置的缓存客户端公开的访问缓存数据,这样就面临着安全和并发的挑战。
为了减少安全问题,所有的缓存客户端、缓存服务和主数据源服务器都应该在同一个域下,并在防火墙内,这是极度推荐的方法。
为了解决并发问题,AppFabric提供了乐观并发模型和悲观并发模型。
乐观并发模型
在乐观并发模型中,缓存对象的更新不进行锁定。但当缓存客户端从缓存获得对象时,它还获得并存储该对象的当前版本。当需要进行更新时,缓存客户端会将对象新值与已存储的版本对象一起发送。仅当发送的版本与缓存中对象的当前版本匹配时,系统才会更新对象。对象的每次更新都会更改其版本号,这可以防止更新覆盖其他人的更改。
下面这个示例中,两个单独应用程序服务器上的两个缓存客户端(cacheClientA 和 cacheClientB)尝试更新同一个名为 RadioInventory 的缓存对象。
时间零点:两个客户端都检索同一个对象
两个缓存客户端实各例化一个DataCacheItem类,并取出缓存同一个对象,两个DataCacheItem实例要准备要更新对象。

时间 1:首次更新成功
cacheClientA将对象RadioInventory更新,RadioInventory的版本号添加,这时cacheClientB中的RadioInventory对象已过期。
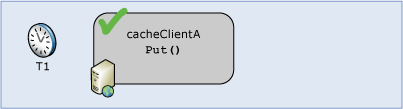
时间 2:第二次更新失败
cacheClientB尝试修改RadioInventory为一个新值,为了阻止将cacheClientA的更新覆盖,cacheClientB的更新将会失败。

悲观并发模型
在悲观并发模型中,客户端显式锁定要执行操作的对象。其他请求锁定的操作(系统不阻止请求)被拒绝,直到释放锁定。当锁定对象时,锁定句柄返回为输出参数。解除对象锁定需要使用锁定句柄。 如果客户端应用程序在释放锁定对象前结束,则提供超时以释放锁定。锁定的对象永不过期,但如果超过过期时间,则锁定的对象可能在被解除锁定后立即过期。
过期和回收(Expiration and Eviction)
AppFabric中,对象并不是一直驻留在内存中。除了显示使用Remove方法将其移除,还有可能过期机制或回收机制从缓存群集中去除。
过期机制(Expiration)
缓存过期机制允许缓存群集自动从缓存中删除缓存对象。使用Put或Add方法时,有一个超时时间的可选参数,用来决定缓存在内存中的生存时间。如果缓存对象没有设置超时时间,命名缓存(Named Cache)中的配置将决定对象的生成时间。
如果对象在并发时被锁,对象不会因到期时间而从内存中移除。但当并发锁解锁时,对象将立即从内存只移除。
本地缓存失效机制(local Cache Invalidation)
一旦对象被下载到本地缓存,您的应用程序将一直使用这些对象,直到他们是失效,无论是否由另一个客户端上缓存群集更新这些对象。出于这个原因,最好是不经常变化的数据缓存到本地。有两种类型的本地缓存失效机制:基于超时的失效和基于通知的失效。
基于超时的失效机制(Timeout-based Invalidation)
将对象下载到本地缓存之后,这些对象将驻留在本地缓存中,直到其达到缓存客户端配置设置中指定的对象超时值。达到此超时值之后,对象将失效,以便下次请求时可以从缓存群集刷新。
基于通知的失效机制(Notification-based Invalidation)
如果缓存客户端启用了本地缓存,则还可以使用缓存通知使本地缓存的对象自动失效。根据需要缩短这些对象的生存期,这样可以降低应用程序使用过时数据的可能性。
回收机制(Eviction)
为了保持缓存主机的内存上面可以有足够的内存用于缓存数据,AppFabric使用LRU(最近最久未使用)算法,用一个界限值确保内存均匀分配在所有缓存主机中。
当内存的使用率超过了界限值时,AppFabric将启动回收机制回收已过期对象。如果回心过期对象后,内存的使用率还在界限值之上,将使用LRU机制纠继续回收对象,不管对象是否已过期,直到将同存的使用率降到界限值以下。
指定过期和逐出设置
过期和回收机制通过群集配置文件来设置。可以使用基于PowerShell的管理员工具来管理,另外以下方法允许你重写缓存的默认设置。
- CreateRegion方法允许你启用和禁用域中对象的回收机制
- Add和Put方法允许重写,可以指定过缓存中对象的过期时间
- PutAndUnlock和Unlock方法允许重载,可以扩展对象解锁后的到期时间
- ResetObjectTimeout 方法允许显示指定对象的生存时间,此方法重写缓存配置的设置
高可用性(High Availability)
AppFabric的高可用性功能支持单独的缓存主机上存储数据的副本,使缓存数据持续可用。如果启用了群集的高可用性功能,应用仍然程序可以在群集中的部分缓存主机挂了的情况下取出数据。
没有高可用性启用,AppFabric仍提供一些保护缓存数据的措施,对象不存储在是在域中,而是分布在集群的所有主机。由于分布式的特性,群集中的主机越多,因某一台机器故障而带来的数据访问问题会越少。
仅管高可用性可以减少缓存主机和应用程序间的故障,但也有可能整个群集挂掉,所以应用程序设计时应该考虑到在没有缓存服务情况下的状态,毕竟缓存总有不存在的时候。
高可用性如何运行
当启用高可用性功能时,每个独立的主机都保存了对象或域的复本。缓存群集管理维护这些复本,当主缓存数据失败时,会复本中的数据提供给应用程序。启用高可用性不会对编程方面产生任务影响。

如何保持一致性
无论是否启用高可用性,支持缓存的应用程序都按照仅存在缓存对象主要副本的情况运行。所有的 Add、Put 和 Remove 方法调用都首先在主要对象上启动,无论他们位于哪个缓存主机上。对维护主要对象或区域的缓存主机启动调用之后,结果操作将因是否启用高可用性而异。
如果启用高可用性,会增加一个步骤通知维护辅助副本的主机即将发生更改。然后,包含对象主要副本的缓存主机在等待来自另一主机的确认以后,向客户端回复操作完成确认。
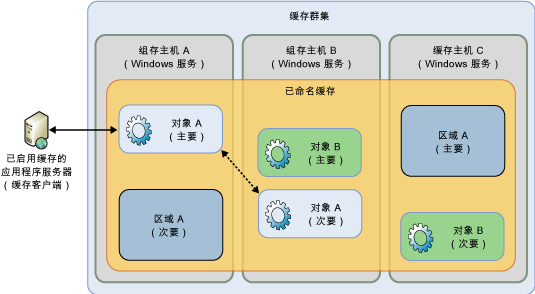
例如下列的示例,缓存主机 A 收到请求以后,会立即开始处理请求并向缓存主机 B 通知此更改。然后,缓存主机 B 向缓存主机 A 发送回复确认。当缓存主机 A 收到确认以后,会完成更改并向支持缓存的应用程序发送回复确认。此过程可确保对象或区域的辅助副本始终与主要副本处于同一状态。此过程称为非常一致:
性能注意事项
维护缓存复本时必需识别所有主缓存的变化,这里有一些性能会消耗在复本的同步中。需要考虑当主缓存丢失后,重新加加载缓存复本的代价。
缓存主机失败时发生的情况
如果其中一个缓存主机出故障不会对应用程序产生任何影响,缓存群集将重新路由到缓存复本,同时将该缓存的复本的访问优先级提升到主复本。然后再生成该缓存的次要复本,并平均分布于其它可用主机。
要启用高可用性,群集中最少要有三台缓存主机,并且有两台主机处于正常运行状态。
| 时间 | 缓存主机 1 | 缓存主机 2 | 缓存主机 3 | HACache(启用高可用性的命名缓存) |
|---|---|---|---|---|
| T1 | 正在运行 | 正在运行 | 正在运行 | 可用 |
| T2 | 正在运行 | 正在运行 | 已停止 | 可用 |
| T3 | 正在运行 | 已停止 | 已停止 | 不可用 |
在 T1 中,当有三个缓存主机可用时,缓存对象或区域的两个副本可以存储在这三个可用服务器中的任意一个上。在 T2 中,当一个缓存服务器失败时,HACache 继续可用,因为仍然有两个缓存主机可用于存储缓存对象或区域的两个副本。在 T3 中,当第二个缓存主机失败时,HACache 不可用。这是因为不再有另一个缓存主机可用于存储缓存对象或区域的第二个副本。
高可用性的一推荐做法
- 让群集中有大量的缓存主机
- 将缓存系统中的所有缓存服务、缓存主机、缓存客户端、数据源服务都部署在企业防火墙的同一个域下。
- 使用SqlServer做为你的分布式缓存系统
- 尽量少修改配置,因为这会重启整个群集,如果有可能,可以用重新创建name caches方法来代替修改配置
- 必需在重启服务前使用Stop-CacheHost命令来停止缓存主机。用Stop-CacheHost命令来关闭群集中管理角色的主机不会成功,因为当管理角色的主机关闭后会导致整个群集关闭
缓存通知(Cache Notifications )
AppFabric提供了缓存通知,当缓存群集中有对缓存的操作时,允许应用程序接收异步通知。缓存通知也提供了让本地缓存失效的功能。
为了接收异步缓存通知,在应用程序中要添加一个缓存通知的回调函数。当您添加回调,您可以定义缓存操作触发一个缓存的通知,当缓存发变化时会调用该函数通知应用程序。
触发缓存通知
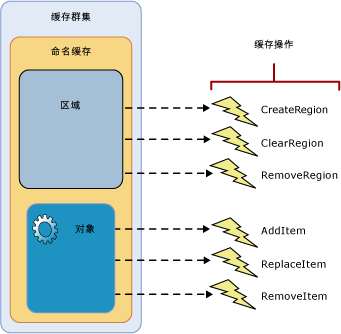
如下图所示,改变这两个地区和缓存的对象(称为缓存内的项目)可以触发缓存通知。(缓存通知的类型由DataCacheOption类的成员定义)
通知范围(Notification Scope)
根据应用程序的业务要求,你不一定要对缓存中所有对象和域的事件做监听。AppFabric可以从地区的级别和域级别的高速缓存级别缩小您的通知的范围。
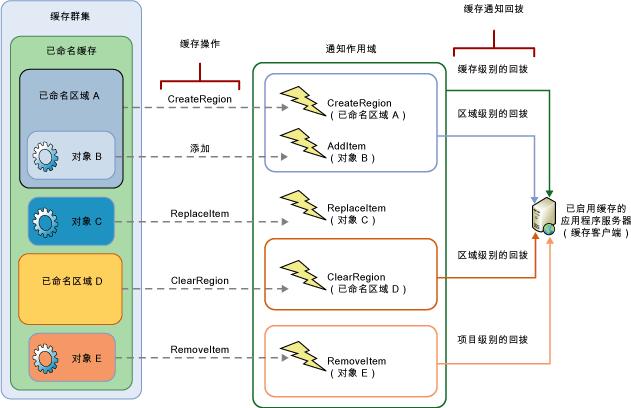
在缓存级别,应用程序将监听到缓存所有对象和域的变化;在域级别应用程序将监听到某个域中的有对象的变化;在Item level,应用程序将仅监听到某个对象发生的变化。
可以用以下三个方法指定不能的监听级别:
- AddCacheLevelCallback:当您希望收到有关所有区域和项目上发生的基于区域和项目的缓存操作的通知时。
- AddRegionLevelCallback:当您希望收到有关某个特定区域上发生的基于区域和项目的缓存操作的通知时。
- AddItemLevelCallback: 当您希望收到某个特定项目上发生的基于项目的缓存操作的通知时。
通知顺序(Notification Order)
缓存客户端接收通知的顺序应保证在一个区域上下文中。 例如,假设您已经创建了一个名为 RegionA 的区域。 由于放入缓存区域的所有数据都限制到同一区域,因此有关 区域A(区域级别通知范围)的所有缓存操作均会按照与彼此相关的适当顺序到达缓存客户端。 不保证其他缓存主机上基于区域和项目的缓存操作按照与 区域A 中发生的操作相关的适当顺序到达。。
查询间隔(Polling Interval)
使用缓存通知时,应用程序会按指定的时间间隔检查是否有新的通知可用,默认轮循时间是300秒。
通知丢失时
由于服务器的负载问题,缓存主机只能处理一定量的缓存操作,所有一此缓存客户端可能在没有接收到通知时,缓存主机就将通知队列终止。缓存客户端也有可能因为某个缓存服务服务故障而丢失通知,虽然缓存群集仍然正常运行。这种情况下应用程序会接收到消息通知失败的通知,可以通过添加 AddFailureNotificationCallback函数处理此消息。
缓存群集丢失时
丢失通知与丢失缓存群集之间有很大的区别,如果应用程序丢失通知,会接收到通知失败的通知,而缓存群集挂了之后应用程序将接收不到任务通知,再尝试连接群集时时应用程序会抛出异常。
启用缓存通知
缓存通知和通知的级别都可以在群集的配置文件中设置。可以把它当做缓存的一个属性来创建缓存。默认情况下缓存通知是不启用的。
群集主机和群集管理(Lead Hosts and Cluster Management )
AppFabric是一组动态服务同时运行的组合,为应用程序提供一个唯一的逻辑缓存。要做到这些,需要一些开销花在各主机的协同工作上。在AppFabric中,群集管理角色是用到管理缓存主机,最终组成一个缓存群集。
根据分布式缓存的不同配置,有两个选项可用于群集管理角色。如果使用SQL Server数据来存储群集配置,SQL Server实例同时也是群集的管理角色。
如果使用网络共享目录来存储群集配置,群集管理的角色将是被指定的一台缓存主机,这台主机被称为lead hosts,它除了有群集中的其它缓存主机的职责外还肩负着群集管理角色的重任。
群集管理角色的职责(Cluster Management Role Duties)
- 确保缓存群集一直正常运行
- 管理群集中的所有可用缓存主机
- 帮助缓存主机加入缓存群集
有两个主要配置用于决定如何配置缓存群集:
- leadHostManagement:群集级别的配置,用于管理群集角色。为true时,lead hosts将履行群体管理职责。当选择网络共享目录为存储位置时,此配置仅能为true。当选择Sqlserver为存储位置时,可以通过将该值设置为true来指定某个主机为lead hosts。
- quorumHost:缓存主机级别的配置。当从SqlServer为存储位置时,用更改主机位置。
对于这两个属性,有四种可能的情况用于确定缓存主机如何运行。下表对这些情况进行了介绍:
| leadHostManagement 群集级别设置 | leadHost 缓存主机设置 | 设置组合说明 | 有效的缓存主机责任 |
|---|---|---|---|
| false | false | SQL Server 或自定义提供程序执行群集管理角色。这不是主要主机。 | 仅正常的缓存主机操作。 |
| false | true | SQL Server 执行群集管理角色。如果您将 leadHostManagement 设置更改为 true,则它是主要主机。 | 仅正常的缓存主机操作。 |
| true | false | 主要主机执行群集管理角色,但它不是主要主机。 | 仅正常的缓存主机操作。 |
| true | true | 主要主机执行群集管理角色。这是主要主机。 | 正常的缓存主机操作,并与其他主要主机一起管理群集。 |
当主要主机执行群集管理角色时
如果 leadHostManagement 和 leadHost 设置都为 true,则缓存主机会在群集中提升至责任更大的级别,并被指定为主要主机。主要主机除了执行普通缓存主机缓存数据相关的操作之外,它还要与其他主要主机一起管理群集操作。
当主要主机出现故障时
为了保持可用的缓存集群,大多数Lead host必须保持可用。确保它有较少的服务器故障导致群集自行关闭。例如:有6个服务的缓存群体,两被指定为群集的管理者。
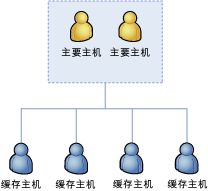
如果一台普通主机挂了,群体仍正常运行。非lead hosts主机的数据将会丢失(假设高可用性未启用),但其余的服务和数据仍正常,群体仍可正常运行。如果所有非lead hosts主机都挂了,lead host将不会再被视为lead hosts。
当 SQL Server 执行群集管理角色时
如果群集的 leadHostManagement 设置为 false,则无论 leadHost 设置如何,每个缓存主机仅承担与缓存数据相关的非主要主机的普通责任。在这种情况下,用于存储群集配置设置的 SQL Server 实例还用于执行群集管理角色。
如果发生服务器故障时
在 SQL Server 执行群集管理角色时,为了使群集保持可用,一个或多个缓存主机必须能够访问 SQL Server 数据库。
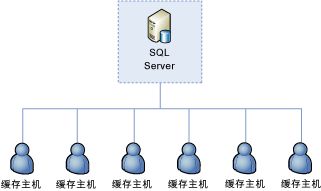
例如,设想上图中显示的六服务器缓存群集。SQL Server 执行群集管理角色,所有六个缓存主机可以将其资源专用于缓存客户端的数据访问。如果群集中的任何一个缓存主机发生故障,则这些服务器上的数据都会丢失(假定未启用高可用性),但群集会继续运行。其他缓存主机上的数据会继续提供给缓存客户端。事实上,在这种情况下,如果群集丢失了六个缓存主机中的五个,它仍可以继续工作。
TCP/IP 通信
AppFabric中,所有主机通过互相间的TCP/IP通信共同组成了缓存群集。为了确保缓存主机间的通信,应关闭主机音的防火墙。缓存客户端使用Tcp/IP方式对缓存进行操作,但它可以在有防火墙的状态下工作。
AppFabric是下个设计为运行在防火墙内的高性能的程序。为了尽可能的提高性能,数据都未进行加密,所以很可能受到“sniffing”和“replay”攻击。
TCP/IP端口设置
为了正常运行,每个缓存服务器需要配置缓存主机服务在防火墙例外列表中。使用三个独立的端口是:群集的端口,仲裁端口,和缓存端口。
每个高速缓存的主机和缓存客户端指定端口,这些端口号可以不同。缓存群集通过群集配置来跟踪每个缓存主机,并维护主机间的通信。
以下给出四个端口号的相关说明:
| 端口名称 | 默认值 | 应用程序配置文件属性 | 群集配置文件属性 |
|---|---|---|---|
| 缓存端口 | 22233 | cachePort | cachePort |
| 群集端口 | 22234 | 不适用 | clusterPort |
| 仲裁端口 | 22235 | 不适用 | arbitratorPort |
| 复制端口 | 22236 | 不适用 | replicationPort |
安全考虑
在安装过程中安装程序会自动配置这些端口到防火墙例外列表中。卸载后的缓存主机服务,我们建议手动根据企业的政策和服务器上的其他应用的需要重新配置这些端口。在某些情况下,这可能意味着在防火墙中关闭这些端口。
数据分类(Data Classification )
能过选择适当的缓存数据类型,AppFabric可以为你的应用程序带来很多好处。数据可以采取多种形式,并驻留在您的应用程序的不同层次。分布式缓存使得不同类型的数据可以轻松存储和检索,不受服务边界限制和语义的差异影响。
如下表所示,有三种类型的数据适合用于分布式缓存:引用、活动和资源。
| 数据类型 | 访问模式 |
|---|---|
| 引用 | 共享读取 |
| 活动 | 独占写入 |
| 资源 | 共享、同时读取和写入,被大量事务访问 |
引用数据
引用数据(非独占写数据)是不会常发生变化的数据的一个版本。它是原数据的复本,引用数据通常是按照配置的间隔时间周期的刷新数据。
由于引用数据不会经常更改,在一定程度上可以将数据缓存,而不用在每次读取数据时都访问数据源。使用引用数据有助于提高应用程序的规模和性能。因为浏览操作可能需要大量资源,因此,这种目录数据非常适合缓存。如果未缓存,这些操作可能会不必要地为数据源增加负担,并可能显著影响应用程序的响应时间和吞吐量。
活动数据
活动数据(独占写数据)是由根据实时执行生成的业务数据的一部分。数据源做为业务事务的一部分,在事务结束后,数据将做为历史日志。
例如定单数据,应用程序的Session状态或在线购物车。考虑到购物车是一个在线的程序,每个购物车都有一个会话状态。在这个购物的会话中,购物车的存储着用户选择的数据。购物车数据被一个交易的事务独占访问。因为数据集合并不共享,因此,可在分布式高速缓存中分发单个数据集合并将其存储在单独的缓存主机上。通过使用更多缓存主机动态增加分布式高速缓存,可以扩展应用程序以满足不断增长的需求。
资源数据
并不是所有的数据都可能被归为引用数据(共享读)和活动数据(独占写)两种数据,还有已共享、同时读取和写入并由大量事务访问的数据,此类数据称为资源数据。
为便于跟踪,资源数据通常存储在联机事务处理 (OLTP) 数据源中,并缓存在应用程序层,以提高性能并为数据源释放计算资源。由于某些类型的数据被共享并同步更新,因此,必须保持群集内缓存的一致性。