5G风起,未来数据库将会如何发展?
导语:
在自己工作的领域中,发现快乐是我坚持做技术的动力。而技术域其实就是一个画圆的过程,当你发现你的圈圈画得越大,需要求知的东西也就越多。每天必须保持一种持续学习,和与技术死磕的精神才能促使我们不断前行。我们不断前行,时代也在不断变化和发展。本文由变化看发展,从移动通讯发展的历程同步透视数据库能力的变迁,进而预测5G时代将会给数据库带来的重大变革。
一、1G时代下的数据库:关系型数据库来满足基本需求
首先,从通信时代的总要变化谈起:从1G到5G,手机见证了人类通信的飞速发展。从军用到民用,从大哥大到智能机,总有一款手机能勾往日的回忆。
1938年,美国贝尔实验室为美国军方制成了世界上第一部“移动电话”,即无线便携式报话机,使用时必须有一人背负信号箱,光是信号箱就是二三十斤,1G所通信所使用的正是模拟技术。1973年摩托罗拉公司的马丁·库帕发明了世界上第一部民用手机,1983年正式推向市场。1993年大陆第一部手机摩托罗拉3200,被尊称为“大哥大”,宣告了我国正式进入1G时代,拥有一部“大哥大”是身份的象征,也是那个年代人们的梦想。
关系型数据库起源自1970年代,其最基本的功能无非就两个:一个是先把数据存下来,另外就是满足用户对数据的计算需求。数据是根基,如果连数据都完整的存不下来,或者保存不好,后续任何事情都无法进行展开,所以这点很重要。有了数据,用户就可以进行一些query操作了。
不管是聚合、连表还是分组,在数据库早期发展阶段都能满足需求,当时优秀的商业数据库产品主要是Oracle,DB2。
二、2G时代下的数据库:开源数据库产品初露锋芒
1G有着很多的缺陷,可能经常会出现串号、盗号等现象。1994年,就在我爸吵吵嚷嚷地要买“大哥大”的时候,A网和B网正式关闭,紧接着2G时代来临了。1995年,新的通讯技术成熟,国内也正式进入了2G通信时代,主宰1G时代的摩托罗拉走下神坛,取而代之的是垄断一时的诺基亚。在这之后的那些年,诺基亚带给我们了无数经典手机。我记得我当时用的是诺基亚7610。

当时,Berkeley DB、MySQL、PostgreSQL等数据库陆续发布,开源数据库产品初露锋芒。这些数据库不断提升单机实例性能,可以很好地支撑业务发展,应对各类业务的变化。拿目前独占开源数据库榜首的MySQL举例来说,它的数据库架构就很丰富。有基于主从架构的MHA,双主+Keepalived。
我们先来看下各个数据库的发布时间,然后简单介绍。
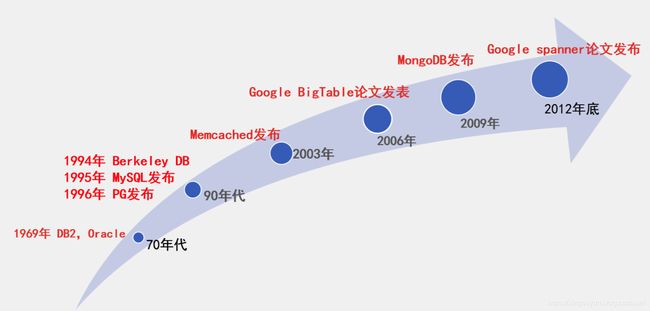
1.基于主从架构的MHA
MHA的目的在于维持MySQL Replication中master库的高可用性,其最大特点是可以修复多个slave之间的差异日志,最终使所有slave保持数据一致,然后从中选择一个充当新的master,并将其他slave指向它。当master出现故障时,可以通过对比slave之间I/O thread 读取主库binlog的position号,选取最接近的slave作为备选主库(备胎)。其他的从库可以通过与备选主库对比生成差异的中继日志。在备选主库上应用从原来master保存的binlog,同时将备选主库提升为master。最后在其他slave上应用相应的差异中继日志并从新的master开始复制。
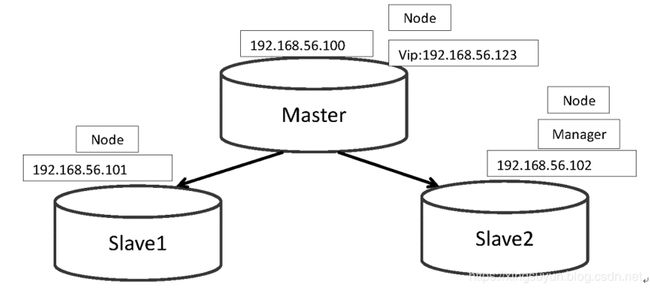
2.基于主从架构的双主+Keepalived
中小型规模的时候,采用这种架构是最省事的。 两个节点可以采用简单的一主一从模式,或者双主模式,并且放置于同一个VLAN中,在master节点发生故障后,利用keepalived/heartbeat的高可用机制实现快速切换到slave节点。
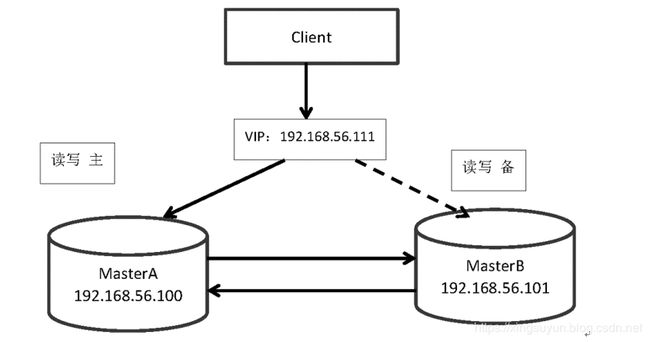
3.基于Galera协议的MySQL高可用集群架构
Galera产品是以Galera Cluster方式为MySQL提供高可用集群解决方案的。Galera Cluster就是集成了Galera插件的MySQL集群。Galera replication是Codership提供的MySQL数据同步方案,具有高可用性,方便扩展,并且可以实现多个MySQL节点间的数据同步复制与读写,可保障数据库的服务高可用及数据强一致性。
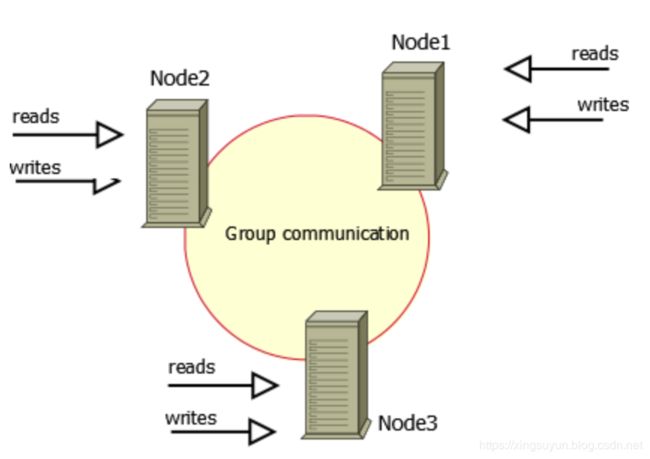
4.官方大力推进的InnoDB Cluster集群架构
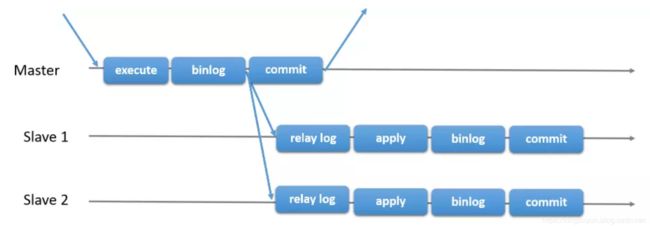
MySQL官方在5.7.17版本正式推出组复制(MySQL Group Replication,简称MGR)。master1,master2,master3,所有成员独立完成各自的事务。当客户端先发起一个更新事务,该事务先在本地执行,执行完成之后就要发起对事务的提交操作了。在还没有真正提交之前需要将产生的复制写集广播出去,复制到其他成员。如果冲突检测成功,组内决定该事务可以提交,其他成员可以应用,否则就回滚。最终,这意味着所有组内成员以相同的顺序接收同一组事务。因此组内成员以相同的顺序应用相同的修改,保证组内数据强一致性。
三、3G时代下的数据库:非关系型数据库应对数据暴增
1.3G时代数据暴增
2G定义为文字通讯,从1G跨入2G则是从模拟调制进入数字调制,相比较而言,2G移动通讯具备高度的保密性,系统的容量也在增加。同时从这一刻的开始,手机也能上网了。虽然当时只能浏览一些文本或者互相传送txt文件等,但我们可以畅快淋漓地随时随地看小说了,带来的满足感还是有的。但日益增长的图片和视频传输的需要,使得人们对于数据传输速度的要求日趋高涨,2G时代的网速显然不能支撑满足这一需求。随之3G图片时代应运而生。互联网超强的热度席卷了全球,触屏手机出现,变得娱乐方式多样化,人们对移动网络的需求也在不断加大。
由于采用更宽的频带,传输的稳定性也大大提高。速度的大幅提升和稳定性的提高,使大数据的传送更为普遍,移动通讯有更多样化的应用。3G可以被视为开启行动通信新纪元的重要关键,于是看新闻、刷微博、下载图片、在线听音乐等等都渐渐成为人们的娱乐日常。
2009年3G时代到来,同年MongoDB发布,NoSQL这个名词也正式出现在我们的视野中。虽然传统的单机关系型数据库底层架构很丰富,但随着移动互联热度的风靡全球,数据量呈现爆发性增长,传统的关系型数据库越来越难以满足用户不同的需求。即便是最基本的数据能存下的问题,当时都不能保证了。
2.NoSQL数据库:应对数据暴增的变革性解决方案
数据暴增,难道就没有解决办法嘛?当然有的!
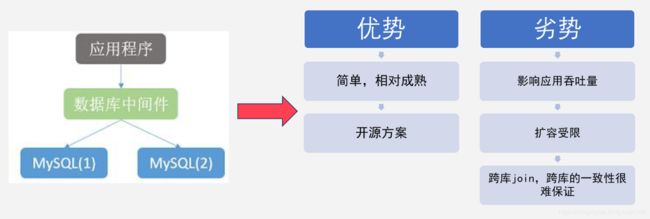
针对关系型数据库存不下数据的问题,有两个核心解决点:第一,我们可以沿着单机关系型数据库的基础之上做一些Proxy;第二,把数据存储在多个集群中,然后查询时再把数据汇总在一起。但是我们发现有了Proxy之后,业务要考虑sharding key的使用问题,针对业务扩容上会很受限,跨库跨表的操作很难实现,跨库join和跨库一致性很难得到支持。具体来说就是前端会把所有的应用逻辑,嵌入到中间件中。那么把所有的业务逻辑,全部放到一个中间件里,一定会制约业务的吞吐量和弹性扩张的能力。具体如下图所示。
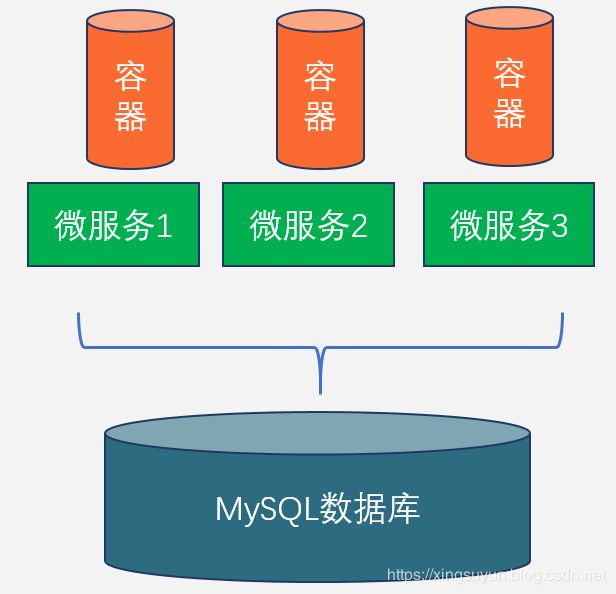
所以越来越多的企业或者互联网公司,开始采用微服务的技术了。把紧耦合到中间件中的应用,拆散到各个中间里面,来提供分布式的服务。微服务架构的核心都是一个可以弹性扩展不断伸缩的框架。比如业务中有登陆的子系统,财务的子系统。每一组子系统可以做成一组独立的服务。每一组独立的服务,我们上层可以使用容器技术,把应用逻辑写到一个个容器里面。当发现子系统压力过高或者计算能力不够的时候,我们只需要考虑增加容器,来提高应用的扩展能力和吞吐量。具体如下图所示。
我们回归到数据库本身,传统的关系型数据库既然应对数据暴增没有很好的解决办法,那我们就来看看通过底层非关系型的NoSQL。
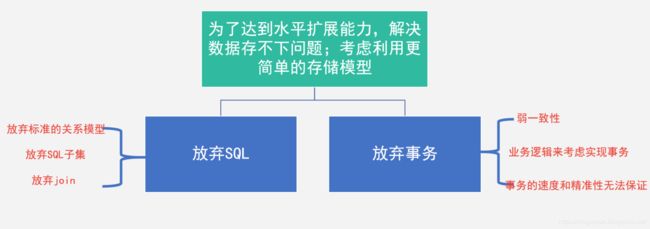
我们考虑用利用更简单的存储模型,放弃SQL,放弃事务,来获取一个更容易实现的扩展系统。HBase是其中的典型代表。HBase是Hadoop生态中的重要产品,Google BigTable的开源实现。HBase本身并不存储数据,数据还是以文件的形式存储在HDFS上,重度依赖 HDFS,并不支持ACID跨行事务。
3.MongoDB:首个支持跨文档事务的NoSQL数据库
说到这里就不得不好好聊聊MongoDB了。MongoDB4.0开始支持跨文档事务,这就也意味着MongoDB是首个支持跨文档事务的NoSQL数据库,将文档模型的速度,灵活性和功能与ACID保证相结合。现在使用MongoDB解决各种用户案例变得更加容易。更值得一提的是从MongoDB4.2版本开始支持分布式事务了。原来在4.0版本中的事务存在最大修改 16MB、事务执行时间不能过长的限制都已经解决了。分布式事务的支持也意味用户修改分片key的内容成为可能,因为修改分片key的内容,可能会导致key要迁移到其他shard,而在4.2之前,无法保证这个迁移动作的原子性,而借助分布式事务,这个问题也就迎刃而解了。
MongoDB的复制级架构
三副本架构是最基础的复制集的架构,一主两备模式。主节点接受外界的读写请求,向备节点进行数据同步。当主节点宕掉,会自动切换到备节点,不影响线上业务,防止单点故障。
MongoDB的分片架构
分片是一种在多台机器上分配数据的方法。 MongoDB使用分片架构有助于您去管理非常大数量的数据集和高吞吐量操作的集群。 大数据量和高吞吐量的业务情况对单台服务器来讲是具备很大的挑战性的。例如,高查询率可能耗尽服务器的CPU容量。工作集大小超过系统内存,那么压力则会给到磁盘上,这对IO来讲不是我们所希望看到的。MongoDB支持通过分片进行水平缩放。
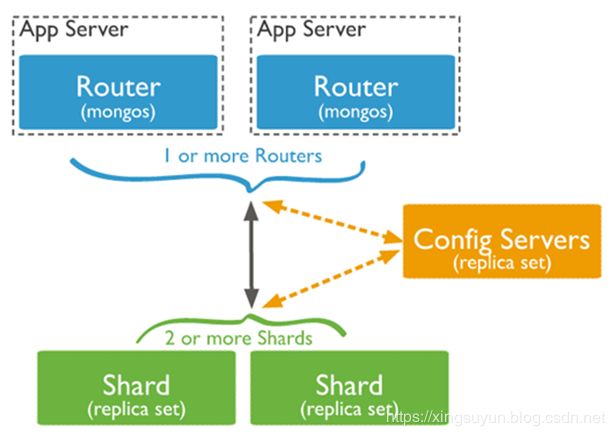
四、4G时代下的数据库:分布式+关系型的NewSQL
时间一晃到了2013年12月,工信部在其官网上宣布向中国移动、中国电信、中国联通颁发“LTE/第四代数字蜂窝移动通信业务(TD-LTE)”经营许可,也就是4G牌照。至此,移动互联网进入了一个新的时代,即4G视频时代。如今4G已经像 “水电”一样成为我们生活中不可缺少的基本资源。而且4G信号的覆盖范围也非常广泛,并且成为大多数人的标配,微信、微博、小视频等手机应用成为生活中的必须,经常看到很多人刷着抖音,快手。越来越多的人参与到拍小视频,当主播这个行业当中来。有句话“南抖音北快手,智障界的两泰斗”,流传比较广的,可见4G不仅开启了一个全民娱乐的时代,也引来了视频自媒体发展的红利时代。我们现在根本无法想象离开手机的生活会是什么样。
对于数据库的发展来说,我们之前也谈了关系型数据库的代表MySQL,非关系型数据库的代表MongoDB,接下来聊聊在4G时代的这个时间节点,NewSQL这个名词出现在了我们的视野里面。如果说NoSQL是一种变革,那么NewSQL就是进击的巨人。 记得三国演义开篇说到“论天下大势,分久必合合久必分”。我们本文聊聊“分久必合”。
NewSQL应是RDBMS中的数据模型(关系型、符合ACID)和NoSQL中的计算框架、分布式存储、开源特定的结合产物。
2012年底到2013年初,Google 相继发表了Spanner和F1两套系统的论文,让业界第一次看到了关系模型和NoSQL的扩展性在一个大规模生产系统上融合的可能性。
Google 的Spanner + F1,是第一个生产环境中大规模验证的 NewSQL 系统;Spanner 通过使用硬件设备(GPS时钟+原子钟)巧妙地解决时钟同步的问题——在分布式系统里,时钟正是最让人头痛的问题。Spanner的强大之处在于即使两个数据中心隔得非常远,也能保证通过TrueTime API获取的时间误差在一个很小的范围内(10ms),并且不需要通讯。Spanner的底层仍然基于分布式文件系统,不过论文里也说是可以未来优化的点。Google的内部的数据库存储业务,大多是3~5副本,重要的数据需要7副本,且这些副本遍布全球各大洲的数据中心,由于普遍使用了Paxos,延迟是可以缩短到一个可以接受的范围(写入延迟100ms以上),另外由Paxos带来的Auto-Failover能力,更是让整个集群即使数据中心瘫痪,业务层都是透明无感知的。F1是构建在Spanner之上,对外提供了SQL接口,F1是一个分布式MPP SQL层,其本身并不存储数据,而是将客户端的SQL翻译成对KV的操作,调用Spanner来完成请求。
NewSQL中的典型代表就是Google Spanner和国内的TiDB,巨杉等。
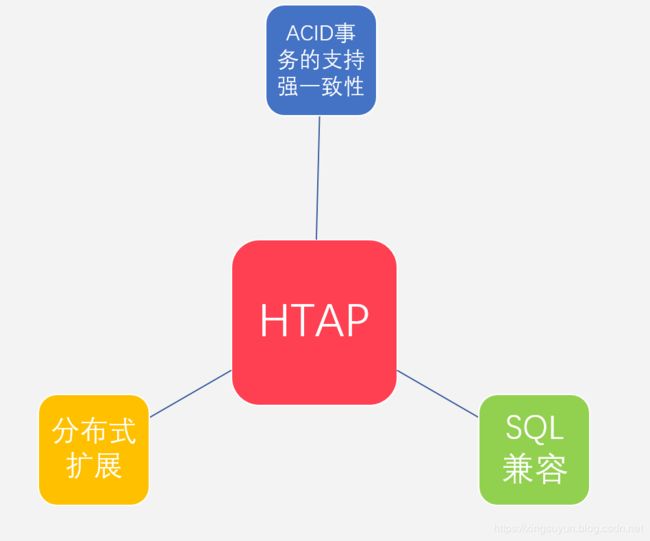
结合NewSQL数据库的特点,主要可以总结为新老技术的搭配。新技术中最基本的是扩展能力,包括存储和计算扩展;除了扩展能力,当然还有HTAP这种混合事务和分析场景,适应更多应用数据需求。老技术中主要就是高可用性,在一个比较大的分布式集群中,少量节点失效下,数据库依然能够提供服务,依然能够自我恢复,依然可用;事务ACID的支持,处理OLTP的能力;最后就是SQL完整支持,业务采用SQL来对存储进行交互。其特性如下图所示。
这里我们看看TiDB分布式数据库的样子,如下图所示。
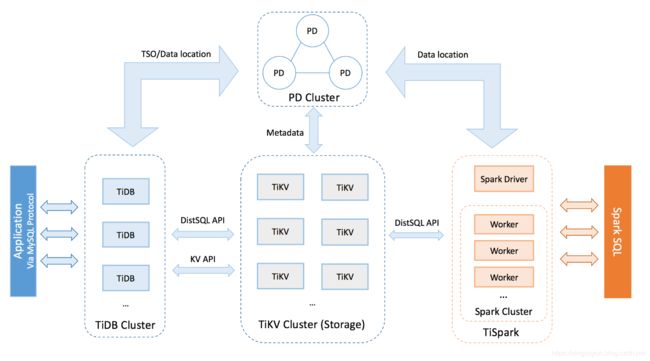
整体架构介绍:TiKV+PD 形成了kv的带事务的存储引擎。
- TiKV:主要存储数据,把数据一片一片存储在集群中。
- PD:(集群管理者)存储Tikv中的元信息。每片数据所在位置和有哪些副本。PD还要负责对TiKV节点进行负载均衡调度和管理。
- TiDB:无状态的计算层(随意扩展),支持MySQL协议和SQL请求和SQL优化。发送计算和获取数据的请求,通过MySQL协议返回给客户端。TiDB是存储引擎和业务端的桥梁枢纽。
六、5G风起,数据库将会如何发展?
1.数据库发展总结
盘点数据库的发展历程,我们可以通过下面这幅图来完全体现出来(图片来源:https://db-engines.com/en/ranking)。
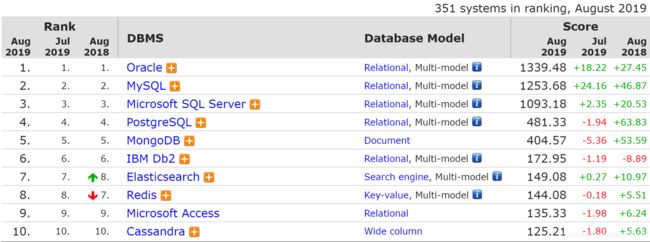
从上图中,我们了解到在最开始发展起来的是关系型数据库+SQL(代表数据库产品Oracle,MySQL),然后发展到了非关系型NoSQL(代表数据库产品MongoDB),最后是分布式+关系型的NewSQL(代表数据库产品TiDB)。
2.5G风起,数据库上云是必然趋势
然后再来说说5G,即第五代移动通信技术。国际电联将5G未来的应用场景划分为移动互联网和物联网两大类。凭借低延时、高可靠、低功耗以及飞一般的网速的特点,5G的应用范围更广泛远超4G、将渗透到生产生活的各个领域,不仅能使得超高清视频、浸入式游戏等交互方式实现再升级,还能实现海量的机器通信、支持智能家居、智能设备和智能城市,也将在车联网、移动医疗、工业互联网等垂直行业一展身手。简单来说,5G更快、更安全、信号更强、覆盖面积更广、发展方向更加多维。如果不出意外,5G手机明年将纷纷上市。同时,中国联通和中国电信都将于2020年实现重点城市的5G商用。这些都将带领人类开启一个万物互联、高度便捷化、自动化、智能化的崭新生活方式。
下面聊聊5G来了之后,未来数据库的发展是个什么样子呢?
根据Gartner预测,到2022或者2023年,将有超过3/4的数据库被部署到或者迁移到云平台,不足5%的数据库会考虑部署到本地,这就意味着云将主导数据库未来的市场。
我们知道云计算是分层次的,即三种服务模式(IaaS,PaaS,SaaS)。数据库是一款服务软件也就是SaaS模式,整个数据的生命周期,数据库起到的作用都是至关重要的。而且还有一点,数据与应用必须紧密配合,而5G时代,大多数应用也要部署在云上,那云数据库这个趋势也就毋庸置疑了。
不过,在上云这个过程中,传统的数据库与云端数据库不一样的产品架构,给上云带来了很高的门槛。还有商业数据库其高成本,难维护的特点,必将接受国产、开源数据库他们其可弹性扩展,易用、开放等特点的各种冲击与挑战。很应景的一句话是”数据信息科技,国产自主可控,开源大势所趋“。
2.5G数据库应该具备能力
我们再来想一想对于5G时代的到来,该如何规划好数据库呢?换句话说,5G数据库应该具备什么样的能力呢?
首先先从高吞吐量和低延迟的角度入手,5G的ITU IMT-2020 规范要求速度高达每秒 20 千兆位,目标延迟为1ms。这种要求才是打开数据流的金钥匙。其次,5G数据库必须拥有瞬间线性扩展能力,5G网络不仅会从5G启用的应用程序中生成大量的流数据,还会从网络、订阅、企业、网络运营商和呼叫处理中生成大量的流数据。
那么,对于目前传统的OLTP数据库来说,是否机器越多,SQL执行就越快呢?
答案肯定是否定的。
对于OLTP数据库中的线性扩展,增加机器数,单SQL的响应时间基本不会发生太大变化。随着云计算技术不断成熟,云数据库开始逐渐崛起,企业正将新应用向云转移,对数据存储和计算分析的能力要求不断地加强。由云厂商主导的云原生数据库势必是这波改变的推动者,云原生数据库的优势在于它的成本、灵活度、安全、技术进化层面。5G数据库更需要在云中无缝工作,并且还要在容器化环境中进行操作。而5G必将带来数据的洪流,这也将推动企业数字化的转型。届时,传统数据库将肯定跟不上当前企业发展的脚步。5G将以前所未有的速度生成前所未见的巨大数据。
3.5G+AI助推数据库发展
科技界有两大领域越来越热:一个是5G,一个是AI。两者都是能够改变时代的颠覆性技术。单独看5G或AI技术,它们的发展都面临重重挑战,但是,当5G与AI这两大颠覆性技术深度融合的情况下,去看数据库的发展呢?
5G、Al通讯与人工智能进入工业物联网、金融、空气预测等数据管理时,由需求推动的时序信息会使数据库变成实时,并且能即时生成预测结果。数据库如果实时可以用Al算法以后,并可生成实时的预报警系统,让大家把损失防范于未然。就如同下图所示,5G和AI共同助推数据库的发展。

市面上也有一些时序数据库,在未来5G时代,比如 RDDTool 和 Graphite 会自动删除高精度的数据,只保留低精度的。而这些“功能”对关系型数据库而言,简直是不可想象的。
4.未来数据库关键词
小结一下,未来数据库的发展,必然离不开下面这些词汇:
上云,数据洪流,开源,国产可控,低延迟,高吞吐,实时……
而对于我们来说,就要更早地适应未来的变化,提升自己一专多能的技术域,找到做技术那份最简单的快乐足以。