使用TF-IDF算法、THULAC和余弦相似性算法比较影评的相似程度
日常中,很多时候是否感觉看过大量的相同或相似的文章呢?有没有想过他们的相似度是多少?我们能不能使用代码去计算出来呢?阅读这篇文章可以给你一种比较的思路~
TF-IDF算法
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。该算法在数据挖掘、文本处理和信息检索等领域得到了广泛的应用,如从一篇文章中找到它的关键词。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF实际上就是 TF减IDF,其中 TF(Term Frequency),表示词条在文章Document 中出现的频率;IDF(Inverse Document Frequency),其主要思想就是,如果包含某个词 Word的文档越少,则这个词的区分度就越大,也就是 IDF 越大。对于如何获取一篇文章的关键词,我们可以计算这边文章出现的所有名词的 TF-IDF,TF-IDF越大,则说明这个名词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
##计算步骤
计算词频(TF)
词 频 = 某 个 词 在 文 章 中 的 出 现 次 数 文 章 总 次 数 词频=\frac{某个词在文章中的出现次数}{文章总次数} 词频=文章总次数某个词在文章中的出现次数
计算逆文档频率(IDF)
逆 文 档 频 率 = log 语 料 库 的 文 档 总 数 包 含 该 词 的 文 档 数 + 1 逆文档频率=\log\frac{语料库的文档总数}{包含该词的文档数+1} 逆文档频率=log包含该词的文档数+1语料库的文档总数
计算词频-逆文档频率(TF-IDF)
词 频 − 逆 文 档 频 率 = 词 频 ∗ 逆 文 档 频 率 词频−逆文档频率=词频∗逆文档频率 词频−逆文档频率=词频∗逆文档频率
余弦相似性算法
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
举个简单的例子:
A:西米喜欢健身
B:超超不爱健身,喜欢打游戏
step1:分词
A:西米/喜欢/健身
B:超超/不/喜欢/健身,喜欢/打/游戏
step2:列出两个句子的并集
西米/喜欢/健身/超超/不/打/游戏
step3:计算词频向量
A:[1,1,1,0,0,0,0]
B:[0,2,1,1,1,1,1]
step4:计算余弦值
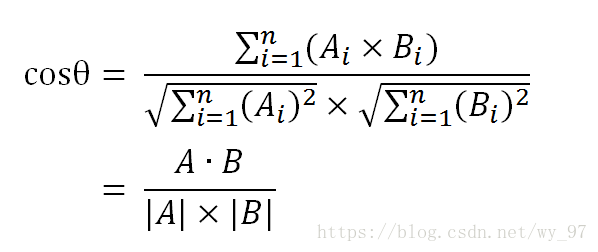
余弦值越大,证明夹角越小,两个向量越相似。
构建爬虫爬取两篇影评
ummmmm,这里来源选用了百度搜索相同关键词得到的两篇文章!ps:最近《最好的我们》挺火的,从豆瓣上找了一句很有感觉的话去百度搜了一下,天啊
标题一样的影评很多啊,这里我们选用了两篇不一样的发布者,不一样的平台,且没有参考链接的两篇同标题影评进行对比~
《后来的我们》| 这一次,终于学会好好和过去说“再见” @拾文化
《后来的我们》:这次,终于学会和过去好好说“再见”!@杜娟
爬虫太简单了,略~
使用THULAC进行分词
使用
sudo pip install thulac
#通过 import thulac 来引用
参数
thulac(user_dict=None, model_path=None, T2S=False, seg_only=False, filt=False)初始化程序,进行自定义设置
user_dict 设置用户词典,用户词典中的词会被打上uw标签。词典中每一个词一行,UTF8编码
T2S 默认False, 是否将句子从繁体转化为简体
seg_only 默认False, 时候只进行分词,不进行词性标注
filt 默认False, 是否使用过滤器去除一些没有意义的词语,例如“可以”。
model_path 设置模型文件所在文件夹,默认为models/
cut(文本, text=False) 对一句话进行分词
text 默认为False, 是否返回文本,不返回文本则返回一个二维数组([[word, tag]..]),tag_only模式下tag为空字符。
cut_f(输入文件, 输出文件) 对文件进行分词
run() 命令行交互式分词(屏幕输入、屏幕输出)
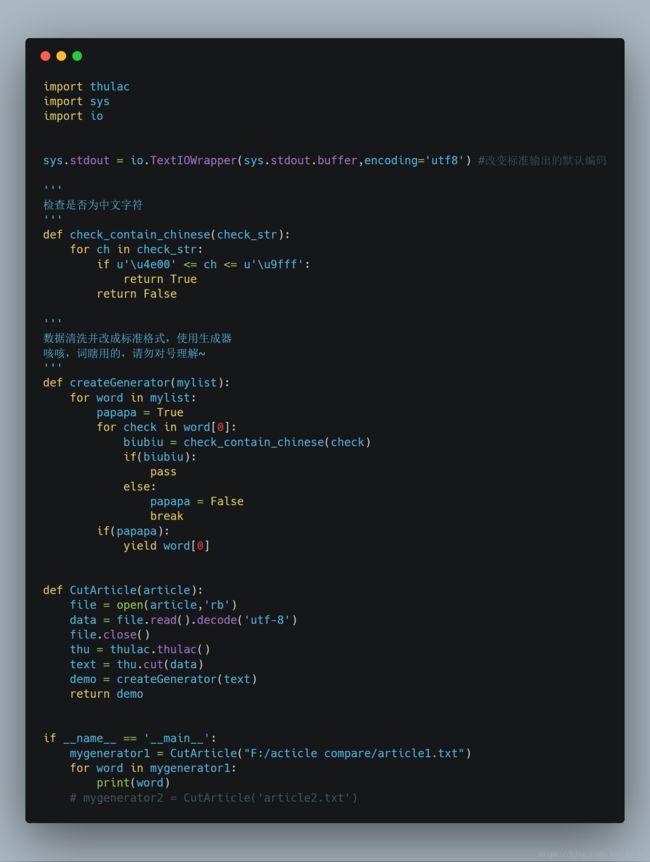
使用TF-IDF算法进行处理
##创建自己的语料库
这里我直接去了头号玩家的豆瓣评论区,爬虫拉下来139个文本,作为我的语料库:
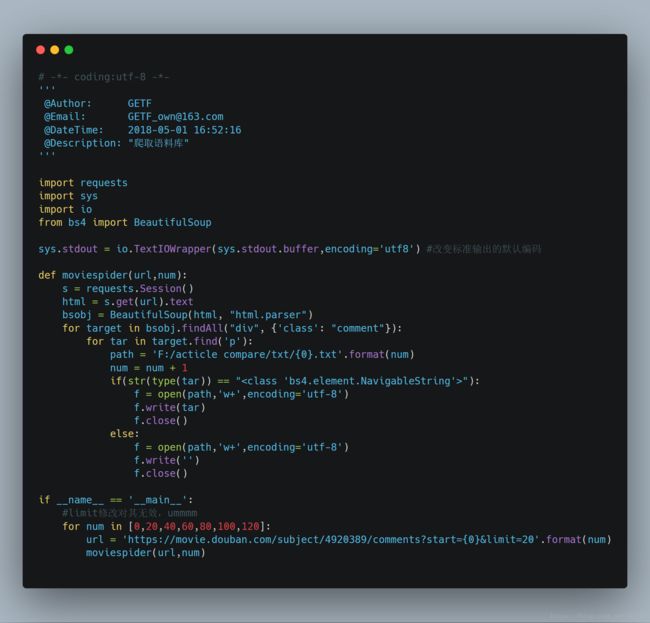
计算TF-IDF
这里接上面的代码继续进行操作:
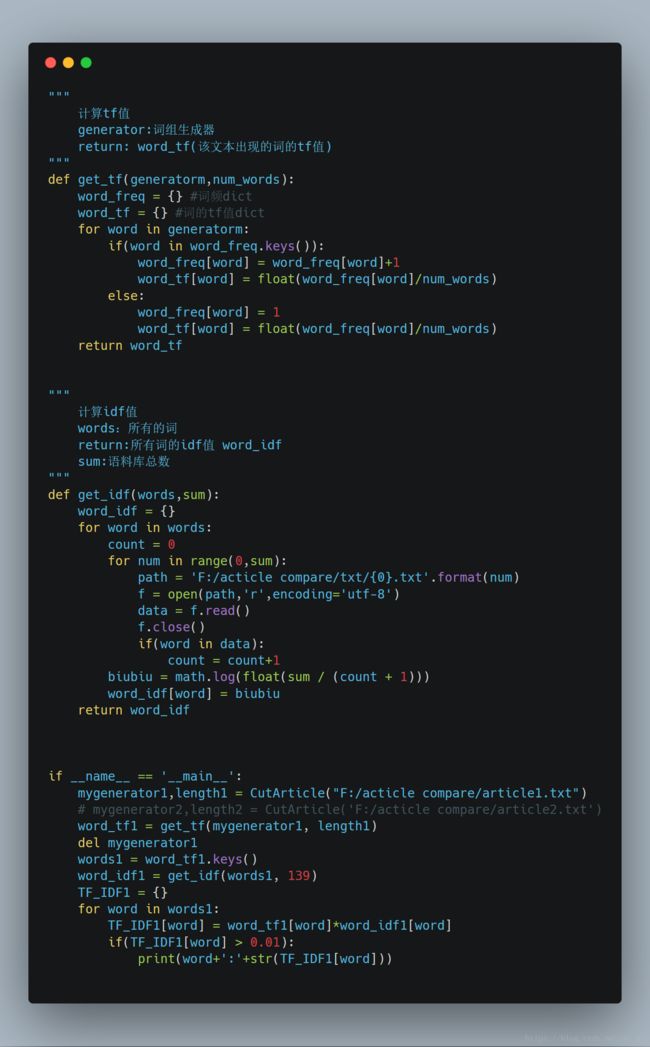
可得数据集如下:
就:0.013198939096501449
我:0.02035872203047933
五一:0.011431213744704304
了:0.011189014848080815
暂时:0.015241618326272407
没有:0.013227949304019408
自己:0.03381929706000893
哭:0.01369953502706873
来:0.01460491886134683
我们:0.017024019729794768
一边:0.013100623173963695
看到:0.010635134842542547
很:0.01001645657555634
过去:0.013100623173963695
内心:0.011431213744704304
见:0.026658497915183967
清:0.02369644259127464
小晓:0.03810404581568102
为什:0.011431213744704304
么:0.024199486607050496
过:0.018547006575810713
很多:0.014810276619546649
卖:0.01184822129563732
同学:0.011431213744704304
去:0.017024019729794768
当时:0.015241618326272407
现在:0.01184822129563732
他们:0.010959628021654984
爱情:0.01905202290784051
说:0.016828498947042258
他:0.019471140593740315
她:0.02947640214141831
飞奔:0.011431213744704304
勇气:0.01184822129563732
[Finished in 11.8s]
ummmm,可能是我语料库选的不好,按照我的逻辑好多词好像不是关键词呢,QWQ
计算余弦相似度
原理上面已经举过例子了,这里直接上代码:
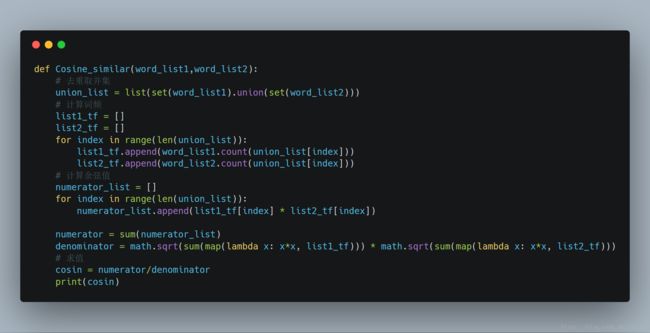
最终结果:
0.40219983326992187
[Finished in 31.8s]
到此结束,希望本文能为你带来更好的关于这几个算法的理解如有问题欢迎邮箱交流
本源码放我github了,请移步下载~写文不易,如果觉得有用请记得点赞!
参考链接:
https://blog.csdn.net/lionel_fengj/article/details/53699903
http://thulac.thunlp.org/
https://thief.one/2018/04/12/1/
https://blog.csdn.net/u012160689/article/details/15341303