萌新的Python学习日记 - 爬虫无影 - 爬取豆瓣电影top250并入库:豆瓣电影top250
博客第九天
测试页面:
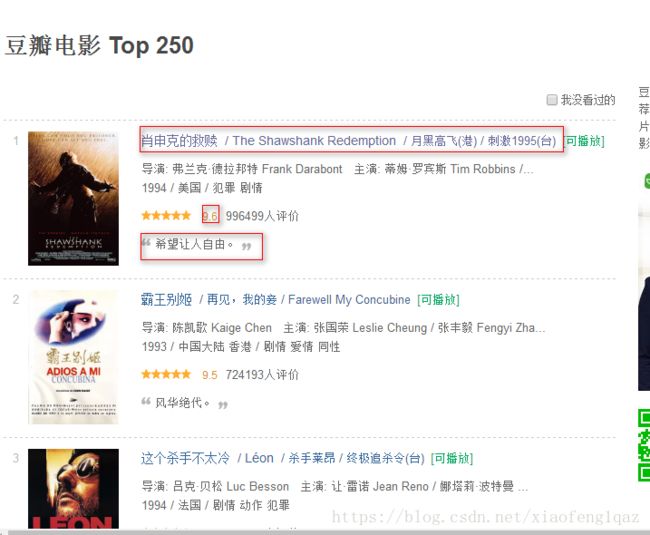
豆瓣电影 Top 250
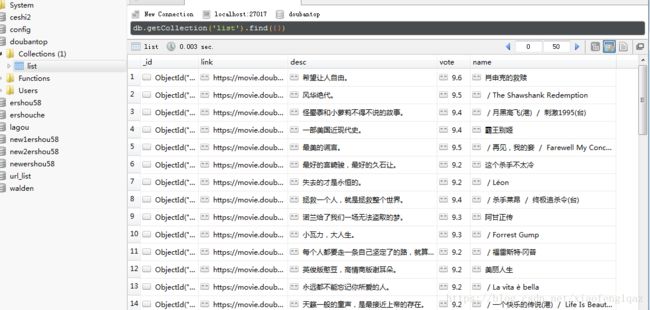
https://movie.douban.com/top250?start=0&filter=目的:抓取该页面中每部电影的名称,链接,评分,评语
工程内容:Python3.5,jupyter notebook
工具包:requests,BeautifulSoup
代码(可翻页):
import requestsfrom bs4 import BeautifulSoup as bs
import pymongo
client = pymongo.MongoClient('localhost',27017)
doubantop = client['doubantop']
toplist = doubantop['list']
# url = 'https://movie.douban.com/top250?start={}&filter='.format(i)
# url = 'https://movie.douban.com/top250?start=0&filter='
def getlist(url):
web = requests.get(url)
soup = bs(web.text,'lxml')
names = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a > span')
links = soup.select('#content > div > div.article > ol > li > div > div.info > div.hd > a')
votes = soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > div > span.rating_num')
descs = soup.select('#content > div > div.article > ol > li > div > div.info > div.bd > p.quote > span')
for name,link,vote,desc in zip(names,links,votes,descs):
data = {
'name':name.text,
'link':link.get('href'),
'vote':vote.text,
'desc':desc.text
}
toplist.insert_one(data)
print(data)
# getlist(url)
for i in range(0,10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25)
getlist(url)
print内容(部分):

数据库内容: