【手把手机器学习入门到放弃】Random Forest && Extremely Randomized Trees参数全解析
随机森林 Random Forest && Extremely Randomized Trees
多种树有利于提高分类准确率
随机森林 Random Forest 是在决策树的基础上进行两种随机
- 随机选取一个数据集的一个子集作为样本
- 随机选取部分特征或者全部特征作为待选择特征库
超随机树 Extremely Randomized Trees
- 在随机森林的基础上对分裂阀值进行进一步的随机
文章目录
- 随机森林 Random Forest && Extremely Randomized Trees
- 不调参训练
- 使用随机森林算法
- 使用Extremely Randomized Trees
- Random forest 参数
- Extremely Randomized Trees 参数
- 测试树的多少对两种结果的影响
- 测试树的深度对两种算法的影响
- OOBS参数的影响
- min_samples_split 的作用
- min_samples_leaf的影响
- 总结
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import metrics
不调参训练
还是选用美国人群收入的数据进行实验,首先先进行一次不做任何调参的实验。
X = pd.read_csv('american_salary_feture.csv')
y = pd.read_csv('american_salary_label.csv', header=None)
y= np.array(y)
y=y.ravel()
print(X.shape, y.shape)
(32561, 106) (32561,)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
使用随机森林算法
clf = RandomForestClassifier(n_estimators=10, max_depth=None,
min_samples_split=2, random_state=0)
clf = clf.fit(X_train, y_train)
print("train_score:",clf.score(X_train, y_train))
print("test_score:", clf.score(X_test, y_test))
print("train_f1_score:", metrics.f1_score(clf.predict(X_train), y_train))
print("test_f1_score:", metrics.f1_score(clf.predict(X_test), y_test))
train_score: 0.987018837018837
test_score: 0.8449821889202801
train_f1_score: 0.9723602755253291
test_f1_score: 0.6437041219649915
可以看到这是一个过拟合的算法,在训练集的表现远好于在测试集的表现
使用Extremely Randomized Trees
clf_e = ExtraTreesClassifier(n_estimators=10, max_depth=None,
min_samples_split=2, random_state=0)
clf_e.fit(X_train, y_train)
/Users/yaochenli/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:3: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().
This is separate from the ipykernel package so we can avoid doing imports until
ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None,
oob_score=False, random_state=0, verbose=0,
warm_start=False)
print("train_score:",clf_e.score(X_train, y_train))
print("test_score:", clf_e.score(X_test, y_test))
print("train_f1_score:", metrics.f1_score(clf_e.predict(X_train), y_train))
print("test_f1_score:", metrics.f1_score(clf_e.predict(X_test), y_test))
train_score: 1.0
test_score: 0.8259427588748312
train_f1_score: 1.0
test_f1_score: 0.6084553744128214
依然是过拟合的模型,但是表现比随机森林更强
Random forest 参数
-
n_estimators : integer, optional (default=10)
The number of trees in the forest.
树的个数
Changed in version 0.20: The default value of n_estimators will change from 10 in version 0.20 to 100 in version 0.22.
-
criterion : string, optional (default=”gini”)
The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain. Note: this parameter is tree-specific.
损失函数,可以选择gini或者entropy
-
max_depth : integer or None, optional (default=None)
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
最大深度,如果不指定,那么树将会一直分裂到无法分裂为止
-
min_samples_split : int, float, optional (default=2)
The minimum number of samples required to split an internal node:
If int, then consider min_samples_split as the minimum number.
If float, then min_samples_split is a fraction and ceil(min_samples_split * n_samples) are the minimum number of samples for each split.
Changed in version 0.18: Added float values for fractions.
如果是整数,就是每个叶子节点需要进一步分裂的最少样本数,如果是小数,那么这个最少样本个数等于min_samples_split*样本总数。
-
min_samples_leaf : int, float, optional (default=1)
The minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if it leaves at least min_samples_leaf training samples in each of the left and right branches. This may have the effect of smoothing the model, especially in regression.
If int, then consider min_samples_leaf as the minimum number.
If float, then min_samples_leaf is a fraction and ceil(min_samples_leaf * n_samples) are the minimum number of samples for each node.
Changed in version 0.18: Added float values for fractions.
如果是整数,就是每个叶子节点最少容纳的样本数,如果是小数,那么每个叶子节点最少容纳的个数等于min_samples_leaf*样本总数。如果某个分裂条件下分裂出得某个子树含有的样本数小于这个数字,那么不能进行分裂。
-
min_weight_fraction_leaf : float, optional (default=0.)
The minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node. Samples have equal weight when sample_weight is not provided.
叶子节点最少需要占据总样本的比重,如果样本比重没有提供的话,每个样本占有相同比重
-
max_features : int, float, string or None, optional (default=”auto”)
The number of features to consider when looking for the best split:
If int, then consider max_features features at each split.
If float, then max_features is a fraction and int(max_features * n_features) features are considered at each split.
If “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
Note: the search for a split does not stop until at least one valid partition of the node samples is found, even if it requires to effectively inspect more than max_features features.
分裂时需要考虑的最多的特征数,如果是整数,那么分裂时就考虑这几个特征,如果是小数,则分裂时考虑的特征数=max_features*总特征数,如果是“auto”或者“sqrt”,考虑的特征数是总特征数的平方根,如果是“log2”,考虑的特征数是log2(总特征素),如果是None,考虑的特征数=总特征数。需要注意的是,如果在规定的考虑特征数之内无法找到满足分裂条件的特征,那么决策树会继续寻找特征,直到找到一个满足分裂条件的特征。
-
max_leaf_nodes : int or None, optional (default=None)
Grow trees with max_leaf_nodes in best-first fashion. Best nodes are defined as relative reduction in impurity. If None then unlimited number of leaf nodes.
规定最多的叶子个数,根据区分度从高到低选择叶子节点,如果不传入这个参数,则不限制叶子节点个数。
-
min_impurity_decrease : float, optional (default=0.)
A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
The weighted impurity decrease equation is the following:
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
where N is the total number of samples, N_t is the number of samples at the current node, N_t_L is the number of samples in the left child, and N_t_R is the number of samples in the right child.N, N_t, N_t_R and N_t_L all refer to the weighted sum, if sample_weight is passed.
New in version 0.19.
最低分裂不纯度,当分裂后的减少的不纯度大于等于这个值时,才进行分裂。不纯度的计算公式如上。
-
min_impurity_split : float, (default=1e-7)
Threshold for early stopping in tree growth. A node will split if its impurity is above the threshold, otherwise it is a leaf.
Deprecated since version 0.19: min_impurity_split has been deprecated in favor of min_impurity_decrease in 0.19. The default value of min_impurity_split will change from 1e-7 to 0 in 0.23 and it will be removed in 0.25. Use min_impurity_decrease instead.
最少分裂阀值,如果一个节点的不纯度大于这个值的时候才进行分裂。
-
bootstrap : boolean, optional (default=True)
Whether bootstrap samples are used when building trees. If False, the whole datset is used to build each tree.
是否使用自主采样法,即每次采样之后放回,对于数据集较小的情况适用,但自主采样法也会引入一定误差,对数据集较大的情况下不建议使用,如果这个选择False, 那么所有数据都会用来生成每棵树
-
oob_score : bool (default=False)
Whether to use out-of-bag samples to estimate the generalization accuracy.
对于使用bootstrap的数据集,大约有36.8%的数据不会被取到,使用这些不会被取到的数据进行评分,有利于防止过拟合。
-
n_jobs : int or None, optional (default=None)
The number of jobs to run in parallel for both fit and predict. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
同时运行的线程数
-
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
随机数值,用于打乱,默认使用np.random
-
verbose : int, optional (default=0)
Controls the verbosity when fitting and predicting.
训练过程中输出轮数信息
-
warm_start : bool, optional (default=False)
When set to True, reuse the solution of the previous call to fit and add more estimators to the ensemble, otherwise, just fit a whole new forest. See the Glossary.
利用之前已经训练过的模型进行继续训练。
-
class_weight : dict, list of dicts, “balanced”, “balanced_subsample” or None, optional (default=None)
Weights associated with classes in the form {class_label: weight}. If not given, all classes are supposed to have weight one. For multi-output problems, a list of dicts can be provided in the same order as the columns of y.
Note that for multioutput (including multilabel) weights should be defined for each class of every column in its own dict. For example, for four-class multilabel classification weights should be [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] instead of [{1:1}, {2:5}, {3:1}, {4:1}].
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
The “balanced_subsample” mode is the same as “balanced” except that weights are computed based on the bootstrap sample for every tree grown.
For multi-output, the weights of each column of y will be multiplied.
Note that these weights will be multiplied with sample_weight (passed through the fit method) if sample_weight is specified.
类别权重,对每个类别设置权重,示例如上,如果标签是多列的,那么每一列的的权重将会被相乘,如果在fit方法中传入了样本权重字典,那么类别权重会和样本权重相乘。
如果选择balanced_subsample,且选择了bootstrap,那么权重计算是根据每次bootstrap选出的数据集进行计算的。
Extremely Randomized Trees 参数
-
n_estimators : integer, optional (default=10)
The number of trees in the forest.
树的个数
Changed in version 0.20: The default value of n_estimators will change from 10 in version 0.20 to 100 in version 0.22.
-
criterion : string, optional (default=”gini”)
The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain. Note: this parameter is tree-specific.
损失函数,可以选择gini或者entropy
-
max_depth : integer or None, optional (default=None)
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.
最大深度,如果不指定,那么树将会一直分裂到无法分裂为止
-
min_samples_split : int, float, optional (default=2)
The minimum number of samples required to split an internal node:
If int, then consider min_samples_split as the minimum number.
If float, then min_samples_split is a fraction and ceil(min_samples_split * n_samples) are the minimum number of samples for each split.
Changed in version 0.18: Added float values for fractions.
如果是整数,就是每个叶子节点需要进一步分裂的最少样本数,如果是小数,那么这个最少样本个数等于min_samples_split*样本总数。
-
min_samples_leaf : int, float, optional (default=1)
The minimum number of samples required to be at a leaf node. A split point at any depth will only be considered if it leaves at least min_samples_leaf training samples in each of the left and right branches. This may have the effect of smoothing the model, especially in regression.
If int, then consider min_samples_leaf as the minimum number.
If float, then min_samples_leaf is a fraction and ceil(min_samples_leaf * n_samples) are the minimum number of samples for each node.
Changed in version 0.18: Added float values for fractions.
如果是整数,就是每个叶子节点最少容纳的样本数,如果是小数,那么每个叶子节点最少容纳的个数等于min_samples_leaf*样本总数。如果某个分裂条件下分裂出得某个子树含有的样本数小于这个数字,那么不能进行分裂。
-
min_weight_fraction_leaf : float, optional (default=0.)
The minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node. Samples have equal weight when sample_weight is not provided.
叶子节点最少需要占据总样本的比重,如果样本比重没有提供的话,每个样本占有相同比重
-
max_features : int, float, string or None, optional (default=”auto”)
The number of features to consider when looking for the best split:
If int, then consider max_features features at each split.
If float, then max_features is a fraction and int(max_features * n_features) features are considered at each split.
If “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features) (same as “auto”).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features.
Note: the search for a split does not stop until at least one valid partition of the node samples is found, even if it requires to effectively inspect more than max_features features.
分裂时需要考虑的最多的特征数,如果是整数,那么分裂时就考虑这几个特征,如果是小数,则分裂时考虑的特征数=max_features*总特征数,如果是“auto”或者“sqrt”,考虑的特征数是总特征数的平方根,如果是“log2”,考虑的特征数是log2(总特征素),如果是None,考虑的特征数=总特征数。需要注意的是,如果在规定的考虑特征数之内无法找到满足分裂条件的特征,那么决策树会继续寻找特征,直到找到一个满足分裂条件的特征。
-
max_leaf_nodes : int or None, optional (default=None)
Grow trees with max_leaf_nodes in best-first fashion. Best nodes are defined as relative reduction in impurity. If None then unlimited number of leaf nodes.
规定最多的叶子个数,根据区分度从高到低选择叶子节点,如果不传入这个参数,则不限制叶子节点个数。
-
min_impurity_decrease : float, optional (default=0.)
A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
The weighted impurity decrease equation is the following:
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
where N is the total number of samples, N_t is the number of samples at the current node, N_t_L is the number of samples in the left child, and N_t_R is the number of samples in the right child.N, N_t, N_t_R and N_t_L all refer to the weighted sum, if sample_weight is passed.
New in version 0.19.
最低分裂不纯度,当分裂后的减少的不纯度大于等于这个值时,才进行分裂。不纯度的计算公式如上。
-
min_impurity_split : float, (default=1e-7)
Threshold for early stopping in tree growth. A node will split if its impurity is above the threshold, otherwise it is a leaf.
Deprecated since version 0.19: min_impurity_split has been deprecated in favor of min_impurity_decrease in 0.19. The default value of min_impurity_split will change from 1e-7 to 0 in 0.23 and it will be removed in 0.25. Use min_impurity_decrease instead.
最少分裂阀值,如果一个节点的不纯度大于这个值的时候才进行分裂。
-
bootstrap : boolean, optional (default=True)
Whether bootstrap samples are used when building trees. If False, the whole datset is used to build each tree.
是否使用自主采样法,即每次采样之后放回,对于数据集较小的情况适用,但自主采样法也会引入一定误差,对数据集较大的情况下不建议使用,如果这个选择False, 那么所有数据都会用来生成每棵树
-
oob_score : bool (default=False)
Whether to use out-of-bag samples to estimate the generalization accuracy.
对于使用bootstrap的数据集,大约有36.8%的数据不会被取到,使用这些不会被取到的数据进行评分,有利于防止过拟合。
-
n_jobs : int or None, optional (default=None)
The number of jobs to run in parallel for both fit and predict. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
同时运行的线程数
-
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator; If RandomState instance, random_state is the random number generator; If None, the random number generator is the RandomState instance used by np.random.
随机数值,用于打乱,默认使用np.random
-
verbose : int, optional (default=0)
Controls the verbosity when fitting and predicting.
训练过程中输出轮数信息
-
warm_start : bool, optional (default=False)
When set to True, reuse the solution of the previous call to fit and add more estimators to the ensemble, otherwise, just fit a whole new forest. See the Glossary.
利用之前已经训练过的模型进行继续训练。
-
class_weight : dict, list of dicts, “balanced”, “balanced_subsample” or None, optional (default=None)
Weights associated with classes in the form {class_label: weight}. If not given, all classes are supposed to have weight one. For multi-output problems, a list of dicts can be provided in the same order as the columns of y.
Note that for multioutput (including multilabel) weights should be defined for each class of every column in its own dict. For example, for four-class multilabel classification weights should be [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] instead of [{1:1}, {2:5}, {3:1}, {4:1}].
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
The “balanced_subsample” mode is the same as “balanced” except that weights are computed based on the bootstrap sample for every tree grown.
For multi-output, the weights of each column of y will be multiplied.
Note that these weights will be multiplied with sample_weight (passed through the fit method) if sample_weight is specified.
类别权重,对每个类别设置权重,示例如上,如果标签是多列的,那么每一列的的权重将会被相乘,如果在fit方法中传入了样本权重字典,那么类别权重会和样本权重相乘。
如果选择balanced_subsample,且选择了bootstrap,那么权重计算是根据每次bootstrap选出的数据集进行计算的。
两个树的参数是一样的,我们把他们放在一起做比较
测试树的多少对两种结果的影响
estimators = [10*x for x in range(1, 11)]
estimators
[10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
f1_score_random_forest_train=np.zeros(10)
f1_score_random_forest_test=np.zeros(10)
f1_score_extreme_random_train=np.zeros(10)
f1_score_extreme_random_test=np.zeros(10)
i=0
for estimator in estimators:
clf1=RandomForestClassifier(n_estimators = estimator, random_state=0, bootstrap ='False', class_weight="balanced_subsample")
clf1.fit(X_train,y_train)
f1_score_random_forest_test[i] = metrics.f1_score(clf1.predict(X_test), y_test)
f1_score_random_forest_train[i] = metrics.f1_score(clf1.predict(X_train), y_train)
clf2 = ExtraTreesClassifier(n_estimators = estimator, random_state=0, bootstrap = 'False', class_weight="balanced_subsample")
clf2.fit(X_train,y_train)
f1_score_extreme_random_test[i] = metrics.f1_score(clf2.predict(X_test), y_test)
f1_score_extreme_random_train[i] = metrics.f1_score(clf2.predict(X_train), y_train)
i=i+1
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
data = pd.DataFrame({"f1_score_random_forest_train":f1_score_random_forest_train,
"f1_score_random_forest_test": f1_score_random_forest_test,
"f1_score_extreme_random_train": f1_score_extreme_random_train,
"f1_score_extreme_random_test": f1_score_extreme_random_test},
index=estimators)
sns.lineplot(data=data)
plt.xlabel("estimators")
plt.ylabel("score")
plt.title("scores varies with number of estimators")
Text(0.5, 1.0, 'scores varies with number of estimators')
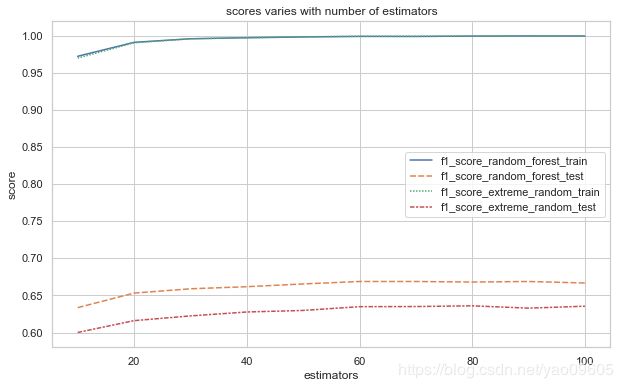
可以看到大约在60的时候,模型达到了最优效果,可以看到在测试集上随机森林算法的表现更好。
测试树的深度对两种算法的影响
depths = range(3,50)
f1_score_random_forest_train=np.zeros(50)
f1_score_random_forest_test=np.zeros(50)
f1_score_extreme_random_train=np.zeros(50)
f1_score_extreme_random_test=np.zeros(50)
for depth in depths:
clf1=RandomForestClassifier(n_estimators = 60, max_depth=depth, random_state=0, bootstrap='False', class_weight="balanced_subsample")
clf1.fit(X_train,y_train)
f1_score_random_forest_test[depth] = metrics.f1_score(clf1.predict(X_test), y_test)
f1_score_random_forest_train[depth] = metrics.f1_score(clf1.predict(X_train), y_train)
clf2 = ExtraTreesClassifier(n_estimators = 60, max_depth=depth, random_state=0, bootstrap='False', class_weight="balanced_subsample")
clf2.fit(X_train,y_train)
f1_score_extreme_random_test[depth] = metrics.f1_score(clf2.predict(X_test), y_test)
f1_score_extreme_random_train[depth] = metrics.f1_score(clf2.predict(X_train), y_train)
plt.figure(figsize=(10,6))
sns.set(style="whitegrid")
data = pd.DataFrame({"f1_score_random_forest_train":f1_score_random_forest_train,
"f1_score_random_forest_test": f1_score_random_forest_test,
"f1_score_extreme_random_train": f1_score_extreme_random_train,
"f1_score_extreme_random_test": f1_score_extreme_random_test})
sns.lineplot(data=data)
plt.xlabel("depths")
plt.ylabel("score")
plt.title("scores varies with number of depths")
Text(0.5, 1.0, 'scores varies with number of depths')
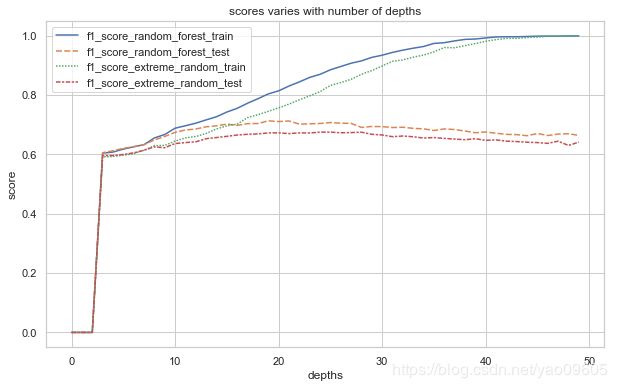
根据图线,在深度为10左右,分数和模型在训练集和测试集上有一个平衡,模型既没有过拟合,分数也比较高
OOBS参数的影响
clf = RandomForestClassifier(n_estimators=100, random_state=0)
clf = clf.fit(X_train, y_train)
print("train_score:",clf.score(X_train, y_train))
print("test_score:", clf.score(X_test, y_test))
print("train_f1_score:", metrics.f1_score(clf.predict(X_train), y_train))
print("test_f1_score:", metrics.f1_score(clf.predict(X_test), y_test))
train_score: 1.0
test_score: 0.8514924456454981
train_f1_score: 1.0
test_f1_score: 0.670482420278005
clf = RandomForestClassifier(n_estimators=100, random_state=0, oob_score=True)
clf = clf.fit(X_train, y_train)
print("train_score:",clf.score(X_train, y_train))
print("test_score:", clf.score(X_test, y_test))
print("train_f1_score:", metrics.f1_score(clf.predict(X_train), y_train))
print("test_f1_score:", metrics.f1_score(clf.predict(X_test), y_test))
train_score: 1.0
test_score: 0.8514924456454981
train_f1_score: 1.0
test_f1_score: 0.670482420278005
光是oobs参数好像没有什么优化过拟合的效果
min_samples_split 的作用
这个参数是指最少需要多少个样本才进行下一步分裂,默认是2,我们常识一系列值来测试这个对优化过拟合模型的帮助
min_sample=range(2,51,2)
f1_score_random_forest_train=np.zeros(25)
f1_score_random_forest_test=np.zeros(25)
f1_score_extreme_random_train=np.zeros(25)
f1_score_extreme_random_test=np.zeros(25)
i=0
for sample in min_sample:
clf1=RandomForestClassifier(n_estimators = 60,random_state=0, min_samples_split=sample, bootstrap='False', class_weight="balanced_subsample")
clf1.fit(X_train,y_train)
f1_score_random_forest_test[i] = metrics.f1_score(clf1.predict(X_test), y_test)
f1_score_random_forest_train[i] = metrics.f1_score(clf1.predict(X_train), y_train)
clf2 = ExtraTreesClassifier(n_estimators = 60,random_state=0, min_samples_split=sample, bootstrap='False', class_weight="balanced_subsample")
clf2.fit(X_train,y_train)
f1_score_extreme_random_test[i] = metrics.f1_score(clf2.predict(X_test), y_test)
f1_score_extreme_random_train[i] = metrics.f1_score(clf2.predict(X_train), y_train)
i=i+1
plt.figure(figsize=(10,6))
sns.set(style="darkgrid")
data = pd.DataFrame({"f1_score_random_forest_train":f1_score_random_forest_train,
"f1_score_random_forest_test": f1_score_random_forest_test,
"f1_score_extreme_random_train": f1_score_extreme_random_train,
"f1_score_extreme_random_test": f1_score_extreme_random_test},
index = min_sample)
sns.lineplot(data=data)
plt.xlabel("min_samples_split")
plt.ylabel("score")
plt.title("scores varies with number of min_samples_split")
Text(0.5, 1.0, 'scores varies with number of min_samples_split')
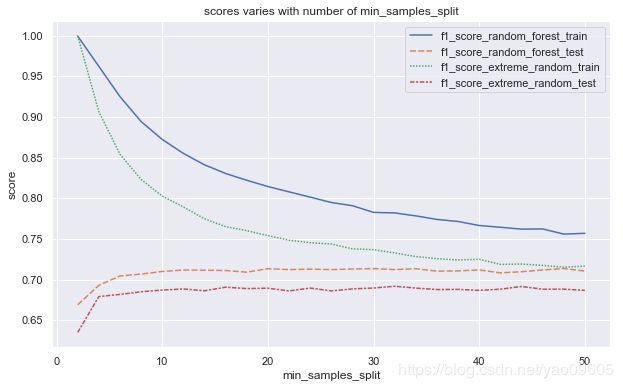
这里可以看到randomforest的f1_score超过了0.70,效果不错,可以看到这比单纯通过控制树的深度这种粗暴的方式来控制过拟合要更好,下面我们使用小数来进行调参
min_sample=np.linspace(0.001,0.02,20)
f1_score_random_forest_train=np.zeros(20)
f1_score_random_forest_test=np.zeros(20)
f1_score_extreme_random_train=np.zeros(20)
f1_score_extreme_random_test=np.zeros(20)
i=0
for sample in min_sample:
clf1=RandomForestClassifier(n_estimators = 60,random_state=0, min_samples_split=sample, bootstrap='False', class_weight="balanced_subsample")
clf1.fit(X_train,y_train)
f1_score_random_forest_test[i] = metrics.f1_score(clf1.predict(X_test), y_test)
f1_score_random_forest_train[i] = metrics.f1_score(clf1.predict(X_train), y_train)
clf2 = ExtraTreesClassifier(n_estimators = 60,random_state=0, min_samples_split=sample, bootstrap='False', class_weight="balanced_subsample")
clf2.fit(X_train,y_train)
f1_score_extreme_random_test[i] = metrics.f1_score(clf2.predict(X_test), y_test)
f1_score_extreme_random_train[i] = metrics.f1_score(clf2.predict(X_train), y_train)
i=i+1
plt.figure(figsize=(10,6))
sns.set(style="darkgrid")
data = pd.DataFrame({"f1_score_random_forest_train":f1_score_random_forest_train,
"f1_score_random_forest_test": f1_score_random_forest_test,
"f1_score_extreme_random_train": f1_score_extreme_random_train,
"f1_score_extreme_random_test": f1_score_extreme_random_test},
index = min_sample)
sns.lineplot(data=data)
plt.xlabel("min_samples_split(fraction)")
plt.ylabel("score")
plt.title("scores varies with number of min_samples_split")
Text(0.5, 1.0, 'scores varies with number of min_samples_split')
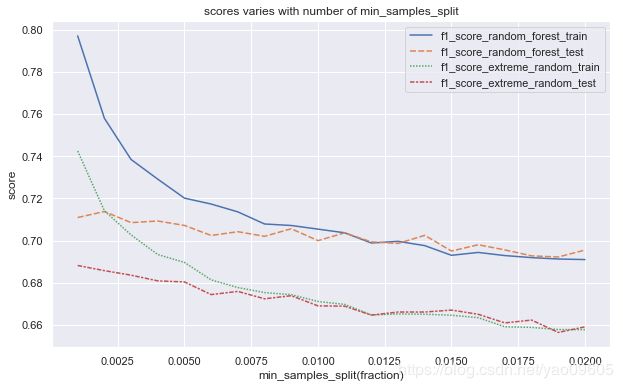
可以看到随着叶子权重占比越来越高,过拟合的现象逐渐消失,但是欠拟合的现象也逐渐呈现,而且测试集上的成绩明显成锯齿形,说明在优化过程中出现震荡。我们发现对于本样本选取0.009的min_samples_split比较好
min_samples_leaf的影响
这个值表示每个叶子至少需要多少个样本,如果某个节点分裂后左子树或右子树中的样本数少于min_samples_leaf,那么不进行分裂
min_sample_leaf=range(1,31)
f1_score_random_forest_train=np.zeros(30)
f1_score_random_forest_test=np.zeros(30)
f1_score_extreme_random_train=np.zeros(30)
f1_score_extreme_random_test=np.zeros(30)
i=0
for sample in min_sample_leaf:
clf1=RandomForestClassifier(n_estimators = 60,random_state=0, min_samples_leaf=sample, bootstrap='False', class_weight="balanced_subsample")
clf1.fit(X_train,y_train)
f1_score_random_forest_test[i] = metrics.f1_score(clf1.predict(X_test), y_test)
f1_score_random_forest_train[i] = metrics.f1_score(clf1.predict(X_train), y_train)
clf2 = ExtraTreesClassifier(n_estimators = 60,random_state=0, min_samples_leaf=sample, bootstrap='False', class_weight="balanced_subsample")
clf2.fit(X_train,y_train)
f1_score_extreme_random_test[i] = metrics.f1_score(clf2.predict(X_test), y_test)
f1_score_extreme_random_train[i] = metrics.f1_score(clf2.predict(X_train), y_train)
i=i+1
plt.figure(figsize=(10,6))
sns.set(style="darkgrid")
data = pd.DataFrame({"f1_score_random_forest_train":f1_score_random_forest_train,
"f1_score_random_forest_test": f1_score_random_forest_test,
"f1_score_extreme_random_train": f1_score_extreme_random_train,
"f1_score_extreme_random_test": f1_score_extreme_random_test},
index = min_sample_leaf)
sns.lineplot(data=data)
plt.xlabel("min_samples_leaf")
plt.ylabel("score")
plt.title("scores varies with number of min_samples_leaf")
Text(0.5, 1.0, 'scores varies with number of min_samples_leaf')
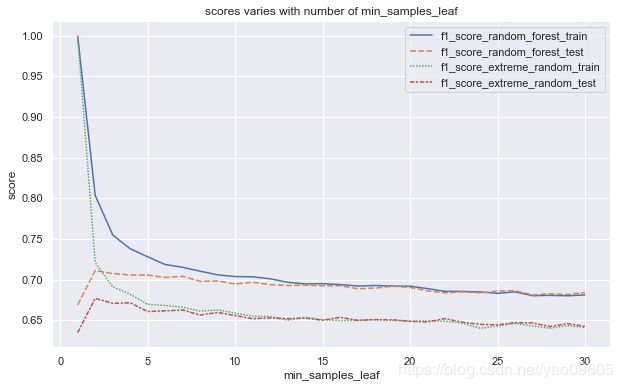
从结果来看,这个参数可以很好的解决过拟合的问题,但是也会降低模型的准确度
总结
这篇文章我们总共看了5个参数
-
n_estimators: 树不是越多越好,但随着树的增加模型效果会变好,但到一定数量之后反而会慢慢下降,不会再增加分数
-
max_depth: 减少树的深度可以解决过拟合的问题,但是由于颗粒度过粗,容易一下子把模型的效果下降太多
-
oob_score: 没有看出有什么效果,可能需要和别的参数配合使用
-
min_samples_split: 可以有效解决过拟合问题,解决过程也比较细腻,比较推荐
-
min_samples_leaf: 可以有效解决过拟合问题,配合min_samples_split食用,效果更佳