【推荐系统】【论文阅读笔记】Improving Content-based and Hybrid Music Recommendation using Deep Learning
原文作者:Xinxi Wang and Ye Wang
在歌曲相关因素中,音乐音频内容是非常重要的。在大多数情况下,我们喜欢/不喜欢一首歌,这是因为它的音频内容具有一些特征,例如人声、旋律、节奏、音色、体裁、乐器或歌词。没有听内容,我们对这首歌的质量几乎一无所知,更不用说我们是否喜欢它了。因为音乐内容在很大程度上决定了我们的偏好,所以内容应该能够为推荐提供良好的预测能力。
然而,现有的音乐推荐者对音乐音频内容的依赖往往会产生不尽如人意的推荐效果。它们都遵循两个阶段的方法:提取传统的音频内容特征,如梅尔倒谱系数(MFCC),然后使用这些特征预测用户偏好。然而,传统的音频内容特征不是为音乐推荐或与音乐相关的任务而创建的(例如,MFCC最初用于语音识别)。在发现他们也能描述诸如体裁、音色和旋律等高级音乐概念之后,他们才开始关注音乐推荐。使用这些特性可能会导致推荐性能在以下两个方面下降。1.由于所谓的语义鸿沟,高层概念无法准确描述。2.即使特征描述是准确的,高级的概念对于用户的音乐偏好也可能不是必需的。因此,传统功能可能无法考虑与音乐推荐相关的信息。
我们认为,一种有效的基于内容的音乐推荐方法的关键是一套好的内容特征。人工获取这样的特征是可能的,但费时费力。一个更好的方法是将现有的两阶段方法结合到一个统一的自动化过程中:自动和直接从音频内容中学习特征,以最大限度地提高推荐性能。深度学习技术的最新发展使这种统一的方法成为可能。事实上,人们已经开始使用深度学习来学习其他音乐任务的特征,如音乐流派分类和音乐情感预测,并取得了很好的效果。
基于内容的方法还经常结合协作过滤(CF),根据志同道合的用户的兴趣推荐歌曲。大多数现有的推荐基于CF,因为它具有较高的准确性。然而,由于它仅仅依赖于使用数据,所以当遇到新的歌曲问题时,CF是无能为力的——它不能推荐没有以前使用历史的歌曲。基于内容的方法不会遇到这个问题,因为它们可以根据歌曲的音频内容进行预测,而音频内容通常可供在线商家使用。因此,基于内容的方法可以在新歌场景中拯救CF。由于CF和基于内容的方法利用了不同维度的信息,因此可以将它们组合成一种混合方法,以便更好地进行预测。
因此,我们首先开发了一个基于内容的模型,该模型可以自动同时从音频内容中提取特征并进行个性化推荐。然后我们开发了一种混合方法来结合CF和内容特征。具体而言,本文力求做出以下贡献:
•:基于内容的方法:我们开发了一个基于概率图形模型和深度学习社区提出的深度信任网络(DBN)的基于内容的推荐模型。它将特征学习和推荐相结合。虽然它不依赖于协作过滤,但它在冷启动阶段和热启动阶段都优于依赖于CF的基于内容的基线模型。
•混合方法:为了将CF和音乐内容结合起来,我们将自动学习的音频功能应用于高效的混合模式。实验结果表明,在混合方法中,所学习的特征对CF具有补充作用,并且优于传统的特征。
在本节中,我们将介绍我们的基于内容的模型和混合模型,以及用于比较我们的模型的两个基于内容的基线模型。
1.推荐模型
符号声明:
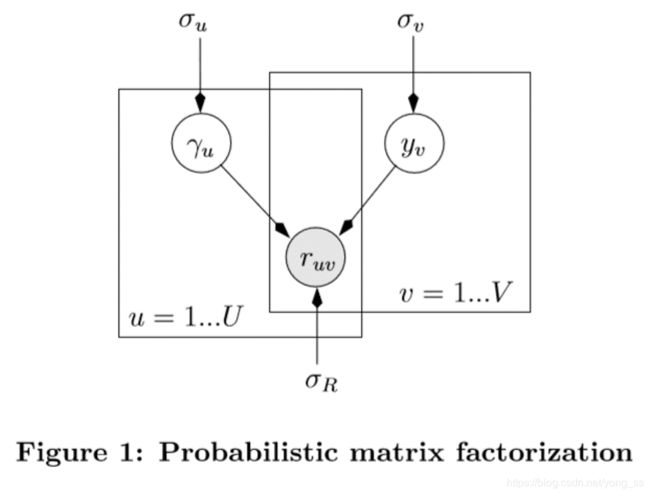
1.1基于概率矩阵分解的协同过滤
协同过滤是一种流行的推荐方法。最新的CF方法是基于矩阵分解(MF)。本文采用概率矩阵因式分解(PMF)方法,具有简单、准确、高效的特点。此外,PMF的原则性概率解释使其能够被扩展以更容易地包含内容信息。
PMF假设每个用户u∈u和song v∈v可以分别表示为潜在特征向量γu和yv。用户u给song v的评分是γu和yv的内积。训练数据通常是非常稀疏的,如果没有正则化,模型会因严重的过度拟合而失效。因此,对γu和yv都使用高斯先验作为正则化。在形式上,模型被指定为以下(参考figure1中的图形表示):
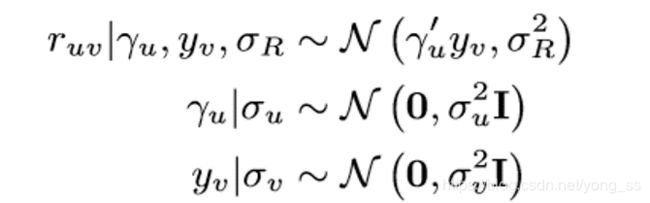
模型的负对数似然可以简化为方程(1),其中I是训练集中的用户歌曲对。λu和λv通常使用验证数据集进行调谐:
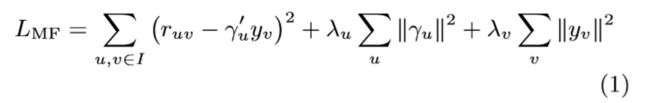
于没有评分数据的新用户/歌曲在模型中没有向量表示,因此无法预测其评分。这种冷启动问题是所有CF方法的特有问题。在下面的部分中,我们将介绍我们对新歌问题的解决方案。
1.2基于内容的音乐推荐
1.2.1具有深度信任网络的层次线性模型(HLDBN)
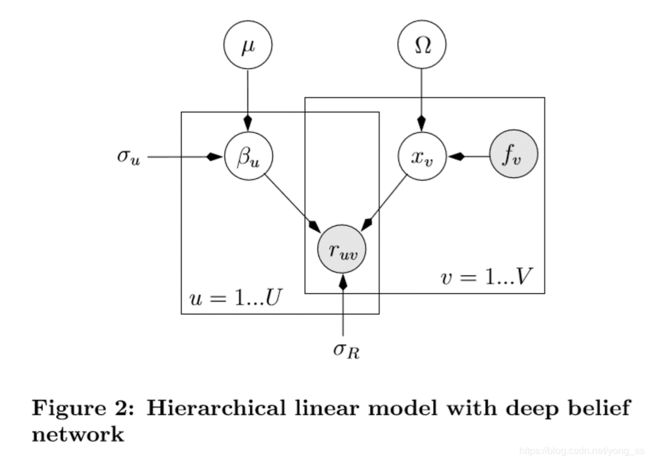
我们假设song v的音频内容为fv,其自动学习的特征向量为xv。用户u的音乐偏好表示为向量βu。u对歌曲v的评分表示为ruv,是xv和βu的内积。我们使用μ表示所有用户的共同音乐偏好,即所有用户βu-s的平均值。模型(figure 2)表示为:
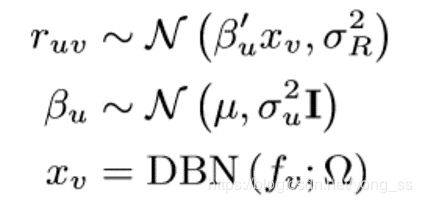
σu指示用户首选项的差异。σu越小,用户偏好与公共偏好μ越相似,βu正则化越强。βu模型的高斯先验将用户的共同兴趣作为一个簇。然而,不同性别、年龄和文化背景的用户可以形成不同的群体。
为了捕捉这种分组效应,我们可以在混合高斯之前改变单个高斯。我们尝试了这样的先验,并使用蒙特卡罗期望最大化来估计参数,但它导致了过度拟合。因此,我们选择单高斯作为先验。
DBN可以看作是一个非常灵活的确定函数,它将fv映射到xv。它有数十万,甚至数百万个参数(表示为Ω)可以从训练数据中学习。我们假设ruv服从正态分布来解释用户评级中的噪声
学习-采用最大似然估计(MLE)对模型进行训练。模型的负对数似然如等式(2)所示,其中不相关常数被省略。超参数λ是比值σu^2/σR^2,较大的λ表示更强的正则化。
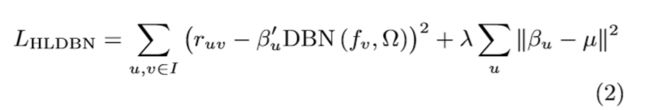
由于Ω包含大量的参数,直接利用梯度下降法优化LHLDBN容易过拟合。按照DBN训练过程,我们首先以无监督的方式将DBN预先训练为受限Boltzmann机器的堆叠层,然后使用小批量随机梯度下降来优化LHLDBN,其中DBN的梯度下降部分被实现为反向传播。
与传统的两阶段方法不同,我们的模型自动同时优化音频特征(xv)和用户偏好参数(βu-s)。这为基于内容的推荐提供了一种统一的、更具原则性的方法。
预测-在学习阶段之后,用户u给予song v的等级可以估计为ru'*DBN(f,vΩ)。由于预测是基于音频内容的,因此也可以准确地推荐新歌。
1.2.2基线模型
我们现在将注意力转向Oord等人提出的两种基于内容的方法。并以此作为我们的基线方法。这些模型是基于卷积神经网络(CNN),另一种流行的深度学习方法。为了使他们的方法与我们的方法直接可比,我们用DBN代替CNN,同时保持其他部分不变。
基于内容的基线模型1(CB1)-该模型首先利用PMF学习所有用户和歌曲的潜在特征γu和yv,然后训练DBN从音频内容映射到潜在特征yv。在形式上,目标可以表述为:

设xv=DBN(fv,Ω);用户u给予song v的额定值可以预测为ˆruv=γu‘*xv。然而,由于定理1中的一个基本缺陷,这个模型失败了。
定理1。CB1模型不最小化预测评级的平方误差之和。
证明:令![]() 最优目标函数(3)相当于
最优目标函数(3)相当于
我们的真正目标并未预测潜在特征而是预测了评级,所以我们事实上需要最小化评级预测的平方误差之和:
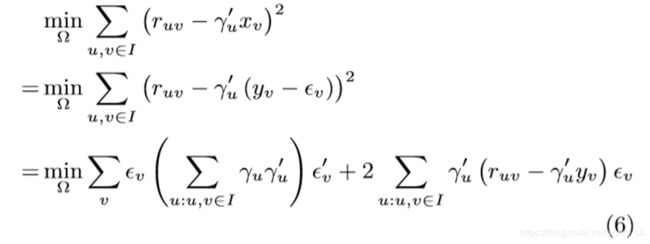
由于![]() 不受约束,因为mlp是通用近似器[43],我们可以看到方程(6)和(4)有不同的最优解。
不受约束,因为mlp是通用近似器[43],我们可以看到方程(6)和(4)有不同的最优解。![]()
Oord等人的原始模型使用加权平方误差和。按照同样的方法,我们可以证明CB1也不最小化加权版本。
基于内容的基线模型2(CB2)-这是Oord等人提出的另一个模型。如下所示:

其中γu是预先从MF获得的。评级ruv预计为γu'xv,其中xv=DBN(fv,Ω)。
该模型使用正确的目标,因此不存在定理1中讨论的CB1问题。但由于缺乏参数的正则化,可能会导致拟合过度。
CB1和CB2的另一个问题是它们直接基于MF的结果,因此它们的预测结果与协同过滤(CF)的结果密切相关。
1.3混合CF和基于内容的音乐推荐
协同过滤和基于内容的方法使用不同的信息。为了融合所有可用的信息以进行更精确的预测,我们可以将两者结合在一种混合方法中。
信息融合在传感器融合、多媒体信息等领域得到了广泛的研究
我们的问题主要有两种解决方法。决策融合结合了现有CF和基于内容的方法的预测结果。另一方面,数据融合开发了一个新的统一模型,将CF和音频内容结合起来。我们的混合方法是基于后者的,但它也使用HLDBN学习的特性。
在我们的混合模型(图3)中,我们假设已经知道每首歌的音频特性xv。γu、yv和βu不是直接从PMF和HLDBN的结果中获得,而是需要从数据中共同学习。通过CF部分γu‘yv和内容部分βu’xv之和预测额定ruv。γu和yv的prior按照PMF模型设置,βu按照HLDBN模型设置。
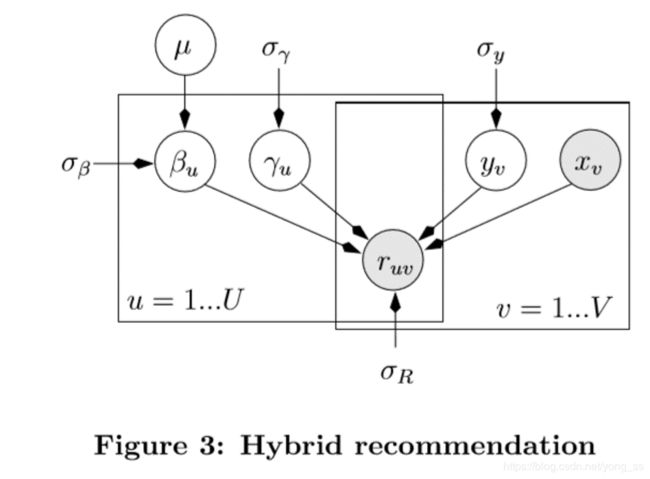
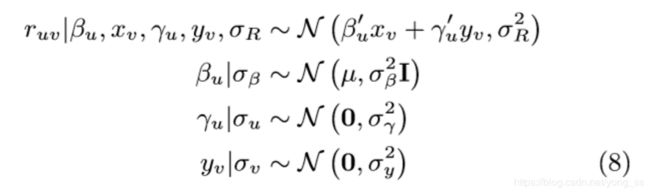
负对数似然可以简化为以下(其中![]() ):
):

Lhybrid的不是凸函数,但如果我们固定βu、μ、γu和yv中的任意三个,则它是凸的,并且可以得到封闭形式的最优解。因此,我们使用交替最小二乘(ALS)算法优化LHybrid:首先将LHybrid对四个参数的导数设为零,然后求解方程,得到以下四个更新公式。然后我们迭代它们,直到LHybrid收敛,或者直到验证集上的预测性能达到最高点。
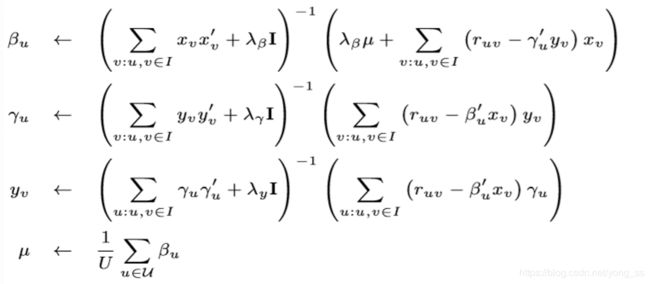
为了获得更快的收敛速度,首先使用PMF初始化γu,yv。
我们可以在方程8之后加上xv=DBN(fv,Ω),并结合其他参数优化Ω,从而建立一个纯数据融合模型。但是,我们发现它的性能不如上面的。